Ab Initio hat viele klassische und ungewöhnliche Transformationen, die mit einer eigenen PDL erweitert werden können. Für ein kleines Unternehmen ist ein derart leistungsfähiges Tool wahrscheinlich redundant, und die meisten seiner Funktionen können teuer und unnötig sein. Aber wenn Ihre Skala in der Nähe der von Sberbank liegt, könnte Ab Initio für Sie interessant sein.
Es hilft dem Unternehmen, Wissen global zu sammeln und das Ökosystem und den Entwickler zu entwickeln - um seine Fähigkeiten in ETL zu verbessern, Wissen in die Shell zu bringen, bietet die Möglichkeit, die PDL-Sprache zu beherrschen, gibt ein visuelles Bild von Ladeprozessen und vereinfacht die Entwicklung aufgrund der Fülle an Funktionskomponenten.
In diesem Beitrag werde ich über die Fähigkeiten von Ab Initio sprechen und vergleichende Merkmale seiner Arbeit mit Hive und GreenPlum angeben.
- MDW GreenPlum
- Ab Initio Hive GreenPlum
- Ab Initio GreenPlum Near Real Time
Die Funktionalität dieses Produkts ist sehr breit und das Erlernen nimmt viel Zeit in Anspruch. Mit den richtigen Fähigkeiten und den richtigen Leistungseinstellungen sind die Datenverarbeitungsergebnisse jedoch beeindruckend. Die Verwendung von Ab Initio für einen Entwickler kann ihm eine interessante Erfahrung bieten. Dies ist eine neue Version der ETL-Entwicklung, eine Mischung aus visueller Umgebung und Download-Entwicklung in einer skriptähnlichen Sprache.
Unternehmen entwickeln ihre Ökosysteme und dieses Tool ist mehr denn je nützlich. Mit Hilfe von Ab Initio können Sie Wissen über Ihr aktuelles Geschäft sammeln und dieses Wissen nutzen, um alte und neue Geschäfte zu erweitern. Alternativen zu Ab Initio können aus den visuellen Entwicklungsumgebungen Informatica BDM und aus nicht visuellen Umgebungen - Apache Spark - aufgerufen werden.
Beschreibung von Ab Initio
Ab Initio ist wie andere ETL-Tools eine Produktsuite.

Ab Initio GDE (Graphical Development Environment) ist eine Umgebung für einen Entwickler, in der er Datentransformationen einrichtet und diese mit Datenströmen in Form von Pfeilen verbindet. In diesem Fall wird ein solcher Satz von Transformationen als Graph bezeichnet:

Eingangs- und Ausgangsverbindungen von Funktionskomponenten sind Ports und enthalten Felder, die innerhalb der Transformationen berechnet wurden. Mehrere Diagramme, die durch Streams in Form von Pfeilen in der Reihenfolge ihrer Ausführung verbunden sind, werden als Plan bezeichnet.
Es gibt mehrere hundert Funktionskomponenten, was sehr viel ist. Viele von ihnen sind hoch spezialisiert. Ab Initio bietet eine größere Auswahl an klassischen Transformationen als andere ETL-Tools. Join hat beispielsweise mehrere Ausgänge. Zusätzlich zum Ergebnis der Verbindung von Datasets können Sie an den Ausgabedatensätzen von Eingabedatensätzen abrufen, über deren Schlüssel keine Verbindung hergestellt werden konnte. Sie können auch Ablehnungen, Fehler und ein Protokoll des Transformationsvorgangs erhalten, das in derselben Spalte wie eine Textdatei gelesen und von anderen Transformationen verarbeitet werden kann:

Sie können beispielsweise den Datenempfänger in Form einer Tabelle materialisieren und Daten in derselben Spalte daraus lesen.
Es gibt ursprüngliche Transformationen. Beispielsweise hat die Scan-Umwandlung dieselbe Funktionalität wie Analysefunktionen. Es gibt Transformationen mit selbsterklärenden Namen: Daten erstellen, Excel lesen, Normalisieren, Innerhalb von Gruppen sortieren, Programm ausführen, SQL ausführen, Mit DB verbinden usw. Diagramme können Laufzeitparameter verwenden, einschließlich der Übertragung von Parametern vom Betriebssystem oder zum Betriebssystem ... Dateien mit einem vorgefertigten Satz von Parametern, die an das Diagramm übergeben werden, werden als Parametersätze (psets) bezeichnet.
