
Einführung
Google Dorks oder Google Hacking ist eine Technik, mit der Medien, Ermittler, Sicherheitsingenieure und andere Personen verschiedene Suchmaschinen abfragen, um versteckte Informationen und Schwachstellen zu entdecken, die auf öffentlichen Servern gefunden werden können. Es ist eine Technik, bei der herkömmliche Website-Suchanfragen in vollem Umfang verwendet werden, um die auf der Oberfläche verborgenen Informationen zu bestimmen.
Wie funktioniert Google Dorking?
Dieses Beispiel für das Sammeln und Analysieren von Informationen als OSINT-Tool ist keine Google-Sicherheitsanfälligkeit oder ein Gerät zum Hacken von Website-Hosting. Im Gegenteil, es handelt sich um einen herkömmlichen Datenabrufprozess mit erweiterten Funktionen. Dies ist nicht neu, da es eine große Anzahl von Websites gibt, die über ein Jahrzehnt alt sind und als Repositories zum Lernen und Verwenden von Google Hacking dienen.
Während Suchmaschinen Kopfzeilen und Seiteninhalte indizieren, speichern und für optimale Suchanfragen miteinander verknüpfen. Leider sind die Web-Spider jeder Suchmaschine so konfiguriert, dass sie absolut alle gefundenen Informationen indizieren. Obwohl die Administratoren der Webressourcen nicht die Absicht hatten, dieses Material zu veröffentlichen.
Das Interessanteste an Google Dorking ist jedoch die große Menge an Informationen, die jedem beim Erlernen des Google-Suchprozesses helfen können. Kann Neuankömmlingen helfen, vermisste Verwandte zu finden, oder kann lehren, wie Informationen zu ihrem eigenen Vorteil extrahiert werden. Im Allgemeinen ist jede Ressource auf ihre Weise interessant und erstaunlich und kann jedem helfen, was genau er sucht.
Welche Informationen kann ich über Dorks finden?
Angefangen von Fernzugriffssteuerungen verschiedener Fabrikmaschinen bis hin zu Konfigurationsschnittstellen kritischer Systeme. Es wird davon ausgegangen, dass niemand jemals eine große Menge an Informationen im Internet finden wird.
Schauen wir es uns jedoch der Reihe nach an. Stellen Sie sich eine neue CCTV-Kamera vor, mit der Sie sie jederzeit live auf Ihrem Telefon ansehen können. Sie richten die App über WLAN ein, stellen eine Verbindung her und laden die App herunter, um die Anmeldung der Überwachungskamera zu authentifizieren. Danach können Sie von überall auf der Welt auf dieselbe Kamera zugreifen.
Im Hintergrund sieht nicht alles so einfach aus. Die Kamera sendet eine Anfrage an den chinesischen Server und spielt das Video in Echtzeit ab. So können Sie sich anmelden und den auf dem Server in China gehosteten Video-Feed von Ihrem Telefon aus öffnen. Für diesen Server ist möglicherweise kein Kennwort erforderlich, um von Ihrer Webcam aus auf den Feed zuzugreifen, sodass er für alle öffentlich verfügbar ist, die nach dem auf der Kameraansichtseite enthaltenen Text suchen.
Und leider ist Google rücksichtslos effizient darin, Geräte im Internet zu finden, die auf HTTP- und HTTPS-Servern ausgeführt werden. Und da die meisten dieser Geräte eine Art Webplattform zum Anpassen enthalten, bedeutet dies, dass viele Dinge, die nicht für Google vorgesehen waren, dort landen.
Der mit Abstand schwerwiegendste Dateityp ist der, der die Anmeldeinformationen der Benutzer oder des gesamten Unternehmens enthält. Dies geschieht normalerweise auf zwei Arten. Im ersten Fall ist der Server falsch konfiguriert und stellt seine Verwaltungsprotokolle oder Protokolle der Öffentlichkeit im Internet zur Verfügung. Wenn Kennwörter geändert werden oder der Benutzer sich nicht anmelden kann, können diese Archive zusammen mit Anmeldeinformationen verloren gehen.
Die zweite Option tritt auf, wenn Konfigurationsdateien mit denselben Informationen (Anmeldungen, Kennwörter, Datenbanknamen usw.) öffentlich verfügbar werden. Diese Dateien müssen vor jeglichem öffentlichen Zugriff verborgen werden, da sie häufig wichtige Informationen hinterlassen. Jeder dieser Fehler kann dazu führen, dass ein Angreifer diese Lücken findet und alle benötigten Informationen erhält.
Dieser Artikel beschreibt die Verwendung von Google Dorks, um nicht nur zu zeigen, wie alle diese Dateien gefunden werden, sondern auch, wie anfällig Plattformen sein können, die Informationen in Form einer Liste mit Adressen, E-Mails, Bildern und sogar einer Liste öffentlich verfügbarer Webcams enthalten.
Analysieren von Suchoperatoren
Dorking kann in verschiedenen Suchmaschinen verwendet werden, nicht nur in Google. Im täglichen Gebrauch nehmen Suchmaschinen wie Google, Bing, Yahoo und DuckDuckGo eine Suchabfrage oder eine Suchabfragezeichenfolge und geben relevante Ergebnisse zurück. Dieselben Systeme sind auch so programmiert, dass sie fortgeschrittenere und komplexere Operatoren akzeptieren, die diese Suchbegriffe stark einschränken. Ein Operator ist ein Schlüsselwort oder eine Phrase, die für eine Suchmaschine eine besondere Bedeutung hat. Beispiele für häufig verwendete Operatoren sind: "inurl", "intext", "site", "feed", "language". Auf jeden Operator folgt ein Doppelpunkt, gefolgt von der entsprechenden Schlüsselphrase oder den entsprechenden Schlüsselphrasen.
Mit diesen Operatoren können Sie nach spezifischeren Informationen suchen, z. B. nach bestimmten Textzeilen auf Seiten einer Website oder nach Dateien, die unter einer bestimmten URL gehostet werden. Google Dorking kann unter anderem auch versteckte Anmeldeseiten, Fehlermeldungen mit Informationen zu verfügbaren Sicherheitslücken und freigegebene Dateien finden. Der Hauptgrund ist, dass der Website-Administrator möglicherweise einfach vergessen hat, den öffentlichen Zugriff auszuschließen.
Der praktischste und gleichzeitig interessanteste Google-Dienst ist die Möglichkeit, nach gelöschten oder archivierten Seiten zu suchen. Dies kann mit dem Operator "cache:" erfolgen. Der Operator arbeitet so, dass er die gespeicherte (gelöschte) Version der im Google-Cache gespeicherten Webseite anzeigt. Die Syntax für diesen Operator wird hier gezeigt:
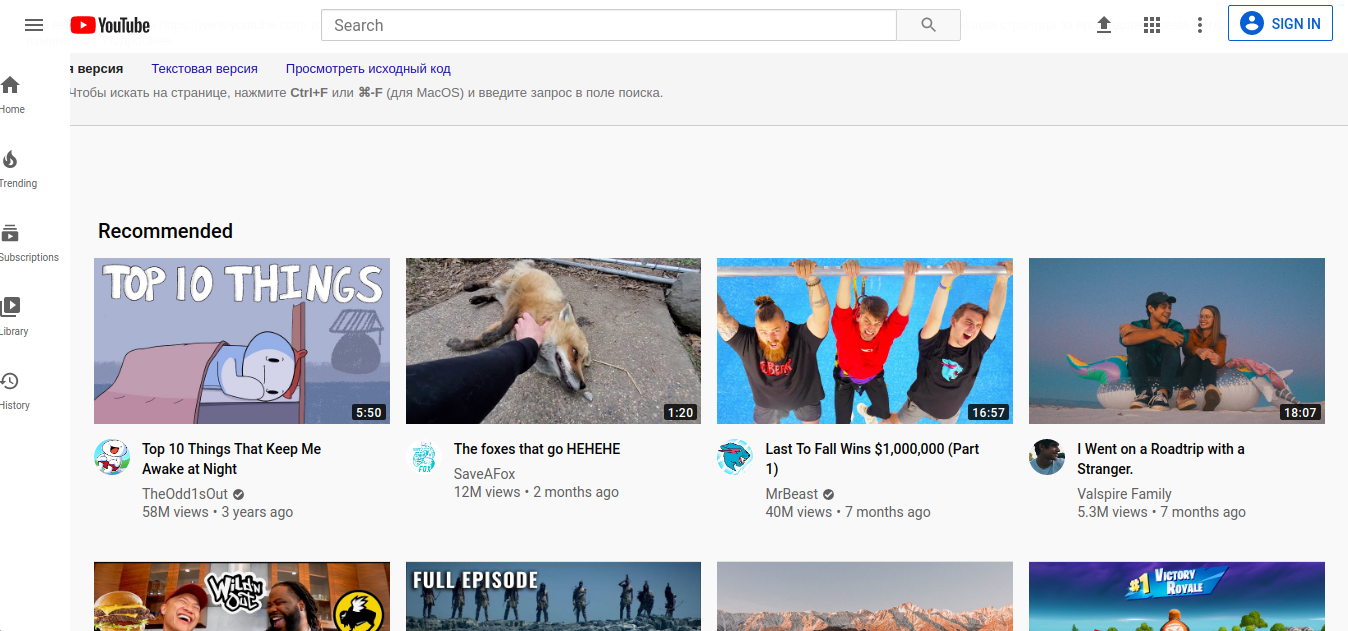
Cache: www.youtube.com
Nach der obigen Anfrage an Google wird der Zugriff auf die vorherige oder veraltete Version der Youtube-Webseite bereitgestellt. Mit dem Befehl können Sie die Vollversion der Seite, die Textversion oder die Seitenquelle selbst (vollständiger Code) aufrufen. Die genaue Uhrzeit (Datum, Stunde, Minute, Sekunde) der von der Google-Spinne vorgenommenen Indizierung wird ebenfalls angegeben. Die Seite wird als Grafikdatei angezeigt, obwohl die Suche auf der Seite selbst auf dieselbe Weise wie auf einer normalen HTML-Seite ausgeführt wird (die Tastenkombination lautet STRG + F). Die Ergebnisse des Befehls "cache:" hängen davon ab, wie oft die Webseite von Google indiziert wurde. Wenn der Entwickler selbst das Kennzeichen mit einer bestimmten Häufigkeit von Besuchen im Kopf des HTML-Dokuments setzt, erkennt Google die Seite als sekundär und ignoriert sie normalerweise zugunsten des PageRank-Verhältnisses.Dies ist der Hauptfaktor für die Häufigkeit der Seitenindizierung. Wenn eine bestimmte Webseite zwischen den Besuchen des Google-Crawlers geändert wurde, wird sie daher nicht mit dem Befehl "cache:" indiziert oder gelesen. Beispiele, die beim Testen dieser Funktion besonders gut funktionieren, sind häufig aktualisierte Blogs, Social Media-Konten und Online-Portale.
Gelöschte Informationen oder Daten, die versehentlich platziert wurden oder irgendwann gelöscht werden müssen, können sehr einfach wiederhergestellt werden. Die Nachlässigkeit des Webplattform-Administrators kann ihn in Gefahr bringen, unerwünschte Informationen zu verbreiten.
