Was ist I-IoT?
Nach der Einführung der Dampfmaschine im Jahr 1760 wurde Dampf verwendet, um alles von der Landwirtschaft bis zu Textilien anzutreiben. Dies löste die erste industrielle Revolution und die Ära der mechanischen Fertigung aus. Ende des 19. Jahrhunderts kamen Elektrizität, neue Arten der Arbeitsorganisation und Massenproduktion hinzu und markierten den Beginn der zweiten industriellen Revolution. In der zweiten Hälfte des 20. Jahrhunderts führten die Entwicklung von Halbleitern und die Einführung elektronischer Steuerungen zur Ära der Automatisierung und der dritten industriellen Revolution. Auf der Hannover Messe 2011 prägten Henning Kagermann, Wolf-Dieter Lucas und Wolfgang Walster den Begriff Industrie 4.0 für ein Projekt zur Erneuerung des deutschen Produktionssystems mit modernster digitaler Technologie.

Industrie 4.0 wird voraussichtlich Folgendes umsetzen können:
- Kombinieren Sie Produktion mit Informations- und Kommunikationstechnologien
- Kombinieren Sie Kundendaten mit Produktionsdaten
- Machen Sie das Beste aus der Kommunikation von Maschine zu Maschine
- Verwalten Sie die Produktion autonom, flexibel und effizient und sparen Sie Ressourcen
Der Gründer und Präsident des Weltwirtschaftsforums, Klaus Schwab, glaubt, dass die Unabhängigkeit der vierten industriellen Revolution durch drei Faktoren gerechtfertigt werden kann.
- Das Tempo der Entwicklung. Im Gegensatz zu früheren verläuft diese industrielle Revolution nicht linear, sondern exponentiell. Dies ist ein Produkt der vielfältigen, stark voneinander abhängigen Welt, in der wir leben, sowie der Tatsache, dass neue Technologien selbst zunehmend fortschrittliche und effiziente Technologien synthetisieren.
- . , , , . , «» «» , , «» .
- . , , .
Per Definition ist IoT der Schlüssel zur Weiterentwicklung der Branche, einschließlich Technologien wie Big Data Analytics, Cloud-Technologien, Robotik und vor allem der Integration und Konvergenz zwischen IT und Fertigung.
Der Begriff I-IoT (Industrial Internet of Things) bezieht sich auf die industrielle Teilmenge des IoT, bei der es sich um die digitale Transformation des natürlichen Geschäfts handelt. I-IoT macht das Geschäft flexibler, profitabler, verständlicher und schafft neue digitale Wertschöpfungsketten.
Traditionelle Produktionsketten sind unkomplizierte, aufeinanderfolgende Schritte wie Produktentwicklung, Beschaffung und Beschaffung von Rohstoffen sowie Herstellung und Wartung von Produkten. Die Essenz der neuen digitalen Transformation besteht darin, dass ein Service-Ökosystem und neue Geschäftsmodelle um einen bestimmten digitalen Kern herum geschaffen werden, die der Produktion neue Qualitäten verleihen. Zum Beispiel Kostensenkung zwischen verschiedenen Phasen der Produktionsvorbereitung, Inbetriebnahme und des Betriebs. Die Verbindungen zwischen verschiedenen Abteilungen und Phasen werden immer schneller, was es ermöglicht, effizienter und wettbewerbsfähiger auf dem Markt zu arbeiten.
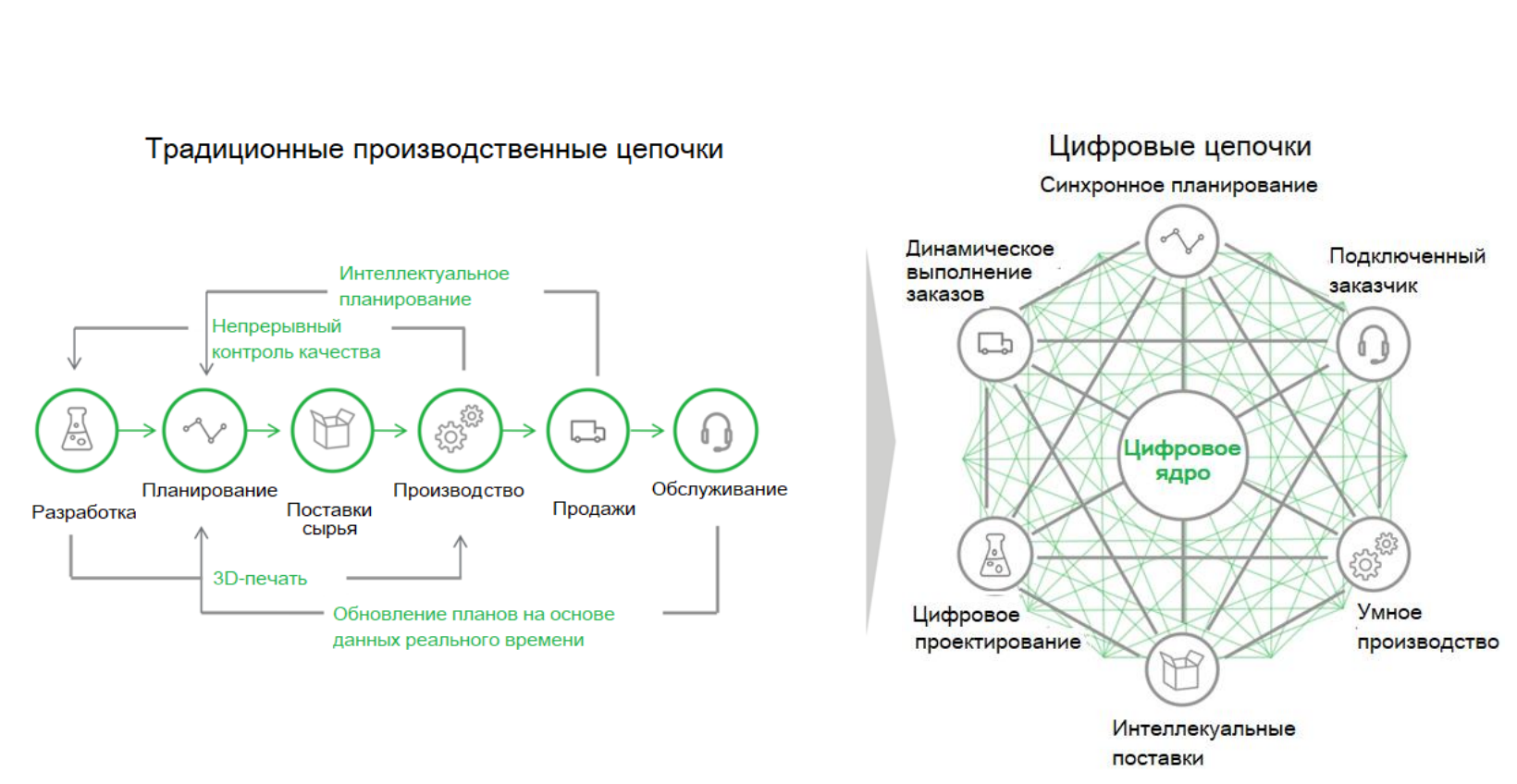
Es wird erwartet, dass das I-IoT mehr geschäftlichen Wert schafft und einen so tiefgreifenden Einfluss auf die menschliche Gesellschaft hat, dass es die vierte industrielle Revolution einleiten wird.
Laut Forbes:
- IoT 157 2016 457 2020 , 28,5%
- , , IoT 2020 , 40 .
IoT I-IoT –
- , . , , . , .
- , , ; .
- I-IoT , .
- — , , . I-IoT, , .
- .
- , . , , , .
- . I-IoT .
- , .
