Was ist menschliche Sprache? Dies sind Wörter, deren Kombinationen es Ihnen ermöglichen, diese oder jene Informationen auszudrücken. Es stellt sich die Frage, woher wir wissen, wann ein Wort endet und ein anderes beginnt. Die Frage ist ziemlich seltsam, werden viele denken, denn von Geburt an hören wir die Sprache der Menschen um uns herum, wir lernen zu sprechen, zu schreiben und zu lesen. Das angesammelte Gepäck an Sprachkenntnissen spielt natürlich eine wichtige Rolle, aber es gibt auch neuronale Netze im Gehirn, die den Sprachfluss in einzelne Wörter und / oder Silben unterteilen. Heute werden wir mit Ihnen eine Studie treffen, in der Wissenschaftler der Universität Genf (Schweiz) ein Neurocomputermodell zur Dekodierung von Sprache durch Vorhersage von Wörtern und Silben erstellt haben. Welche Gehirnprozesse wurden zur Grundlage des Modells, was ist mit dem großen Wort "Vorhersage" gemeint?und wie effektiv ist das erstellte Modell? Die Antworten auf diese Fragen erwarten uns im Bericht der Wissenschaftler. Gehen.
Grundlagen der Forschung
Für uns Menschen ist die menschliche Sprache (meistens) verständlich und artikuliert. Für ein Auto ist dies jedoch nur ein Strom akustischer Informationen, ein kontinuierliches Signal, das dekodiert werden muss, bevor es verstanden wird.
Das menschliche Gehirn verhält sich ähnlich, es geschieht für uns nur extrem schnell und unmerklich. Wissenschaftler glauben, dass die Grundlage dieses und vieler anderer Gehirnprozesse bestimmte neuronale Schwingungen sowie deren Kombinationen sind.
Insbesondere ist die Spracherkennung mit einer Kombination von Theta- und Gamma-Oszillationen verbunden, da sie die hierarchische Koordinierung der Codierung von Phonemen in Silben ohne vorherige Kenntnis ihrer Dauer und ihres zeitlichen Ursprungs ermöglicht, d. H. Upstream-Verarbeitung * in Echtzeit.
* (bottom-up) — , .Die natürliche Spracherkennung hängt auch stark von kontextbezogenen Signalen ab, mit denen Sie den Inhalt und die zeitliche Struktur des Sprachsignals vorhersagen können. Frühere Studien haben gezeigt, dass bei der Wahrnehmung kontinuierlicher Sprache der Vorhersagemechanismus eine wichtige Rolle spielt. Dieser Prozess ist mit Beta-Vibrationen verbunden.
Eine weitere wichtige Komponente der Spracherkennung kann als Predictive Coding bezeichnet werden, wenn das Gehirn ständig ein mentales Modell der Umgebung generiert und aktualisiert. Dieses Modell wird verwendet, um Vorhersagen für Berührungseingaben zu generieren, die mit der tatsächlichen Berührungseingabe verglichen werden. Der Vergleich des vorhergesagten und des tatsächlichen Signals führt zur Identifizierung von Fehlern, die zur Aktualisierung und Überarbeitung des mentalen Modells dienen.
Mit anderen Worten, das Gehirn lernt immer etwas Neues und aktualisiert ständig das Modell der umgebenden Welt. Dieser Prozess wird bei der Verarbeitung von Sprachsignalen als kritisch angesehen.
Die Forscher stellen fest, dass viele theoretische Studien sowohl Bottom-up- als auch Top-down * -Ansätze für die Sprachverarbeitung unterstützen.
Abwärtsverarbeitung * (von oben nach unten ) - Analyse von Systemkomponenten für die Einreichung des Composite Subsystems Way Reverse Engineering.Ein zuvor entwickeltes Neurocomputermodell, das die Verbindung realistischer exzitatorischer / inhibitorischer Theta- und Gamma-Netzwerke beinhaltet, konnte Sprache vorverarbeiten, so dass sie dann korrekt decodiert werden konnte.
Ein anderes Modell, das ausschließlich auf prädiktiver Codierung basiert, könnte einzelne Sprachelemente (wie Wörter oder vollständige Sätze, wenn sie als einzelnes Sprachelement betrachtet werden) genau erkennen.
Daher arbeiteten beide Modelle nur in unterschiedliche Richtungen. Einer konzentrierte sich auf den Aspekt der Echtzeit-Sprachanalyse und der andere auf die Erkennung isolierter Sprachsegmente (keine Analyse erforderlich).
Was aber, wenn wir die Grundprinzipien dieser radikal unterschiedlichen Modelle zu einem kombinieren? Laut den Autoren der Studie, die wir in Betracht ziehen, wird dies die Leistung verbessern und den biologischen Realismus von Sprachverarbeitungsmodellen für Neurocomputer erhöhen.
