Während Sprachen wie Python und R für Data Science immer beliebter werden, können C und C ++ eine gute Wahl sein, um Probleme in Data Science effizient zu lösen. In diesem Artikel werden wir C99 und C ++ 11 verwenden, um ein Programm zu schreiben, das mit dem Anscombe-Quartett zusammenarbeitet, das ich als nächstes diskutieren werde.
Ich schrieb über meine Motivation, ständig Sprachen zu lernen, in einem Artikel über Python und GNU Octave, der es wert ist, gelesen zu werden. Alle Programme sind für die Befehlszeile vorgesehen, keine grafische Benutzeroberfläche (GUI). Vollständige Beispiele finden Sie im Repository polyglot_fit.
Programmierherausforderung
Das Programm, das Sie in dieser Reihe schreiben werden:
- Liest Daten aus einer CSV-Datei
- Interpoliert Daten mit einer geraden Linie (d. H. F (x) = m ≤ x + q).
- Schreibt das Ergebnis in eine Bilddatei
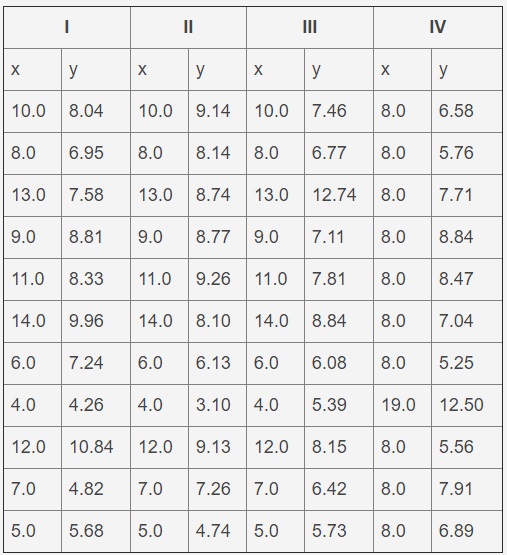
Dies ist eine häufige Herausforderung für viele Datenwissenschaftler. Ein Beispiel für Daten ist der erste Satz des Anscombe-Quartetts, der in der folgenden Tabelle dargestellt ist. Dies ist ein Satz künstlich konstruierter Daten, die bei Anpassung an eine gerade Linie dieselben Ergebnisse liefern, deren Diagramme jedoch sehr unterschiedlich sind. Eine Datendatei ist eine Textdatei mit Registerkarten zum Trennen von Spalten und mehreren Zeilen, die eine Kopfzeile bilden. Dieses Problem verwendet nur den ersten Satz (d. H. Die ersten beiden Spalten).
Anscombe Quartett
Lösung in C.
C ist eine universelle Programmiersprache, die heute eine der beliebtesten Sprachen ist ( gemessen am TIOBE-Index , den RedMonk-Ranglisten für Programmiersprachen , dem Programmiersprachen- Beliebtheitsindex und der GitHub-Forschung ). Es ist eine alte Sprache (sie wurde um 1973 erstellt) und viele erfolgreiche Programme wurden darin geschrieben (zum Beispiel der Linux-Kernel und Git). Diese Sprache ist auch so nah wie möglich am Innenleben eines Computers, da sie für die direkte Speicherverwaltung verwendet wird. Da es sich um eine kompilierte Sprache handelt , muss der Quellcode vom Compiler in Maschinencode übersetzt werden . SeineDie Standardbibliothek ist klein und leicht, daher wurden andere Bibliotheken entwickelt, um die fehlende Funktionalität bereitzustellen.
Dies ist die Sprache, die ich am häufigsten zum Zerkleinern von Zahlen verwende , hauptsächlich wegen ihrer Leistung. Ich finde es ziemlich mühsam zu verwenden, da es viel Boilerplate-Code erfordert , aber es wird in einer Vielzahl von Umgebungen gut unterstützt. Der C99-Standard ist eine kürzlich überarbeitete Version, die einige raffinierte Funktionen hinzufügt und von Compilern gut unterstützt wird.
Ich werde die Voraussetzungen für die Programmierung in C und C ++ behandeln, damit sowohl Anfänger als auch erfahrene Benutzer diese Sprachen verwenden können.
