
In der Tat ist dies die Geschichte der Suche nach einem Fehler im Layout einer Bankenseite, die zu einer ungenauen Anzeige ihrer Hauptseite bei der Suche führte. Ein ähnliches Problem tritt häufig auf einer Site auf, die beispielsweise in einem Online-Konstruktor zusammengestellt oder beispielsweise von einem Layout-Designer entworfen wurde, der mit den Grundlagen der Suchmaschinenoptimierung nicht vertraut ist.
Und diese Geschichte wäre nur für einen engen Kreis praktizierender SEOs interessant geblieben, hätte sie nicht ein undokumentiertes Merkmal der Indizierung berührt, das sicherlich etwas über andere Site-Wartungsspezialisten wissen möchte. Ich lade sie unter die Katze ein.
Kurzes Intro
Jeder erfahrene SEO-Master kennt die Regeln für das semantische Parsen einer Website-Seite durch Suchmaschinen-Crawler. Diese Regeln basieren auf individuellen Bestimmungen einiger technischer Standards im Internet. Beispielsweise:
- Das <title> -Tag ist ein eindeutiger Name für das gesamte Dokument und wird nur in seinem Überschriftenabschnitt und nur einmal verwendet.
- Das <h1> -Tag überschreibt einen bestimmten Abschnitt des Dokuments und kann wiederverwendet werden, jedoch nur in einem anderen Abschnitt und unter Wahrung der Eindeutigkeit aller <h1> -Tags desselben Dokuments.
- Das <h2> -Tag ist eine Unterüberschrift eines Abschnitts, die auch im selben Abschnitt wiederverwendet werden kann, wobei die Eindeutigkeit unter den Peer-Unterüberschriften des Abschnitts erhalten bleibt.
- Das <h3> -Tag ist die Unterüberschrift der übergeordneten Unterüberschrift.
- … usw.
Natürlich gibt es in diesen Regeln verschiedene Nuancen für das Parsen von Seiten vor dem Indizieren, die von jedem Suchserver auf seine Weise interpretiert werden:
- , «», — , <p> ;
- (outlines), «» — , <h2> <p> () ;
- … .
Diese Regeln der semantischen Analyse und Nuancen sind für uns noch nicht wichtig. Und wenn Sie an den Bestimmungen der technischen Standards, auf denen die Inhaltsindizierung basiert, so interessiert sind, wird der Hauptteil dieser Bestimmungen in der Übersichtsveröffentlichung [1] über die Zulässigkeit mehrerer <h1> -Tags auf einer Seite einer Website ganz klar angegeben .
Ich möchte nur darauf hinweisen, dass SEO-Meister an solche Nuancen gewöhnt sind. Dies ist nicht das erste Mal, dass sie ihre Gültigkeit anhand ihrer eigenen Erfahrung überprüft haben und seit langem Websites bei der Suche unter Berücksichtigung dieser Ansicht über die Priorität von Tags bewerben. Wenn Sie die Prinzipien der Indizierung verstehen, können Sie den Text, der das Such-Snippet der Site als Antwort auf die Anfrage eines Benutzers anzeigt, teilweise "steuern".
Vor einigen Tagen tauchten jedoch Insiderinformationen auf, dass in den organischen Suchergebnissen zur offiziellen Website der ukrainischen Monobank ein unverständliches Snippet-Verhalten aufgedeckt wurde: Die Suchmaschine benennt es überhaupt nicht mit dem Tag <title> oder <h1>. Das heißt, der Texter könnte die eindeutigste Überschrift und den einzigartigsten Text schreiben, der Inhaltsmanager könnte den Text auf der Website einfügen, aber die Suche wäre immer noch nicht richtig.
Es war notwendig, den Grund herauszufinden, über den ich weiter sprechen werde.
Der erste Schritt der Forschung
Für den Anfang habe ich den Cache und den Browserverlauf gelöscht, neu gestartet, die Google- Suchleiste geöffnet und den Namen der Bank eingegeben. Damit selbst eine unerfahrene SEO-Person jeden meiner Schritte verstehen konnte, machte ich ein Foto des ersten Schritts.
