
Warum brauchen Ölmänner NLP? Wie bringt man einen Computer dazu, Fachjargon zu verstehen? Kann man der Maschine erklären, was "Druck", "Gasannahme", "ringförmig" ist? Wie sind Neueinstellungen und der Sprachassistent verbunden? Wir werden versuchen, diese Fragen in dem Artikel über die Einführung eines digitalen Assistenten in die Software zur Unterstützung der Ölförderung zu beantworten, der die Routinearbeit eines Geologen-Entwicklers erleichtert.
Wir am Institut entwickeln unsere eigene Software ( https://rn.digital/ ) für die Ölindustrie. Damit sich Benutzer in sie verlieben können, müssen Sie nicht nur nützliche Funktionen implementieren, sondern auch ständig über den Komfort der Benutzeroberfläche nachdenken. Einer der Trends in UI / UX ist heute der Übergang zu Sprachschnittstellen. Was auch immer man sagen mag, die natürlichste und bequemste Form der Interaktion für eine Person ist die Sprache. Daher wurde die Entscheidung getroffen, einen Sprachassistenten in unseren Softwareprodukten zu entwickeln und zu implementieren.
Neben der Verbesserung der UI / UX-Komponente können Sie mit der Einführung des Assistenten auch den "Schwellenwert" für die Arbeit neuer Mitarbeiter mit Software senken. Die Funktionalität unserer Programme ist umfangreich und es kann mehr als einen Tag dauern, um dies herauszufinden. Die Möglichkeit, den Assistenten zu "bitten", den gewünschten Befehl auszuführen, reduziert den Zeitaufwand für die Lösung der Aufgabe sowie den Stress eines neuen Jobs.
Da der Sicherheitsdienst des Unternehmens sehr empfindlich auf die Übertragung von Daten an externe Dienste reagiert, haben wir uns überlegt, einen Assistenten zu entwickeln, der auf Open Source-Lösungen basiert und es uns ermöglicht, Informationen lokal zu verarbeiten.
Strukturell besteht unser Assistent aus folgenden Modulen:
- Spracherkennung (ASR)
- Zuordnung semantischer Objekte (Natural Language Understanding, NLU)
- Befehlsausführung
- Sprachsynthese (Text-to-Speech, TTS)
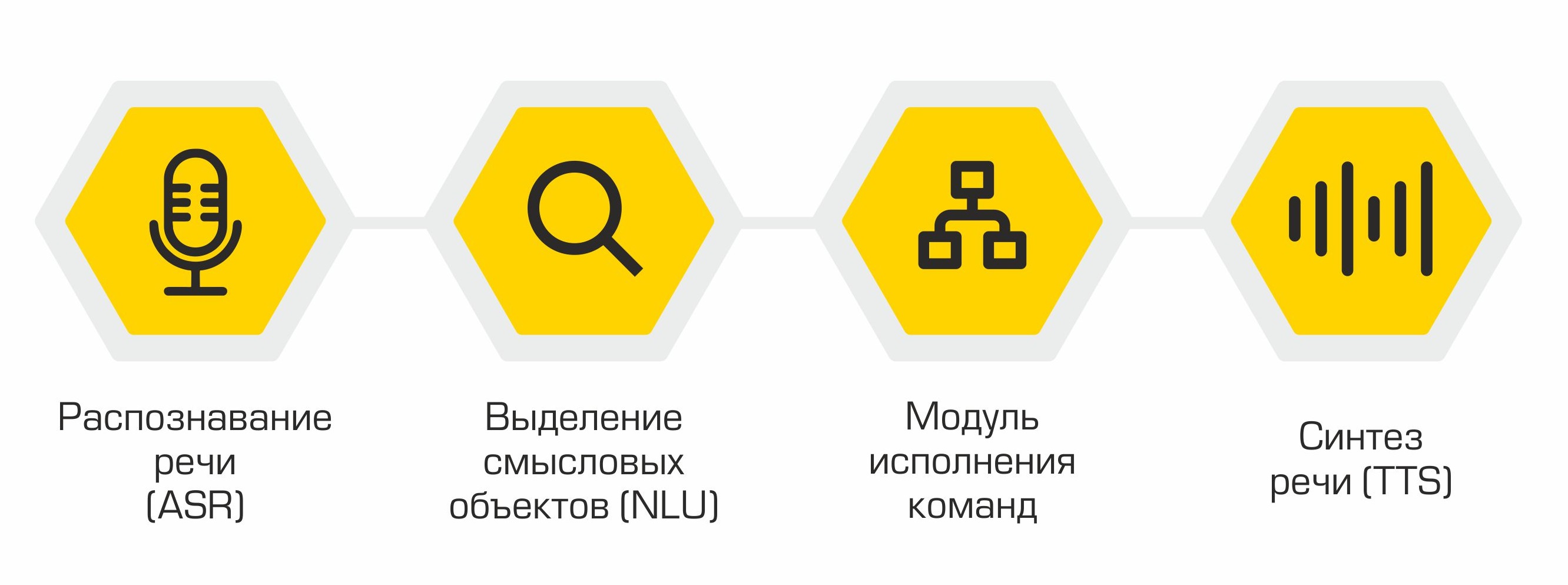
Das Prinzip des Assistenten: von Worten (Benutzer) zu Handlungen (in Software)!