Nutzerinformation
Die Suche nach Informationen über Benutzer wird mithilfe erweiterter Operatoren verwendet, die die Suchergebnisse genau und detailliert machen. Der Operator "@" dient zur Suche nach indizierenden Benutzern in sozialen Netzwerken: Twitter, Facebook, Instagram. Am Beispiel derselben polnischen Universität finden Sie ihren offiziellen Vertreter auf einer der sozialen Plattformen, der diesen Operator wie folgt verwendet:
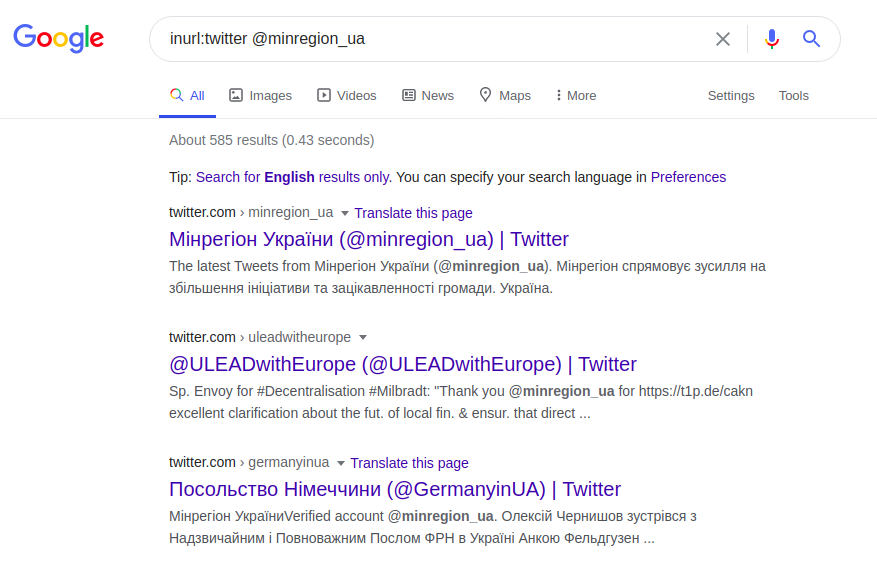
inurl: twitter @minregion_ua
Diese Twitter-Anfrage findet den Benutzer "minregion_ua". Unter der Annahme, dass der Ort oder Name der Arbeit des gesuchten Benutzers (das Ministerium für die Entwicklung der Gemeinschaften und Gebiete der Ukraine) und sein Name bekannt sind, können Sie eine spezifischere Anfrage stellen. Und anstatt mühsam die gesamte Webseite der Institution durchsuchen zu müssen, können Sie die richtige Abfrage basierend auf der E-Mail-Adresse stellen und davon ausgehen, dass der Adressname mindestens den Namen des angeforderten Benutzers oder der Institution enthalten muss. Zum Beispiel:
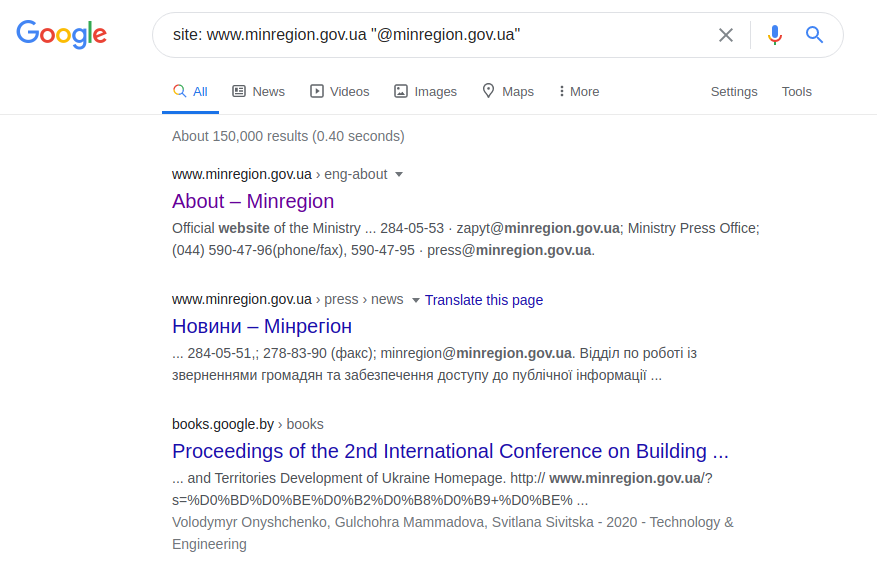
site: www.minregion.gov.ua "@ minregion.ua"
Sie können auch eine weniger komplizierte Methode verwenden und eine Anfrage nur an E-Mail-Adressen senden, wie unten gezeigt, in der Hoffnung auf Glück und mangelnde Professionalität des Webressourcenadministrators.
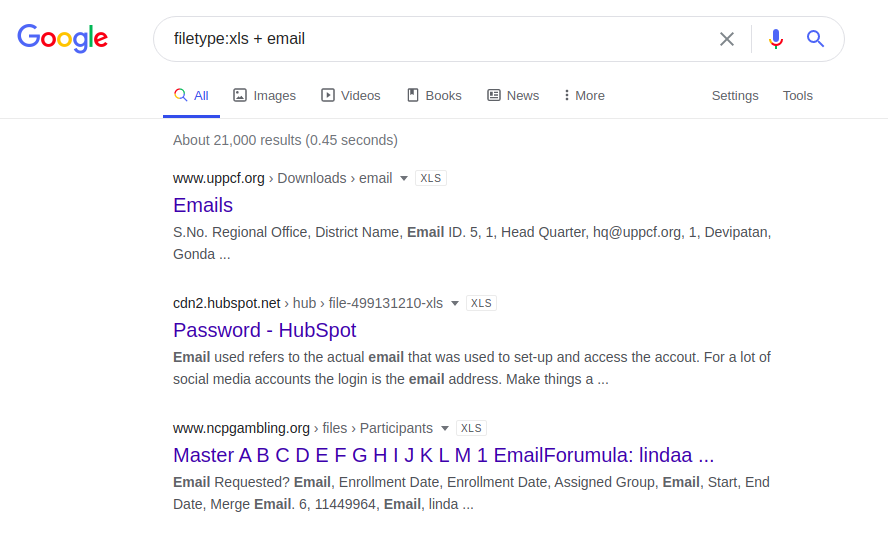
email.xlsx-
Dateityp: xls + email
Zusätzlich können Sie versuchen, E-Mail-Adressen von einer Webseite mit der folgenden Anfrage abzurufen :

site: www.minregion.gov.ua intext: e-mail Bei
der obigen Abfrage wird auf der Webseite des Ministeriums für die Entwicklung der Gemeinschaften und Gebiete der Ukraine nach dem Schlüsselwort "email" gesucht. Das Auffinden von E-Mail-Adressen ist von begrenztem Nutzen und erfordert im Allgemeinen nur wenig Vorbereitung und das Sammeln von Benutzerinformationen im Voraus.
Leider ist die Suche nach indizierten Telefonnummern über das Google-Telefonbuch nur auf die USA beschränkt. Zum Beispiel:
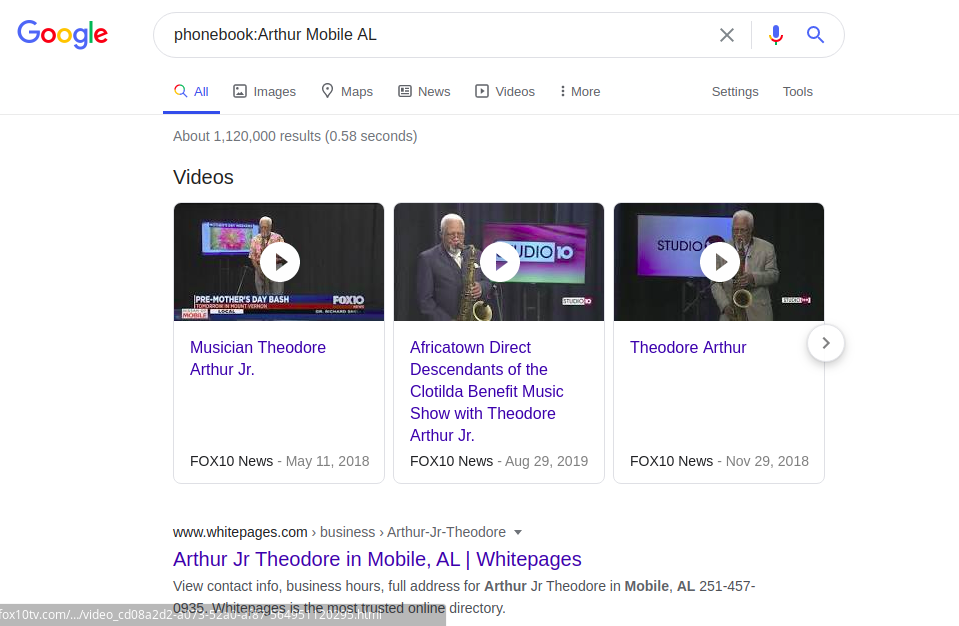
Telefonbuch: Arthur Mobile AL Die
Suche nach Benutzerinformationen ist auch über die Google "Bildsuche" oder die umgekehrte Bildsuche möglich. Auf diese Weise können Sie identische oder ähnliche Fotos auf von Google indizierten Websites finden.
Informationen zu Webressourcen
Google verfügt über mehrere nützliche Operatoren, insbesondere "related:", die eine Liste "ähnlicher" Websites wie die gewünschte anzeigen. Die Ähnlichkeit basiert auf funktionalen Verknüpfungen, nicht auf logischen oder sinnvollen Verknüpfungen.