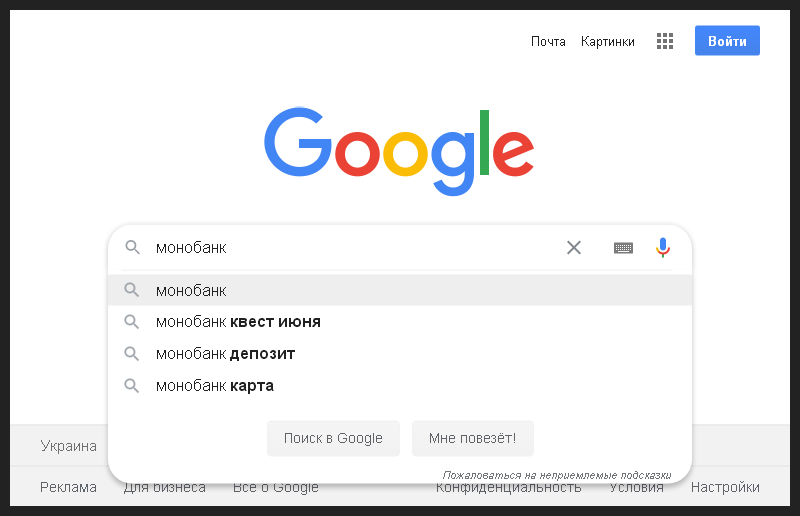
Dies ist eine Markeninformationsanfrage, was bedeutet, dass es an erster Stelle der organischen Ergebnisse logisch ist, das Erscheinen eines Snippets für die Hauptseite der Bank zu erwarten.
Alles passierte wie erwartet, das Snippet war das erste in der Suche und enthielt auch einen Block mit schnellen Links zu den Hauptabschnitten der Site. Ich habe diesen Moment auf dem nächsten Foto festgehalten.
Bisher hat alles normal ausgesehen.

Um sicherzustellen, dass eine dunkle Situation nur in den Google-Ergebnissen auftritt, wiederholte ich dieselbe Abfrage in der Yandex- Suche und stellte erfreulicherweise fest, dass dieser Suchriese die üblichen Regeln einhält: Das Snippet trug den Titel Monobank - eine mobile Bank - genau so, wie es im <title> -Tag des gewünschten Tags angegeben ist Seiten.

Die Antwort im Google-Suchschnappschuss war zumindest im Titelteil grundlegend anders. Außerdem war ich etwas verwirrt von den lächerlichen Texten unter den Überschriften des Google-Snippets.
Ich nahm an, dass dies nur eine Folge der Tatsache , dass nach SMM Förderung die Marke und seine mobile Anwendung, die von Promodo in 2017-2018 umgesetzt wurde [2] für die ehemalige monobank.com.ua Domain , mehr SEO-Meister mieten die neuen Service Monobank Domain .ua machte keinen Sinn mehr. Immerhin hat die Werbekampagne die erwarteten Ergebnisse getragen. Und das Management der Bank hat höchstwahrscheinlich ein Ziel bei der Suchmaschinenwerbung für die neue Domain erzielt oder die Verantwortung Vollzeit-IT-Spezialisten übertragen.
Daher führte ich die Unbeholfenheit der aktuellen Texte auf die verständliche mangelnde Bereitschaft der Mitarbeiter zurück, das Ergebnis der Abfrage zu überprüfen, die ein typischer Bankbenutzer niemals eingeben wird.
Schließlich besucht die Kundschaft der Bank die Website größtenteils über eine mobile Anwendung, fast ohne zu beobachten, wie die Seiten der Bank bei der Suche aussehen. Und der Teil der Kunden, die die Internetsuche durchlaufen, verwendet hauptsächlich Abfragen des Formulars:
- Monobank-Dollarkurs;
- Wechselkurs der Monobank;
- ein Monobank-Konto eröffnen;
- eine Monobankkarte machen;
- Erstellen Sie eine Monobank-Karte.
- Monobank-Kreditkarte;
- einen Monobank-Kredit erhalten;
- einen Monobankkredit aufnehmen;
- … usw.