Wie erwartet verfügt Ab Initio GDE über ein eigenes Repository namens EME (Enterprise Meta Environment). Entwickler haben die Möglichkeit, mit lokalen Versionen des Codes zu arbeiten und ihre Entwicklungen im zentralen Repository einzuchecken.
Während der Ausführung oder nach der Ausführung des Diagramms können Sie auf einen beliebigen Stream klicken, der die Transformationen verbindet, und die Daten anzeigen, die zwischen diesen Transformationen übertragen wurden:

Es ist auch möglich, auf einen beliebigen Stream zu klicken und die Tracking-Details anzuzeigen - in wie vielen Parallelen die Transformation funktioniert hat, in wie vielen Zeilen und Bytes in welchen Parallelen werden geladen:

Es ist möglich, die Ausführung des Graphen in Phasen aufzuteilen und zu markieren, dass einige Transformationen zuerst (in Phase Null), in der ersten Phase, in der zweiten Phase usw. durchgeführt werden sollen.
Für jede Transformation können Sie das sogenannte Layout auswählen (wo es ausgeführt wird): ohne Parallelen oder in parallelen Threads, deren Anzahl festgelegt werden kann. Gleichzeitig können temporäre Dateien, die von Ab Initio während der Transformationsarbeit erstellt wurden, sowohl im Server-Dateisystem als auch in HDFS abgelegt werden.
In jeder Transformation können Sie basierend auf der Standardvorlage Ihr eigenes Skript in der PDL-Sprache erstellen, die ein bisschen wie eine Shell ist.
Mit Hilfe der PDL-Sprache können Sie die Funktionalität von Transformationen erweitern und insbesondere dynamisch (zur Laufzeit) beliebige Codefragmente in Abhängigkeit von den Laufzeitparametern generieren.
Außerdem verfügt Ab Initio über eine gut entwickelte Integration in das Betriebssystem über die Shell. Insbesondere verwendet Sberbank Linux ksh. Sie können Variablen mit der Shell austauschen und als Diagrammparameter verwenden. Sie können die Ausführung von Ab Initio-Diagrammen über die Shell aufrufen und Ab Initio verwalten.
Neben Ab Initio GDE umfasst die Lieferung viele weitere Produkte. Es gibt ein Co> -Betriebssystem mit dem Anspruch, als Betriebssystem bezeichnet zu werden. Unter Control> Center können Sie Download-Streams planen und überwachen. Es gibt Produkte für eine primitivere Entwicklung, als es Ab Initio GDE zulässt.
Beschreibung des MDW-Frameworks und Bearbeitung seiner Anpassung für GreenPlum
Zusammen mit seinen Produkten liefert der Anbieter das Produkt MDW (Metadata Driven Warehouse), einen Grafikkonfigurator, der bei typischen Aufgaben zum Befüllen von Data Warehouses oder Datentresoren hilft.
Es enthält benutzerdefinierte (projektspezifische) Metadaten-Parser und sofort einsatzbereite Codegeneratoren.
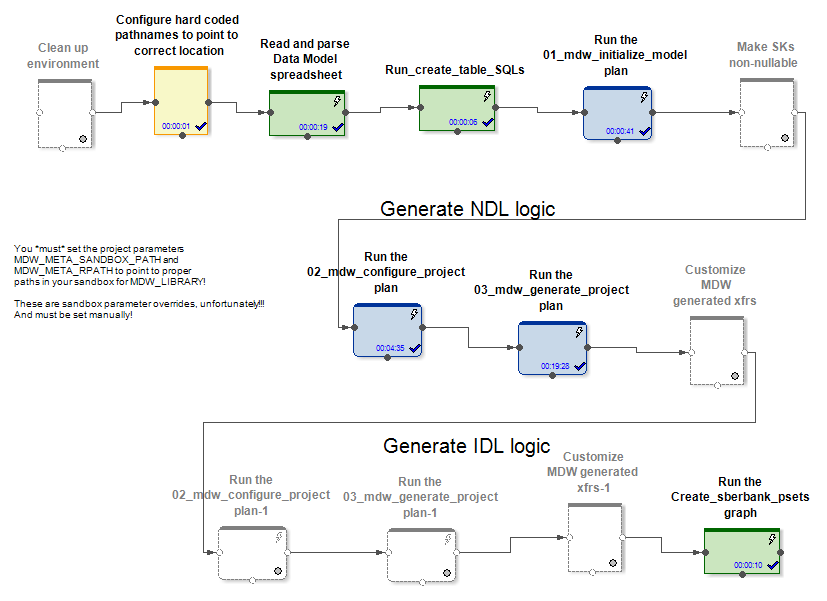
Am Eingang erhält MDW ein Datenmodell, eine Konfigurationsdatei zum Einrichten einer Datenbankverbindung (Oracle, Teradata oder Hive) und einige andere Einstellungen. Der projektspezifische Teil stellt beispielsweise das Modell in der Datenbank bereit. Der umrahmte Teil des Produkts generiert beim Laden von Daten in die Modelltabellen Diagramme und Konfigurationsdateien für diese. Dadurch werden Diagramme (und Psets) für verschiedene Modi der Initialisierung und inkrementellen Arbeit an der Aktualisierung von Entitäten erstellt.