In ihrer Arbeit beschlossen die Wissenschaftler zu testen, ob ein auf Vorhersagevorhersagen basierendes Spracherkennungssystem von den Prozessen neuronaler Schwingungen profitieren kann.
Sie entwickelten das Neurocomputermodell Precoss (aus prädiktiver Codierung und Oszillationen für Sprache ), basierend auf der prädiktiven Codierungsstruktur, zu dem sie Theta- und Gamma-Oszillationsfunktionen hinzufügten, um die kontinuierliche Natur natürlicher Sprache zu bewältigen.
Der spezifische Zweck dieser Arbeit bestand darin, die Antwort auf die Frage zu finden, ob eine Kombination aus prädiktiver Codierung und neuronalen Schwingungen für die schnelle Identifizierung von Silbenkomponenten natürlicher Sätze von Vorteil sein kann. Insbesondere wurden die Mechanismen untersucht, durch die Theta-Oszillationen mit Informationsflüssen nach oben und unten interagieren können, und der Einfluss dieser Wechselwirkung auf die Effizienz des Silbendecodierungsprozesses wurde bewertet.
Architektur-Precoss-Modelle
Eine wichtige Funktion des Modells besteht darin, dass es in der Lage sein sollte, die in kontinuierlicher Sprache vorhandenen temporären Signale / Informationen zu verwenden, um Silbengrenzen zu bestimmen. Wissenschaftler haben vorgeschlagen, dass interne generative Modelle, einschließlich zeitlicher Vorhersagen, von solchen Signalen profitieren sollten. Um diese Hypothese sowie die sich wiederholenden Prozesse während der Spracherkennung zu berücksichtigen, wurde ein kontinuierliches Vorhersagecodierungsmodell verwendet.
Das entwickelte Modell unterscheidet klar zwischen „Was“ und „Wann“. "Was" - bezieht sich auf die Identität der Silbe und ihre spektrale Darstellung (keine temporäre, sondern eine geordnete Folge von Spektralvektoren); "Wann" bezieht sich auf die Vorhersage des Zeitpunkts und der Dauer von Silben.
Infolgedessen haben Vorhersagen zwei Formen: den Beginn einer Silbe, die vom Theta-Modul signalisiert wird; und Silbendauer, signalisiert durch exogene / endogene Theta-Oszillationen, die die Dauer der gammasynchronisierten Einheitssequenz definieren (Diagramm unten).