Jede Bank kennt eine vollständige Liste solcher Suchphrasen, die den Mustern "Was ist zu finden + wo" oder "Wo + was" entsprechen und den höchsten eingehenden Datenverkehr aus der organischen Suche erzielen.
Überprüfen von "leckeren" Fragen
Wie überrascht ich war, als für die meisten dieser Abfragen dasselbe Snippet in den Suchergebnissen mit demselben Titel und oft dummem Text angezeigt wurde, der kaum mit der eingegebenen Abfrage übereinstimmte.
Ich habe ein Beispiel für eine solche Anfrage im folgenden Bild fotografiert und den Problempunkt identifiziert.

Darüber hinaus führte die Zieladresse (URL) des Snippets für fast alle Anfragen zum oberen Rand der Hauptseite, ohne den für die aktuelle Anfrage relevanten Abschnitt in der Adresse zu verankern.
Angenommen, die Anfrage betraf den Wechselkurs und der entsprechende Abschnitt wäre auf der Zielzielseite vorhanden. Es wäre logisch, den Link zu dem Abschnitt mit einem Hash wie monobank.ua/#kurs-valut mit der Kanonisierung derselben verankerten URL zu verankern, damit der Suchroboter dies versteht dass die Zielseite mehrere Zielpunkte für die entsprechenden Suchphrasen enthält, die von Vollzeit-SEOs im Ankertext von Links, die von ihnen irgendwo auf der Website oder außerhalb der Website platziert wurden, beispielsweise in sozialen Netzwerken, angegeben werden.
Ansonsten sah es so aus, als hätten die Website-Entwickler der Hauptseite die Rolle einer multisektionalen Zielseite zugewiesen, aber sie haben es den SEO-Dienstleistern nicht mitgeteilt und Werbelinks mit dem geplanten Ankertext, jedoch ohne die Abschnittsanker, eingefügt. Infolgedessen schienen alle Links für verschiedene Arten von Anfragen in den anfänglichen Einstiegspunkt der Hauptseite zu fallen und erhielten unweigerlich einen einzelnen Ausschnitt mit einem Titel, der sich auf den Hauptabschnitt der Hauptseite bezog.
Kleiner Exkurs
Für alle Fälle zeige ich im nächsten Bild ein Beispiel für ein HTML-Markup, wie das semantische Layout verwendet wird, um die Probleme mehrerer Landepunkte auf einer einzelnen Zielseite der Site zu lösen.

Dieses Schema funktioniert natürlich, sofern wir die Zielseite mit einem Anker verknüpfen, der dem Informationsfall entspricht. Also:
- monobank.ua - Basisinformationen;
- monobank.ua/#kurs-valut - über Wechselkurse;
- monobank.ua/#otkryt-schet - über die Eröffnung eines Kontos;
- monobank.ua/#kreditnaja-karta - über Kreditkarten.
Aber zurück zum erkannten SEO-Pfosten
Der Fehler ist zwar nicht so schwerwiegend, da der Hauptstrom der Kunden immer noch über die mobile Anwendung fließt. Aufgrund dieses Fehlers verliert die Bank jedoch einen Teil ihres Suchverkehrs. Weil Suchbenutzer in zwei Typen unterteilt sind - die rauschende Mehrheit und die gemächliche Minderheit:
- Ersteres liest nur die Überschriften der Snippets und klickt sie an, wenn die Bedeutung der Überschrift und der eingegebenen Abfrage übereinstimmt.
- Letztere lesen den Titel und den Text darunter sorgfältig durch und klicken auch nur, wenn die Bedeutung übereinstimmt.
Die Nachricht im verknöcherten Suchausschnitt für die Bankseite stimmte eindeutig nur mit einem sehr kleinen Prozentsatz der Anfragen überein. Es war notwendig zu verstehen, wo der Fehler gemacht wurde.
Zeigen Sie das Markup der Masterseite an
Ich habe die Hauptseite der Bank über den Link aus dem Snippet geöffnet. Im Quellcode dieser Seite gab es ein einzelnes <h1> -Tag, das normalerweise zum Schreiben des Haupttitels der Seite verwendet wurde und normalerweise auch im Titel des Snippets endet.
