
Mathematik wird oft als "Sprache der Wissenschaft" bezeichnet. Es eignet sich gut für die quantitative Verarbeitung nahezu aller wissenschaftlichen Informationen, unabhängig von deren Inhalt. Und mit Hilfe des mathematischen Formalismus können sich Wissenschaftler aus verschiedenen Bereichen bis zu einem gewissen Grad "verstehen". Eine ähnliche Situation zeichnet sich heute in der Informatik ab. Aber wenn Mathematik die Sprache der Wissenschaft ist, dann ist CS das Schweizer Messer. In der Tat ist eine moderne Forschung kaum vorstellbar, ohne große Datenmengen, komplexe Berechnungen, Computermodellierung, Visualisierung und den Einsatz spezieller Software und Algorithmen zu analysieren und zu verarbeiten. Schauen wir uns einige interessante "Geschichten" an, in denen verschiedene Disziplinen CS-Methoden verwenden, um ihre Probleme zu lösen.
Bioinformatik: Von Petrischalen zur Biologie In silico
Die Bioinformatik kann als eines der auffälligsten Beispiele für die Überschneidung von CS und anderen Disziplinen bezeichnet werden. Diese Wissenschaft befasst sich mit der Analyse molekularbiologischer Daten unter Verwendung von Computermethoden. Die Bioinformatik als eigenständige wissenschaftliche Richtung erschien in den frühen 70er Jahren des letzten Jahrhunderts, als erstmals Nukleotidsequenzen kleiner RNAs veröffentlicht und Algorithmen zur Vorhersage ihrer Sekundärstruktur (der räumlichen Anordnung von Atomen in einem Molekül) erstellt wurden.
Mit dem Humangenomprojekt hat eine neue Ära der Bioinformatik begonnen, die darauf abzielt, die Sequenz von Nukleotiden in der menschlichen DNA zu bestimmen und Gene im Genom zu identifizieren. Die Kosten für die DNA-Sequenzierung (Nukleotidsequenzierung) sind um mehrere Größenordnungen gesunken. Dies hat zu einer enormen Zunahme der Anzahl von Sequenzen in öffentlichen Datenbanken geführt. Die folgende Grafik zeigt das Wachstum der Anzahl der Sequenzen in der öffentlichen Datenbank der GenBank von Dezember 1982 bis Februar 2017 auf einer halblogarithmischen Skala. Damit die gesammelten Daten nützlich werden, müssen sie auf irgendeine Weise analysiert werden.

Zunahme der Sequenzanzahl in der GenBank von Dezember 1982 bis Februar 2017. Quelle: www.ncbi.nlm.nih.gov/genbank/statistics
Eine der Methoden der Sequenzanalyse in der Bioinformatik ist das Sequenzalignment. Das Wesentliche des Verfahrens liegt in der Tatsache, dass die Sequenzen von Monomeren von DNA, RNA oder Proteinen so untereinander angeordnet sind, dass ähnliche Bereiche sichtbar werden. Die Ähnlichkeit in den Primärstrukturen (dh Sequenzen) zweier Moleküle kann ihre funktionelle, strukturelle oder evolutionäre Beziehung widerspiegeln. Da eine Sequenz als Zeichenfolge mit einem bestimmten Alphabet dargestellt werden kann (4 Nukleotide für DNA und 20 Aminosäuren für Protein), stellt sich die Ausrichtung als kombinatorische Aufgabe von CS heraus (z. B. wird die Linienausrichtung auch bei der Verarbeitung natürlicher Sprache verwendet - NLP). Der biologische Kontext fügt dem Problem jedoch eine gewisse Spezifität hinzu.
Schauen wir uns die Ausrichtung am Beispiel von Proteinen an. Ein Aminosäurerest im Protein entspricht einem Buchstaben des lateinischen Alphabets in der Sequenz. Die Zeichenfolgen werden untereinander geschrieben, um die beste Übereinstimmung zu erzielen. Übereinstimmende Elemente liegen untereinander, "Lücken" werden durch "-" (Lücke) ersetzt. Sie bezeichnen Indel , dh den Ort der möglichen Insertion (Einführung eines oder mehrerer Nukleotide oder Aminosäuren in ein Molekül) und Deletionen ("Dropout" eines Nukleotids oder einer Aminosäure).