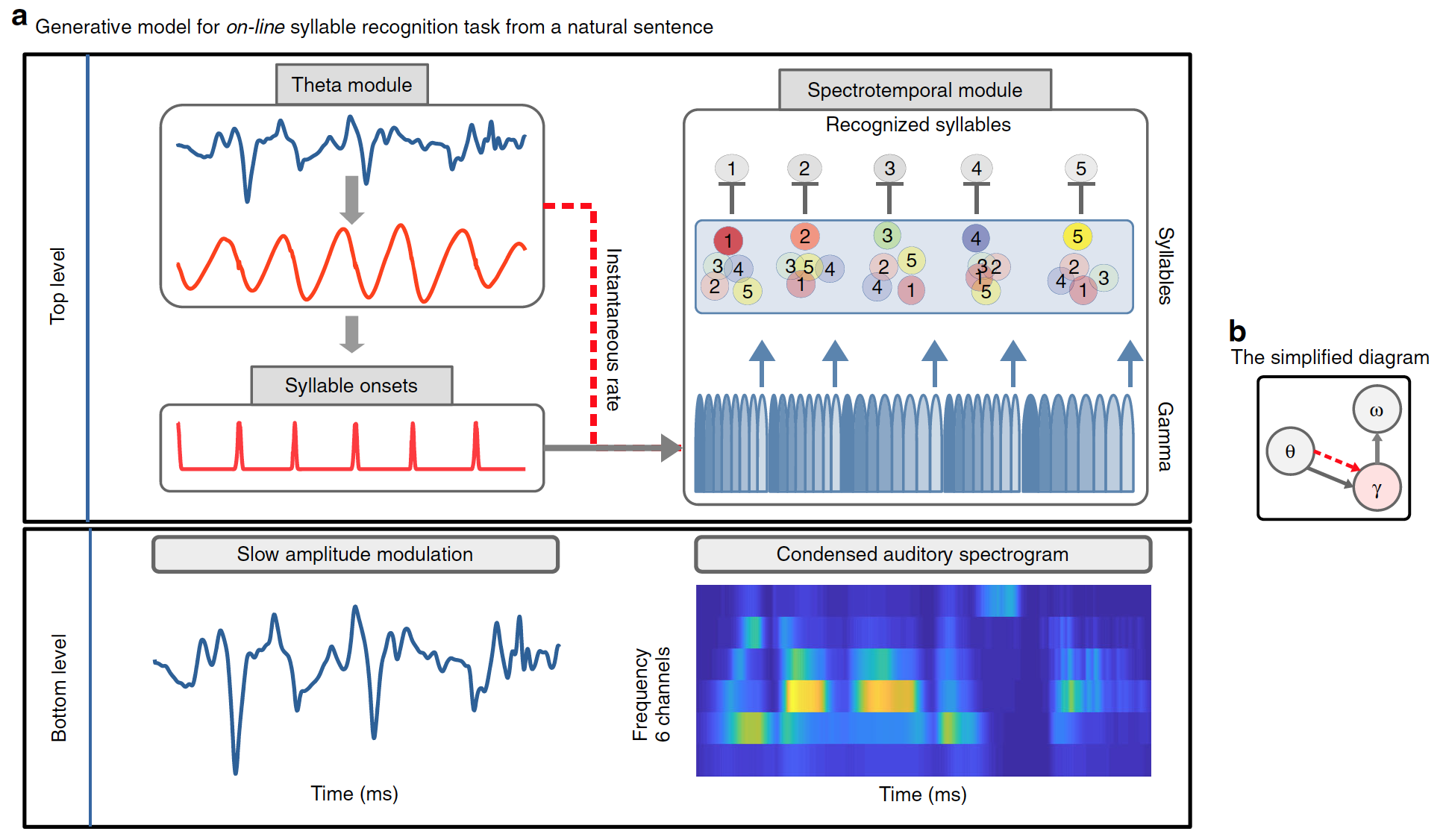
Bild Nr. 1
Precoss extrahiert das Sensorsignal aus internen Darstellungen seiner Quelle unter Bezugnahme auf das generierende Modell. In diesem Fall entspricht die sensorische Eingabe der langsamen Amplitudenmodulation des Sprachsignals und dem 6-Kanal-Hörspektrogramm des vollständigen natürlichen Satzes, das das Modell intern aus vier Komponenten generiert:
- Theta wackeln;
- Block der langsamen Amplitudenmodulation im Theta-Modul;
- Pool von Silbeneinheiten (so viele Silben wie im natürlichen Einleitungssatz vorhanden sind, d. h. von 4 bis 25);
- Bank von acht Gamma-Einheiten im spektrotemporalen Modul.
Zusammen erzeugen die Einheiten von Silben und Gammaschwingungen Abwärtsvorhersagen bezüglich des Eingangsspektrogramms. Jede der acht Gamma-Einheiten repräsentiert eine Phase in einer Silbe; Sie werden nacheinander aktiviert und die gesamte Aktivierungssequenz wird wiederholt. Daher ist jede Silbeneinheit einer Folge von acht Vektoren (einer pro Gammaeinheit) mit jeweils sechs Komponenten (einer pro Frequenzkanal) zugeordnet. Ein akustisches Spektrogramm einer einzelnen Silbe wird erzeugt, indem die entsprechende Einheit der Silbe während der gesamten Dauer der Silbe aktiviert wird.
Während der Silbenblock ein bestimmtes akustisches Muster codiert, verwenden Gammablöcke vorübergehend die entsprechende spektrale Vorhersage für die Dauer der Silbe. Informationen über die Dauer der Silbe werden durch die Theta-Schwingung gegeben, da ihre momentane Geschwindigkeit die Geschwindigkeit / Dauer der Gammasequenz beeinflusst.
Schließlich müssen die gesammelten Daten über die beabsichtigte Silbe gelöscht werden, bevor die nächste Silbe verarbeitet wird. Zu diesem Zweck setzt der letzte (achte) Gammablock, der den letzten Teil einer Silbe codiert, alle Silbeneinheiten auf eine insgesamt niedrige Aktivierungsstufe zurück, wodurch neue Beweise gesammelt werden können.