In den Fällen Hive und RDBMS werden unterschiedliche Diagramme zur Initialisierung und inkrementellen Datenaktualisierung generiert.
Im Fall von Hive werden die eingehenden Delta-Daten von Ab Initio Join mit den Daten verknüpft, die vor der Aktualisierung in der Tabelle enthalten waren. Datenlader in MDW (sowohl in Hive als auch in RDBMS) fügen nicht nur neue Daten aus dem Delta ein, sondern schließen auch die Datengültigkeitszeiträume, für die das Delta von den Primärschlüsseln empfangen wurde. Außerdem müssen Sie den unveränderten Teil der Daten neu schreiben. Dies muss jedoch getan werden, da Hive keine Lösch- oder Aktualisierungsvorgänge hat.
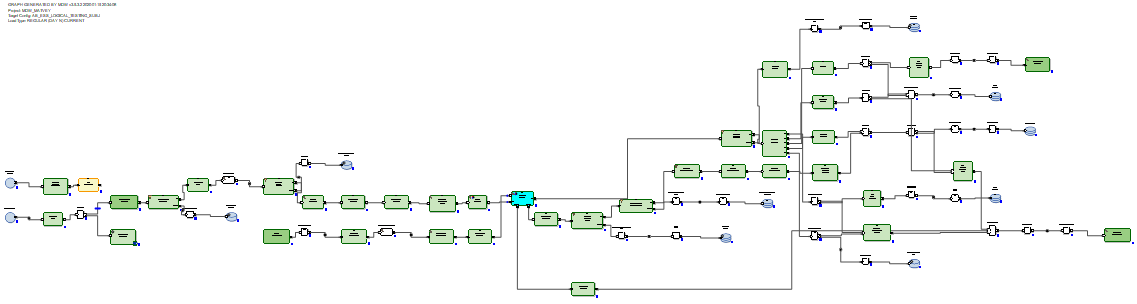
Im Fall von RDBMS sehen die inkrementellen Datenaktualisierungsdiagramme optimaler aus, da RDBMS über echte Aktualisierungsfunktionen verfügt.
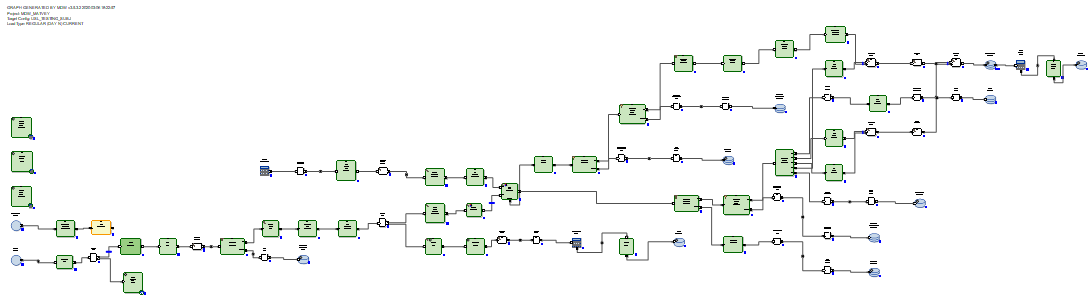
Das empfangene Delta wird in eine Staging-Tabelle in der Datenbank geladen. Danach wird das Delta mit den Daten verbunden, die sich vor der Aktualisierung in der Tabelle befanden. Dies geschieht mittels SQL über die generierte SQL-Abfrage. Anschließend werden mit den SQL-Befehlen delete + insert neue Daten aus dem Delta in die Zieltabelle eingefügt und die relevanten Zeiträume der Daten werden entsprechend den Primärschlüsseln geschlossen, von denen das Delta empfangen wurde.