CIM (Computer-Integrated Manufacturing) ist ein Logikmodell für Fertigungssysteme, das in den 1990er Jahren entwickelt wurde, um Fertigungsprozesse, Automatisierungssysteme und Informationstechnologiesysteme auf Unternehmens- oder Unternehmensebene zu integrieren. CIM sollte nicht als Entwurfsmethode für die Erstellung automatisierter Fabriken angesehen werden, sondern als Referenzmodell für die Implementierung der industriellen Automatisierung auf der Grundlage der Erfassung, Koordination, Weitergabe und Übertragung von Daten und Informationen zwischen verschiedenen Systemen und Subsystemen über Softwareanwendungen und Kommunikationsnetzwerke. Das CIM wird häufig als Pyramide mit sechs Funktionsebenen dargestellt, wie in der folgenden Abbildung dargestellt
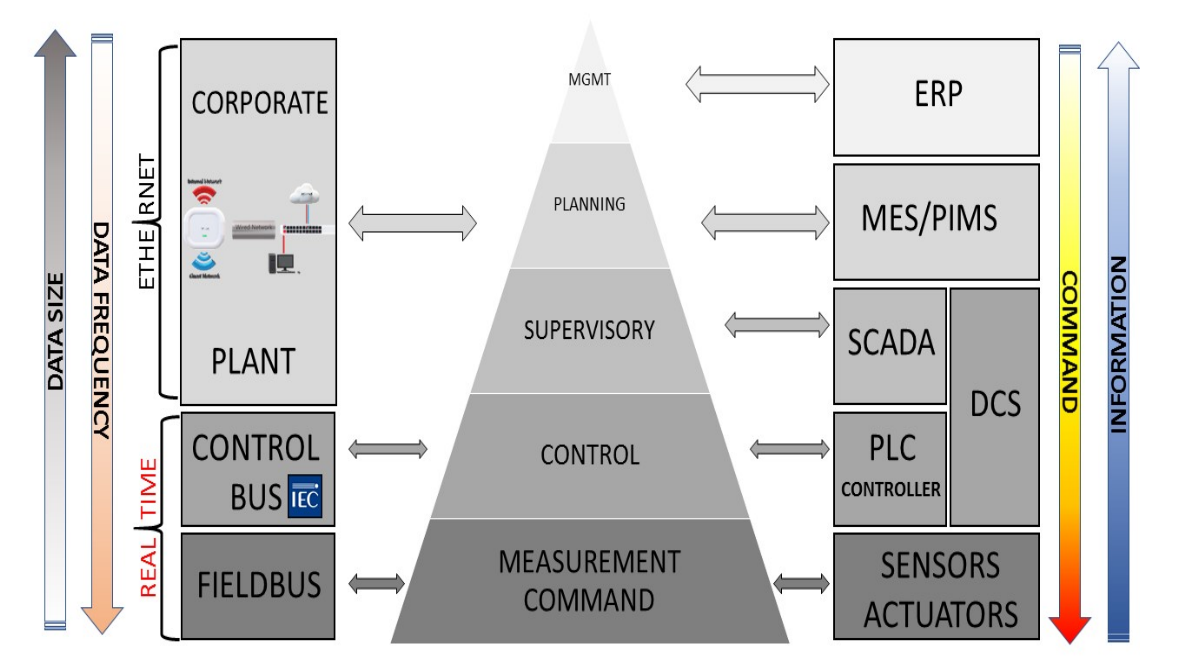
Stufe 1 - Sensoren, Wandler und Aktuator
Ein elektronischer Sensor ist ein strukturell vollständiges Messgerät, das eine oder mehrere physikalische Größen in ein elektrisches Signal für nachfolgende Transformationen, Übertragung, Verarbeitung und Anzeige von Messinformationen umwandeln kann. Ein Aktuator (Aktuator) ist ein Gerät, das einen Steuerbefehl in eine physikalische Auswirkung auf den Prozess umwandelt. Tatsächlich ergänzt seine Funktion die des Sensors. Der Aktuator akzeptiert ein Steuersignal als Eingang zum Steuersystem und überträgt Energie als Ausgang zum Mechanismus.
Stufe 2 - RTUs, Mikrocontroller, CNC, SPS und DCS
- (Remote terminal unit RTU) — , . , , . , .
- (Embedded controller), , , . .
- (CNC) – , . . , - .
- PLC — , . PLC , , , . , , , . 10 100 .
- DCS werden üblicherweise in kontinuierlichen Prozessen wie Raffinerien, Kraftwerken oder Chemiefabriken eingesetzt. Sie kombinieren sowohl die in der SPS implementierte Steuerfunktion als auch die Überwachungssteuerungssystemfunktion (SCADA). Während PLC und SCADA zwei separate Systeme mit jeweils eigenen Adressräumen sind, verwenden diese Systeme in DCS dieselben Variablen und Datenstrukturen.
Level 3 - SCADA, Historiker
Das SCADA-System ist ein Softwarepaket zum Sammeln, Verarbeiten, Anzeigen und Archivieren von Informationen über ein Überwachungs- oder Steuerobjekt in Echtzeit. Ein Datenerfassungssystem (Historian) sammelt Echtzeitinformationen über den Betriebsstatus von Geräten. Das SCADA-System implementiert die folgenden Hauptfunktionen:
- PLC, , RTU , CIM.
- , .
- , , .
- - (HMI).
- HMI PLC.
4 -MES
MES ist ein Softwaresystem zwischen ERP und SCADA oder PLC, mit dem der Produktionsprozess des Unternehmens effizient verwaltet werden kann. Die Hauptfunktion von MES besteht darin, das Management des Geschäfts und des Fertigungssystems zu synchronisieren, indem Planungs- und Steuerungsebenen kombiniert werden, um Prozesse und Ressourcen zu optimieren.
Die Hauptmerkmale des MES-Systems sind:
- Auftragsmanagement und Produktionsplanung
- Management von eingehenden Rohstoffen und Halbzeugen
- Asset Management und Überwachung
- Produktionsverfolgung
- Wartungsverwaltung
- Qualitätsprüfung
Stufe 5 - ERP
ERP umfasst Softwarepakete, mit denen ein Unternehmen die täglichen Aktivitäten seines Unternehmens verwaltet, z. B. Buchhaltung, Einkauf, Projektmanagement und Fertigung. ERP integriert und definiert eine Reihe von Geschäftsprozessen, die den Informations- und Datenaustausch zwischen den beteiligten Systemen regeln. ERP sammelt und überträgt Transaktionsdaten aus verschiedenen Abteilungen des Unternehmens und stellt so die Datenintegrität sicher, indem es als eine einzige Quelle fungiert.
Produktionsnetzwerke
Ein integriertes Produktionssystem erfordert verschiedene Arten von Kommunikationsnetzwerken, die jeweils einer bestimmten Aufgabe zugeordnet sind
- Stufe 1: Feldbus
- Stufe 2: Netzwerk von Controllern
- Level 3, 4, 5: Unternehmensnetzwerk
Feldnetzwerke wurden für Schnittstellensteuerungen, Sensoren und Aktoren eingeführt, wodurch der Bedarf an komplexer Verkabelung verringert wird. Im Feldbus sind Sensoren und Aktoren mit einem Mindestmaß an Verarbeitung ausgestattet, um eine deterministische Informationsübertragung zu gewährleisten.
Das Controller-Netzwerk muss die Kommunikation zwischen den SPS-Knoten bereitstellen. Die Datenübertragung muss in bestimmten Intervallen erfolgen. Steuerungsnetzwerke und Feldbusse werden aufgrund des Zeitpunkts der Übertragung von Daten und Informationen häufig auch als Echtzeitnetzwerke bezeichnet.
Ein Unternehmensnetzwerk ist ein Netzwerk zwischen Managementsystemen und Planungs- und Managementsystemen. Diese Schicht des Netzwerks sollte die Verarbeitung komplexer Informationen gewährleisten, jedoch in kürzeren Zeiträumen. Daher ist für diese Netzwerkschicht kein enger Zeitrahmen erforderlich.