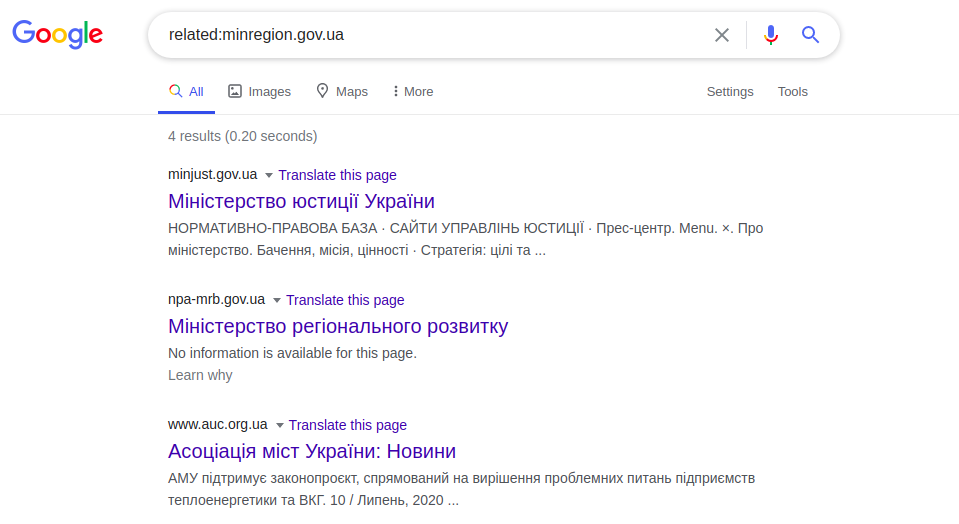
Verwandte: minregion.gov.ua In
diesem Beispiel werden Seiten anderer Ministerien der Ukraine angezeigt . Dieser Operator funktioniert wie die Schaltfläche "Verwandte Seiten" in erweiterten Google-Suchanfragen. Auf die gleiche Weise funktioniert die Anforderung "info:", bei der Informationen auf einer bestimmten Webseite angezeigt werden. Dies sind die spezifischen Informationen einer Webseite, die im Titel der Website () enthalten ist, und zwar in den Meta-Beschreibungs-Tags (<meta name = “Description”). Beispiel:

info: minregion.gov.ua
Eine andere Abfrage, "define:", ist sehr nützlich, um Forschungsarbeiten zu finden . Sie können Definitionen von Wörtern aus Quellen wie Enzyklopädien und Online-Wörterbüchern abrufen. Ein Beispiel für seine Anwendung:
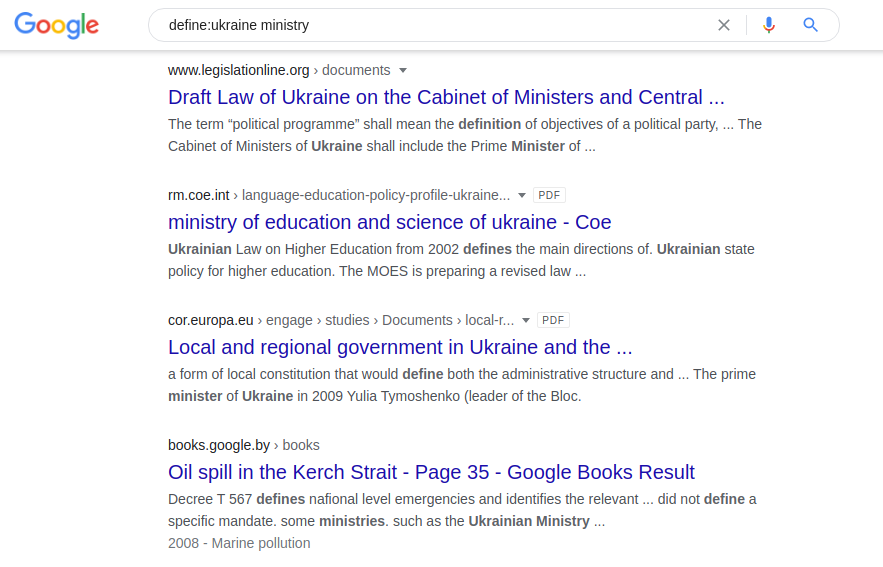
define: ukraine territories Mit dem
Universaloperator - tilde ("~") können Sie nach ähnlichen Wörtern oder Synonymen suchen:
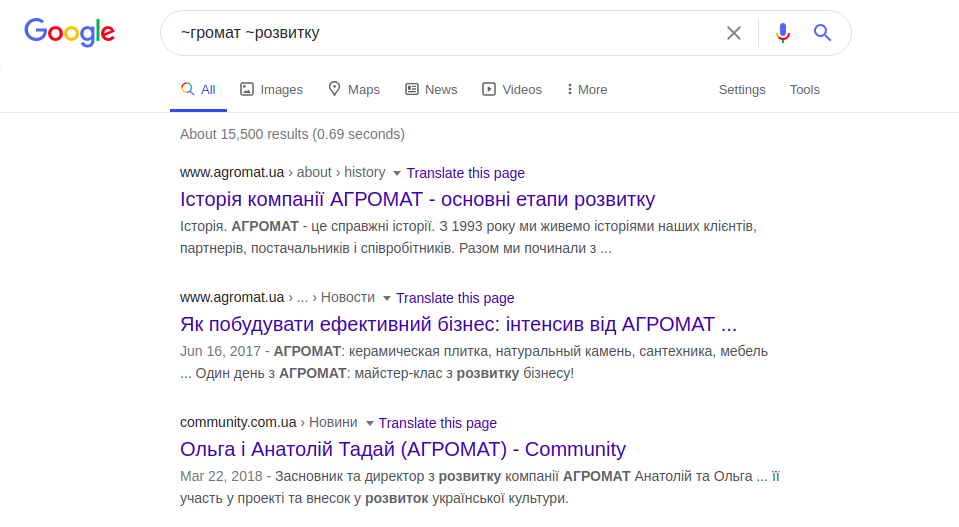
~ Communities ~ Entwicklung
Die obige Abfrage zeigt sowohl Websites mit den Worten "Communities" (Gebiete) und "Entwicklung" (Entwicklung) als auch Websites mit dem Synonym "Communities" an. Der Operator "link:", der die Abfrage ändert, begrenzt den Suchbereich auf die für eine bestimmte Seite angegebenen Links.
link: www.minregion.gov.ua
Dieser Operator zeigt jedoch nicht alle Ergebnisse an und erweitert die Suchkriterien nicht.
Hashtags sind eine Art Identifikationsnummer, mit der Sie Informationen gruppieren können. Sie werden derzeit auf Instagram, VK, Facebook, Tumblr und TikTok verwendet. Mit Google können Sie viele soziale Netzwerke gleichzeitig durchsuchen oder nur empfohlene. Ein Beispiel für eine typische Abfrage für eine Suchmaschine ist:
#
politikavukraini Mit dem Operator "AROUND (n)" können Sie nach zwei Wörtern suchen, die sich in einem Abstand von einer bestimmten Anzahl von Wörtern voneinander befinden. Beispiel:

Ministerium für AROUND (4) der Ukraine
Das Ergebnis der obigen Abfrage ist die Anzeige von Websites, die diese beiden Wörter enthalten ("Ministerium" und "Ukraine"), die jedoch durch vier weitere Wörter voneinander getrennt sind.
Die Suche nach Dateityp ist ebenfalls äußerst nützlich, da Google Inhalte nach dem Format indiziert, in dem sie aufgezeichnet wurden. Verwenden Sie dazu den Operator "Dateityp:". Derzeit wird eine Vielzahl von Dateisuchen durchgeführt. Von allen verfügbaren Suchmaschinen bietet Google die fortschrittlichsten Operatoren für die Suche nach Open Source.
Als Alternative zu den oben genannten Operatoren werden Tools wie Maltego und Oryon OSINT Browser empfohlen. Sie bieten einen automatischen Datenabruf und erfordern keine Kenntnisse spezieller Bediener. Der Mechanismus der Programme ist sehr einfach: Mit der richtigen Abfrage an Google oder Bing werden Dokumente gefunden, die von der für Sie interessanten Institution veröffentlicht wurden, und die Metadaten aus diesen Dokumenten werden analysiert. Eine potenzielle Informationsquelle für solche Programme ist jede Datei mit einer beliebigen Erweiterung, z. B. ".doc", ".pdf", ".ppt", ".odt", ".xls" oder ".jpg".
Darüber hinaus sollte gesagt werden, wie die "Bereinigung ihrer Metadaten" ordnungsgemäß durchgeführt werden muss, bevor Dateien veröffentlicht werden. Einige Web-Guides bieten mindestens mehrere Möglichkeiten, um Metainformationen zu entfernen. Es ist jedoch unmöglich, den besten Weg abzuleiten, da alles von den individuellen Vorlieben des Administrators selbst abhängt. Es wird allgemein empfohlen, die Dateien in einem Format zu schreiben, in dem keine Metadaten nativ gespeichert sind, und die Dateien dann verfügbar zu machen. Im Internet gibt es zahlreiche kostenlose Programme zur Bereinigung von Metadaten, hauptsächlich für Bilder. ExifCleaner kann als eines der wünschenswertesten angesehen werden. Bei Textdateien wird dringend empfohlen, die Bereinigung manuell durchzuführen.
Informationen, die von den Eigentümern der Website unwissentlich hinterlassen wurden
Von Google indizierte Ressourcen bleiben öffentlich (z. B. interne Dokumente und Unternehmensmaterialien, die auf dem Server verbleiben), oder sie werden zur Vereinfachung von denselben Personen (z. B. Musikdateien oder Filmdateien) belassen. Die Suche nach solchen Inhalten kann mit Google auf viele verschiedene Arten erfolgen, und am einfachsten ist es, nur zu raten. Wenn sich beispielsweise in einem bestimmten Verzeichnis die Dateien 5.jpg, 8.jpg und 9.jpg befinden, können Sie vorhersagen, dass Dateien von 1 bis 4, von 6 bis 7 und sogar mehr vorhanden sind. 9. Daher können Sie auf Materialien zugreifen, die dies nicht sollten sollten in der Öffentlichkeit sein. Eine andere Möglichkeit besteht darin, auf Websites nach bestimmten Arten von Inhalten zu suchen. Sie können nach Musikdateien, Fotos, Filmen und Büchern (E-Books, Hörbücher) suchen.
In einem anderen Fall können dies Dateien sein, die der Benutzer unwissentlich öffentlich zugänglich gemacht hat (z. B. Musik auf einem FTP-Server für den eigenen Gebrauch). Diese Informationen können auf zwei Arten abgerufen werden: mit dem Operator "filetype:" oder dem Operator "inurl:". Zum Beispiel:
Dateityp: doc site: gov.ua
site: www.minregion.gov.ua filetype: pdf
site: www.minregion.gov.ua inurl: doc
Sie können auch nach Programmdateien suchen, indem Sie eine Suchabfrage verwenden und die gewünschte Datei nach ihrer Erweiterung filtern:
Dateityp: iso
Informationen zur Struktur von Webseiten
Um die Struktur einer bestimmten Webseite anzuzeigen und ihre gesamte Struktur anzuzeigen, die dem Server und seinen Schwachstellen in Zukunft helfen wird, können Sie dies nur mit dem Operator "site:" tun. Lassen Sie uns den folgenden Satz analysieren:
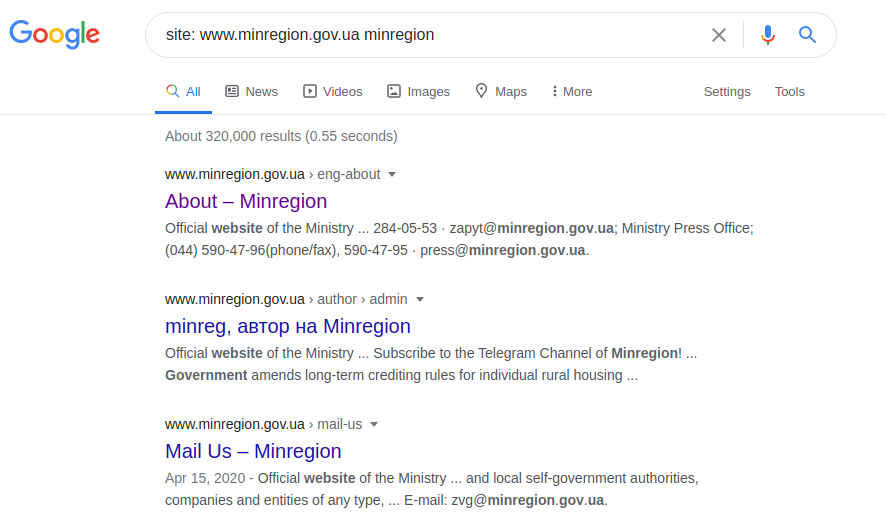
site: www.minregion.gov.ua minregion
Wir beginnen mit der Suche nach dem Wort "minregion" in der Domain "www.minregion.gov.ua". Jede Website dieser Domain (Google sucht sowohl im Text als auch in Überschriften und im Titel der Website) enthält dieses Wort. So erhalten Sie die vollständige Struktur aller Sites für diese bestimmte Domain. Sobald die Verzeichnisstruktur verfügbar ist, kann mit der folgenden Abfrage ein genaueres Ergebnis erzielt werden (obwohl dies möglicherweise nicht immer der Fall ist):
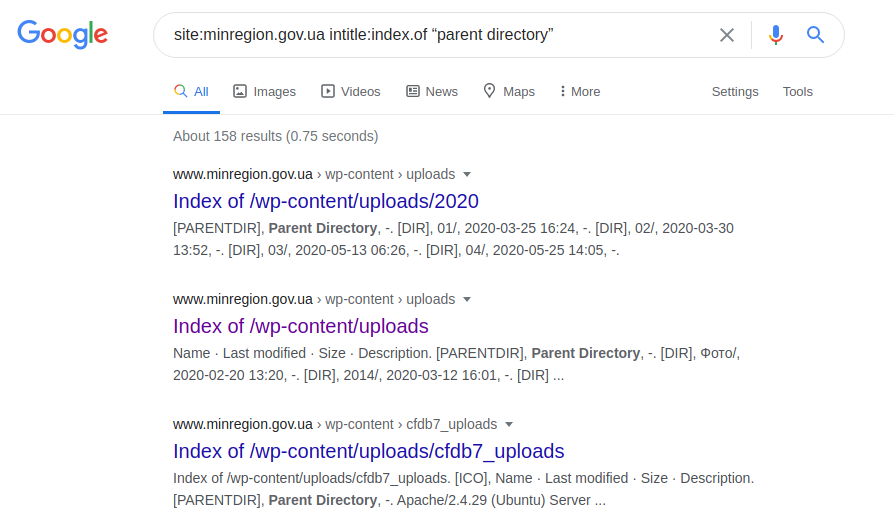
site: minregion.gov.ua intitle: index.of "Elternverzeichnis"
Zeigt die am wenigsten geschützten Unterdomänen von "minregion.gov.ua" an, manchmal mit der Möglichkeit, das gesamte Verzeichnis zusammen mit möglichen Datei-Uploads zu durchsuchen. Daher gilt eine solche Anforderung natürlich nicht für alle Domänen, da sie geschützt oder unter der Kontrolle eines anderen Servers ausgeführt werden können.
