Voraussetzungen
Die Suche nach einer Phrase in einem paginierten Text reduziert sich auf die Berechnung des Relevanzkoeffizienten für jede der Seiten und die anschließende Sortierung der Liste in absteigender Reihenfolge des Koeffizienten.
Bei der Berechnung nach dem Grundansatz wird jede Seite einer symbolweisen Analyse unterzogen, und hier liegt die Möglichkeit der Optimierung.

Bei der Berechnung des Koeffizienten werden Gruppen übereinstimmender Zeichen von Suchzeichenfolgen und Daten analysiert, während Gruppen nur innerhalb von Wörtern gebildet werden können. Andererseits wurde unter Berücksichtigung des Problems der Überschätzung der Bedeutung von „langen“ Wörtern (in Teil 2 ) als mögliche Lösung vorgeschlagen, „ die Relevanz eines Suchbegriffs als Durchschnitt der Relevanz der darin enthaltenen Wörter zu berechnen, unabhängig berechnet “. Die Verwendung eines Index führt zu einem Ergebnis, das diesem speziellen Ansatz entspricht.
Index
Die Idee der Indizierung ist nicht neu und lautet wie folgt: Aufgrund der Tatsache, dass Wörter im Text wiederholt werden, kann der Rechenaufwand reduziert werden. Dazu muss der Text, in dem die Suche durchgeführt wird, zunächst einen Index generieren. Im einfachsten Fall ist der Index eine Tabelle aller Wörter im Text, die neben Wörtern auch Daten zu den Seiten enthält, auf denen sie vorkommen. Fragment der Indextabelle basierend auf dem Text von L.N. Tolstois "Krieg und Frieden" (insgesamt enthält es ungefähr 50.000 Wörter) ist in der Abbildung dargestellt.

Direkt bei der Verarbeitung einer Anfrage wird die Suchzeichenfolge zunächst in Wörter zerlegt. Ferner wird für jedes der Wörter der Suchzeichenfolge die Relevanz mit jedem der Wörter im Index berechnet . Die Berechnungsergebnisse werden in akkumuliertTabelle der vorläufigen Ergebnisse mit den Spalten "Suchzeichenfolge", "Indexwort", "Relevanzfaktor", "Seitenzahl". Die Tabelle enthält nur die Zeilen des Index, den Relevanzkoeffizienten, für den Wörter den angegebenen Schwellenwert überschritten haben. Das heißt, jede Zeile des Index mit einem übereinstimmenden Wort generiert Zeilen in der Tabelle der vorläufigen Ergebnisse , die der Anzahl der Textseiten entsprechen, auf denen dieses Wort vorkommt. Unten finden Sie ein Fragment der Tabelle der vorläufigen Ergebnisse für die Suche nach dem Ausdruck "Abend bei Anna Pavlovna Sherer".

Dann wird die Tabelle der vorläufigen Ergebnisse wird durch Spalten Seite sortiert Nummer , Suchbegriff Wort , Factor(absteigend).

Durch Durchlaufen der Zeilen der sortierten Tabelle für jede Seite und für jedes Wort der Suchzeichenfolge wird das relevanteste Wort dieser Seite identifiziert. Dank der oben beschriebenen Sortierung ist dies das erste Wort für jede Kombination. Seitenzahl - Suchzeichenfolgenwort . Der Rest der Zeilen wird durch Kombination verworfen.
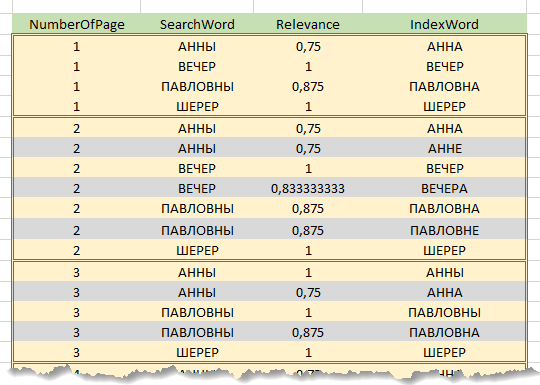
Somit werden für jede in der Tabelle der vorläufigen Ergebnisse enthaltene Textseite für jedes Wort in der Suchzeichenfolge die relevantesten Wörter dieser Seite mit den entsprechenden Koeffizienten gefunden. Die Summe der auf der Seite gefundenen Wortkoeffizienten, bezogen auf die Anzahl der Wörter in der Suchleiste, ergibt den für die Seite relevanten Koeffizienten.