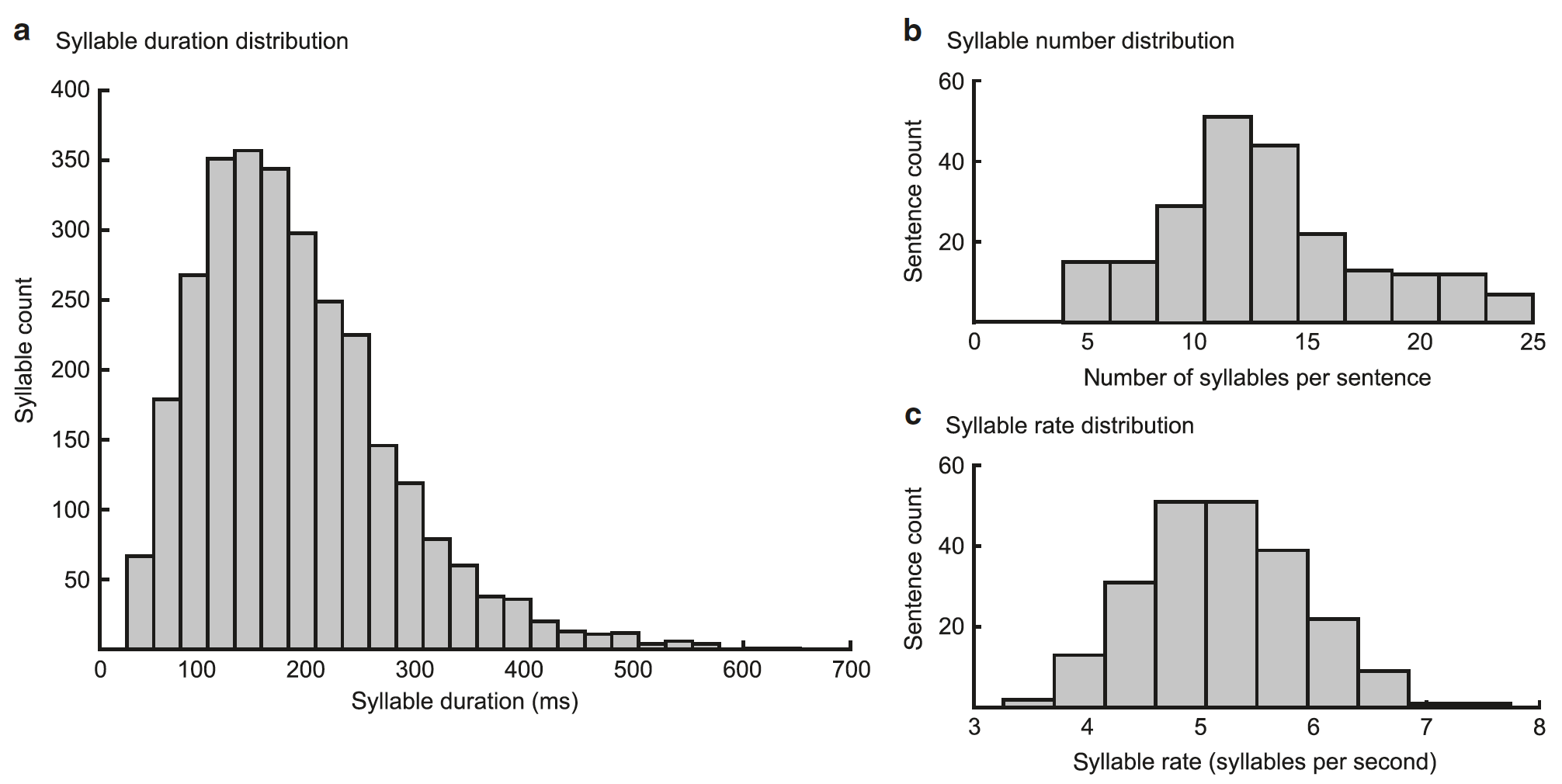
Bild Nr. 2
Die Leistung des Modells hängt davon ab, ob die Gammasequenz mit dem Beginn einer Silbe übereinstimmt und ob ihre Dauer der Dauer einer Silbe entspricht (50–600 ms, Durchschnitt = 182 ms).
Die Bewertung des Modells in Bezug auf die Silbenfolge erfolgt durch Silbeneinheiten, die zusammen mit Gammaeinheiten die erwarteten spektral-zeitlichen Muster (das Ergebnis des Modells) erzeugen, die mit dem einleitenden Spektrogramm verglichen werden. Das Modell aktualisiert seine Schätzungen zur aktuellen Silbe, um den Unterschied zwischen dem generierten und dem tatsächlichen Spektrogramm zu minimieren. Das Aktivitätsniveau steigt in den Silbeneinheiten an, deren Spektrogramm sensorischen Eingaben entspricht, und nimmt in anderen ab. Im Idealfall führt die Minimierung von Echtzeit-Prognosefehlern zu einer erhöhten Aktivität in einer separaten Silbeneinheit, die der Eingabesilbe entspricht.
Simulationsergebnisse
Das oben vorgestellte Modell enthält physiologisch motivierte Theta-Oszillationen, die durch langsame Amplitudenmodulationen des Sprachsignals gesteuert werden und Informationen über den Beginn und die Dauer einer Silbe an die Gammakomponente übertragen.