Installation
Die C99-Entwicklung erfordert einen Compiler. Normalerweise benutze ich Clang , aber GCC , ein weiterer vollwertiger Open Source- Compiler , wird es tun . Um die Daten anzupassen, entschied ich mich für die wissenschaftliche Bibliothek der GNU . Zum Plotten konnte ich keine vernünftige Bibliothek finden und daher stützt sich dieses Programm auf ein externes Programm: Gnuplot . Das Beispiel verwendet auch eine dynamische Datenstruktur zum Speichern von Daten, die in der Berkeley Software Distribution (BSD ) definiert ist.
Die Installation unter Fedora ist sehr einfach:
sudo dnf install clang gnuplot gsl gsl-develCode Kommentare
In C99 werden Kommentare durch Hinzufügen von // am Zeilenanfang formatiert, und der Rest der Zeile wird vom Interpreter verworfen. Alles zwischen / * und * / wird ebenfalls verworfen.
// .
/* */Erforderliche Bibliotheken
Bibliotheken bestehen aus zwei Teilen:
- Header-Datei mit Beschreibung der Funktionen
- Quelldatei mit Funktionsdefinitionen
Header-Dateien sind im Quellcode enthalten, und der Quellcode der Bibliotheken ist mit der ausführbaren Datei verknüpft. Daher werden für dieses Beispiel die Header-Dateien benötigt:
// -
#include <stdio.h>
//
#include <stdlib.h>
//
#include <string.h>
// "" BSD
#include <sys/queue.h>
// GSL
#include <gsl/gsl_fit.h>
#include <gsl/gsl_statistics_double.h>Hauptfunktion
In C muss sich das Programm in einer speziellen Funktion namens main () befinden :
int main(void) {
...
}Hier können Sie einen Unterschied zu Python feststellen, der im letzten Tutorial besprochen wurde, da im Fall von Python der in den Quelldateien gefundene Code ausgeführt wird.
Variablen definieren
In C müssen Variablen deklariert werden, bevor sie verwendet werden, und sie müssen einem Typ zugeordnet sein. Wann immer Sie eine Variable verwenden möchten, müssen Sie entscheiden, welche Daten darin gespeichert werden sollen. Sie können auch angeben, ob Sie die Variable als konstanten Wert verwenden möchten, was nicht erforderlich ist, aber der Compiler kann von diesen Informationen profitieren. Beispiel aus dem Programm fit_C99.c im Repository:
const char *input_file_name = "anscombe.csv";
const char *delimiter = "\t";
const unsigned int skip_header = 3;
const unsigned int column_x = 0;
const unsigned int column_y = 1;
const char *output_file_name = "fit_C99.csv";
const unsigned int N = 100;Arrays in C sind nicht dynamisch in dem Sinne, dass ihre Länge im Voraus bestimmt werden muss (d. H. Vor der Kompilierung):
int data_array[1024];Verwenden Sie eine einfach verknüpfte Liste, da Sie normalerweise nicht wissen, wie viele Datenpunkte sich in der Datei befinden . Es ist eine dynamische Datenstruktur, die unbegrenzt wachsen kann. Glücklicherweise bietet BSD einfach verknüpfte Listen an . Hier ist eine Beispieldefinition:
struct data_point {
double x;
double y;
SLIST_ENTRY(data_point) entries;
};
SLIST_HEAD(data_list, data_point) head = SLIST_HEAD_INITIALIZER(head);
SLIST_INIT(&head);In diesem Beispiel wird eine Liste data_point definiert , die aus strukturierten Werten besteht, die sowohl x- als auch y- Werte enthalten . Die Syntax ist recht komplex, aber intuitiv, und eine detaillierte Beschreibung wäre zu ausführlich.
Ausdrucken
Zum Drucken auf dem Terminal können Sie die Funktion printf () verwenden , die wie die Funktion printf () in Octave funktioniert (im ersten Artikel beschrieben):
printf("#### C99 ####\n");Die Funktion printf () fügt nicht automatisch eine neue Zeile am Ende der gedruckten Zeile hinzu. Sie müssen sie daher selbst hinzufügen. Das erste Argument ist eine Zeichenfolge, die Informationen zum Format anderer Argumente enthalten kann, die an die Funktion übergeben werden können, z. B.:
printf("Slope: %f\n", slope);Daten lesen
Jetzt kommt der schwierige Teil ... Es gibt mehrere Bibliotheken zum Parsen von CSV-Dateien in C, aber keine hat sich als stabil oder beliebt genug erwiesen, um im Fedora-Paket-Repository zu sein. Anstatt eine Abhängigkeit für dieses Tutorial hinzuzufügen, habe ich beschlossen, diesen Teil selbst zu schreiben. Auch hier wäre es zu wortreich, auf Details einzugehen, daher werde ich nur die allgemeine Idee erläutern. Einige Zeilen im Quellcode werden der Kürze halber ignoriert, ein vollständiges Beispiel finden Sie jedoch im Repository.