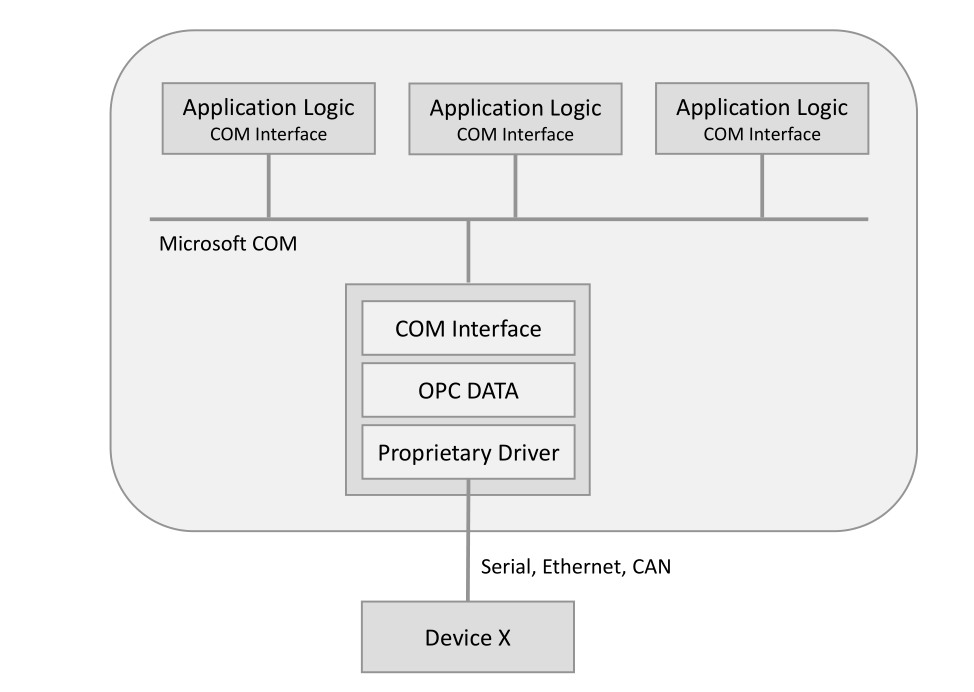
OPC-Server
Kein anderer industrieller Kommunikationsstandard hat in vielen Branchen und Geräteherstellern eine so breite Akzeptanz gefunden wie OPC. Es wird verwendet, um eine Vielzahl von Industrie- und Geschäftssystemen zu integrieren. SCADA, Sicherheitssysteme (SIS), speicherprogrammierbare Steuerungen (SPS) und verteilte Steuerungssysteme (DCS) verwenden OPC zur Kommunikation untereinander sowie mit Historian-Datenbanken, MES- und ERP-Systemen. Der Grund für den Erfolg von OPC ist sehr einfach: Es ist die einzige wirklich universelle Schnittstelle, die für die Kommunikation mit verschiedenen industriellen Geräten und Anwendungen verwendet werden kann, unabhängig vom Hersteller, der Software oder den Protokollen, die im Steuerungssystem verwendet werden. Nach der Einführung des OPC-Standards wurden fast alle SCADA als OPC-Clients neu gestaltet.Jeder Hardwarehersteller begann, seine Steuerungen, E / A-Module, intelligenten Sensoren und Aktoren mit einem Standard-OPC-Server zu versorgen.
OPC classic (Datenzugriff DA)
1995 beschlossen verschiedene Unternehmen, eine Arbeitsgruppe zur Definition des Interoperabilitätsstandards einzurichten. Diese Unternehmen waren: Fisher Rosemount, Intellution, Intuitive Technology, Opto22, Rockwell, Siemens AG.
Microsoft-Mitglieder wurden auch aufgefordert, die erforderliche Unterstützung bereitzustellen. Die Aufgabe der Arbeitsgruppe bestand darin, den Standard für den Zugriff auf Informationen in der Windows-Umgebung auf der Grundlage moderner Technologien dieser Zeit zu definieren. Die entwickelte Technologie wurde als Object Linking and Embedding (OLE) für die Prozesssteuerung (OPC) bezeichnet. Im August 1996 wurde die erste Version des OPC definiert.
Das folgende Diagramm zeigt die verschiedenen Schichten von OPC Classic mit den Hauptkommunikationsprotokollen - COM, DCOM und Remote Procedure Call (RPC).
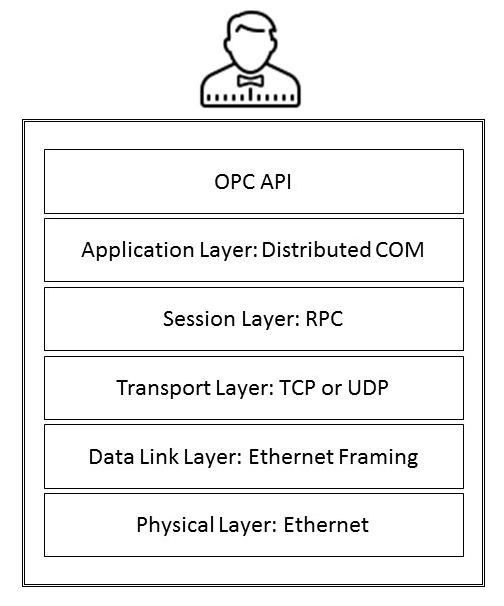
COM ist eine von Microsoft entwickelte Softwarearchitektur zum Erstellen von Komponentenanwendungen. Zu dieser Zeit konnten Programmierer wiederverwendbare Codeteile so kapseln, dass andere Anwendungen sie verwenden konnten, ohne sich um die Details ihrer Implementierung kümmern zu müssen. COM-Objekte können durch neuere Versionen ersetzt werden, ohne dass die Anwendungen, die sie verwenden, neu geschrieben werden müssen. DCOM sind vernetzte Versionen von COM. DCOM versucht, die Unterschiede zwischen COM-Objekten, die auf einem Computer ausgeführt werden, und COM-Objekten, die remote auf einem anderen Computer ausgeführt werden, vor Softwareentwicklern zu verbergen. Dazu müssen alle Parameter als Wert übergeben werden. Dies bedeutet, dass der Aufrufer beim Aufrufen einer von einem COM-Objekt bereitgestellten Funktion die zugehörigen Parameter als Wert übergeben muss. Andererseits,Das COM-Objekt antwortet dem Aufrufer, indem es die Ergebnisse ebenfalls als Wert übergibt. Das Konvertieren von Parametern in Daten, die über das Netzwerk übertragen werden, wird als Marshalling bezeichnet. Nach Abschluss des Marshallings wird der Datenstrom serialisiert, übertragen und am anderen Ende der Verbindung in seiner ursprünglichen Datenreihenfolge wiederhergestellt.
DCOM verwendet den RPC-Mechanismus, um Informationen zwischen COM-Komponenten im selben Netzwerk transparent zu übertragen und zu empfangen. Der RPC-Mechanismus wurde von Microsoft entwickelt, damit Systementwickler die Ausführung von Remote-Programmen anfordern können, ohne spezielle Verfahren für den Server entwickeln zu müssen. Das Client-Programm sendet eine Nachricht mit den richtigen Argumenten an den Server, und der Server gibt eine Nachricht zurück, die die Ergebnisse des ausgeführten Programms enthält.
OPC Classic enthält eine Reihe von Einschränkungen:
- nur unter Betriebssystemen der Microsoft Windows-Familie verfügbar;
- Verbindung mit der DCOM-Technologie, deren Quellcode geschlossen ist.
- Konfigurationsprobleme im Zusammenhang mit DCOM;
- ungenaue DCOM-Kommunikationsunterbrechungsnachrichten;
- die Unfähigkeit von DCOM, Daten über das Internet auszutauschen;
- Unfähigkeit von DCOM, Informationssicherheit zu gewährleisten.
OPC Classic Datenerfassungsmodell
Die Ziele des OPC Classic-Standards sind folgende:
- Strukturieren Sie Daten auf der Serverseite, um das Sammeln von Daten auf der Clientseite zu vereinfachen.
- Definieren Sie Kommunikationsdienste und Standardkommunikationsmechanismen
Im Wesentlichen funktioniert der OPC Classic-Standard wie folgt.