Diese Theta-Gamma-Beziehung liefert eine zeitliche Ausrichtung der intern erzeugten Vorhersagen mit den aus den Eingabedaten gefundenen Silbengrenzen (Option A in Bild 3).
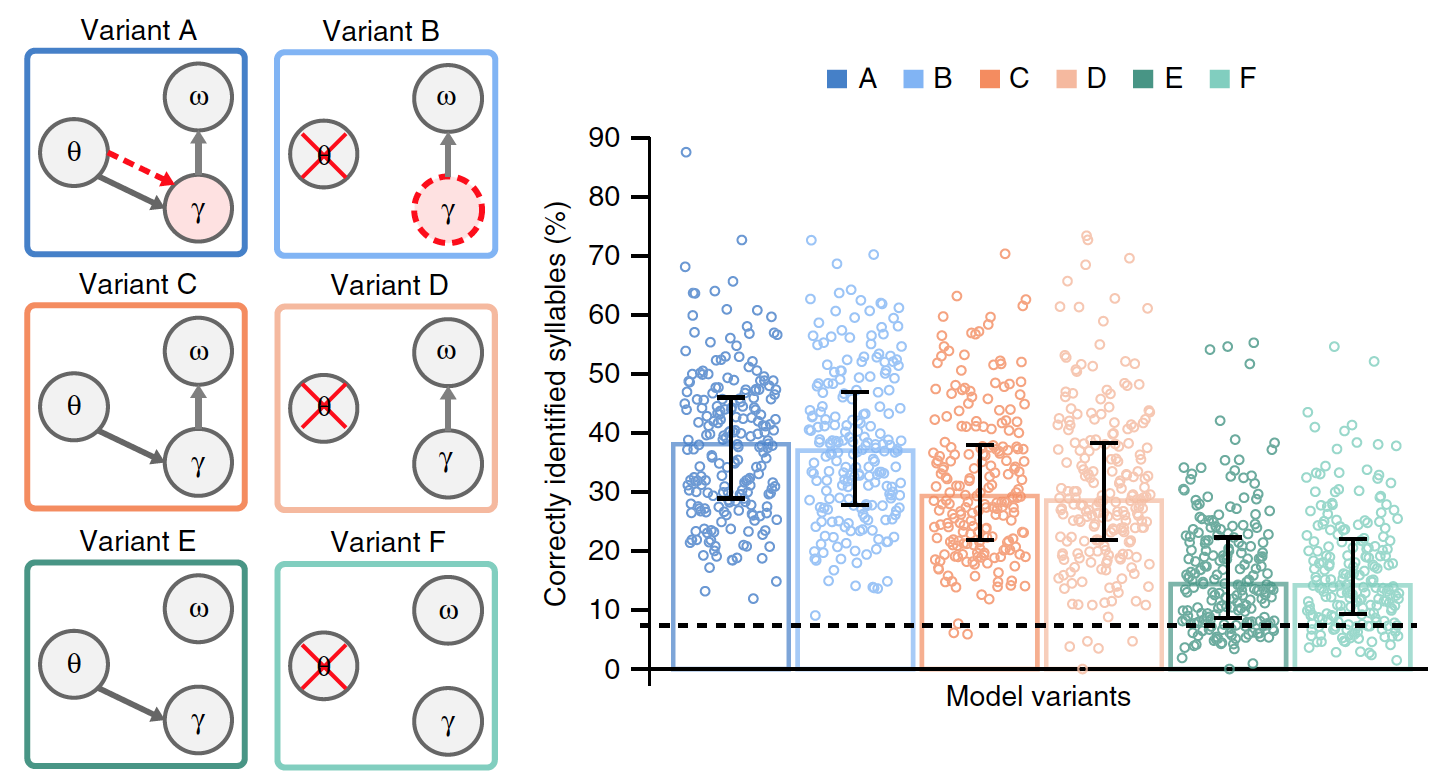
Bild Nr. 3
Um die Relevanz der Silbensynchronisation basierend auf langsamer Amplitudenmodulation zu beurteilen, wurde ein Vergleich von Modell A mit Option B durchgeführt, bei dem die Theta-Aktivität nicht durch Vibrationen modelliert wird, sondern sich aus der Selbstwiederholung der Gammasequenz ergibt.