Es ist nicht erforderlich, unveränderte Daten neu zu schreiben.
Daher kamen wir zu dem Schluss, dass MDW im Fall von Hive die gesamte Tabelle neu schreiben sollte, da Hive keine Aktualisierungsfunktion hat. Und nichts Besseres als ein vollständiges Umschreiben der Daten beim Aktualisieren wird nicht erfunden. Im Fall von RDBMS hielten es die Entwickler des Produkts im Gegenteil für erforderlich, die Verbindung und Aktualisierung von Tabellen mithilfe von SQL anzuvertrauen.
Für ein Projekt bei Sberbank haben wir eine neue wiederverwendbare Implementierung des GreenPlum-Datenbankladers erstellt. Dies erfolgte basierend auf der Version, die MDW für Teradata generiert. Es war Teradata, nicht Oracle, das dafür am besten und am nächsten kam. ist auch ein MPP-System. Die Arbeitsweise sowie die Syntax von Teradata und GreenPlum erwiesen sich als ähnlich.
Beispiele für kritische Unterschiede für MDW zwischen verschiedenen RDBMS sind wie folgt. In GreenPlum müssen Sie im Gegensatz zu Teradata beim Erstellen von Tabellen eine Klausel schreiben
distributed byTeradata schreibt
delete <table> allund in GreenePlum schreiben sie
delete from <table>Oracle schreibt zu Optimierungszwecken
delete from t where rowid in (< t >)und Teradata und GreenPlum schreiben
delete from t where exists (select * from delta where delta.pk=t.pk)Wir beachten außerdem, dass Ab Initio für die Arbeit mit GreenPlum den GreenPlum-Client auf allen Knoten des Ab Initio-Clusters installieren musste. Dies liegt daran, dass wir von allen Knoten in unserem Cluster gleichzeitig eine Verbindung zu GreenPlum hergestellt haben. Damit das Lesen von GreenPlum parallel ist und jeder parallele Ab Initio-Thread seinen eigenen Teil der Daten von GreenPlum liest, musste eine von Ab Initio verstandene Konstruktion in den Abschnitt "where" von SQL-Abfragen eingefügt werden
where ABLOCAL()und Bestimmen des Werts dieser Konstruktion durch Angeben des Parameterlesens aus der Transformationsdatenbank
ablocal_expr=«string_concat("mod(t.", string_filter_out("{$TABLE_KEY}","{}"), ",", (decimal(3))(number_of_partitions()),")=", (decimal(3))(this_partition()))»was zu so etwas kompiliert
mod(sk,10)=3d.h. Sie müssen GreenPlum einen expliziten Filter für jede Partition mitteilen. Für andere Datenbanken (Teradata, Oracle) kann Ab Initio diese Parallelisierung automatisch durchführen.
Vergleichende Leistungsmerkmale von Ab Initio für die Arbeit mit Hive und GreenPlum
Bei der Sberbank wurde ein Experiment durchgeführt, um die Leistung der von MDW erzeugten Diagramme in Bezug auf Hive und in Bezug auf GreenPlum zu vergleichen. Im Rahmen des Experiments befanden sich im Fall von Hive 5 Knoten im selben Cluster wie Ab Initio, und im Fall von GreenPlum befanden sich 4 Knoten in einem separaten Cluster. Jene. Hive hatte einige Hardwarevorteile gegenüber GreenPlum.
Wir haben uns zwei Diagrammpaare angesehen, die dieselbe Aufgabe zum Aktualisieren von Daten in Hive und GreenPlum ausführen. Die vom MDW-Konfigurator generierten Diagramme wurden gestartet:
- Initialisieren der Last + inkrementelles Laden zufällig generierter Daten in die Hive-Tabelle
- Initialisieren des Ladens + inkrementelles Laden zufällig generierter Daten in dieselbe GreenPlum-Tabelle
In beiden Fällen (Hive und GreenPlum) wurden Downloads in 10 parallelen Threads auf demselben Ab Initio-Cluster gestartet. Ab Initio speicherte Zwischendaten für Berechnungen in HDFS (in Bezug auf Ab Initio wurde das MFS-Layout mit HDFS verwendet). Eine Zeile zufällig generierter Daten belegte in beiden Fällen 200 Bytes.