Der Ausgang jedes Moduls dient als Einstiegspunkt für die nächste Komponente im System. Daher wird die Sprache des Benutzers in Text umgewandelt und zur Verarbeitung an Algorithmen für maschinelles Lernen gesendet, um die Absicht des Benutzers zu bestimmen. Abhängig von dieser Absicht wird die erforderliche Klasse im Befehlsausführungsmodul aktiviert, das die Anforderung des Benutzers erfüllt. Nach Abschluss der Operation überträgt das Befehlsausführungsmodul Informationen über den Befehlsausführungsstatus an das Sprachsynthesemodul, das wiederum den Benutzer benachrichtigt.
Jedes Hilfsmodul ist ein Microservice. Auf Wunsch kann der Benutzer also überhaupt auf Sprachtechnologien verzichten und sich über einen Chat-Bot direkt an das "Gehirn" des Assistenten wenden - an das Modul zum Hervorheben semantischer Objekte.
Spracherkennung
Die erste Stufe der Spracherkennung ist die Sprachsignalverarbeitung und Merkmalsextraktion. Die einfachste Darstellung eines Audiosignals ist ein Oszillogramm. Es spiegelt die Energiemenge zu einem bestimmten Zeitpunkt wider. Diese Informationen reichen jedoch nicht aus, um den gesprochenen Ton zu bestimmen. Für uns ist es wichtig zu wissen, wie viel Energie in verschiedenen Frequenzbereichen enthalten ist. Dazu wird mit der Fourier-Transformation ein Übergang vom Oszillogramm zum Spektrum durchgeführt.
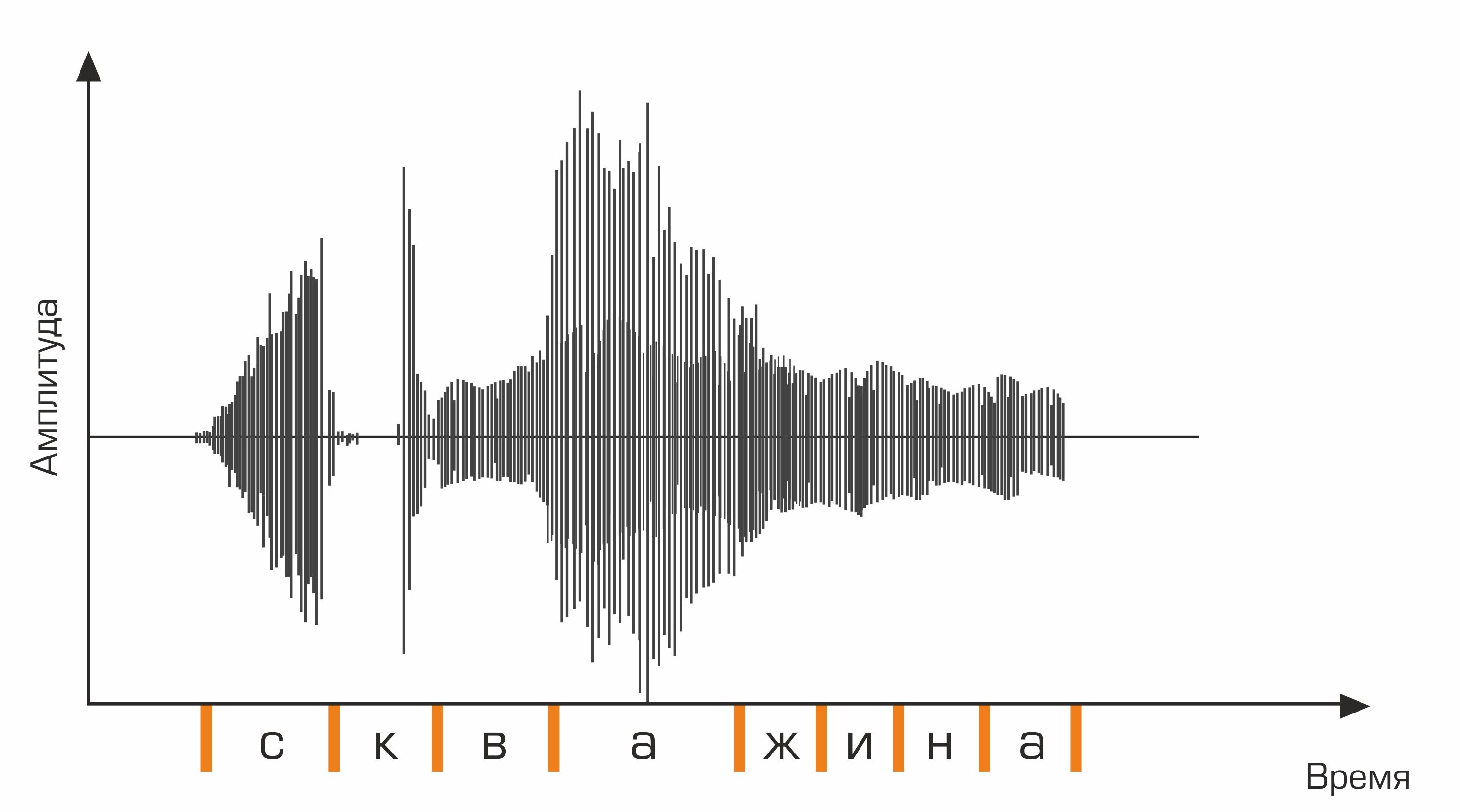
Dies ist ein Oszillogramm.