In Modell B wird die Dauer der Gammasequenz nicht mehr exogen (aufgrund externer Faktoren) durch Theta-Oszillationen gesteuert, und endogen (aufgrund interner Faktoren) wird die bevorzugte Gammageschwindigkeit verwendet, die bei Wiederholung der Sequenz zur Bildung eines internen Theta-Rhythmus führt. Wie im Fall von Theta-Oszillationen hat die Dauer der Gammasequenz eine bevorzugte Rate im Theta-Bereich, die sich möglicherweise an unterschiedliche Silbenlängen anpassen kann. In diesem Fall ist es möglich, den Theta-Rhythmus zu testen, der sich aus der Wiederholung der Gammasequenz ergibt.
Um die spezifischen Auswirkungen des Theta-Gammas beim Zusammensetzen und Dumping akkumulierter Daten in Silbeneinheiten genauer zu bewerten, wurden zusätzliche Versionen der vorherigen Modelle A und B hergestellt.
Die Optionen C und D wurden durch das Fehlen einer bevorzugten Gammastrahlungsrate unterschieden. Die Varianten E und F unterschieden sich zusätzlich von den Varianten C und D durch das Fehlen eines Zurücksetzens der akkumulierten Silbendaten.
Von allen Varianten des Modells hat nur A eine echte Theta-Gamma-Verbindung, wobei die Gamma-Aktivität vom Theta-Modul bestimmt wird, während im Modell die Gamma-Geschwindigkeit endogen festgelegt wird.
Es musste ermittelt werden, welche Version des Modells am effektivsten ist, für die die Ergebnisse ihrer Arbeit bei Vorhandensein gemeinsamer Eingabedaten (natürliche Sätze) verglichen wurden. Die Grafik im obigen Bild zeigt die durchschnittliche Leistung jedes Modells.
Es gab signifikante Unterschiede zwischen den Optionen. Im Vergleich zu den Modellen A und B war die Leistung bei den Modellen E und F (durchschnittlich 23%) sowie bei C und D (15%) signifikant geringer. Dies zeigt an, dass das Löschen der akkumulierten Daten über die vorherige Silbe vor der Verarbeitung der neuen Silbe ein kritischer Faktor bei der Codierung des Silbenstroms in natürlicher Sprache ist.
Der Vergleich der Optionen A und B mit den Optionen C und D zeigte, dass die Theta-Gamma-Assoziation, sei es Stimulus (A) oder endogen (B), die Modellleistung signifikant verbessert (im Durchschnitt um 8,6%).
Im Allgemeinen zeigten Experimente mit verschiedenen Versionen der Modelle, dass es am besten funktionierte, wenn die Silbeneinheiten nach jeder Sequenz von Gammaeinheiten (basierend auf internen Informationen über die spektrale Struktur der Silbe) zurückgesetzt wurden und wenn die Rate der Gammastrahlung durch Theta-Gamma-Kopplung bestimmt wurde.
Die Leistung des Modells mit natürlichen Sätzen hängt daher weder von der genauen Signalisierung des Silbenbeginns durch vom Stimulus gesteuerte Theta-Oszillationen noch vom genauen Mechanismus der Theta-Gamma-Kommunikation ab.
Wie die Wissenschaftler selbst zugeben, ist dies eine ziemlich überraschende Entdeckung. Andererseits spiegelt das Fehlen von Leistungsunterschieden zwischen stimulusgesteuerter und endogener Theta-Gamma-Beziehung wider, dass die Dauer der Silben in natürlicher Sprache sehr nahe an den Erwartungen des Modells liegt. In diesem Fall gibt es keinen Vorteil für das Theta-Signal, das direkt von der Eingabe gesteuert wird.
Um eine solche unerwartete Wendung besser zu verstehen, führten die Wissenschaftler eine weitere Reihe von Experimenten durch, jedoch mit komprimierten Sprachsignalen (x2 und x3). Wie Verhaltensstudien zeigen, ändert sich das Verständnis von sprachkomprimiertem x2 praktisch nicht, aber es sinkt dramatisch, wenn es dreimal komprimiert wird.
In diesem Fall kann die stimulierte Theta-Gamma-Verbindung zum Parsen und Decodieren von Silben äußerst nützlich sein. Die Simulationsergebnisse sind unten dargestellt.

Bild Nr. 4
Wie erwartet sank die Gesamtleistung mit zunehmendem Kompressionsverhältnis. Für die x2-Kompression gab es immer noch keinen signifikanten Unterschied zwischen dem Stimulus und der endogenen Theta-Gamma-Beziehung. Bei der x3-Komprimierung gibt es jedoch einen signifikanten Unterschied. Dies legt nahe, dass das stimulusgetriebene Theta-Wackeln, das die Theta-Gamma-Verbindung antreibt, für den Silbencodierungsprozess vorteilhafter war als die endogen eingestellte Theta-Geschwindigkeit.