Das Ergebnis ist wie folgt:
Hive:
| Laden in Hive initialisieren | |||
| Zeilen eingefügt | 6.000.000 | 60.000.000 | 600.000.000 |
| Dauer der Initialisierung der
Last in Sekunden |
41 | 203 | 1 601 |
| Inkrementelles Laden in Hive | |||
| Die Anzahl der Zeilen in der
Zieltabelle zu Beginn des Experiments |
6.000.000 | 60.000.000 | 600.000.000 |
| Anzahl der Delta-Zeilen, die
während des Experiments auf die Zieltabelle angewendet wurden |
6.000.000 | 6.000.000 | 6.000.000 |
| Inkrementelle
Downloaddauer in Sekunden |
88 | 299 | 2541 |
GreenPlum:
| GreenPlum | |||
| 6 000 000 | 60 000 000 | 600 000 000 | |
|
|
72 | 360 | 3 631 |
| GreenPlum | |||
| ,
|
6 000 000 | 60 000 000 | 600 000 000 |
| ,
|
6 000 000 | 6 000 000 | 6 000 000 |
|
|
159 | 199 | 321 |
Wir sehen, dass die Geschwindigkeit der Initialisierung des Downloads in Hive und GreenPlum linear von der Datenmenge abhängt und aus Gründen der besseren Hardware für Hive etwas schneller ist als für GreenPlum.
Das inkrementelle Laden in Hive hängt auch linear von der Menge der zuvor geladenen Daten in der Zieltabelle ab und ist mit zunehmendem Volumen eher langsam. Dies liegt an der Notwendigkeit, die Zieltabelle vollständig zu überschreiben. Dies bedeutet, dass das Anwenden kleiner Änderungen an großen Tabellen kein guter Anwendungsfall für Hive ist.
Das inkrementelle Laden in GreenPlum hängt schwach von der Menge der zuvor geladenen Daten in der Zieltabelle ab und ist ziemlich schnell. Dies geschah dank SQL Joins und der GreenPlum-Architektur, die den Löschvorgang ermöglicht.
Daher injiziert GreenPlum das Delta mithilfe der Methode "Löschen + Einfügen", während Hive keine Lösch- oder Aktualisierungsvorgänge ausführt. Daher musste das gesamte Datenarray während einer inkrementellen Aktualisierung vollständig neu geschrieben werden. Am aussagekräftigsten ist der Vergleich der fett hervorgehobenen Zellen, da er der häufigsten Variante des Betriebs ressourcenintensiver Downloads entspricht. Wir sehen, dass GreenPlum in diesem Test 8 Mal gegen Hive gewonnen hat.
Ab Initio mit GreenPlum in nahezu Echtzeit
In diesem Experiment werden wir die Fähigkeit von Ab Initio testen, die GreenPlum-Tabelle mit zufällig generierten Datenblöcken nahezu in Echtzeit zu aktualisieren. Betrachten Sie die Tabelle GreenPlum dev42_1_db_usl.TESTING_SUBJ_org_finval, mit der wir arbeiten werden.
Wir werden drei Ab Initio-Diagramme verwenden, um damit zu arbeiten:
1) Create_test_data.mp-Diagramm - Erstellt Dateien mit Daten in HDFS für 6.000.000 Zeilen in 10 parallelen Streams. Die Daten sind zufällig, ihre Struktur ist zum Einfügen in unsere Tabelle organisiert.