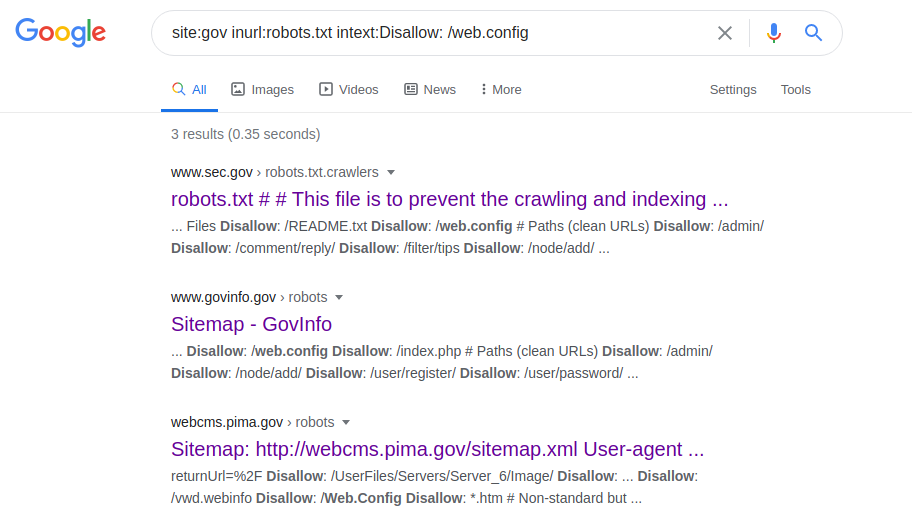
site: gov inurl: robots.txt intext: Disallow: /web.config Mit
diesem Operator können Sie auf die Konfigurationsparameter verschiedener Server zugreifen. Wechseln Sie nach der Anforderung zur Datei robots.txt, suchen Sie den Pfad zu "web.config" und gehen Sie zum angegebenen Dateipfad. Um den Servernamen, seine Version und andere Parameter (z. B. Ports) abzurufen, wird die folgende Anforderung gestellt:
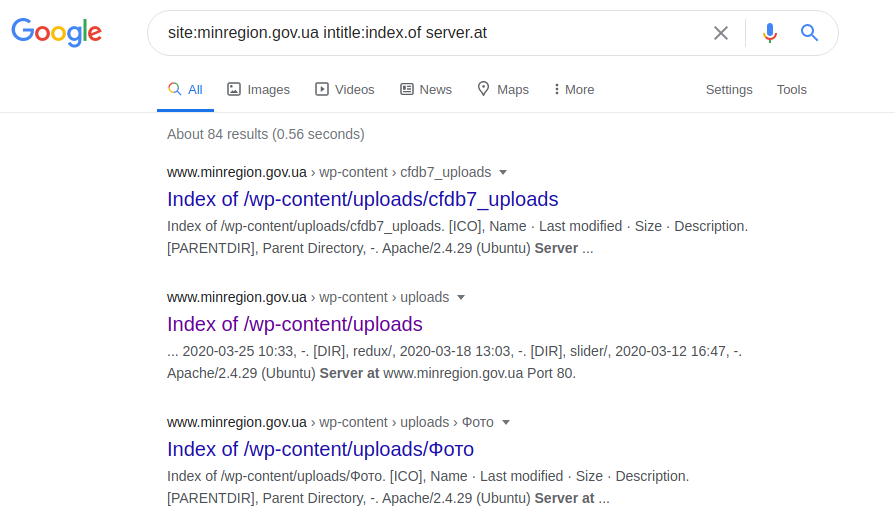
site: gosstandart.gov.by intitle: index.of server.at
Jeder Server hat auf seinen Homepages einige eindeutige Ausdrücke, z. B. Internet Information Service (IIS):
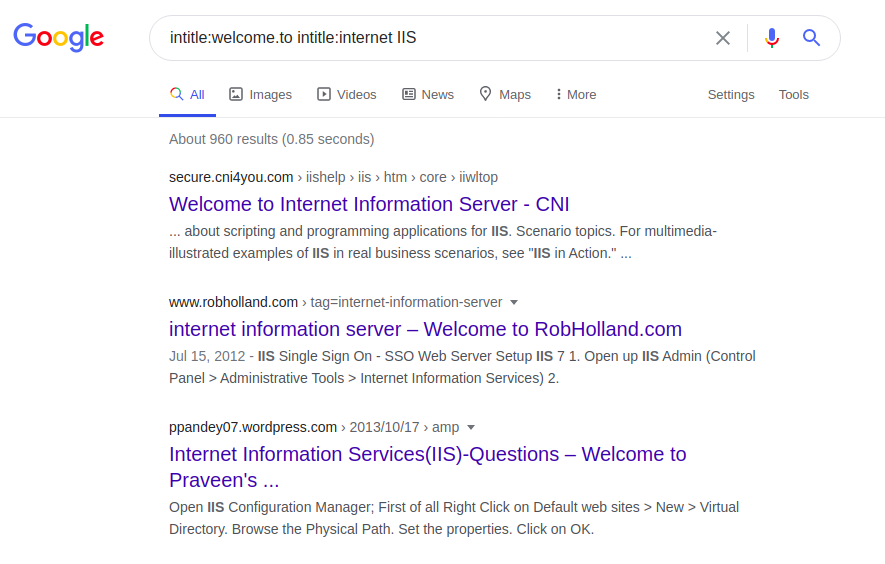
intitle: welcome.to intitle: internet IIS
Die Definition des Servers selbst und der darin verwendeten Technologien hängt nur vom Einfallsreichtum der gestellten Abfrage ab. Sie können dies beispielsweise versuchen, indem Sie eine technische Spezifikation, ein Handbuch oder sogenannte Hilfeseiten erläutern. Um diese Funktion zu demonstrieren, können Sie die folgende Abfrage verwenden:
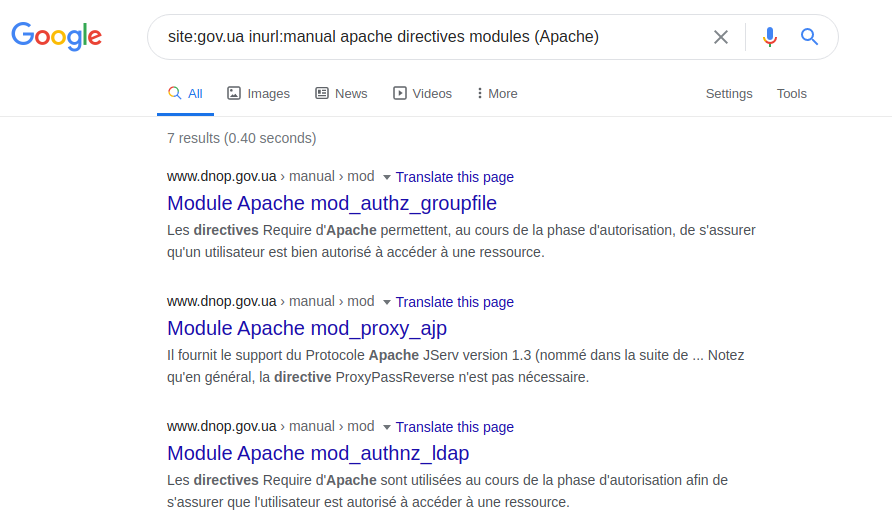
site: gov.ua inurl: manuelle Apache-Direktiven-Module (Apache) Der
Zugriff kann beispielsweise dank der Datei mit SQL-Fehlern erweitert werden:
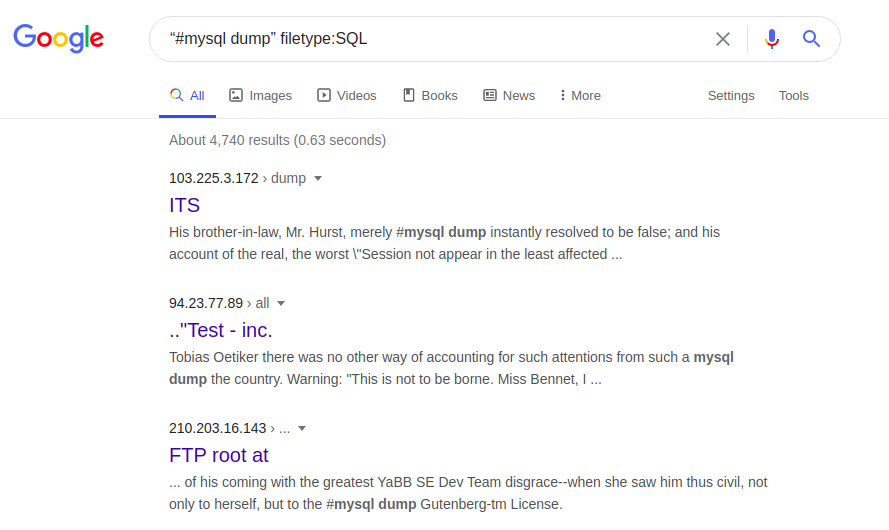
Dateityp "#Mysql dump": SQL-
Fehler in einer SQL-Datenbank können insbesondere Informationen über die Struktur und den Inhalt von Datenbanken liefern. Auf die gesamte Webseite, ihre Originalversion und / oder ihre aktualisierten Versionen kann wiederum über die folgende Anforderung zugegriffen werden:
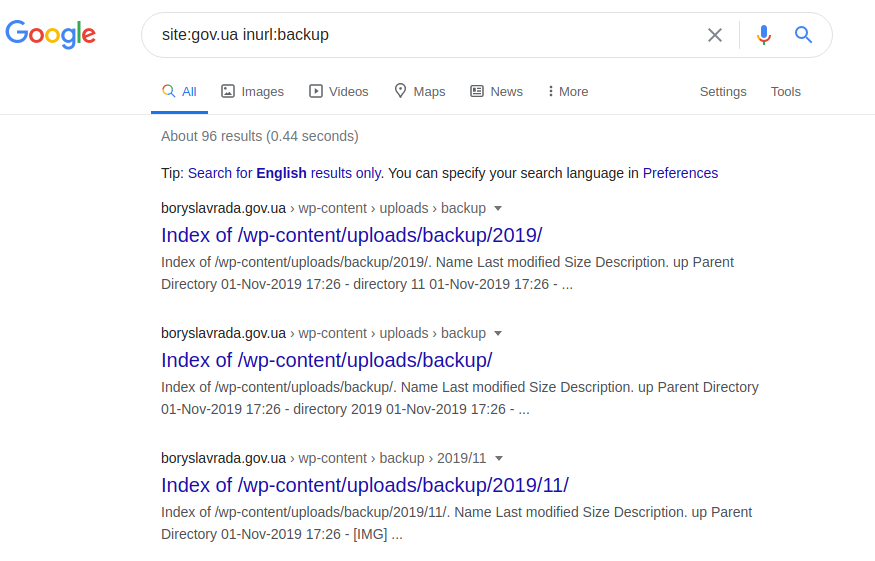
site: gov.ua inurl: backup
site: gov.ua inurl: backup intitle: index.of inurl: admin
Derzeit liefert die Verwendung der oben genannten Operatoren selten die erwarteten Ergebnisse, da sie von sachkundigen Benutzern im Voraus blockiert werden können.