Öffnen Sie zuerst die Eingabedatei:
FILE* input_file = fopen(input_file_name, "r");Lesen Sie dann die Datei Zeile für Zeile, bis ein Fehler auftritt oder bis die Datei endet:
while (!ferror(input_file) && !feof(input_file)) {
size_t buffer_size = 0;
char *buffer = NULL;
getline(&buffer, &buffer_size, input_file);
...
}Die Funktion getline () ist eine nette Neuerung im POSIX.1-2008-Standard . Es kann eine ganze Zeile in einer Datei lesen und sich um die Zuweisung des erforderlichen Speichers kümmern. Jede Zeile wird dann mit der Funktion strtok () in Token aufgeteilt . Wählen Sie im Token die Spalten aus, die Sie benötigen:
char *token = strtok(buffer, delimiter);
while (token != NULL)
{
double value;
sscanf(token, "%lf", &value);
if (column == column_x) {
x = value;
} else if (column == column_y) {
y = value;
}
column += 1;
token = strtok(NULL, delimiter);
}Fügen Sie schließlich mit den ausgewählten x- und y-Werten einen neuen Punkt zur Liste hinzu:
struct data_point *datum = malloc(sizeof(struct data_point));
datum->x = x;
datum->y = y;
SLIST_INSERT_HEAD(&head, datum, entries);Die Funktion malloc () reserviert (reserviert) dynamisch eine Menge permanenten Speichers für einen neuen Punkt.
Daten anpassen
Die lineare Interpolationsfunktion gsl_fit_linear () von GSL akzeptiert reguläre Arrays als Eingabe. Da Sie die Größe der erstellten Arrays nicht im Voraus kennen, müssen Sie ihnen daher manuell Speicher zuweisen:
const size_t entries_number = row - skip_header - 1;
double *x = malloc(sizeof(double) * entries_number);
double *y = malloc(sizeof(double) * entries_number);Gehen Sie dann die Liste durch, um die relevanten Daten in den Arrays zu speichern:
SLIST_FOREACH(datum, &head, entries) {
const double current_x = datum->x;
const double current_y = datum->y;
x[i] = current_x;
y[i] = current_y;
i += 1;
}Nachdem Sie mit der Liste fertig sind, bereinigen Sie die Bestellung. Immer freier Speicher, der manuell zugewiesen wurde, um Speicherlecks zu vermeiden . Speicherlecks sind schlecht, schlecht und wieder schlecht. Jedes Mal, wenn die Erinnerung nicht befreit wird, verliert der Gartenzwerg den Kopf:
while (!SLIST_EMPTY(&head)) {
struct data_point *datum = SLIST_FIRST(&head);
SLIST_REMOVE_HEAD(&head, entries);
free(datum);
}Endlich, endlich (!) Können Sie Ihre Daten anpassen:
gsl_fit_linear(x, 1, y, 1, entries_number,
&intercept, &slope,
&cov00, &cov01, &cov11, &chi_squared);
const double r_value = gsl_stats_correlation(x, 1, y, 1, entries_number);
printf("Slope: %f\n", slope);
printf("Intercept: %f\n", intercept);
printf("Correlation coefficient: %f\n", r_value);Zeichnen eines Diagramms
Um ein Diagramm zu erstellen, müssen Sie ein externes Programm verwenden. Behalten Sie also die Anpassungsfunktion in einer externen Datei:
const double step_x = ((max_x + 1) - (min_x - 1)) / N;
for (unsigned int i = 0; i < N; i += 1) {