2) Diagramm mdw_load.day_one.current.dev42_1_db_usl_testing_subj_org_finval.pset - generiertes MDW-Diagramm zum Initialisieren des Einfügens von Daten in unsere Tabelle in 10 parallelen Threads (unter Verwendung der von Diagramm (1) generierten Testdaten)

3) Diagramm mdw_load.regular.current.dev42_1_db_usl_testing_subj_org_finval.pset - MDW-generiertes Diagramm zur inkrementellen Aktualisierung unserer Tabelle in 10 parallelen Threads unter Verwendung eines Teils der vom Diagramm generierten neuen eingehenden Daten (Delta) (1)

Führen Sie das folgende Skript im NRT-Modus aus:
- generieren 6.000.000 Testlinien
- Beim Initialisieren der Last werden 6.000.000 Testzeilen in die leere Tabelle eingefügt
- 5 mal inkrementellen Download wiederholen
- generieren 6.000.000 Testlinien
- Nehmen Sie eine inkrementelle Einfügung von 6.000.000 Testzeilen in die Tabelle vor (in diesem Fall werden die alten Daten mit der Ablaufzeit valid_to_ts versehen und neuere Daten mit demselben Primärschlüssel eingefügt).
Ein solches Szenario emuliert die Art des realen Betriebs eines bestimmten Geschäftssystems - ein ziemlich großer Teil der neuen Daten wird in Echtzeit angezeigt und fließt sofort in GreenPlum ein.
Sehen wir uns nun das Protokoll des Skripts an:
Starten Sie Create_test_data.input.pset um 2020-06-04 11:49:11 Beenden Sie
Create_test_data.input.pset um 2020-06-04 11:49:37
Starten Sie mdw_load.day_one.current.dev42_1_db_usl_testing_subj_org_finval bei 2020.06.04 11.49.37
Fertig mdw_load.day_one.current.dev42_1_db_usl_testing_subj_org_finval.pset bei 2020.06.04 11.50.42
starten Create_test_data.input.pset bei 2020.06.04 11.50.42
Fertig Create_test_data.input.pset am 2020-06-04 11:51:06
Starten Sie mdw_load.regular.current.dev42_1_db_usl_testing_subj_org_finval.pset am 2020-06-04 11:51:06
Finish mdw_load.regular.current.dev42_1_db_usl_testing_subj_org_finval.pset at 2020-06-04 11:53:41
Start Create_test_data.input.pset at 2020-06-04 11:53:41
Finish Create_test_data.input.pset at 2020-06-04 11:54:04
Start mdw_load.regular.current.dev42_1_db_usl_testing_subj_org_finval.pset at 2020-06-04 11:54:04
Finish mdw_load.regular.current.dev42_1_db_usl_testing_subj_org_finval.pset at 2020-06-04 11:56:51
Start Create_test_data.input.pset at 2020-06-04 11:56:51
Finish Create_test_data.input.pset at 2020-06-04 11:57:14
Start mdw_load.regular.current.dev42_1_db_usl_testing_subj_org_finval.pset at 2020-06-04 11:57:14
Finish mdw_load.regular.current.dev42_1_db_usl_testing_subj_org_finval.pset at 2020-06-04 11:59:55
Starten Sie Create_test_data.input.pset um 2020-06-04 11:59:55. Beenden Sie
Create_test_data.input.pset um 2020-06-04 12:00:23.
Starten Sie mdw_load.regular.current.dev42_1_db_usl_testing_subj_org_finval.pset um 2020-06-04 12:00:23
Beenden Sie mdw_load.regular.current.dev42_1_db_usl_testing_subj_org_finval.pset um 2020-06-04 12:03:23
Starten Sie Create_test_data.input.pset um 2020-06-04 12:03:23 Beenden Sie
Create_test_data.input.pset um 2020-06-04 12:03:49
Starten Sie mdw_load.regular.current.dev42_1_db_usl_testing_subj_org_finval.pset um 2020-06-04 12:03:49
Beenden Sie mdw_load.regular.current.dev42_1_db_usl_testing_subj_org:04 : 46 Das
Bild sieht so aus:
| Graph | Startzeit | Endzeit | Länge |
|---|---|---|---|
| Create_test_data.input.pset | 06/04/2020 11:49:11 | 06/04/2020 11:49:37 | 00:00:26 |
| mdw_load.day_one.current.
dev42_1_db_usl_testing_subj_org_finval.pset |
06/04/2020 11:49:37 | 06/04/2020 11:50:42 | 00:01:05 |
| Create_test_data.input.pset | 06/04/2020 11:50:42 | 06/04/2020 11:51:06 | 00:00:24 |
| mdw_load.regular.current.
dev42_1_db_usl_testing_subj_org_finval.pset |
06/04/2020 11:51:06 | 06/04/2020 11:53:41 | 00:02:35 |
| Create_test_data.input.pset | 06/04/2020 11:53:41 | 06/04/2020 11:54:04 | 00:00:23 |
| mdw_load.regular.current.