Daraus folgt, dass natürliche Sprache unter Verwendung eines relativ festen endogenen Theta-Generators verarbeitet werden kann. Für komplexere eingegebene Sprachsignale (d. H. Wenn sich die Sprachrate ständig ändert) ist jedoch ein gesteuerter Theta-Generator erforderlich, der dem Gamma-Codierer genaue zeitliche Informationen über Silben (Silbenstart und Silbendauer) liefert.
Die Fähigkeit des Modells, Silben im Eingabesatz genau zu erkennen, berücksichtigt nicht die variable Komplexität der verschiedenen verglichenen Modelle. Daher wurde für jedes Modell ein Bayesian Information Criterion (BIC) bewertet. Dieses Kriterium quantifiziert den Kompromiss zwischen Genauigkeit und Komplexität des Modells (Bild 5).
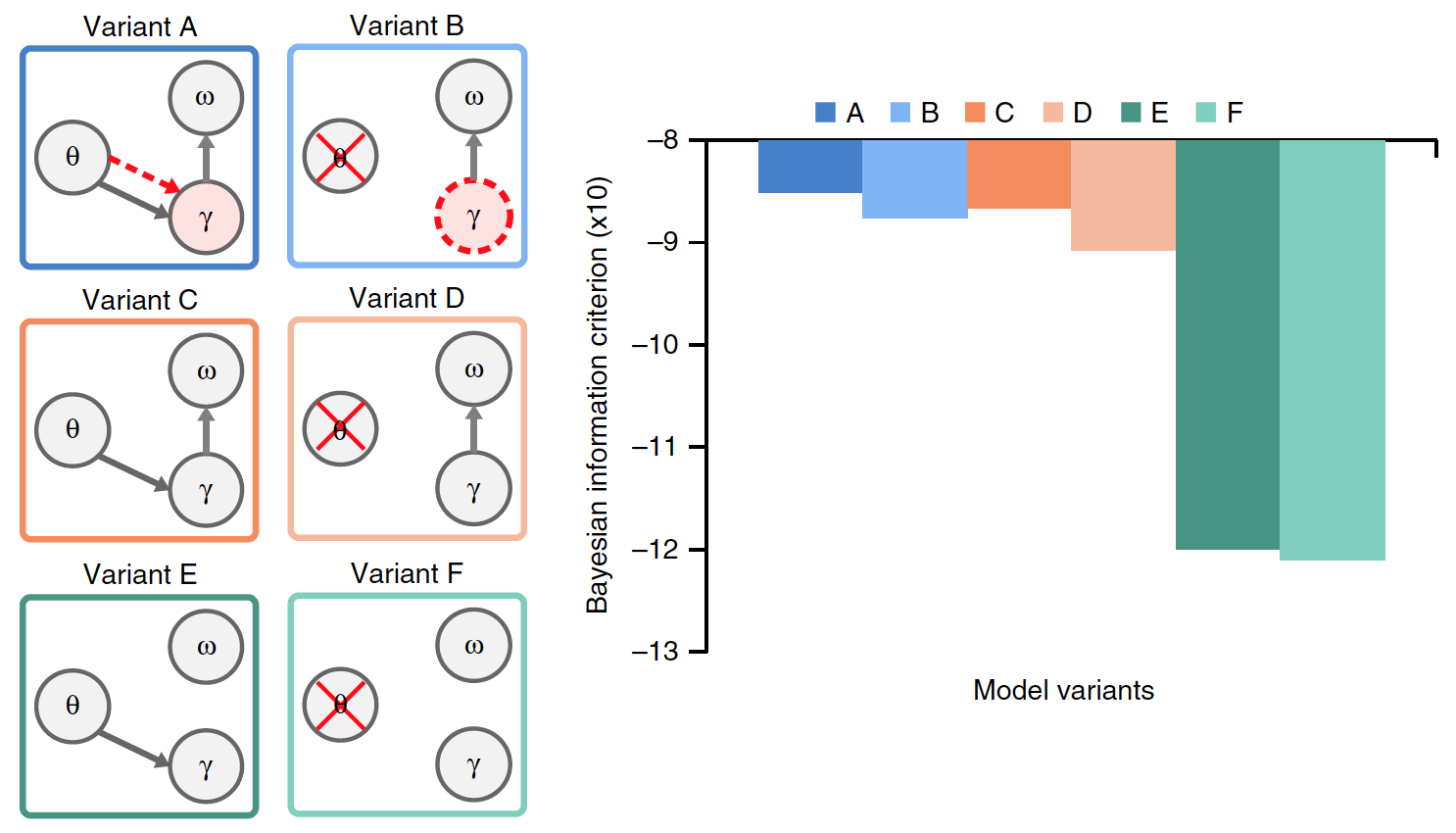
Bild Nr. 5
Option A zeigte die höchsten BIC-Werte. Frühere Vergleiche zwischen Modell A und Modell B konnten ihre Leistung nicht genau unterscheiden. Dank des BIC-Kriteriums wurde jedoch klar, dass Option A eine sicherere Silbenerkennung bietet als ein Modell ohne Theta-Oszillationen, die vom Stimulus gesteuert werden (Modell B).