Der Server verwaltet alle verfügbaren Daten.
Der Server sendet bei Bedarf Datenanforderungen von Geräten und aktualisiert den internen Cache regelmäßig. Der Server initialisiert und verwaltet den Cache für jede Gruppe von Variablen, die vom OPC-Client angefordert werden. Die Scanrate auf der OPC-Clientseite darf nicht niedriger sein als die Scanrate des OPC-Servers, um Daten von Geräten zu erfassen und den internen Cache zu aktualisieren. Es wird empfohlen, den OPC-Client so zu konfigurieren, dass er aus dem Cache liest und ihn doppelt so schnell aktualisiert, wie der OPC-Server nach Geräten sucht. Jedes ausgetauschte Datenelement hat seine eigene Bedeutung, die durch seinen Zeitstempel und seine Qualität angezeigt wird. Der Datenaustausch umfasst das Lesen, Schreiben und automatische Aktualisieren, wenn sich Werte ändern. Das Lesen oder Abrufen wird vom OPC-Client durchgeführt, der regelmäßig Anforderungen für Gruppendaten sendet.Die Aufnahmephase kann synchron oder asynchron sein. Automatische Updates verwenden die vom OPC-Client bereitgestellte Anforderungsrate. Der OPC-Server überprüft bei jeder Aktualisierung, ob der Absolutwert des zwischengespeicherten Werts abzüglich des aktuellen Werts größer ist als die vom Client angegebene Totzone multipliziert mit dem für diese Variable konfigurierten Bereich. Es kann so geschrieben werden:
if (abs(last_cached_value – current_value) > (PERCENT_DEAD_BAND/100) * range) {
//cache is updated, and the client is notified through a callback mechanism
}
Informationen vom OPC-Server sind aus Effizienzgründen in Gruppen verwandter Elemente organisiert. Es gibt zwei verschiedene Arten von Gruppen:
- Öffentliche Gruppen: Für jeden Kunden verfügbar
- Lokale Gruppen: Nur für den Client verfügbar, der sie erstellt hat
OPC UA
Die erste Reaktion der OPC Foundation auf die wachsenden Einschränkungen der Einführung von COM und DCOM war die Entwicklung von OPC XML-DA. Es behielt die Eigenschaften von OPC bei, übernahm jedoch eine Kommunikationsinfrastruktur, die weder dem Hersteller noch einer bestimmten Softwareplattform zugeordnet ist. Die Konvertierung von OPC-DA-Spezifikationen in webdienstbasierte Versionen hat sich als unzureichend erwiesen, um die Anforderungen von Unternehmen zu erfüllen, die zunehmend mit der Unternehmens- und Außenwelt interagieren und sich integrieren.
Informationen zur OPC UA-Architektur finden Sie unter opcfoundation.org/developer-tools/specifications-unified-architecture .
Daher wurde das OPC UA-Protokoll entwickelt, um alle vorhandenen COM-basierten Versionen zu ersetzen und Sicherheits- und Leistungsbedenken auszuräumen. Der Standard befasst sich mit der Notwendigkeit plattformunabhängiger Schnittstellen und ermöglicht die Erstellung erweiterbarer Datenmodelle zur Beschreibung komplexer Systeme ohne Funktionsverlust. OPC UA basiert auf dem serviceorientierten Ansatz, der in der Norm IEC 62451 definiert ist. Es verfolgt folgende Ziele:
- Verwenden von OPC-Komponenten auf Nicht-Windows-Plattformen
- Ermöglicht die Integration der Hauptkomponenten in kleine Geräte
- Implementiert die Standardkommunikation zwischen Firewall-basierten Systemen
Aus technischer Sicht funktioniert OPC UA wie folgt:
- Die API isoliert Client- und Servercode vom OPC-UA-Stack
- UA Stack konvertiert API-Aufrufe in Nachrichten
- Der UA-Stack empfängt Nachrichten, indem er sie über die API an den Client oder Server sendet

OPC UA Informationsmodell
Grundprinzipien der Informationsmodellierung in OPC UA:
- Verwendung objektorientierter Methoden einschließlich Vererbungshierarchie.
- Der gleiche Mechanismus wird für den Zugriff auf Typen und Instanzen verwendet.
- Informationen werden durch die Verwendung vollständig verbundener Knoten im Netzwerk verfügbar gemacht.
- Datentyphierarchien und Verknüpfungen zwischen Knoten sind erweiterbar.
- Es gibt keine Einschränkungen beim Modellieren von Informationen.
- Die Informationsmodellierung wird immer auf der Serverseite gehostet.
Der Satz von Objekten und zugehörigen Informationen, die der OPC UA-Server Clients zur Verfügung stellt, ist der Adressraum. Sie können sich den Adressraum als Implementierung des OPC UA-Informationsmodells vorstellen.
Ein OPC UA-Adressraum ist eine Sammlung von Knoten, die durch Links verbunden sind. Jeder Knoten verfügt über Eigenschaften, die als Attribute bezeichnet werden. Auf allen Knoten muss ein bestimmter Satz von Attributen vorhanden sein. Die Beziehung zwischen Knoten, Attributen und Verknüpfungen ist in der folgenden Abbildung dargestellt
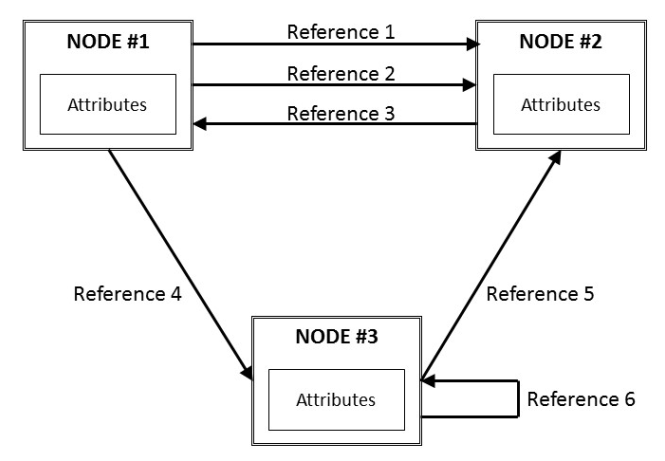
Knoten können je nach ihrem spezifischen Zweck zu verschiedenen Klassen von Knoten gehören. Einige Knoten können Instanzen darstellen, andere können Typen usw. darstellen. OPC UA verfügt über acht Standardknotenklassen: Variable, Objekt, Methode, Ansicht, Datentyp, Variablentyp, Objekttyp und Referenztyp. In OPC UA sind die wichtigsten Knotenklassen Objekt, Variable und Methode.
OPC UA-Sitzungen
OPC UA bietet ein Client-Server-Kommunikationsmodell, das Statusinformationen enthält. Diese Statusinformationen sind sitzungsbezogen. Eine Sitzung ist als logische Verbindung zwischen einem Client und einem Server definiert. Jede Sitzung ist unabhängig vom zugrunde liegenden Kommunikationsprotokoll. Ein Problem auf Protokollebene beendet die Sitzung nicht automatisch. Die Sitzung endet nach einer expliziten Anforderung des Clients oder aufgrund von Inaktivität des Clients. Leerlaufintervalle werden während der Sitzungserstellung festgelegt.
OPC UA-Sicherheitsmodell
Das OPC UA-Sicherheitsmodell wird implementiert, indem der sichere Kanal definiert wird, auf dem die Sitzung basiert. Der sichere Kanal tauscht Daten wie folgt aus:
- Gewährleistet die Datenintegrität mithilfe digitaler Signaturen.
- Bietet Datenschutz durch Verschlüsselung.
- Authentifiziert und autorisiert Anwendungen mithilfe von X.509-Zertifikaten.