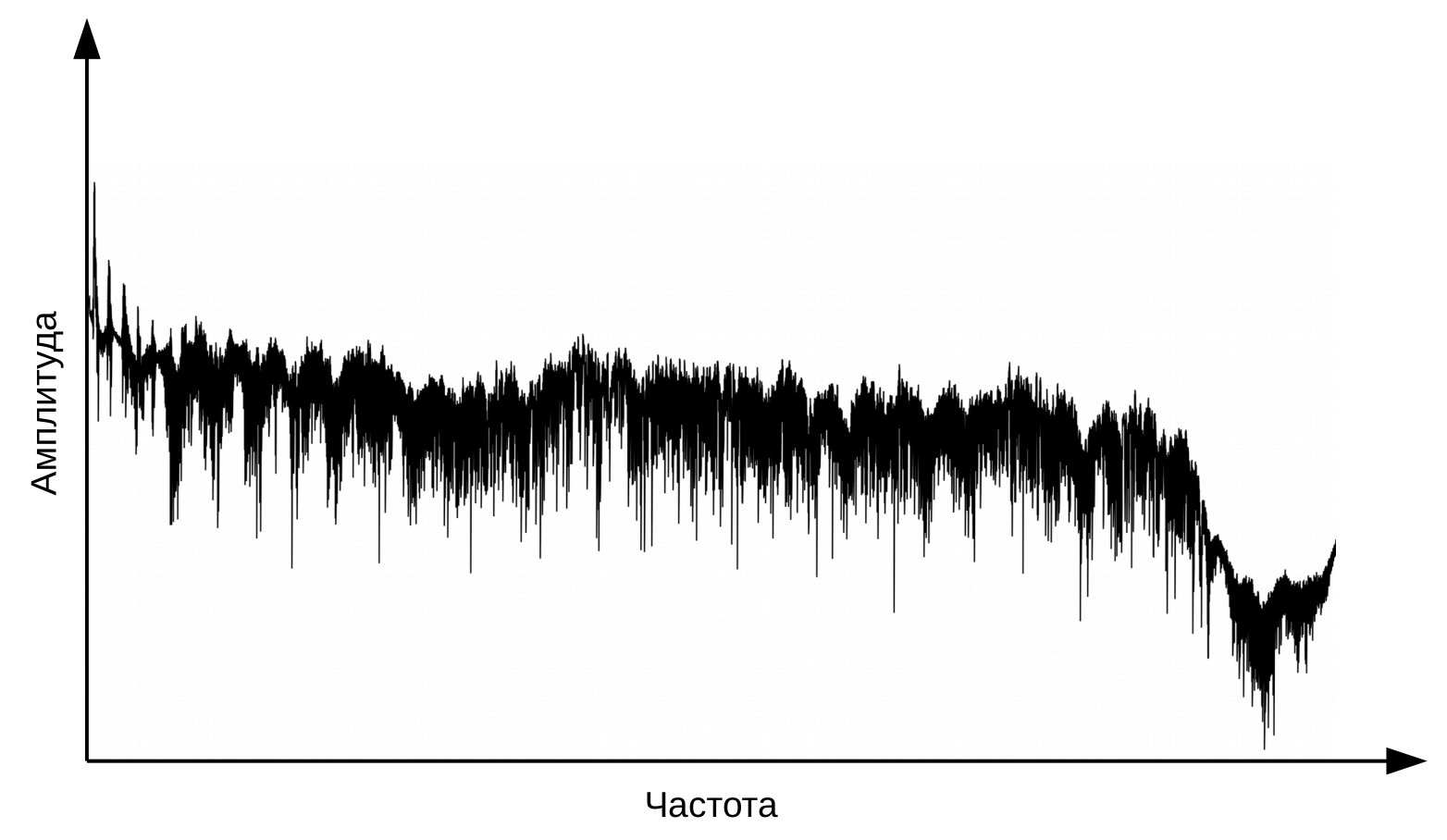
Und das ist das Spektrum für jeden Moment.
Hier muss klargestellt werden, dass Sprache entsteht, wenn ein vibrierender Luftstrom durch den Kehlkopf (Quelle) und den Stimmapparat (Filter) strömt. Zur Klassifizierung von Phonemen benötigen wir lediglich Informationen zur Filterkonfiguration, dh zur Position der Lippen und der Zunge. Diese Information kann durch den Übergang vom Spektrum zum Cepstrum (Cepstrum - ein Anagramm des Wortspektrums) unterschieden werden, der unter Verwendung der inversen Fourier-Transformation des Logarithmus des Spektrums durchgeführt wird. Auch hier ist die x-Achse nicht die Frequenz, sondern die Zeit. Der Begriff "Frequenz" wird verwendet, um zwischen den Zeitbereichen des Cepstrums und dem ursprünglichen Audiosignal zu unterscheiden (Oppenheim, Schafer. Digital Signal Processing, 2018).