Für eine detailliertere Kenntnis der Nuancen der Studie empfehle ich, den Bericht von Wissenschaftlern und Wissenschaftlern zu lesenzusätzliche Materialien dazu.
Epilog
Zusammenfassend können wir sagen, dass der Erfolg des Modells von zwei Hauptfaktoren abhängt. Das erste und wichtigste ist das Zurücksetzen der akkumulierten Daten basierend auf den Informationen des Modells über den Inhalt der Silbe (in diesem Fall ist es ihre spektrale Struktur). Der zweite Faktor ist die Beziehung zwischen Theta- und Gamma-Prozessen, die sicherstellt, dass die Gamma-Aktivität im Theta-Zyklus enthalten ist, entsprechend der erwarteten Dauer einer Silbe.
Im Wesentlichen ahmte das entwickelte Modell die Arbeit des menschlichen Gehirns nach. Der in das System eintretende Schall wurde durch eine Theta-Welle moduliert, die der Aktivität von Neuronen ähnelte. Auf diese Weise können Sie die Grenzen von Silben definieren. Darüber hinaus helfen schnellere Gammawellen, die Silbe zu codieren. Dabei schlägt das System mögliche Varianten von Silben vor und korrigiert gegebenenfalls die Auswahl. Das System springt zwischen der ersten und der zweiten Ebene (Theta und Gamma), erkennt die richtige Version der Silbe und wird dann auf Null zurückgesetzt, um den Prozess für die nächste Silbe erneut zu starten.
In praktischen Tests konnten 2888 Silben erfolgreich entschlüsselt werden (220 Sätze natürlicher Sprache, Englisch wurde verwendet).
Diese Studie kombinierte nicht nur zwei gegensätzliche Theorien und setzte sie als ein einziges System in die Praxis um, sondern ermöglichte es auch, besser zu verstehen, wie unser Gehirn Sprachsignale wahrnimmt. Es scheint uns, dass wir Sprache "so wie sie ist" wahrnehmen, d.h. ohne komplizierte unterstützende Prozesse. Angesichts der Simulationsergebnisse stellt sich jedoch heraus, dass neuronale Theta- und Gamma-Oszillationen es unserem Gehirn ermöglichen, kleine Vorhersagen darüber zu treffen, welche Silbe wir hören, auf deren Grundlage die Sprachwahrnehmung gebildet wird.
Wer etwas sagt, aber das menschliche Gehirn scheint manchmal viel mysteriöser und unverständlicher als die unerforschten Ecken des Universums oder die hoffnungslosen Tiefen der Ozeane.
Vielen Dank für Ihre Aufmerksamkeit, bleiben Sie neugierig und haben Sie eine gute Arbeitswoche, Jungs. :) :)
Ein bisschen Werbung
Vielen Dank für Ihren Aufenthalt bei uns. Gefällt dir unser Artikel? Möchten Sie weitere interessante Inhalte sehen? Unterstützen Sie uns, indem Sie eine Bestellung aufgeben oder Freunden Cloud-VPS für Entwickler ab 4,99 US-Dollar empfehlen , ein einzigartiges Analogon von Einstiegsservern, das wir für Sie erfunden haben: Die ganze Wahrheit über VPS (KVM) E5-2697 v3 (6 Kerne) 10 GB DDR4 480 GB SSD 1 Gbit / s ab 19 $ oder wie teilt man den Server? (Optionen sind mit RAID1 und RAID10, bis zu 24 Kernen und bis zu 40 GB DDR4 verfügbar).
Dell R730xd ist im Equinix Tier IV-Rechenzentrum in Amsterdam 2x billiger? Nur wir haben 2 x Intel TetraDeca-Core Xeon 2x E5-2697v3 2,6 GHz 14C 64 GB DDR4 4 x 960 GB SSD 1 Gbit / s 100 TV von 199 US-Dollar in den Niederlanden!Dell R420 - 2x E5-2430 2,2 GHz 6C 128 GB DDR3 2x960 GB SSD 1 Gbit / s 100 TB - ab 99 US-Dollar! Lesen Sie mehr über den Aufbau eines Infrastrukturgebäudes. Klasse mit Dell R730xd E5-2650 v4 Servern für 9.000 Euro pro Penny?