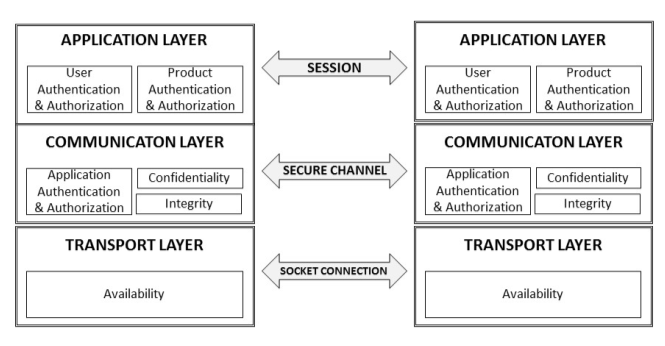
Die Abbildung zeigt die folgenden Ebenen: Anwendungsschicht, Sitzungsschicht und Transportschicht.
Die Anwendungsschicht wird zum Übertragen von Informationen zwischen Clients und Servern verwendet, die eine OPC-UA-Sitzung eingerichtet haben. Die OPC UA-Sitzung wird auf einem sicheren Kanal eingerichtet. Die Transportschicht ist die Schicht, die für das Senden und Empfangen von Daten über eine Socket-Verbindung verantwortlich ist, auf die Fehlerbehandlungsmechanismen angewendet werden, um sicherzustellen, dass das System vor Angriffen wie Denial-of-Service (DoS) geschützt ist.
OPC UA Datenaustausch
Der einfachste Weg, Daten zwischen einem OPC UA-Client und einem Server auszutauschen, ist die Verwendung von Lese- und Schreibdiensten. Lese- und Schreibdienste sind optimiert, um eine Gruppe von Daten anstelle eines einzelnen Datenelements oder mehrerer Werte zu übertragen. Mit ihnen können Sie entweder die Werte oder die Attribute der Knoten lesen und schreiben. Der
Lesedienst hat die folgenden Parameter: maxAge: Dies ist die maximale Zeit, die zum Abrufen der Werte benötigt wird. Dies wird vom Kunden angezeigt. Der Server wird gezwungen, ein Gerät (z. B. einen Sensor) zu kontaktieren, wenn die Kopie in seinem Cache älter als der vom Client konfigurierte Parameter maxAge ist. Wenn maxAge auf Null gesetzt ist, sollte der Server den aktuellen Wert bereitstellen und ihn immer direkt vom Gerät lesen.
Zeitstempeltyp: OPC UA definiert zwei Zeitstempel: den Quellzeitstempel und den Serverzeitstempel. Der ursprüngliche Zeitstempel ist der Zeitstempel, der vom Gerät stammt, und der Server-Zeitstempel ist der Zeitstempel, der vom Betriebssystem stammt, auf dem der OPC UA-Server ausgeführt wird.
Die Liste der Knoten und Attribute sieht folgendermaßen aus:
- NodeId
- AttributeId zum Beispiel Wert
- DataEncoding: Hiermit kann der Client eine geeignete Datencodierung auswählen. Die Standardeinstellungen sind XML, UA Binary
Merkmale des OPC-Protokolls
Das OPC-Protokoll kann nicht vollständig als frei bezeichnet werden. Um Software mit dem OPC SDK zu entwickeln, müssen Sie Mitglied der OPC Foundation sein. Derzeit gibt es jedoch kostenlose Implementierungen der Client- und Serverbibliothek , z. B. freeopcua.github.io , die jedoch noch keine Pub / Sub-Implementierung haben.
Im Vergleich zu anderen Protokollen wie MQTT ist OPC nicht leicht.
SPS-speicherprogrammierbare Steuerung
Der Begriff SPS (Speicherprogrammierbare Steuerung, SPS) wurde später in den Normen EN 61131 (IEC 61131) definiert. PLC ist ein einheitliches digitales elektronisches Steuerungssystem, das speziell für den Einsatz in industriellen Umgebungen entwickelt wurde. Die SPS überwacht ständig den Status der Eingabegeräte und trifft basierend auf dem Anwenderprogramm Entscheidungen, um den Status der Ausgabegeräte zu steuern.
Anforderungen an die SPS:
- Es muss in der Lage sein, unter rauen industriellen Bedingungen wie extremen Temperaturen, Vorhandensein von Schmutz und einem Stromversorgungsnetz von schlechter Qualität zu funktionieren.
- Es sollte mit branchenspezifischen diskreten 24VDC- oder 240VAC-Eingangs- und Ausgangssignalen sowie analogen Signalen (± 10V, 4-20 mA usw.) betrieben werden.
- Die Programmiersprache muss von Automatisierungsingenieuren verstanden werden
- Die SPS muss den Betrieb der Industrieanlage kontinuierlich überwachen
- Das Betriebssystem muss schnell genug sein, um einen Scan-Zyklus durchzuführen (20 - 100 ms).
Die folgende Abbildung zeigt den Aufbau der Grundbetriebsart der SPS (am Beispiel von CPU Simatic).

OPC UA mit SIMATIC S7-1500
Voraussetzungen - Simatic TIA Portal V13-16 muss installiert sein
Um eine Steuerung mit einem OPC-Server zu simulieren, muss SIMATIC S7-PLCSIM Advanced Version 2 oder 3 installiert und konfiguriert sein.
Support.industry.siemens.com/cs/document/109772889/trial -download% 3A-simatic-s7-plcsim-advanced-v3-0? dti = 0 & lc = de-WWIch habe Simulator Version 3 auf einem System mit einem vorhandenen Simatic TIA Portal V14 SP1-Paket installiert. Vor der Installation hat das Installationsprogramm mitgeteilt, dass PLCSIM V14 nicht mit SIMATIC S7-PLCSIM V3 kompatibel ist und entfernt werden muss. Ich folgte diesen Schritten, wonach die Installation ausgesetzt wurde. Im TIA Portal wurde ein Testprojekt mit der CPU 1512C-1 PN erstellt. Eine Besonderheit war, dass es unmöglich wurde, eine Simulation mit der Schaltfläche "Simulation starten" durchzuführen, die Schaltfläche "Auf Gerät herunterladen" jedoch funktioniert, wenn PLCSIM Advanced ausgeführt wird.
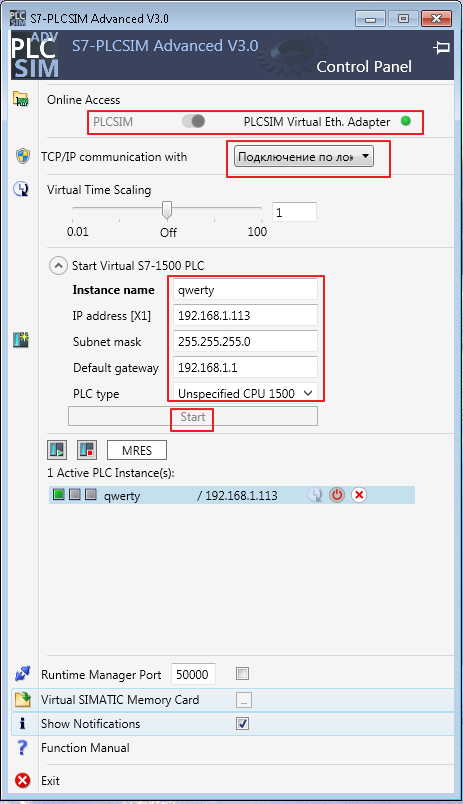
Um über das Netzwerk auf den Simulator zuzugreifen, müssen Sie PLCSIM Virtual Eth aktivieren. Adapter, für den Sie zuerst die WinPcap-Software installieren müssen. Als nächstes folgen die Standard-Ethernet-Einstellungen.