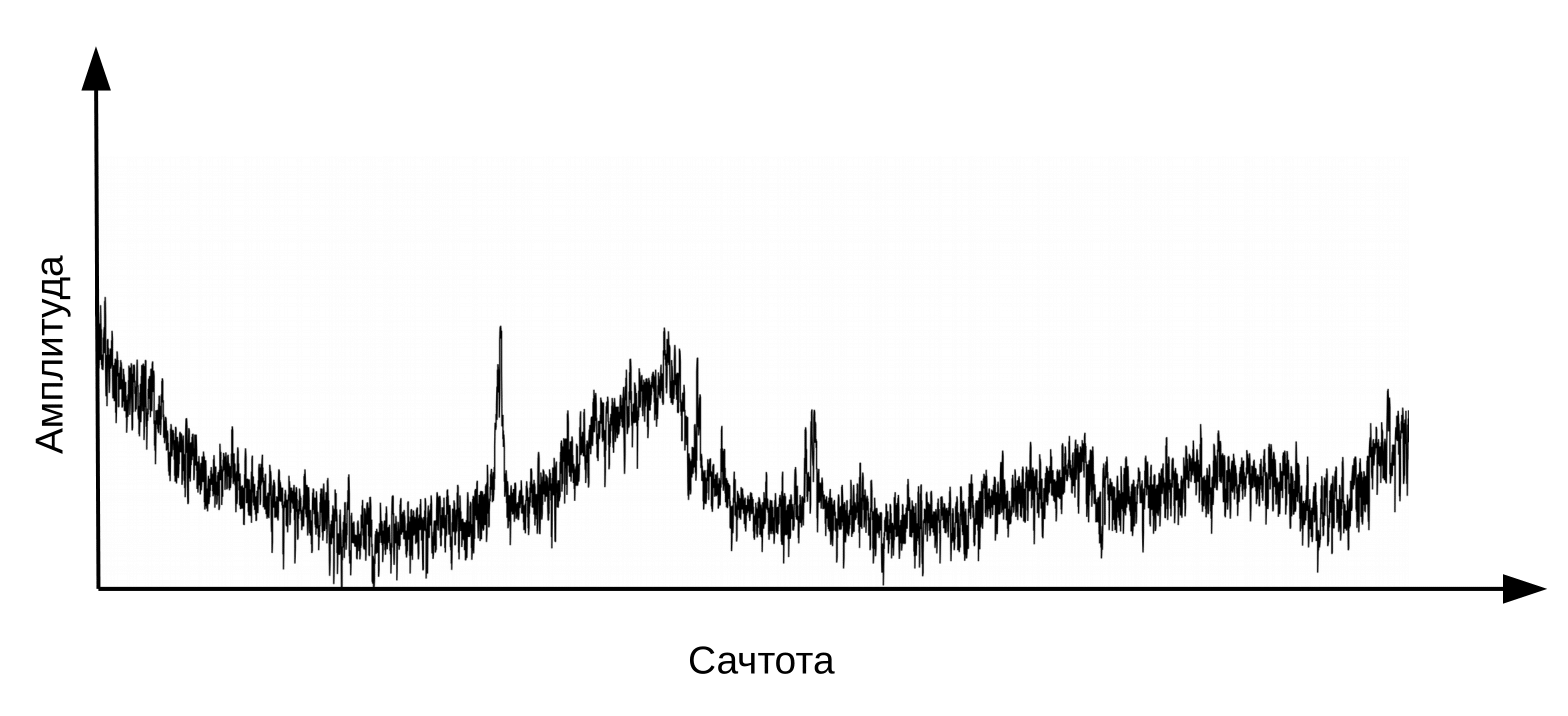
Cepstrum oder einfach "Spektrum des Logarithmus des Spektrums". Ja, ja, häufig ist ein Begriff , kein Tippfehler
Informationen über die Position des Vokaltrakts finden Sie in den ersten 12 Cepstrum-Koeffizienten. Diese 12 Cepstralkoeffizienten werden durch dynamische Merkmale (Delta und Delta-Delta) ergänzt, die Änderungen im Audiosignal beschreiben. (Jurafsky, Martin. Sprach- und Sprachverarbeitung, 2008). Der resultierende Wertevektor wird als MFCC-Vektor (Mel-Frequenz-Cepstral-Koeffizienten) bezeichnet und ist das häufigste akustische Merkmal, das bei der Spracherkennung verwendet wird.
Was passiert als nächstes mit den Schildern? Sie werden als Eingabe für das akustische Modell verwendet. Es zeigt, welche Spracheinheit einen solchen MFCC-Vektor am wahrscheinlichsten "erzeugt". In verschiedenen Systemen können solche Spracheinheiten Teile von Phonemen, Phonemen oder sogar Wörtern sein. Somit transformiert das akustische Modell eine Folge von MFCC-Vektoren in eine Folge von höchstwahrscheinlich Phonemen.
Ferner ist es für die Folge von Phonemen erforderlich, die geeignete Folge von Wörtern auszuwählen. Hier kommt das Sprachwörterbuch ins Spiel, das die Transkription aller vom System erkannten Wörter enthält. Das Zusammenstellen solcher Wörterbücher ist ein mühsamer Prozess, der Expertenwissen über die Phonetik und Phonologie einer bestimmten Sprache erfordert. Ein Beispiel für eine Zeile aus einem Transkriptionswörterbuch:
gut skv aa zh yn ay
Im nächsten Schritt bestimmt das Sprachmodell die vorherige Wahrscheinlichkeit des Satzes in der Sprache. Mit anderen Worten, das Modell gibt eine Schätzung darüber, wie wahrscheinlich es ist, dass ein solcher Satz in einer Sprache erscheint. Ein gutes Sprachmodell wird feststellen, dass der Ausdruck "Chart the Oil Rate" wahrscheinlicher ist als der Satz "Chart the Nine Oil".
Die Kombination eines akustischen Modells, eines Sprachmodells und eines Aussprachewörterbuchs erzeugt ein „Gitter“ von Hypothesen - alle möglichen Wortsequenzen, aus denen die wahrscheinlichste mit dem dynamischen Programmieralgorithmus ermittelt werden kann. Sein System bietet es als anerkannten Text an.