Darüber hinaus wurde dieses Haupt-Header-Tag im Seitencode früher als die übrigen Header-Tags <h> verwendet. Auf den ersten Blick sah es also so aus, als hätte es keine SEO-Fehler.
Ich habe ein Foto von dieser Seite gemacht und die Position der ersten beiden Überschriften-Tags darauf markiert.
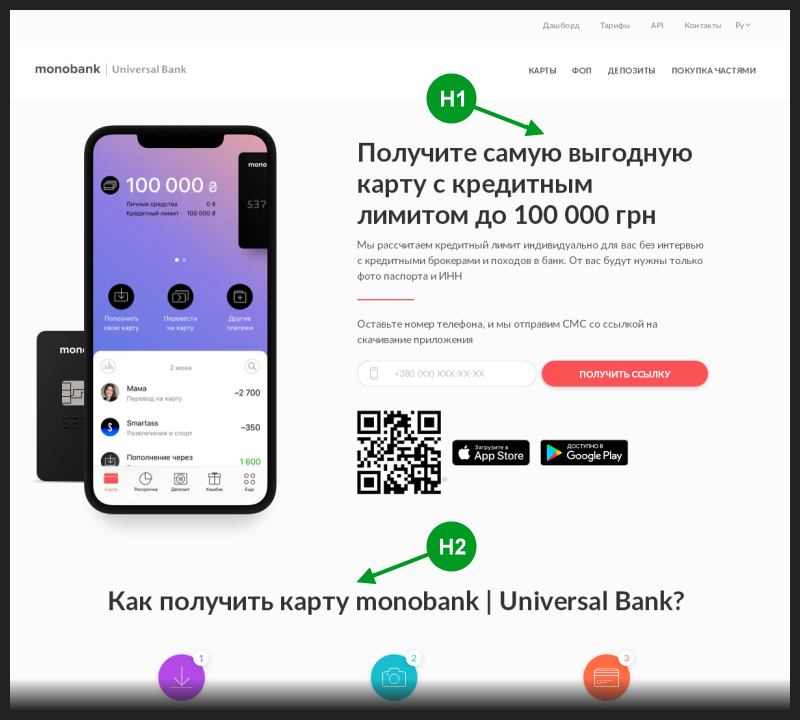
Es war logisch zu erwarten, dass das <h1> -Tag den Titel des Suchausschnitts ersetzt. Aber aus irgendeinem Grund kam jedes Mal ein Tag mit einem niedrigeren Rang dort an.
Zunächst ging ich davon aus, dass es sich bei dem Fall nur um Anfragen handelte, die den Namen der Bank enthielten. Das <h1> -Tag hat es nicht, das <h2> -Tag jedoch - so dass das Tag trotz seines niedrigeren Ranges immer noch den Vorteil hat, den Snippet-Titel zu übernehmen.
Diese Annahme ist jedoch leicht zu testen: Sie müssen eine Anforderung schreiben, die genau dem <h1> -Tag entspricht, und dann hat dieses Header-Tag garantiert das Recht, den Snippet-Header basierend auf einer absoluten Übereinstimmung mit der Anforderung zu belegen. Was ich getan habe, während ich das Ergebnis in der nächsten Aufnahme korrigiert habe.

Aus dem Schnappschuss folgt, dass der Suchserver den Text des <h1> -Tags immer noch sieht und versteht, ihn jedoch aus irgendeinem Grund nicht als Hauptüberschrift auf der Website dieser Bank betrachtet. Dies ist in 2 Fällen möglich:
- Entweder hat der SEO-Master dem Seitenlayout ein bestimmtes semantisches Mikro-Markup hinzugefügt, das ein anderes Tag anweist, die Hauptüberschrift zu werden.
- oder es gibt das sogenannte „Problem der Online-Designer“, wenn aufgrund der Suboptimalität der Suche nach Bausteinen ihre Text-Tags in verschiedenen Abschnitten des HTML-Dokuments angezeigt werden, während das Haupttitel-Tag tiefer als das Nicht-Haupttitel-Tag aus dem Umriss seines Abschnitts entfernt wird.