dev42_1_db_usl_testing_subj_org_finval.pset |
06/04/2020 11:54:04 | 06/04/2020 11:56:51 | 00:02:47 |
| Create_test_data.input.pset | 06/04/2020 11:56:51 | 06/04/2020 11:57:14 | 00:00:23 |
| mdw_load.regular.current.
dev42_1_db_usl_testing_subj_org_finval.pset |
06/04/2020 11:57:14 | 06/04/2020 11:59:55 | 00:02:41 |
| Create_test_data.input.pset | 06/04/2020 11:59:55 | 06/04/2020 12:00:23 | 00:00:28 |
| mdw_load.regular.current.
dev42_1_db_usl_testing_subj_org_finval.pset |
06/04/2020 12:00:23 | 06/04/2020 12:03:23 PM | 00:03:00 |
| Create_test_data.input.pset | 06/04/2020 12:03:23 PM | 06/04/2020 12:03:49 PM | 00:00:26 |
| mdw_load.regular.current.
dev42_1_db_usl_testing_subj_org_finval.pset |
06/04/2020 12:03:49 PM | 06/04/2020 12:06:46 PM | 00:02:57 |
Wir sehen, dass 6.000.000 Inkrementzeilen in 3 Minuten verarbeitet werden, was ziemlich schnell ist.
Die Daten in der Zieltabelle waren wie folgt verteilt:
select valid_from_ts, valid_to_ts, count(1), min(sk), max(sk) from dev42_1_db_usl.TESTING_SUBJ_org_finval group by valid_from_ts, valid_to_ts order by 1,2;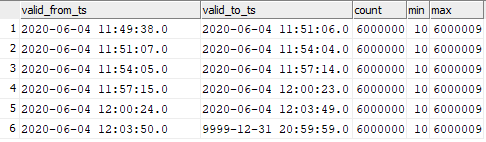
Sie können die Entsprechung der eingefügten Daten zu den Momenten des Diagrammstarts sehen.
Dies bedeutet, dass Sie das schrittweise Laden von Daten in GreenPlum in Ab Initio mit einer sehr hohen Frequenz starten und eine hohe Geschwindigkeit beim Einfügen dieser Daten in GreenPlum beobachten können. Natürlich ist es nicht möglich, einmal pro Sekunde zu starten, da Ab Initio wie jedes ETL-Tool Zeit benötigt, um beim Start zu "schwingen".
Fazit
Jetzt wird Ab Initio in Sberbank verwendet, um die Unified Semantic Data Layer (ESS) zu erstellen. Bei diesem Projekt wird eine einzige Version des Zustands verschiedener Bankunternehmen erstellt. Informationen stammen aus verschiedenen Quellen, von denen Repliken auf Hadoop erstellt wurden. Basierend auf den Anforderungen des Unternehmens wird ein Datenmodell erstellt und Datentransformationen beschrieben. Ab Initio lädt Informationen in das ECC hoch und die geladenen Daten sind nicht nur für das Unternehmen an sich von Interesse, sondern dienen auch als Quelle für den Aufbau von Data Marts. Gleichzeitig können Sie dank der Funktionalität des Produkts verschiedene Systeme (Hive, Greenplum, Teradata, Oracle) als Empfänger verwenden, um mühelos Daten für Unternehmen in verschiedenen erforderlichen Formaten vorzubereiten.
Die Möglichkeiten von Ab Initio sind breit gefächert. Das mitgelieferte MDW-Framework ermöglicht beispielsweise die sofortige Erstellung technischer und geschäftlicher historischer Daten. Für Entwickler bietet Ab Initio die Möglichkeit, „das Rad nicht neu zu erfinden“, sondern viele der verfügbaren Funktionskomponenten zu verwenden, bei denen es sich tatsächlich um Bibliotheken handelt, die für die Arbeit mit Daten benötigt werden.
Der Autor ist Experte der Sberbank-Fachgemeinschaft SberProfi DWH / BigData. Die Fachwelt SberProfi DWH / BigData ist verantwortlich für die Entwicklung von Kompetenzen in Bereichen wie dem Hadoop-Ökosystem, Teradata, Oracle DB, GreenPlum sowie den BI-Tools Qlik, SAP BO, Tableau usw.