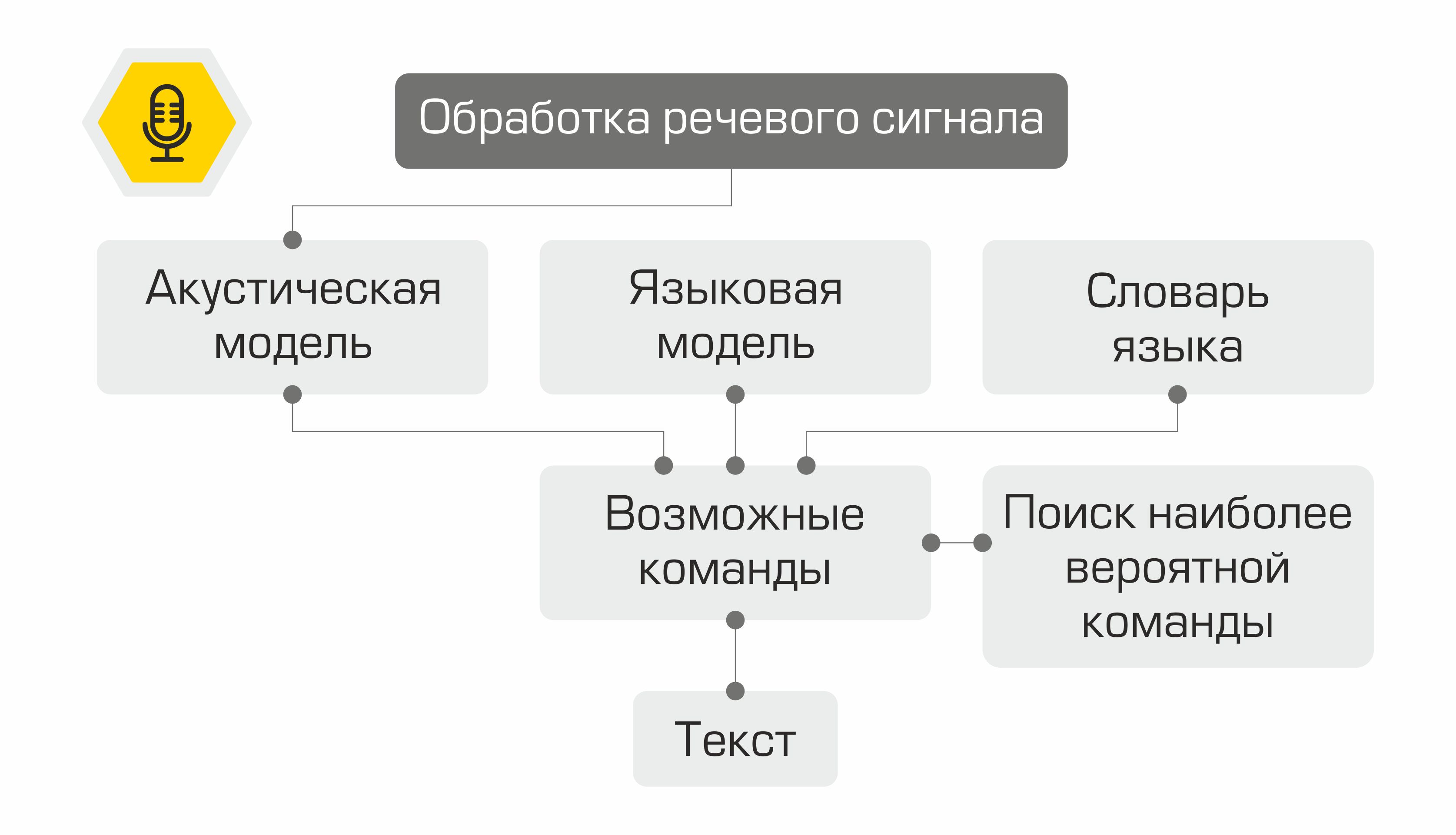
Schematische Darstellung der Funktionsweise des Spracherkennungssystems
Es wäre unpraktisch, das Rad neu zu erfinden und eine Spracherkennungsbibliothek von Grund auf neu zu schreiben, daher fiel unsere Wahl auf das Kaldi- Framework . Der zweifelsfreie Vorteil der Bibliothek liegt in ihrer Flexibilität, die es bei Bedarf ermöglicht, alle Komponenten des Systems zu erstellen und zu ändern. Darüber hinaus können Sie mit der Apache-Lizenz 2.0 die Bibliothek in der kommerziellen Entwicklung frei verwenden.
Als Daten für das Training verwendete ein akustisches Modell den Freeware-Audiodatensatz VoxForge . Um eine Folge von Phonemen in Wörter umzuwandeln, haben wir das russische Sprachwörterbuch verwendet, das von der CMU Sphinx- Bibliothek bereitgestellt wird . Da das Wörterbuch nicht die Aussprache von Begriffen enthielt, die für die Ölindustrie spezifisch sind, basierend darauf, unter Verwendung des Dienstprogrammsg2p-seq2seq trainierte ein Graphem-zu-Phonem-Modell, um schnell Transkriptionen für neue Wörter zu erstellen. Das Sprachmodell wurde sowohl auf Audio-Transkripten von VoxForge als auch auf einem von uns erstellten Datensatz trainiert, der Begriffe der Öl- und Gasindustrie, Namen von Feldern und produzierenden Gesellschaften enthält.