Nach dem Drücken der Taste "Start" wird der Simulator aktiv und im Netzwerk sichtbar
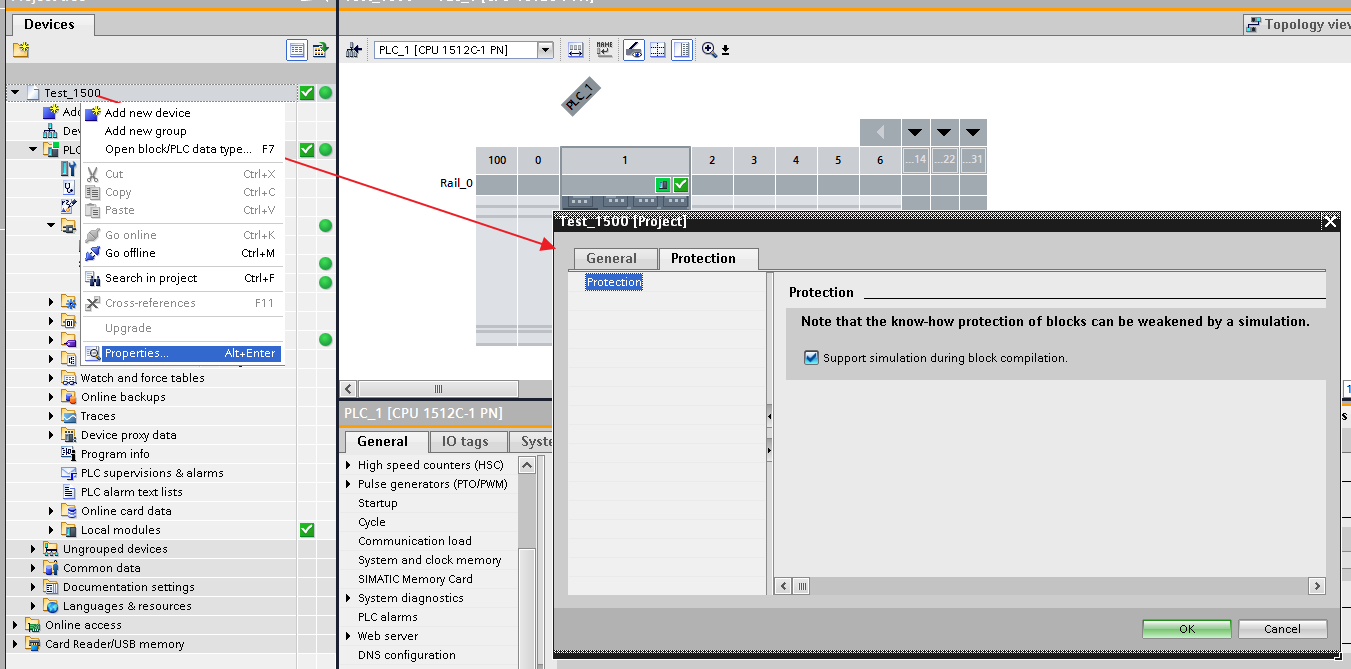
Als Nächstes müssen Sie das Kontrollkästchen "Simulation während der Blockkompilierung unterstützen" auf der Registerkarte "Schutz" im Dialogfeld aktivieren, um das Kontextmenü "Eigenschaften" im Projektstamm aufzurufen
Der nächste Schritt besteht darin, den OPC-Server im Projekt zu aktivieren und den Lizenztyp auszuwählen (Sie können ihn übersehen, danach wird das Projekt nicht kompiliert).

Darüber hinaus ähnelt das Hochladen von Software zu PLCSIM Advanced dem Hochladen auf einen Standardsimulator, mit Ausnahme des zuvor beschriebenen.
Im TIA Portal-Testprojekt wurde DB1 mit einem Tag „Druck“ erstellt und der Digitalausgang „Q0.1 Tag_2“ zugewiesen.
Um eine Verbindung zum OPC-Server herzustellen und das Netzwerk, die Knoten und Tags zu überwachen, können Sie den UaExpert OPC-Client verwenden, der von www.unified-automation.com/products/development-tools/uaexpert.html heruntergeladen werden kann .
Um eine Verbindung zum OPC-Server herzustellen, müssen Sie eine neue Verbindung hinzufügen und die Endpunkt-URL registrieren, die zuvor in den OPC-Server-Projekteinstellungen im TIA-Portale festgelegt wurde. In meinem Fall ist dies opc.tcp: //192.168.1.113: 4840

Wenn Sie den OPC-Client mit dem Simulatorserver verbinden, können Sie die erstellten Knoten und Tags beobachten.

Um die Interaktion zwischen OPC-Client und -Server programmgesteuert zu implementieren, können Sie die OpenSource-Implementierung der Bibliothek in Python github.com/FreeOpcUa/python-opcua verwenden . Es gibt auch Beispiele mit Code. Vor der Verwendung müssen Sie die erforderlichen Abhängigkeiten installieren:
pip install freeopcua
pip install cryptography
Das einfachste Beispiel für die Erstellung eines OPC-Servers mit drei Tags
from opcua import Server
from random import randint
import datetime
import time
class Opc:
def __init__(self):
self.server = Server()
self.url = "opc.tcp://127.0.0.1:4848"
self.server.set_endpoint(self.url)
self.namespace_uri = "OPCUA_SIMULATION_SERVER"
self.namespace = self.server.register_namespace(self.namespace_uri)
self.root_node = self.server.get_objects_node()
self.parameters = self.root_node.add_object(self.namespace, "Parameters")
def create_variable(self, name, initial=0):
variable = self.parameters.add_variable(self.namespace, name, initial)
variable.set_writable()
return variable
def main():
opc = Opc()
tag_1 = opc.create_variable("Temperature", 25)
tag_2 = opc.create_variable("Pressure")
tag_3 = opc.create_variable("Time")
opc.server.start()
print("Server started at {}".format(opc.url))
while True:
#tag_1.set_value(randint(10, 50))
tag_2.set_value(randint(200, 999))
tag_3.set_value(datetime.datetime.now())
time.sleep(2)
if __name__ == '__main__':
main()
Das gleiche einfachste Beispiel für den Client-Teil
from opcua import Client
import time
url = "opc.tcp://127.0.0.1:4848"
client = Client(url)
client.connect()
print("Client connected")
Temp = client.get_node("ns=2;i=2")
Temp.set_value(25)
if __name__ == '__main__':
while True:
temperature = Temp.get_value()
print(temperature)
time.sleep(1)
Es ist auch möglich, die Verbindung mit dem UaExpert-Client zu beobachten

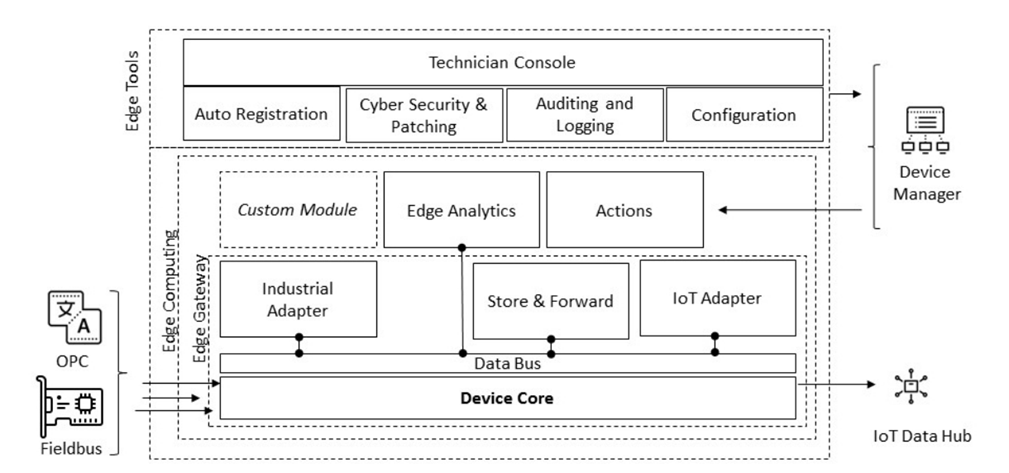
I-IoT Edge-Konzept
Edge ist die Drehscheibe zwischen der Produktionsumgebung und der IoT-Welt in der Cloud. Edge kann in drei Makrokomponenten zerlegt werden: Edge Gateway, Edge-Tools, Edge Computing
Im Jahr 2017 kündigte Gartner Folgendes an: "The Edge wird die Cloud auffressen." Diese Aussage mag etwas kontrovers klingen, unterstreicht jedoch die Rolle, die Edge im Laufe der Jahre gespielt hat. Industrieunternehmen erkannten nach einer Phase des Übergangs zur Cloud, dass es nicht immer möglich ist, alles an einem entfernten Ort zu erledigen. Die Gründe dafür sind folgende:
- . . , , . .