const double current_x = (min_x - 1) + step_x * i;
const double current_y = intercept + slope * current_x;
fprintf(output_file, "%f\t%f\n", current_x, current_y);
}Der Gnuplot-Plotbefehl sieht folgendermaßen aus:
plot 'fit_C99.csv' using 1:2 with lines title 'Fit', 'anscombe.csv' using 1:2 with points pointtype 7 title 'Data'Ergebnisse
Bevor Sie das Programm ausführen, müssen Sie es kompilieren:
clang -std=c99 -I/usr/include/ fitting_C99.c -L/usr/lib/ -L/usr/lib64/ -lgsl -lgslcblas -o fitting_C99Dieser Befehl weist den Compiler an, den C99-Standard zu verwenden, die Datei fit_C99.c zu lesen, die Bibliotheken gsl und gslcblas zu laden und das Ergebnis in fit_C99 zu speichern. Die resultierende Ausgabe in der Befehlszeile:
#### C99 ####
: 0.500091
: 3.000091
: 0.816421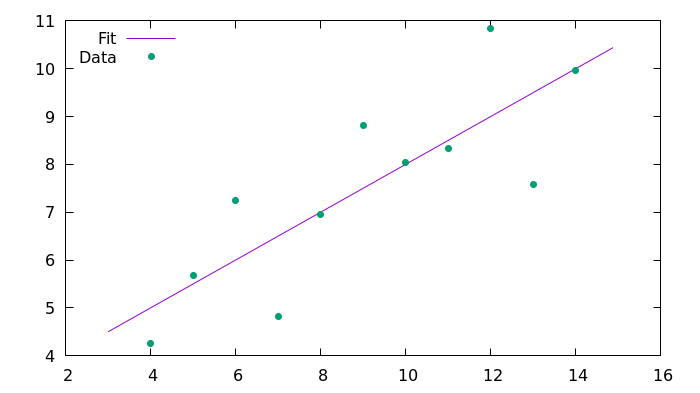
Hier ist das resultierende Bild, das mit Gnuplot generiert wurde.
C ++ 11-Lösung
C ++ ist eine universelle Programmiersprache, die auch heute eine der beliebtesten Sprachen ist. Es wurde als Nachfolger der C-Sprache (1983) mit Schwerpunkt auf objektorientierter Programmierung (OOP) geschaffen. C ++ wird im Allgemeinen als Obermenge von C betrachtet, daher muss ein C-Programm mit einem C ++ - Compiler kompiliert werden. Dies ist nicht immer der Fall, da es einige Randfälle gibt, in denen sie sich unterschiedlich verhalten. Nach meiner Erfahrung erfordert C ++ weniger Boilerplate-Code als C, aber seine Syntax ist komplexer, wenn Sie Objekte entwerfen möchten. Der C ++ 11-Standard ist eine aktuelle Version, die einige raffinierte Funktionen hinzufügt, die von Compilern mehr oder weniger unterstützt werden.
Da C ++ ziemlich C-kompatibel ist, werde ich mich nur auf die Unterschiede zwischen den beiden konzentrieren. Wenn ich in diesem Teil keinen Abschnitt beschreibe, bedeutet dies, dass er derselbe ist wie in C.
Installation
Die Abhängigkeiten für C ++ sind dieselben wie für Beispiel C. Führen Sie unter Fedora den folgenden Befehl aus:
sudo dnf install clang gnuplot gsl gsl-develErforderliche Bibliotheken
Die Bibliotheken funktionieren genauso wie in C, aber die include-Anweisungen unterscheiden sich geringfügig:
#include <cstdlib>
#include <cstring>
#include <iostream>
#include <fstream>
#include <string>
#include <vector>
#include <algorithm>
extern "C" {
#include <gsl/gsl_fit.h>
#include <gsl/gsl_statistics_double.h>
}Da die GSL-Bibliotheken in C geschrieben sind, muss der Compiler über diese Funktion informiert werden.
Variablen definieren
C ++ unterstützt mehr Datentypen (Klassen) als C, z. B. der Zeichenfolgentyp, der viel mehr Funktionen als sein C-Gegenstück bietet. Aktualisieren Sie Ihre Variablendefinitionen entsprechend:
const std::string input_file_name("anscombe.csv");Für strukturierte Objekte wie Zeichenfolgen können Sie eine Variable definieren, ohne das Zeichen = zu verwenden .