Auswahl semantischer Objekte
Wir haben also die Sprache des Benutzers erkannt, aber dies ist nur eine Textzeile. Wie sagen Sie dem Computer, was zu tun ist? Die frühesten Sprachsteuerungssysteme verwendeten einen streng begrenzten Befehlssatz. Nachdem einer dieser Sätze erkannt worden war, konnte die entsprechende Operation aufgerufen werden. Seitdem sind Technologien für die Verarbeitung und das Verständnis natürlicher Sprachen (NLP bzw. NLU) einen Sprung nach vorne gemacht. Bereits heute können Modelle, die mit großen Datenmengen trainiert wurden, die Bedeutung einer Aussage gut verstehen.
Um dem Text einer erkannten Phrase eine Bedeutung zu entziehen, müssen zwei Probleme des maschinellen Lernens gelöst werden:
- Benutzerteamklassifizierung (Absichtsklassifizierung).
- Zuordnung benannter Entitäten (Named Entity Recognition).
Bei der Entwicklung der Modelle haben wir die Open-Source- Rasa- Bibliothek verwendet , die unter der Apache-Lizenz 2.0 vertrieben wird.
Um das erste Problem zu lösen, muss der Text als numerischer Vektor dargestellt werden, der von einer Maschine verarbeitet werden kann. Für eine solche Transformation wird das neuronale StarSpace- Modell verwendet , mit dem der Anforderungstext und die Anforderungsklasse in einem gemeinsamen Raum " verschachtelt " werden können.

Neuronales StarSpace-Modell
Während des Trainings lernt das neuronale Netzwerk, Entitäten zu vergleichen, um den Abstand zwischen dem Anforderungsvektor und dem Vektor der richtigen Klasse zu minimieren und den Abstand zu den Vektoren verschiedener Klassen zu maximieren. Während des Tests wird die Klasse y für die Abfrage x ausgewählt, damit:
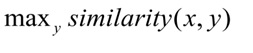
Der Kosinusabstand wird als Maß für die Ähnlichkeit von Vektoren verwendet:
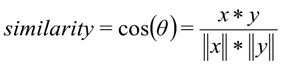
wobei
x die Anforderung des Benutzers ist, y die Anforderungskategorie ist.
3000 Abfragen wurden markiert, um den Benutzerabsichtsklassifizierer zu trainieren. Insgesamt haben wir 8 Klassen absolviert. Wir haben die Stichprobe in Trainings- und Teststichproben im Verhältnis 70/30 unter Verwendung der stratifizierten Zielschichtungsmethode unterteilt. Durch die Schichtung konnte die ursprüngliche Verteilung der Klassen im Zug und im Test beibehalten werden. Die Qualität des trainierten Modells wurde anhand mehrerer Kriterien gleichzeitig bewertet:
- Rückruf - Der Anteil korrekt klassifizierter Anforderungen für alle Anforderungen dieser Klasse.
- Der Anteil korrekt klassifizierter Anfragen (Genauigkeit).
- Präzision - Der Anteil korrekt klassifizierter Anforderungen an allen Anforderungen, die das System dieser Klasse zugeordnet hat.
- F1 – .
Die Systemfehlermatrix wird auch verwendet, um die Qualität des Klassifizierungsmodells zu bewerten. Die y-Achse ist die wahre Klasse der Anweisung, die x-Achse ist die vom Algorithmus vorhergesagte Klasse.
In der Kontrollprobe zeigte das Modell die folgenden Ergebnisse:
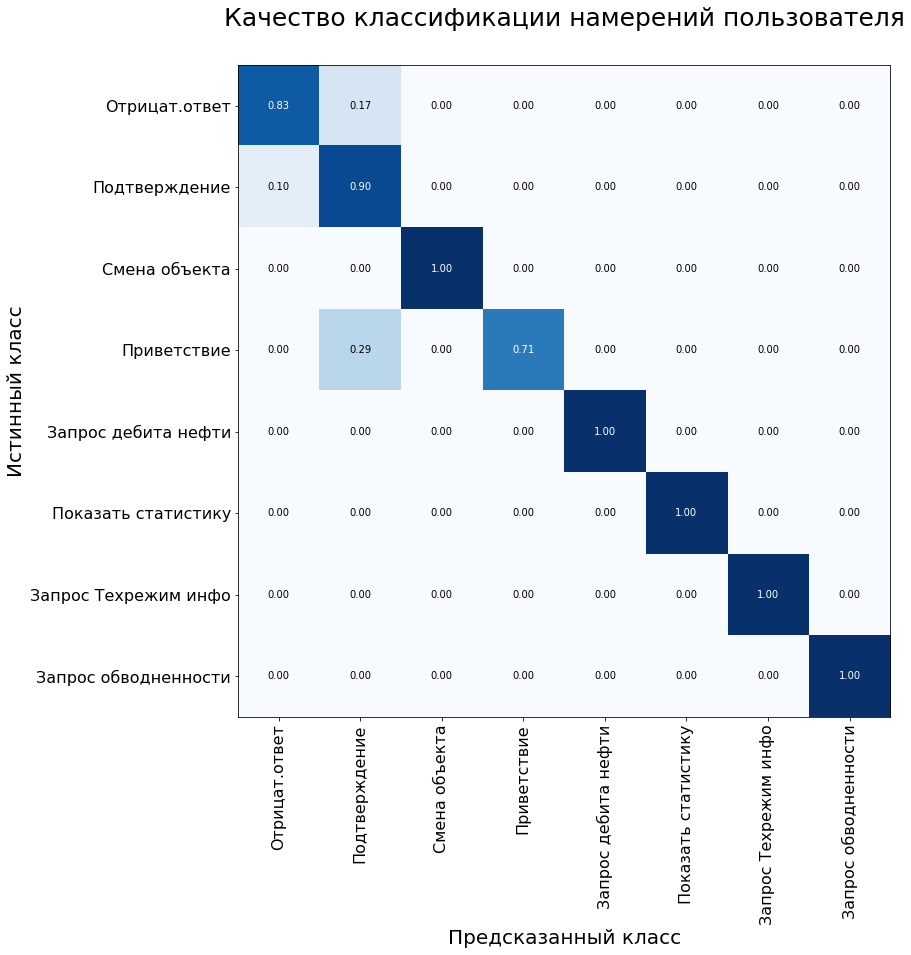
Modellmetriken im Testdatensatz: Genauigkeit - 92%, F1 - 90%.