Mit dem FOCA-Programm können Sie außerdem denselben Inhalt finden wie bei der Suche nach den oben genannten Operatoren. Zu Beginn benötigt das Programm den Namen des Domänennamens. Anschließend analysiert es die Struktur der gesamten Domäne und aller anderen Subdomänen, die mit den Servern einer bestimmten Institution verbunden sind. Diese Informationen finden Sie im Dialogfeld auf der Registerkarte Netzwerk:
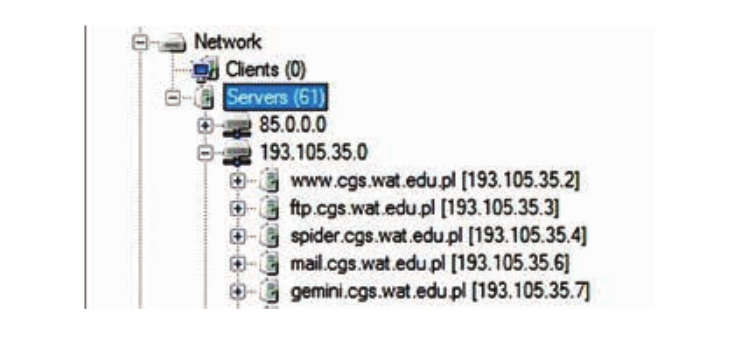
Auf diese Weise kann ein potenzieller Angreifer Daten abfangen, die von Webadministratoren, internen Dokumenten und Unternehmensmaterialien hinterlassen wurden, selbst auf einem versteckten Server.
Wenn Sie noch mehr Informationen über alle möglichen Indizierung Betreiber wissen möchten , können Sie die Zieldatenbank aller Google Dorking Betreiber überprüfen hier . Sie können sich auch mit einem interessanten Projekt auf GitHub vertraut machen, das alle gängigen und anfälligen URL-Links gesammelt hat, und versuchen, nach etwas zu suchen, das für Sie interessant ist. Sie können es hier unter diesem Link sehen .
Ergebnisse kombinieren und erzielen
Im Folgenden finden Sie eine kleine Sammlung häufig verwendeter Google-Operatoren. In einer Kombination aus verschiedenen zusätzlichen Informationen und denselben Befehlen zeigen die Suchergebnisse einen detaillierteren Blick auf den Prozess des Erhaltens vertraulicher Informationen. Schließlich kann dieser Prozess des Sammelns von Informationen für eine normale Suchmaschine von Google sehr interessant sein.
Suchen Sie auf der Website des US-amerikanischen Ministeriums für Heimatschutz und Cybersicherheit nach Budgets.
Die folgende Kombination enthält alle öffentlich indizierten Excel-Tabellen, die das Wort "Budget" enthalten:
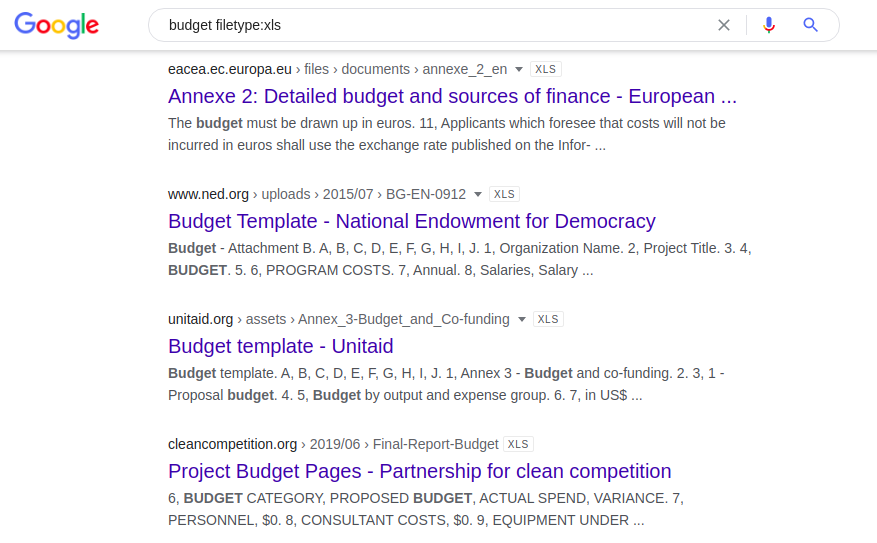
Budget-Dateityp: xls
Da der Operator "Dateityp:" nicht automatisch verschiedene Versionen desselben Dateiformats erkennt (z. B. doc versus odt oder xlsx versus csv), muss jedes dieser Formate separat aufgeteilt werden:
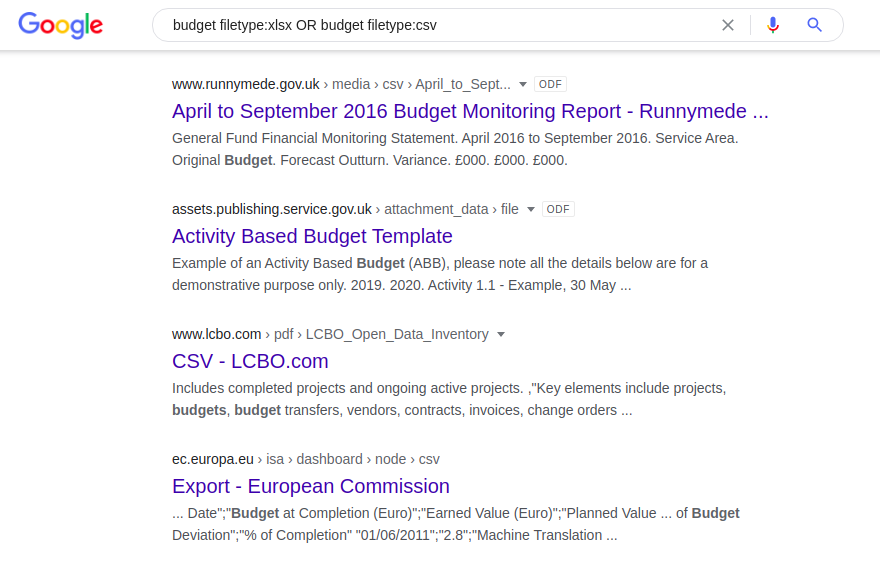
Budget-Dateityp: xlsx ODER Budget-Dateityp: csv Der
nachfolgende Dork gibt PDF-Dateien auf der NASA-Website zurück:
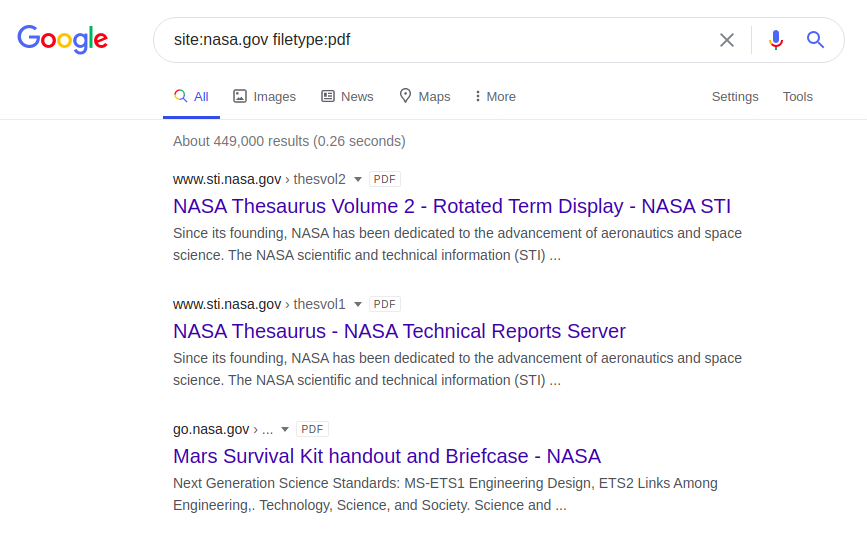
site: nasa.gov Dateityp: pdf
Ein weiteres interessantes Beispiel für die Verwendung eines Dork mit dem Schlüsselwort "budget" ist die Suche nach US-amerikanischen Cybersicherheitsdokumenten im "pdf" -Format auf der offiziellen Website des Department of Home Defense.