Ausdrucken
Sie können die Funktion printf () verwenden , es ist jedoch üblicher, cout zu verwenden . Verwenden Sie den Operator << , um die Zeichenfolge (oder Objekte) anzugeben, die Sie mit cout drucken möchten :
std::cout << "#### C++11 ####" << std::endl;
...
std::cout << " : " << slope << std::endl;
std::cout << ": " << intercept << std::endl;
std::cout << " : " << r_value << std::endl;Daten lesen
Die Schaltung ist die gleiche wie zuvor. Die Datei wird Zeile für Zeile geöffnet und gelesen, jedoch mit einer anderen Syntax:
std::ifstream input_file(input_file_name);
while (input_file.good()) {
std::string line;
getline(input_file, line);
...
}String-Token werden mit derselben Funktion wie im C99-Beispiel abgerufen. Verwenden Sie zwei Vektoren anstelle von Standard-C-Arrays . Vektoren sind eine Erweiterung von C-Arrays in der C ++ - Standardbibliothek , um den Speicher dynamisch zu verwalten, ohne malloc () aufzurufen :
std::vector<double> x;
std::vector<double> y;
// x y
x.emplace_back(value);
y.emplace_back(value);Daten anpassen
Um Daten in C ++ anzupassen, müssen Sie sich keine Gedanken über Listen machen, da Vektoren garantiert über sequentiellen Speicher verfügen. Sie können Zeiger auf Vektorpuffer direkt an die Anpassungsfunktionen übergeben:
gsl_fit_linear(x.data(), 1, y.data(), 1, entries_number,
&intercept, &slope,
&cov00, &cov01, &cov11, &chi_squared);
const double r_value = gsl_stats_correlation(x.data(), 1, y.data(), 1, entries_number);
std::cout << " : " << slope << std::endl;
std::cout << ": " << intercept << std::endl;
std::cout << " : " << r_value << std::endl;Zeichnen eines Diagramms
Das Plotten erfolgt auf die gleiche Weise wie zuvor. In Datei schreiben:
const double step_x = ((max_x + 1) - (min_x - 1)) / N;
for (unsigned int i = 0; i < N; i += 1) {
const double current_x = (min_x - 1) + step_x * i;
const double current_y = intercept + slope * current_x;
output_file << current_x << "\t" << current_y << std::endl;
}
output_file.close();Verwenden Sie dann Gnuplot, um das Diagramm zu zeichnen.
Ergebnisse
Bevor das Programm ausgeführt wird, muss es mit einem ähnlichen Befehl kompiliert werden:
clang++ -std=c++11 -I/usr/include/ fitting_Cpp11.cpp -L/usr/lib/ -L/usr/lib64/ -lgsl -lgslcblas -o fitting_Cpp11Resultierende Ausgabe in der Befehlszeile:
#### C++11 ####
: 0.500091
: 3.00009
: 0.816421Und hier ist das resultierende Bild, das mit Gnuplot generiert wurde.
Fazit
Dieser Artikel enthält Beispiele für das Anpassen und Plotten von Daten in C99 und C ++ 11. Da C ++ weitgehend mit C kompatibel ist, verwendet dieser Artikel die Ähnlichkeiten, um ein zweites Beispiel zu schreiben. In einigen Aspekten ist C ++ einfacher zu verwenden, da es die explizite Speicherverwaltung teilweise entlastet, seine Syntax jedoch komplexer ist, da es die Möglichkeit einführt, Klassen für OOP zu schreiben. Sie können jedoch auch mit OOP-Techniken in C schreiben, da OOP ein Programmierstil ist und in jeder Sprache verwendet werden kann. Es gibt einige großartige Beispiele für OOP in C, wie z. B. die Bibliotheken GObject und Jansson .
Ich bevorzuge C99 für die Arbeit mit Zahlen wegen seiner einfacheren Syntax und breiteren Unterstützung. Bis vor kurzem wurde C ++ 11 nicht allgemein unterstützt und ich habe versucht, die Ecken und Kanten in früheren Versionen zu vermeiden. Für komplexere Software ist C ++ möglicherweise eine gute Wahl.
Verwenden Sie C oder C ++ für Data Science? Teilen Sie Ihre Erfahrungen in den Kommentaren.

In den kostenpflichtigen Online-Kursen von SkillFactory erfahren Sie, wie Sie einen hochkarätigen Beruf von Grund auf neu aufbauen oder Ihre Fähigkeiten und Ihr Gehalt verbessern können:
- Kurs für maschinelles Lernen (12 Wochen)
- Data Science von Grund auf lernen (12 Monate)
- Analytics-Beruf mit jedem Startlevel (9 Monate)
- Python für Webentwicklungskurs (9 Monate)