In der obigen Abbildung wird die Suche beispielsweise durch die Zeile "Abend bei Anna Pavlovna Sherer" durchgeführt (die Präposition "y" wird nicht berücksichtigt). Die grau hervorgehobenen Zeilen werden während des Bypasses verworfen. Der Relevanzkoeffizient für Seite 1 beträgt (0,75 + 1 + 0,875 + 1) / 4 = 0,906 für Seite 2 - 0,906 für 3 - 0,75.
Leistungen
Wenn Sie die für die Indizierung aufgewendete Zeit nicht berücksichtigen, deren Ergebnisse wiederverwendet werden, und berücksichtigen Sie, dass der Gesamtbetrag der Berechnung, dessen Bewertung in Teil 1 wiedergegeben wird. Ein Vielfaches der Länge der Datenzeichenfolge :
 ;
;
Wir können sagen, dass der Gewinn aus der Verwendung des Index ein Vielfaches des Verhältnisses sein wird:
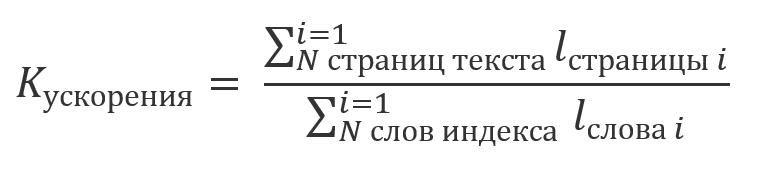
Zum Beispiel ist der Text des Romans "Krieg und Frieden" auf dem Demostand textradar.ru in 1488 Seiten mit jeweils 2000 Zeichen unterteilt. Die Gesamtzahl der Symbole in den Wörtern des Index, die aus 52156 Elementen bestehen, beträgt 434060. Das heißt, der Gewinn aus der Indexierung beträgt ungefähr 7:

Aufgrund der Tatsache, dass die mit Hilfe der Indizierung erhaltenen Ergebnisse den Ergebnissen entsprechen, die mit einem der zuvor beschriebenen Ansätze ohne diesen Index erzielt wurden, wird es möglich, die Suchergebnisse für die indizierten und nicht indizierten Teile des Textes gemeinsam zu verarbeiten. Aufgrund der Tatsache, dass die Indizierung eine relativ teure Operation ist und normalerweise nach einem Zeitplan durchgeführt wird, ist es möglich, dass ein Teil des Textes indiziert wird und einige noch nicht. In diesem Fall beträgt die Einsparung an Rechenaufwand ein Vielfaches des Anteils des indizierten Textes an seiner Gesamtgröße:
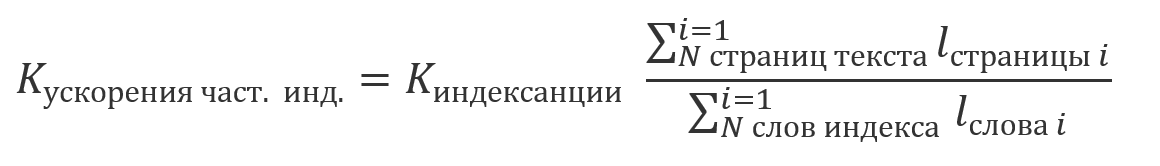
Neben der Verbesserung der Suchgeschwindigkeit eröffnet die Verwendung eines Index eine Reihe weiterer Möglichkeiten. Mithilfe von Statistiken aus der Indizierung können Sie beispielsweise die Bedeutung seltener Wörter erhöhen und die Textseiten hervorheben, auf denen die signifikanten Wörter des Suchbegriffs häufiger gefunden werden. Sie können die Indextabelle auch um Synonyme erweitern.
Damit ist der Publikationszyklus zur Beschreibung von TextRadar abgeschlossen. Vielen Dank für Ihr Interesse und Ihre wertvollen Kommentare, die es uns ermöglicht haben, weiter als ursprünglich geplant zu gehen.
Die Ergebnisse der Anwendung der beschriebenen Ansätze sind auf dem Demostand auf der Website textradar.ru zu sehen . Die Implementierung (C # ASP.NET MVC) finden Sie hier .