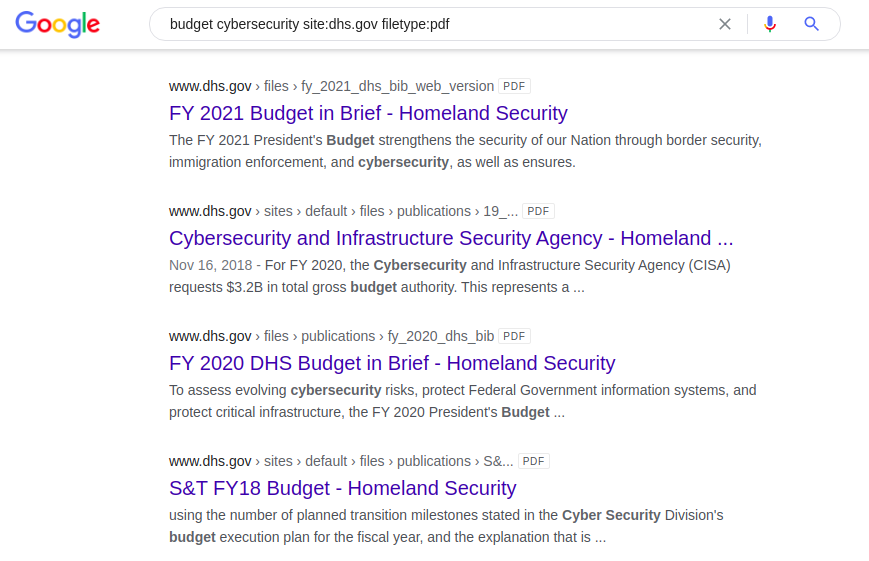
Budget Cybersicherheits-Website: dhs.gov Dateityp: pdf Dieselbe
Dork-Anwendung, aber dieses Mal gibt die Suchmaschine XLSX-Tabellen mit dem Wort "Budget" auf der Website des US-Heimatschutzministeriums zurück:
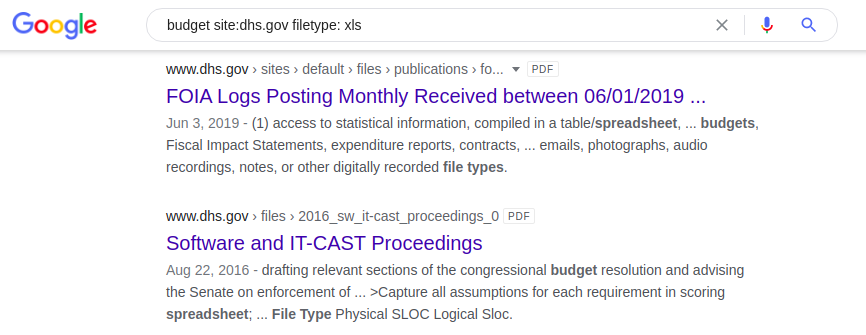
Budget-Site: dhs.gov Dateityp: xls
Suche nach Passwörtern
Die Suche nach Informationen über Login und Passwort kann hilfreich sein, um nach Schwachstellen in Ihrer eigenen Ressource zu suchen. Andernfalls werden Kennwörter in freigegebenen Dokumenten auf Webservern gespeichert. Sie können die folgenden Kombinationen in verschiedenen Suchmaschinen ausprobieren:
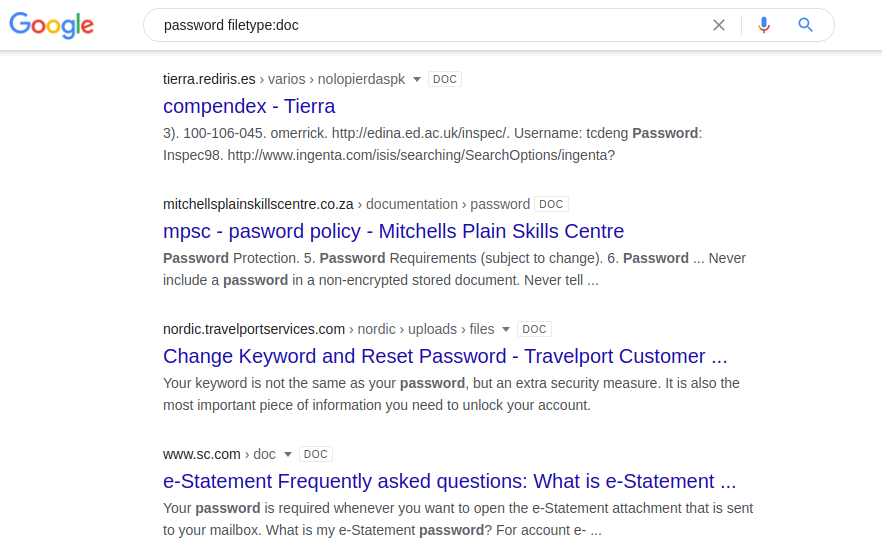
Kennwortdateityp: doc / docx / pdf / xls
Kennwortdateityp: doc / docx / pdf / xls Site: [Site-Name]
Wenn Sie versuchen, eine solche Abfrage in eine andere Suchmaschine einzugeben, können Sie völlig andere Ergebnisse erhalten. Wenn Sie diese Abfrage beispielsweise ohne den Begriff "Site: [Site Name] " ausführen , gibt Google Dokumentergebnisse zurück, die die tatsächlichen Benutzernamen und Kennwörter einiger amerikanischer High Schools enthalten. Andere Suchmaschinen zeigen diese Informationen nicht auf den ersten Ergebnisseiten an. Wie Sie unten sehen können, sind Yahoo und DuckDuckGo Beispiele.
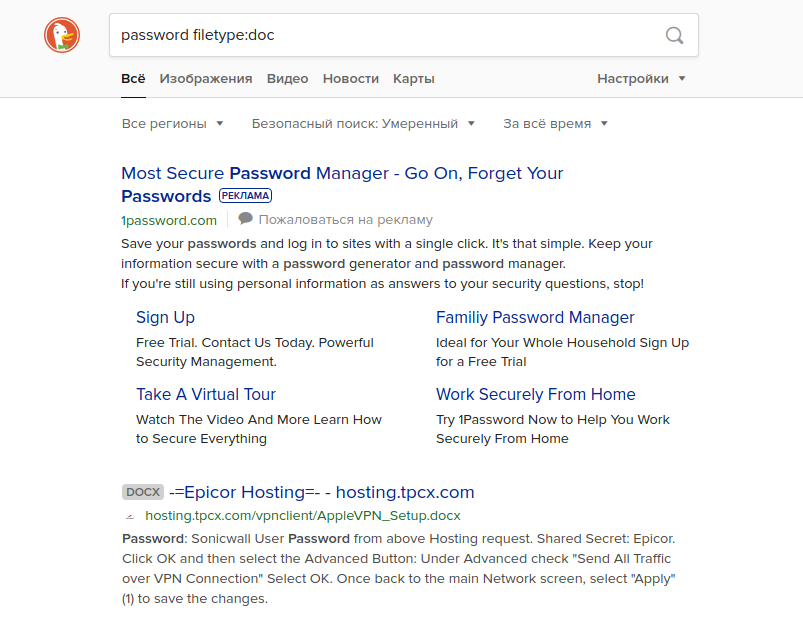
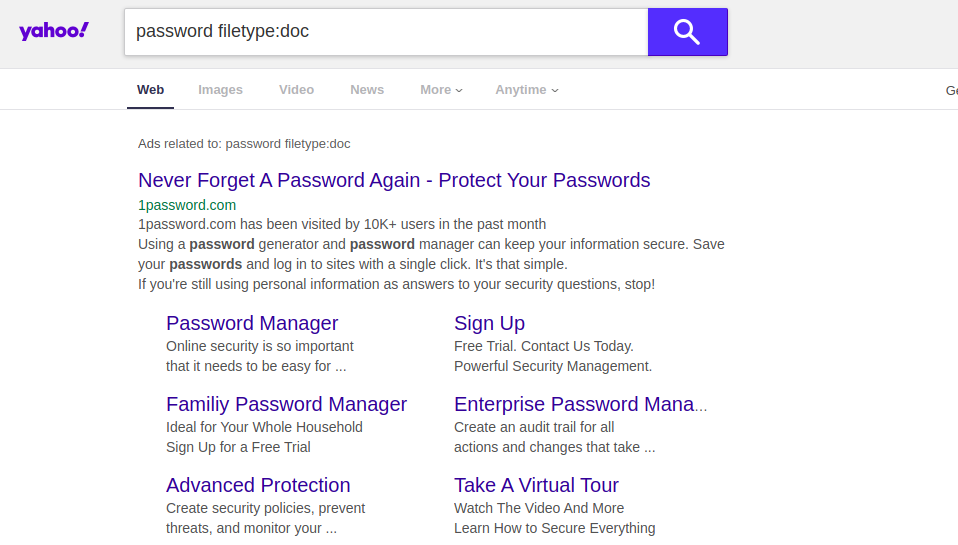
Immobilienpreise in London
Ein weiteres interessantes Beispiel betrifft Informationen über den Preis von Wohnraum in London. Nachfolgend sind die Ergebnisse einer Abfrage aufgeführt, die in vier verschiedenen Suchmaschinen eingegeben wurde:
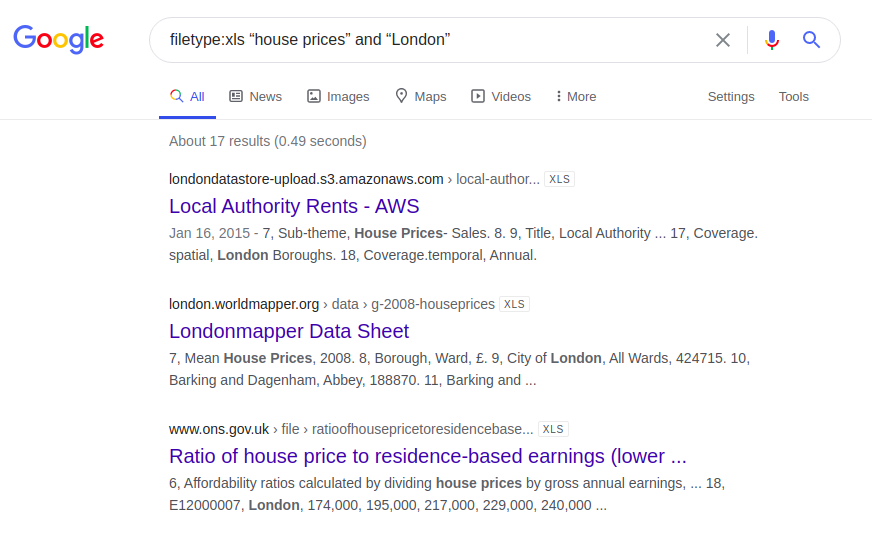
Dateityp: xls "Immobilienpreise" und "London"
Vielleicht haben Sie jetzt Ihre eigenen Ideen und Ideen, auf welche Websites Sie sich bei Ihrer eigenen Suche nach Informationen konzentrieren möchten oder wie Sie Ihre eigene Ressource ordnungsgemäß auf mögliche Schwachstellen überprüfen können ...
Alternative Suchindizierungswerkzeuge
Es gibt auch andere Methoden zum Sammeln von Informationen mit Google Dorking. Sie sind alle Alternativen und dienen als Suchautomatisierung. Im Folgenden schlagen wir vor, einen Blick auf einige der beliebtesten Projekte zu werfen, die keine Sünde sind.
Google Hacking Online
Google Hacking Online ist eine Online-Integration der Google Dorking-Suche nach verschiedenen Daten über eine Webseite mit etablierten Betreibern, die Sie hier finden . Das Tool ist ein einfaches Eingabefeld zum Auffinden der gewünschten IP-Adresse oder URL eines Links zu einer Ressource von Interesse sowie vorgeschlagener Suchoptionen.