Die zweite Aufgabe - die Auswahl benannter Entitäten - besteht darin, Wörter und Phrasen zu identifizieren, die ein bestimmtes Objekt oder Phänomen bezeichnen. Solche Einheiten können beispielsweise der Name einer Lagerstätte oder eines Bergbauunternehmens sein.
Um das Problem zu lösen, wurde der Algorithmus der bedingten Zufallsfelder verwendet, bei denen es sich um eine Art Markov-Felder handelt. CRF ist ein Unterscheidungsmodell, d. H. Es modelliert die bedingte Wahrscheinlichkeit P.(Y | X) latenter Zustand Y (Wortklasse) aus Beobachtung X (Wort).
Um Benutzeranforderungen zu erfüllen, muss unser Assistent drei Arten benannter Entitäten hervorheben: Feldname, Bohrlochname und Name des Entwicklungsobjekts. Um das Modell zu trainieren, haben wir einen Datensatz vorbereitet und eine Anmerkung erstellt: Jedem Wort in der Stichprobe wurde eine entsprechende Klasse zugewiesen.

Ein Beispiel aus dem Trainingssatz für das Problem der Erkennung benannter Entitäten.
Es stellte sich jedoch heraus, dass nicht alles so einfach war. Fachjargon ist unter Feldentwicklern und Geologen weit verbreitet. Es ist für die Menschen nicht schwer zu verstehen, dass der "Injektor" eine Injektionsbohrung ist, und "Samotlor" bedeutet höchstwahrscheinlich das Samotlorfeld. Für ein Modell, das mit einer begrenzten Datenmenge trainiert wurde, ist es immer noch schwierig, eine solche Parallele zu ziehen. Um diese Einschränkung zu bewältigen, hilft eine so wunderbare Funktion der Rasa-Bibliothek, ein Wörterbuch mit Synonymen zu erstellen.
## Synonym: Samotlor
- Samotlor
- Samotlor
- das größte Ölfeld in Russland
Durch das Hinzufügen von Synonymen konnten wir die Stichprobe auch geringfügig erweitern. Das Volumen des gesamten Datensatzes betrug 2000 Anfragen, die wir im Verhältnis 70/30 in Zug und Test unterteilt haben. Die Qualität des Modells wurde unter Verwendung der F1-Metrik bewertet und betrug 98%, wenn sie an einer Kontrollprobe getestet wurde.
Befehlsausführung
Abhängig von der im vorherigen Schritt definierten Benutzeranforderungsklasse aktiviert das System die entsprechende Klasse im Software-Kernel. Jede Klasse verfügt über mindestens zwei Methoden: eine Methode, die die Anforderung direkt ausführt, und eine Methode zum Generieren einer Antwort für den Benutzer.
Wenn beispielsweise der Klasse "request_production_schedule" ein Befehl zugewiesen wird, wird ein Objekt der RequestOilChart-Klasse erstellt, das Informationen zur Ölförderung aus der Datenbank entlädt. Dedizierte benannte Entitäten (z. B. Bohrloch- und Feldnamen) werden verwendet, um Slots in Abfragen zu füllen, um auf die Datenbank oder den Software-Kernel zuzugreifen. Der Assistent antwortet mit Hilfe vorbereiteter Vorlagen, deren Leerzeichen mit den Werten der hochgeladenen Daten gefüllt sind.

Ein Beispiel für einen Assistenten-Prototyp.
Sprachsynthese

Funktionsweise der verketteten Sprachsynthese
Der in der vorherigen Phase generierte Benutzerbenachrichtigungstext wird auf dem Bildschirm angezeigt und auch als Eingabe für das Modul für die mündliche Sprachsynthese verwendet. Die Sprachgenerierung erfolgt über die RHVoice- Bibliothek... Mit der GNU LGPL v2.1-Lizenz kann das Framework als Bestandteil kommerzieller Software verwendet werden. Die Hauptkomponenten des Sprachsynthesesystems sind der Sprachprozessor, der den eingegebenen Text verarbeitet. Der Text wird normalisiert: Die Zahlen werden auf schriftliche Darstellung reduziert, Abkürzungen werden entschlüsselt usw. Anschließend wird unter Verwendung des Aussprachewörterbuchs eine Transkription für den Text erstellt, die dann an den Eingang des akustischen Prozessors übertragen wird. Diese Komponente ist für die Auswahl von Tonelementen aus der Sprachdatenbank, die Verkettung der ausgewählten Elemente und die Verarbeitung des Tonsignals verantwortlich.