- : . , , , , 1 50 .
- Netzwerklatenz: Erweiterte Prozesskontrollen oder Analysen im Zusammenhang mit Datenänderungen am Verhalten von Profilgeräten in einem kleinen Zeitfenster leiden unter einer hohen und variablen Netzwerklatenz. Die Geräteoptimierung ist für die schnellstmögliche Ausführung innerhalb eines bestimmten Zeitintervalls erforderlich.
- Datenverbindung. Um den Workflow zu optimieren oder die Geräte zu warten, müssen Komponenten ohne Zugriff auf die Internetverbindung ausgetauscht werden.
Edge Gateway
Das Edge-Gateway ist der Kern des Edge-Geräts. Die Hauptaufgabe des Edge-Gateways besteht darin, eine Verbindung zu einer industriellen Quelle herzustellen, um Daten mithilfe eines Übertragungsprotokolls wie MQTT, CoAP, HTTPS oder AMQP zu sammeln und an den I-IoT-Hub zu senden.
Die wichtigsten Komponenten eines Edge-Gateways sind der Industrieadapter und der IoT-Adapter. Ein Industrieadapter abonniert normalerweise Daten aus dem Feldbereich und veröffentlicht sie auf dem Datenbus. In der Regel wird der Connector für das ausgewählte Gerät implementiert, der als Quelle im I-IoT-Datenstrom fungiert und auf dem Edge-Datenbus verfügbar ist. Ein IoT-Adapter hingegen empfängt Werte vom Datenbus und überträgt sie an den IoT Data Hub. Ein wichtiger Teil des Gateway Edge ist die Store-and-Forward-Komponente. Dies ist ein allgemeiner Mechanismus zum Speichern von Daten in einem temporären lokalen Speicher. Es bietet Robustheit der Datenübertragung gegen Netzwerkinstabilität. Im globalen Netzwerk sind die Instabilität und Latenz des Kommunikationskanals sehr hoch. Der Speicher- und Weiterleitungsmechanismus kann wie folgt sein:
- Begrenzter Speicherpuffer, der einen kurzen Zeitraum der Inaktivität abdeckt
- Ein dedizierter Speicherbereich auf der Festplatte, der lange Zeiträume der Inaktivität oder des großen Datenverkehrs aufnehmen kann.
Der Bereich des Zeitfensters, in dem die Datenübertragung sichergestellt werden muss, hängt von den spezifischen Szenarien und den physischen Ressourcen des Edge-Speichers und -Speichers ab.
Konfigurationsdienstprogramme (Edge-Tools)
Edge-Tools sollten die folgenden Funktionen aufweisen:
- Die Möglichkeit, die Datenerfassung sowohl remote als auch lokal einfach zu verwalten und zu konfigurieren
- Möglichkeit zur Registrierung für Fixes und Updates
- Möglichkeit der Protokollierung von Aktionen
- Möglichkeit zum Anzeigen und Ändern von Daten über die Benutzeroberfläche
- Selbstkonfiguration und Selbstregistrierung in der Cloud beim Start
- Fähigkeit, Befehle aus der Cloud zu empfangen und auszuführen
Edge Computing
Edge Computing bietet die folgenden Funktionen:
- Möglichkeit, Aktionen mit I-IoT-Software (Middleware) sowohl offline als auch online auszuführen.
- Möglichkeit, benutzerdefinierte Anwendungen zu hosten
- Die Möglichkeit, Analysen offline, in Verbindung mit I-IoT-Middleware oder remote auszuführen.
- Möglichkeit zum Ausführen von Aktionen oder Laden von Analysen aus der I-IoT-Middleware
- Möglichkeit, unstrukturierte und spezifische Daten bei Bedarf oder bei bedingtem Start an die I-IoT-Middleware zu senden
Edge-Implementierungen
Cloud-Anbieter und Original Equipment Manufacturers (OEMs) entwickeln verschiedene Lösungen basierend auf ihrem eigenen Betriebssystem oder bieten Cloud-unabhängige Software Development Kits (SDKs) an.
Azure IoT Edge
Azure IoT Edge ist die Edge-Lösung von Microsoft für Azure IoT. Die Plattform unterstützt Speicherung und Weiterleitung, Edge Analytics und mehrere Adapter zum Konvertieren nativer oder Standardprotokolle in Internetprotokolle. Azure IoT Edge unterstützt auch OPC Server in seinen OPC Classic- und OPC-UA-Implementierungen. Produktübersicht:
- Funktioniert mit Linux- oder Windows-Geräten, die Container-Subsysteme unterstützen.
- Kostenlose Open Source-Laufzeit mit MIT-Lizenz
- Docker-kompatible Container von Azure-Diensten oder vom Cloud-Frontend des Microsoft-Partners. Ermöglicht die Remoteverwaltung und Bereitstellung von Workloads aus der Cloud mithilfe von IoT Hub
Grünes Gras
Greengrass ist die nächste Generation von IoT Edge von AWS. AWS bietet das SDK zum Erstellen von AWS Edge und erweitert die Cloud-Funktionen auf Edge-Geräte mit Greengrass. Auf diese Weise können Geräte lokal Maßnahmen ergreifen, während die Cloud weiterhin für die Verwaltung, Analyse und dauerhafte Speicherung verwendet wird. Greengrass unterstützt OPC UA und OPC Classic nicht. Leistungen:
- Nahezu Echtzeit-Ereignisantwort
- Offline arbeiten
- AWS IoT Greengrass authentifiziert und verschlüsselt Gerätedaten sowohl über das LAN als auch über die Cloud
- Vereinfachte Geräteprogrammierung mit Containerunterstützung
Android Dinge
Google bietet ein SDK für die Edge-Entwicklung. Es sponsert Android als die nächste Generation von Edge-Geräten. Plattformfunktionen:
- Entwicklung mit Android SDK und Android Studio
- Zugriff auf Hardware wie Display und Kamera über die Android-Plattform
- Verbinden der App mit Google-Diensten
- Integration zusätzlicher Peripheriegeräte über die Peripherie-E / A-API (GPIO, I2C, SPI, UART, PWM)
- Verwenden der Android Things Console zum Senden von Updates über Funk und Sicherheitsupdates
Knoten-ROT
Es ist ein visuelles Programmiertool für das Internet der Dinge, mit dem Geräte, APIs und Onlinedienste miteinander verbunden werden können. Die Node-RED-Laufzeit basiert auf Node.js und nutzt daher das ereignisgesteuerte, nicht blockierende Modell optimal aus. Node-RED ist ein Streaming-Programmiertool, das ursprünglich vom IBM Emerging Technology Services-Team entwickelt wurde und derzeit Teil der JS Foundation ist.
Eigenschaften:
- Erstellen Sie die Programmlogik direkt im Browser
- Die Node-RED-Laufzeit basiert auf Node.js.
- In Node-RED erstellte Streams (logische Einheiten) werden in JSON-Dateien gespeichert, die einfach exportiert und importiert werden können
- Das Ausführen ist auf jedem Gerät möglich, das node.js unterstützt
- Eine Vielzahl von Erweiterungen
Intel IoT Gateway
Eigenschaften:
- Cloud- und Unternehmenskonnektivität.
- Anschließbar an Sensoren und vorhandene Steuerungen.
- Vorfilterung der ausgewählten Daten für die Lieferung.
- Lokale Entscheidungsfindung zur Gewährleistung einer einfachen Konnektivität mit Legacy-Systemen.
- Hardware-Datenverschlüsselung und Software-Sperre.
- Lokale Datenverarbeitung und Analyse auf dem Gerät.