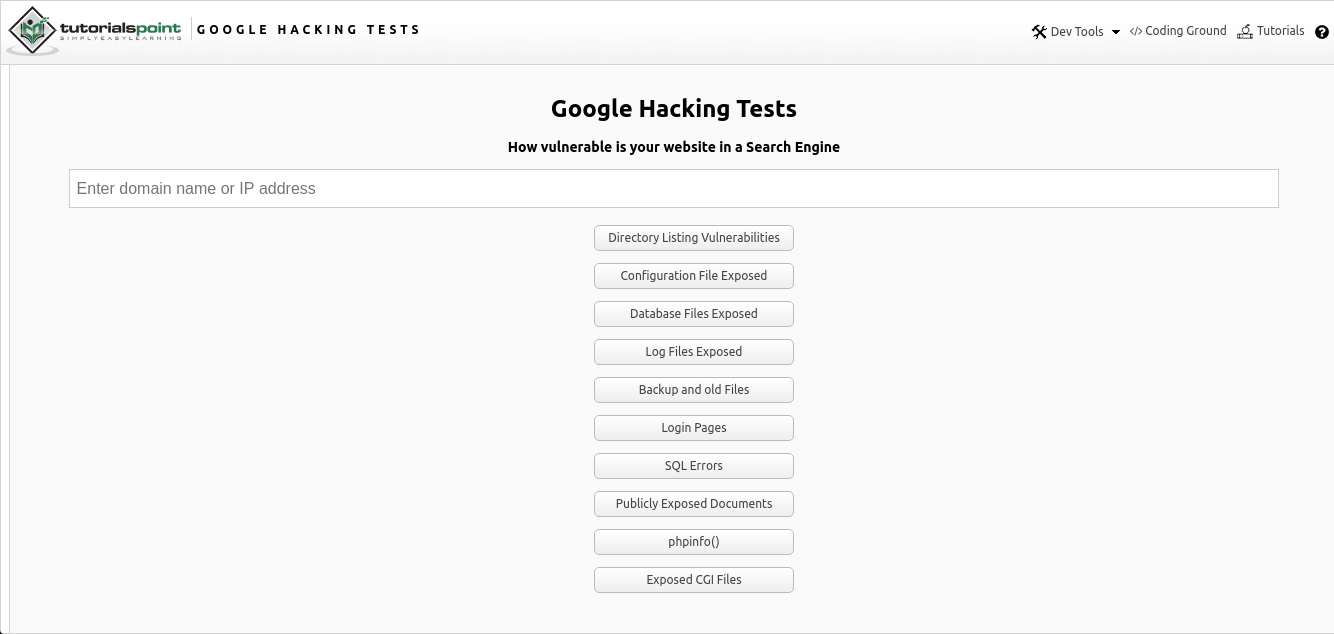
Wie Sie aus dem obigen Bild sehen können, wird die Suche nach mehreren Parametern in Form mehrerer Optionen bereitgestellt:
- Suchen Sie nach öffentlichen und anfälligen Verzeichnissen
- Konfigurationsdateien
- Datenbankdateien
- Protokolle
- Alte Daten und Sicherungsdaten
- Authentifizierungsseiten
- SQL-Fehler
- Öffentlich zugängliche Dokumente
- Informationen zur Server-PHP-Konfiguration ("phpinfo")
- CGI-Dateien (Common Gateway Interface)
Alles funktioniert mit Vanilla JS, das in der Webseitendatei selbst geschrieben ist. Zu Beginn werden die eingegebenen Benutzerinformationen verwendet, nämlich der Hostname oder die IP-Adresse der Webseite. Anschließend wird bei den Bedienern eine Anfrage nach den eingegebenen Informationen gestellt. Ein Link zur Suche nach einer bestimmten Ressource wird in einem neuen Popup-Fenster mit den bereitgestellten Ergebnissen geöffnet.
BinGoo
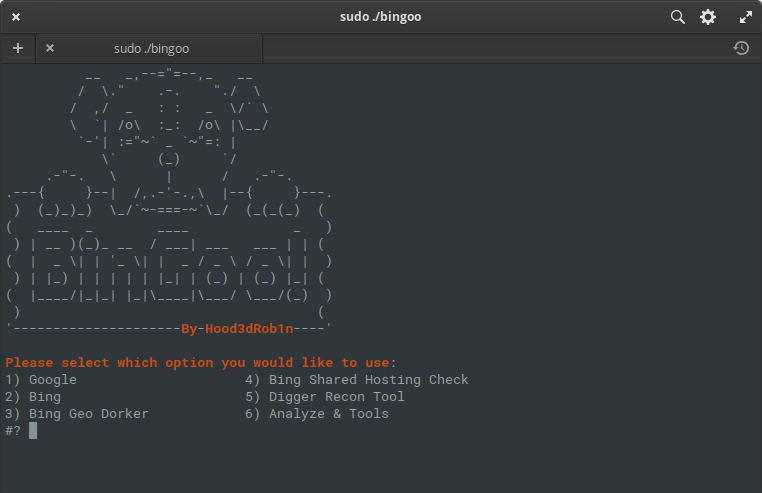
BinGoo ist ein vielseitiges Tool, das in reiner Bash geschrieben wurde. Es verwendet die Suchoperatoren Google und Bing, um eine große Anzahl von Links basierend auf den angegebenen Suchbegriffen zu filtern. Sie können wählen, ob Sie jeweils einen Operator suchen oder einen Operator pro Zeile auflisten und einen Bulk-Scan durchführen möchten. Sobald der erste Erfassungsprozess abgeschlossen ist oder Sie Links auf andere Weise erfasst haben, können Sie mit den Analysetools fortfahren, um nach häufigen Anzeichen von Schwachstellen zu suchen.
Die Ergebnisse werden basierend auf den erhaltenen Ergebnissen ordentlich in geeignete Dateien sortiert. Aber die Analyse hört auch hier nicht auf. Sie können sogar noch weiter gehen und sie mit zusätzlichen SQL- oder LFI-Funktionen ausführen, oder Sie können die SQLMAP- und FIMAP-Wrapper-Tools verwenden, die viel besser funktionieren und genaue Ergebnisse liefern.
Ebenfalls enthalten sind einige praktische Funktionen, die das Leben erleichtern, wie Geodorking basierend auf dem Domänentyp, Ländercodes in der Domain und Shared Hosting Checker, der vorkonfigurierte Bing-Such- und Dork-Listen verwendet, um nach möglichen Schwachstellen auf anderen Websites zu suchen. Ebenfalls enthalten ist eine einfache Suche nach Administrationsseiten basierend auf der bereitgestellten Liste und den Serverantwortcodes zur Bestätigung. Im Allgemeinen ist dies ein sehr interessantes und kompaktes Paket von Werkzeugen, das die Hauptsammlung und Analyse der gegebenen Informationen durchführt! Sie können mit ihm vertraut machen hier .
Pagodo
Der Zweck des Pagodo-Tools ist die passive Indizierung durch Google Dorking-Betreiber, um potenziell gefährdete Webseiten und Anwendungen über das Internet zu erfassen. Das Programm besteht aus zwei Teilen. Das erste ist ghdb_scraper.py, das die Google Dorks-Operatoren abfragt und sammelt, und das zweite, pagodo.py, verwendet die über ghdb_scraper.py gesammelten Operatoren und Informationen und analysiert sie über Google-Abfragen.
Für die Datei pagodo.py ist zunächst eine Liste der Google Dorks-Operatoren erforderlich. Eine ähnliche Datei wird entweder im Repository des Projekts selbst bereitgestellt oder Sie können einfach die gesamte Datenbank über eine einzelne GET-Anforderung mit ghdb_scraper.py abfragen. Und dann kopieren Sie einfach die einzelnen dorks-Anweisungen in eine Textdatei oder fügen Sie sie in json ein, wenn zusätzliche Kontextdaten erforderlich sind.
Um diesen Vorgang auszuführen, müssen Sie den folgenden Befehl eingeben:
python3 ghdb_scraper.py -j -sNachdem eine Datei mit allen erforderlichen Operatoren vorhanden ist, kann sie mit der Option "-g" auf pagodo.py umgeleitet werden, um potenziell anfällige und öffentliche Anwendungen zu erfassen. Die Datei pagodo.py verwendet die "google" -Bibliothek, um diese Websites mit folgenden Operatoren zu finden:
intitle: "ListMail Login" admin -demo
site: example.com
Leider ist der Vorgang so vieler Anfragen (nämlich ~ 4600) über Google einfach wird nicht funktionieren. Google identifiziert Sie sofort als Bot und blockiert die IP-Adresse für einen bestimmten Zeitraum. Es wurden verschiedene Verbesserungen hinzugefügt, damit Suchanfragen organischer aussehen.
Das Google Python-Modul wurde speziell optimiert, um die Randomisierung von Benutzeragenten über Google-Suchanfragen hinweg zu ermöglichen. Diese Funktion ist in Modulversion 1.9.3 verfügbar und ermöglicht es Ihnen, die verschiedenen Benutzeragenten, die für jede Suchabfrage verwendet werden, zufällig zu sortieren. Mit dieser Funktion können Sie verschiedene Browser emulieren, die in einer großen Unternehmensumgebung verwendet werden.
Die zweite Verbesserung konzentriert sich auf die Randomisierung der Zeit zwischen den Suchvorgängen. Die minimale Verzögerung wird mit dem Parameter -e angegeben, und der Jitterfaktor wird verwendet, um der minimalen Anzahl von Verzögerungen Zeit hinzuzufügen. Eine Liste mit 50 Jitters wird generiert und einer davon wird zufällig zur minimalen Latenz für jede Google-Suche hinzugefügt.
self.jitter = numpy.random.uniform(low=self.delay, high=jitter * self.delay, size=(50,))Weiter im Skript wird eine zufällige Zeit aus dem Jitter-Array ausgewählt und zur Verzögerung beim Erstellen von Anforderungen hinzugefügt:
pause_time = self.delay + random.choice (self.jitter)Sie können selbst mit den Werten experimentieren, aber die Standardeinstellungen funktionieren einwandfrei. Bitte beachten Sie, dass der Tool-Prozess mehrere Tage dauern kann (durchschnittlich 3; abhängig von der Anzahl der angegebenen Operatoren und dem Anforderungsintervall). Stellen Sie also sicher, dass Sie Zeit dafür haben.
Um das Tool selbst auszuführen, reicht der folgende Befehl aus, wobei "example.com" der Link zur Website von Interesse ist und "dorks.txt" die von ghdb_scraper.py erstellte Textdatei ist:
python3 pagodo.py -d example.com -g dorks.txt -l 50 -s -e 35.0 -j 1.1Wenn Sie auf diesen Link klicken, können Sie sich mit dem Tool vertraut machen .
Schutzmethoden von Google Dorking
Wichtige Empfehlungen
Google Dorking verfügt wie jedes andere Open Source-Tool über eigene Techniken, um Eindringlinge daran zu hindern, vertrauliche Informationen zu sammeln. Die folgenden Empfehlungen der fünf Protokolle sollten von Administratoren aller Webplattformen und Server befolgt werden, um Bedrohungen durch "Google Dorking" zu vermeiden:
- Systematische Aktualisierung von Betriebssystemen, Diensten und Anwendungen.
- Implementierung und Wartung von Anti-Hacker-Systemen.
- Kenntnis der Google-Roboter und der verschiedenen Suchmaschinenverfahren sowie Informationen zur Validierung solcher Prozesse.
- Entfernen sensibler Inhalte aus öffentlichen Quellen.
- Trennen von öffentlichen und privaten Inhalten und Sperren des Zugriffs auf Inhalte für öffentliche Benutzer.
Konfiguration der Datei .Htaccess und robots.txt
Grundsätzlich werden alle mit "Dorking" verbundenen Schwachstellen und Bedrohungen aufgrund von Nachlässigkeit oder Nachlässigkeit von Benutzern verschiedener Programme, Server oder anderer Webgeräte erzeugt. Daher verursachen die Regeln des Selbstschutzes und des Datenschutzes keine Schwierigkeiten oder Komplikationen.
Um die Verhinderung der Indizierung durch Suchmaschinen sorgfältig anzugehen, sollten Sie zwei Hauptkonfigurationsdateien einer Netzwerkressource beachten: ".htaccess" und "robots.txt". Der erste schützt die angegebenen Pfade und Verzeichnisse mit Passwörtern. Das zweite schließt Verzeichnisse von der Indizierung durch Suchmaschinen aus.