Ich entschied mich, zuerst den ersten Fall zu überprüfen und öffnete die Site im Tool zur Validierung strukturierter Daten. Es wurde jedoch nur das Open Graph-Mikro-Markup gefunden, keine Hinweise auf eine erzwungene Neuzuweisung der Tag-Semantik.
Ich habe diesen Moment auf dem nächsten Bild festgehalten.

Dann öffnete ich den Quellcode der Problemseite, formatierte die Leerzeichen für ein einfaches Studium, entfernte die Tag-Attribute für denselben Zweck und bemerkte im nächsten Bild das Wesentliche des Problems.

Infolgedessen haben wir den unten interpretierten Sachverhalt, aus dem ich im Voraus eine wichtige Schlussfolgerung aufschreiben werde : Überprüfen Sie nach einem Monat (dies ist ungefähr die durchschnittliche Zeit für Crawls durch Indizieren von Robotern) nach dem Start der Website, um einige wichtige Fragen zu überprüfen, wie die Suchmaschine das Layout Ihrer Seiten übernommen hat, d. H. Welche Teile Inhalt, den er tatsächlich indizierte.
Interpretation des Ergebnisses
Yandex fand beim Parsen der Seite in der neuen Monobank-Domäne kein semantisches Layout (da alles mit <div> s angelegt ist) und begann, ohne Anweisungen zur Analyse der impliziten Semantik, von den Tag-Klassen zu raten, und verwendete bei der Auswahl des Snippet-Titels einfach die Regel aus der Spezifikation: tag <title> ist der Haupttitel des Dokuments.
Google, wenn die gleiche Seite Parsen, hat auch keine semantisches Layout finden, aber seine künstliche Intelligenz in der Lage , verborgene semantische Merkmale zu analysieren, so dass es vier bemerkt <div> s mit einem impliziten semantischen Klasse InhaltBezeichnet den Abschnittsumriss in der aktuellen Markierungssituation. Daher wurde die Regel für das <title> -Tag abgelehnt, und die Suchmaschine verwendete die Regel aus der Spezifikation für die Abschnittskonturen, um einen geeigneten Abschnitt aus den vier deklarierten Abschnitten zu finden. Der erste Abschnitt ist nicht geeignet, da sein Titel-Tag weiter von der Kontur entfernt ist als das Titel-Tag in den Abschnitten 2, 3 und 4. Von diesen besser geeigneten Abschnitten wurde der zweite Abschnitt aufgrund seiner Nähe zum Anfang des Dokuments ausgewählt. So kam der Titel in das Snippet.
Tatsächlich war die Logik zur Auswahl eines Titels für ein Snippet für beide Suchmaschinen identisch. Yandex wählte einfach das erste Überschriften-Tag aus dem ersten Pfad (das <head> -Tag ist implizit) im Dokument aus, und Google wählte das erste Überschriften-Tag aus dem semantisch markierten Pfad aus (das <div class = "content"> -Tag war es offensichtlich).
Dies ist das erstaunliche Merkmal der Suche, das zu Beginn meiner Untersuchung als "undokumentiert" bezeichnet wurde. Das <h1> -Tag hat eigentlich keine wesentliche Bedeutung. Basierend auf der Suchabfrage des Benutzers werden eine übereinstimmende Abschnittskontur im Dokument und die erste Überschrift in der Gliederung ausgewählt, ohne die verwendete numerische Überschriftenebene zu berücksichtigen.
Gebrauchte Materialien
[1] Ein H1 oder mehrere - warum ist das richtig? , März 2020. Impera, SEO-Dokumente. Auszüge aus der HTML-Standardspezifikation zeigen, dass das Schreiben eines oder mehrerer H1-Tags auf einer Seite in beiden Fällen als korrekt angesehen wird.
[2] Monobank-Fall zur Förderung mobiler Anwendungen , August 2017 - März 2018. Promodo, Fälle. Am Beispiel der von der Agentur verwendeten Ereignisse wird beschrieben, wie die mobile Anwendung auf iOS und Android mit AdWords, Facebook, Instagram, Twitter, YouTube beworben und auch im App Store und bei Google Play optimiert wurde.