Flogo iot
Project Flogo ist ein leichtes Open-Source-Go-basiertes Ökosystem zum Erstellen ereignisgesteuerter Anwendungen. Trigger und Aktionen werden verwendet, um eingehende Ereignisse zu verarbeiten. Die Interaktionsschnittstelle bietet wichtige Funktionen wie Anwendungsintegration, Stream-Verarbeitung usw.
- Integration Flows Application Engine mit bedingter Verzweigung und visueller Entwicklungsumgebung
- Streaming ist eine einfache Pipeline-basierte Stream-Verarbeitungsaktion mit der Fähigkeit, Ereignisse über mehrere Trigger hinweg und über Zeitfenster hinweg zu aggregieren.
- Deklarative Regeln für kontextbezogene Entscheidungen in Echtzeit
- Microgateway-Muster für inhaltsbasiertes bedingtes Routing, JWT-Validierung, Ratenbegrenzung, Unterbrechung des Stromkreises und mehr
Eclipse kura
Eclipse Kura ist ein Open Source, erweiterbares IoT Edge Framework, das auf Java / OSGi basiert. Kura bietet API-Zugriff auf IoT-Gateway-Hardwareschnittstellen (serielle Schnittstellen, GPS, Watchdog-Timer, GPIO, I2C usw.). Es enthält einsatzbereite Feldprotokolle (einschließlich Modbus, OPC-UA, S7), einen Anwendungscontainer und eine webbasierte visuelle Programmierung für die Datenerfassung, -verarbeitung und -veröffentlichung auf Cloud-Plattformen.
EdgeX-Gießerei
EdgeX FoundryTM ist ein herstellerneutrales Open Source-Projekt, das von der Linux Foundation unterstützt wird und eine gemeinsame offene Umgebung für IoT Edge Computing erstellt. Im Mittelpunkt des Projekts steht eine Interoperabilitätsinfrastruktur, die auf einer vollständigen betriebssystemunabhängigen Referenzsoftwareplattform gehostet wird, um ein Plug-and-Play-Ökosystem zu schaffen, das den Markt vereinheitlicht und die Bereitstellung von IoT-Lösungen beschleunigt.
Edge-Konnektivitätsoptionen für industrielle Datenquellen
- Kante am Feldbus
- Edge auf OPC DCOM
- Edge auf OPC-Proxy
- Rand auf OPC UA
- OPC UA auf dem Controller
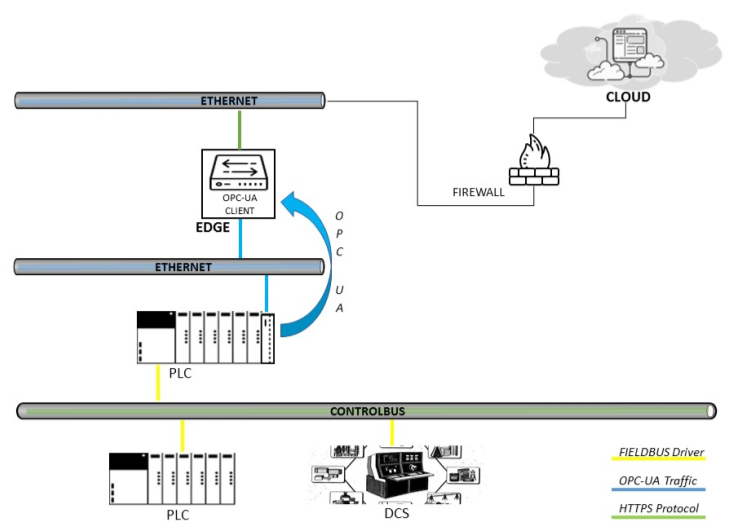
Edge am OPC UA und am Controller
Die Verbindung zu einem OPC UA-Server ist das bevorzugte Szenario, da dadurch die Funktionen von OPC UA maximiert werden. Die Verbindung zum OPC-Server kann auf zwei verschiedene Arten bereitgestellt werden. Im ersten Fall stellt Edge über seine OPC UA-Clientschnittstelle eine Verbindung zum OPC UA-Server her. Die Datenquelle kann eine der folgenden sein: SPS, DCS, SCADA oder Historian.

Im zweiten Fall stellt der Edge eine Verbindung zu dem direkt auf der SPS installierten OPC-Server her, wie zuvor mit der Simatic CPU 1500 erläutert.
MQTT-Protokoll
Pub / Sub ist eine Möglichkeit, einen Client, der eine Nachricht sendet, von einem anderen Client zu trennen, der eine Nachricht empfängt. Im Gegensatz zum Client-Server-Modell kennen Clients keine physischen Kennungen wie eine IP-Adresse oder einen Port. MQTT ist eine Pub / Sub-Architektur, keine Nachrichtenwarteschlange. Nachrichtenwarteschlangen speichern naturgemäß Nachrichten, MQTT hingegen nicht. Wenn in MQTT niemand ein Thema abonniert (oder hört), wird es einfach ignoriert und geht verloren.

Der Client, der die Nachricht sendet, wird als Herausgeber bezeichnet. Der Client, der die Nachricht empfängt, wird als Abonnent bezeichnet. Im Zentrum steht der MQTT-Broker, der für die Verbindung von Clients und das Filtern von Daten verantwortlich ist. Solche Filter bieten:
- Filtern nach Themen - Kunden abonnieren nach Design Themen und bestimmte Themenbereiche und erhalten nicht mehr Daten als sie möchten. Jede gepostete Nachricht muss einen Betreff enthalten, und der Broker ist dafür verantwortlich, diese Nachricht erneut an Abonnenten zu senden oder zu ignorieren.
- Inhaltsfilterung - Broker können veröffentlichte Daten überprüfen und filtern. Somit können alle Daten, die nicht verschlüsselt sind, vom Broker verwaltet werden, bevor sie gespeichert oder an andere Clients übertragen werden.
- Filtern nach Typ - Ein Client, der einen Datenstrom abhört, den er abonniert hat, kann auch seine eigenen Filter anwenden. Eingehende Daten können analysiert werden, und abhängig davon wird der Datenstrom weiterverarbeitet oder ignoriert.
In MQTT gibt es drei Ebenen der Servicequalität:
- QoS-0 ( ) – QoS. « », . ;
- QoS-1 ( ) – . , PUBACK;
- QoS-2 ( ) – QoS, , . - . QoS-2, PUBREC. , PUBREL. PUBREL . PUBREL PUBCOMP. PUBCOMP , .
Derzeit gibt es zwei Versionen der MQTT-Protokollspezifikation: 3.1.1 und 5.0 . Eine detailliertere Beschreibung des Protokolls finden Sie hier oder eine Aufzeichnung meiner Präsentation github.com/vladipirogov/Message-Queue-Telemetry-Transport , www.youtube.com/watch?v=fYoGubQFz5c&t=5s und www.youtube.com/watch?v=8mupuCjedlc .
Im nächsten Artikel werde ich versuchen, ein Beispiel für die Implementierung einer benutzerdefinierten Edge I-IoT-Plattform mit Node-Red als Edge-Gateway, Apache Kafka als Datenmanager und temporärem Speicher, Kafka Streams als Rule Engine und Mosquitto (eine weitere Implementierung ist möglich) als MQTT-Connector zu zeigen ... InfluxData-Technologien werden zum Speichern von Zeitreihendaten verwendet.
Link zum Video des Meetups.
Informationsquellen
- Digitale Transformationsplattform
- OPC Unified Architecture-Spezifikation
- Enzyklopädie von ACS TP
- FreeOpcUa ist ein Projekt zur Implementierung eines Open-Source-OPC-UA-Stacks (LGPL) und zugehöriger Tools.
- GR Kanagachidambaresan Internet der Dinge für Industrie 4.0
- Max Hoffmann Smart Agents für die Industrie 4.0
- Wolfgang Mahnke OPC Einheitliche Architektur
- Klaus Schwab Vierte industrielle Revolution
- Perry Lee Internet der Dinge Architektur
- Ismail Butun Industrial IoT
- MQTT-Spezifikationen