Wenn Ihre eigene Ressource bestimmte Arten von Daten oder Verzeichnissen enthält, die nicht bei Google indiziert werden sollen, sollten Sie zunächst den Zugriff auf Ordner über Kennwörter konfigurieren. Im folgenden Beispiel können Sie deutlich sehen, wie und was genau in die Datei ".htaccess" geschrieben werden soll, die sich im Stammverzeichnis einer Website befindet. Fügen Sie zunächst
einige Zeilen hinzu, wie unten gezeigt:
AuthUserFile /your/directory/here/.htpasswd
AuthGroupFile / dev / null
AuthName "Sicheres Dokument"
AuthType Basic
erfordert Benutzer-Benutzername1
erfordert Benutzer-Benutzername2
erfordert Benutzer-Benutzername3
Geben Sie in der Zeile AuthUserFile den Pfad zum Speicherort der .htaccess-Datei an, die sich in Ihrem Verzeichnis befindet. In den letzten drei Zeilen müssen Sie den entsprechenden Benutzernamen angeben, auf den zugegriffen werden soll. Anschließend müssen Sie ".htpasswd" im selben Ordner wie ".htaccess" erstellen und den folgenden Befehl
ausführen : htpasswd -c .htpasswd Benutzername1
Geben Sie das Kennwort für Benutzername1 zweimal ein. Danach wird eine vollständig saubere Datei ".htpasswd" erstellt aktuelles Verzeichnis und enthält die verschlüsselte Version des Passworts.
Wenn mehrere Benutzer vorhanden sind, müssen Sie jedem von ihnen ein Kennwort zuweisen. Um weitere Benutzer hinzuzufügen, müssen Sie keine neue Datei erstellen. Sie können sie einfach zur vorhandenen Datei hinzufügen, ohne die Option -c mit diesem Befehl zu verwenden:
htpasswd .htpasswd Benutzername2
In anderen Fällen wird empfohlen, eine robots.txt-Datei einzurichten, die für die Indizierung von Seiten einer Webressource verantwortlich ist. Es dient als Leitfaden für jede Suchmaschine, die auf bestimmte Seitenadressen verweist. Und bevor Sie direkt zu der Quelle gehen, nach der Sie suchen, blockiert robots.txt solche Anforderungen entweder oder überspringt sie.
Die Datei selbst befindet sich im Stammverzeichnis einer beliebigen Webplattform, die im Internet ausgeführt wird. Die Konfiguration erfolgt lediglich durch Ändern von zwei Hauptparametern: "User-Agent" und "Disallow". Der erste wählt entweder alle oder einige bestimmte Suchmaschinen aus und markiert sie. Während der zweite notiert, was genau blockiert werden muss (Dateien, Verzeichnisse, Dateien mit bestimmten Erweiterungen usw.). Im Folgenden finden Sie einige Beispiele: Verzeichnis-, Datei- und bestimmte Suchmaschinenausschlüsse, die vom Indizierungsprozess ausgeschlossen sind.
Benutzeragent: *
Nicht zulassen: / cgi-bin /
Benutzeragent: *
Nicht zulassen: /~joe/junk.html
Benutzeragent: Bing Nicht
zulassen: /
Verwenden von Meta-Tags
Außerdem können Einschränkungen für Webspinnen auf einzelnen Webseiten eingeführt werden. Sie können sich auf typischen Websites, Blogs und Konfigurationsseiten befinden. In der HTML-Überschrift müssen sie von einem der folgenden Sätze begleitet werden:
<meta name = "Robots" content = "none" \>
<meta name = "Robots" content = "noindex, nofollow" \>
Wenn Sie einen solchen Eintrag in den Seitenkopf einfügen, indiziert Google Robots keine Sekundär- oder Hauptseite. Diese Zeichenfolge kann auf Seiten eingegeben werden, die nicht indiziert werden sollen. Diese Entscheidung basiert jedoch auf einer gegenseitigen Vereinbarung zwischen den Suchmaschinen und dem Benutzer selbst. Während Google und andere Web-Spider die oben genannten Einschränkungen einhalten, gibt es bestimmte Web-Roboter, die nach solchen Phrasen "suchen", um Daten abzurufen, die ursprünglich ohne Indizierung konfiguriert wurden.
Von den erweiterten Optionen für die Indizierungssicherheit können Sie das CAPTCHA-System verwenden. Dies ist ein Computertest, bei dem nur Menschen auf den Inhalt einer Seite zugreifen können, nicht auf automatisierte Bots. Diese Option hat jedoch einen kleinen Nachteil. Es ist für die Benutzer selbst nicht sehr benutzerfreundlich.
Eine andere einfache Abwehrmethode von Google Dorks könnte beispielsweise das Codieren von Zeichen in Verwaltungsdateien mit ASCII sein, was die Verwendung von Google Dorking erschwert.
Pentesting-Praxis
Pentesting-Praktiken sind Tests zum Erkennen von Schwachstellen im Netzwerk und auf Webplattformen. Sie sind auf ihre eigene Weise wichtig, da solche Tests den Grad der Verwundbarkeit von Webseiten oder Servern, einschließlich Google Dorking, eindeutig bestimmen. Es gibt spezielle Pentesting-Tools, die im Internet verfügbar sind. Eine davon ist Site Digger, eine Website, mit der Sie die Google Hacking-Datenbank auf jeder ausgewählten Webseite automatisch überprüfen können. Es gibt auch Tools wie den Wikto-Scanner, SUCURI und verschiedene andere Online-Scanner. Sie arbeiten auf ähnliche Weise.
Es gibt erweiterte Tools, die die Webseitenumgebung nachahmen, sowie Fehler und Schwachstellen, um einen Angreifer anzulocken und dann vertrauliche Informationen über ihn abzurufen, z. B. den Google Hack Honeypot. Ein Standardbenutzer mit wenig Wissen und unzureichender Erfahrung im Schutz vor Google Dorking sollte zunächst seine Netzwerkressourcen überprüfen, um Sicherheitslücken in Google Dorking zu identifizieren und zu überprüfen, welche vertraulichen Daten öffentlich verfügbar sind. Es lohnt sich, diese Datenbanken regelmäßig zu überprüfen, haveibeenpwned.com und dehashed.com , um festzustellen , ob die Sicherheit Ihrer Online-Konten gefährdet und veröffentlicht wurde.
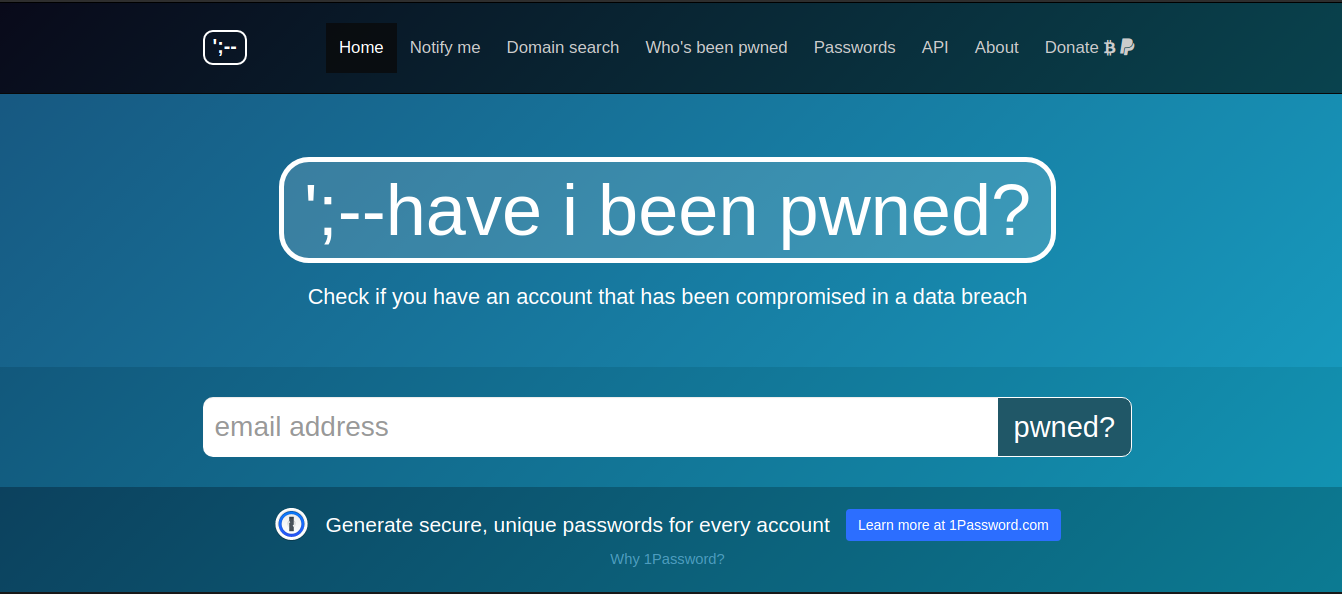
https://haveibeenpwned.com/ bezieht sich auf schlecht gesicherte Webseiten, auf denen Kontodaten (E-Mail-Adressen, Anmeldungen, Kennwörter und andere Daten) gesammelt wurden. Die Datenbank enthält derzeit über 5 Milliarden Konten. Unter https://dehashed.com steht ein erweitertes Tool zur Verfügung , mit dem Sie Informationen nach Benutzernamen, E-Mail-Adressen, Kennwörtern und deren Hashes, IP-Adressen, Namen und Telefonnummern suchen können. Darüber hinaus können durchgesickerte Konten online gekauft werden. Ein Tag Zugang kostet nur 2 $.
Fazit
Google Dorking ist ein wesentlicher Bestandteil der Erfassung vertraulicher Informationen und des Analyseprozesses. Es kann zu Recht als eines der wichtigsten und wichtigsten OSINT-Tools angesehen werden. Google Dorking-Betreiber helfen sowohl beim Testen ihres eigenen Servers als auch beim Auffinden aller möglichen Informationen über ein potenzielles Opfer. Dies ist in der Tat ein sehr eindrucksvolles Beispiel für die korrekte Verwendung von Suchmaschinen zum Zwecke der Untersuchung spezifischer Informationen. Ob die Absichten, diese Technologie zu verwenden, gut (Überprüfung der Schwachstellen ihrer eigenen Internetressource) oder unfreundlich (Suche und Sammlung von Informationen aus verschiedenen Ressourcen und Verwendung für illegale Zwecke) sind, bleibt jedoch nur den Benutzern überlassen.
Alternative Methoden und Automatisierungstools bieten noch mehr Möglichkeiten und Komfort für die Analyse von Webressourcen. Einige von ihnen, wie BinGoo, erweitern die reguläre indizierte Suche in Bing und analysieren alle Informationen, die über zusätzliche Tools (SqlMap, Fimap) empfangen werden. Sie bieten wiederum genauere und spezifischere Informationen zur Sicherheit der ausgewählten Webressource.
Gleichzeitig ist es wichtig zu wissen und sich daran zu erinnern, wie Sie Ihre Online-Plattformen ordnungsgemäß sichern und verhindern können, dass sie dort indiziert werden, wo sie nicht sein sollten. Beachten Sie auch die grundlegenden Bestimmungen für jeden Webadministrator. Unwissenheit und Unwissenheit darüber, dass andere Menschen aus Versehen Ihre Informationen erhalten haben, bedeuten schließlich nicht, dass alles wie bisher zurückgegeben werden kann.