Alles zusammenfügen
Damit sind alle Komponenten des Sprachassistenten bereit. Es bleibt nur, sie in der richtigen Reihenfolge zu "sammeln" und zu testen. Wie bereits erwähnt, ist jedes Modul ein Microservice. Das RabbitMQ-Framework wird als Bus zum Verbinden aller Module verwendet. Die Abbildung zeigt deutlich die interne Arbeit des Assistenten am Beispiel einer typischen Benutzeranforderung:
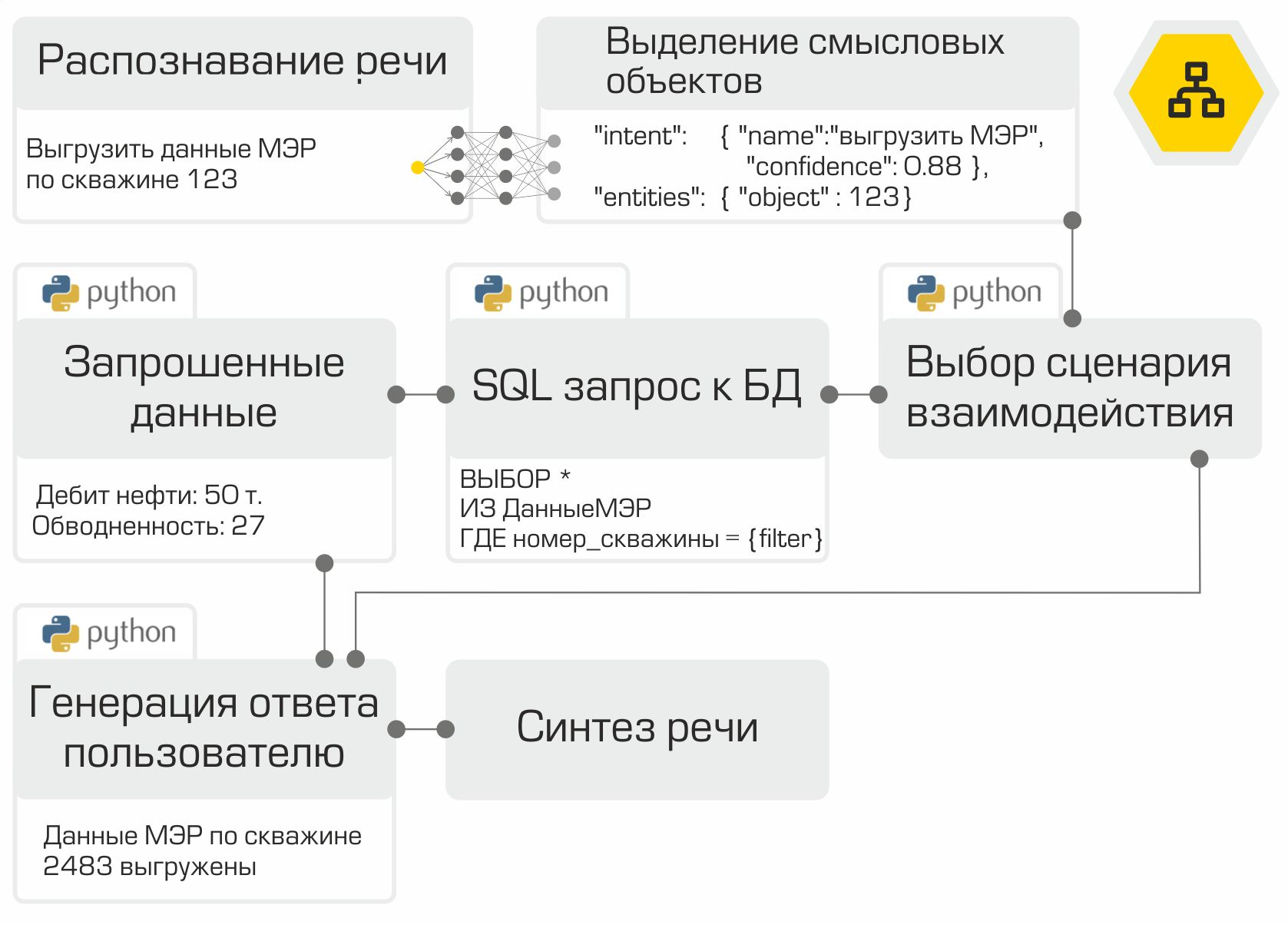
Die erstellte Lösung ermöglicht die Platzierung der gesamten Infrastruktur im Netzwerk des Unternehmens. Die lokale Informationsverarbeitung ist der Hauptvorteil des Systems. Sie müssen jedoch für die Autonomie bezahlen, da Sie selbst Daten sammeln, Modelle trainieren und testen müssen, anstatt die Macht der Top-Anbieter auf dem Markt für digitale Assistenten zu nutzen.
Derzeit integrieren wir den Assistenten in eines unserer Produkte.
Wie bequem wird es sein, mit nur einer Phrase nach Ihrem Brunnen oder Ihrem Lieblingsbusch zu suchen!
In der nächsten Phase ist geplant, Feedback von Benutzern zu sammeln und zu analysieren. Es ist auch geplant, die vom Assistenten erkannten und ausgeführten Befehle zu erweitern.
Das im Artikel beschriebene Projekt ist bei weitem nicht das einzige Beispiel für den Einsatz maschineller Lernmethoden in unserem Unternehmen. So werden beispielsweise mithilfe der Datenanalyse automatisch Kandidatenbohrungen für geologische und technische Maßnahmen ausgewählt, mit denen die Ölförderung stimuliert werden soll. In einem der kommenden Artikel werden wir Ihnen erzählen, wie wir dieses coole Problem gelöst haben. Abonnieren Sie unseren Blog, um ihn nicht zu verpassen!