Ein Beispiel für die Ausrichtung der Aminosäuresequenzen zweier Proteine. Leucin (L) und Isoleucin (I), die Isomere sind, sind blau hervorgehoben - eine solche Substitution beeinflusst in den meisten Fällen die Proteinstruktur nicht
Wie können Sie jedoch feststellen, ob die Ausrichtung optimal ist? Das erste, was mir in den Sinn kommt, ist die Schätzung der Anzahl der Übereinstimmungen: Je mehr Übereinstimmungen, desto besser. Im Kontext der Biologie ist dies jedoch nicht ganz richtig. Substitutionen (Substitutionen einer Aminosäure gegen eine andere) sind ungleich: Einige Substitutionen (z. B. S und T, D und E sind Reste, deren Struktur sich um genau ein Kohlenstoffatom unterscheidet) beeinflussen die Struktur von Proteinen praktisch nicht. Das Ersetzen von Serin durch Tryptophan wird jedoch die Struktur des Moleküls stark verändern. Ein quantitatives Kriterium (Gewicht oder Punktzahl) wird eingegeben, um zu bestimmen, ob das Clearing das bestmögliche ist. Zur Beurteilung von Substitutionen werden sogenannte Substitutionsmatrizen verwendet, die auf der Statistik der Aminosäuresubstitution in Proteinen mit bekannter Struktur basieren. Je höher die Zahl am Schnittpunkt der übereinstimmenden Buchstaben ist, desto höher ist die Punktzahl.

In regelmäßigen Abständen erscheinen neue Substitutionsmatrizen. Hier ist die BLOSUM62-Matrix.
Die Bewertung berücksichtigt auch das Vorhandensein von Deletionen. Normalerweise ist die Strafe für das „Öffnen“ einer Löschung um mehrere Größenordnungen höher als für das „Fortfahren“. Dies liegt an der Tatsache, dass ein Abschnitt mit mehreren aufeinanderfolgenden Lücken als eine Mutation betrachtet wird und mehrere Lücken an verschiedenen Stellen als mehrere angesehen werden. Im folgenden Beispiel ist das erste Sequenzpaar ähnlicher als das zweite, da im ersten Fall die Sequenzen formal durch ein Evolutionsereignis getrennt sind:

Nun zu den Ausrichtungsalgorithmen selbst. Es gibt zwei Arten der gepaarten Ausrichtung (Finden ähnlicher Bereiche aus zwei Sequenzen): global und lokal. Globale Ausrichtung impliziert, dass die Sequenzen über ihre gesamte Länge homolog (ähnlich) sind. Es enthält beide Sequenzen in ihrer Gesamtheit. Bei diesem Ansatz sind ähnliche Bereiche jedoch nicht immer genau definiert, wenn nur wenige vorhanden sind. Lokales Alignment wird verwendet, wenn die Sequenzen als homolog gehalten werden (zum Beispiel aufgrund von Rekombination) und nicht verwandte Websites. Es kann aber nicht immer in den Bereich von Interesse gelangen, außerdem besteht die Möglichkeit, einen zufälligen ähnlichen Bereich zu treffen. Um eine paarweise Ausrichtung zu erhalten, werden dynamische Programmiermethoden verwendet (Lösen eines Problems durch Aufteilen in mehrere identische Teilaufgaben, die wiederholt miteinander verbunden sind). In Programmen zur globalen Ausrichtung wird häufig der Needleman-Wunsch-Algorithmus und für die lokale Ausrichtung der Smith-Waterman-Algorithmus verwendet . Sie können mehr darüber lesen, indem Sie den Links folgen.
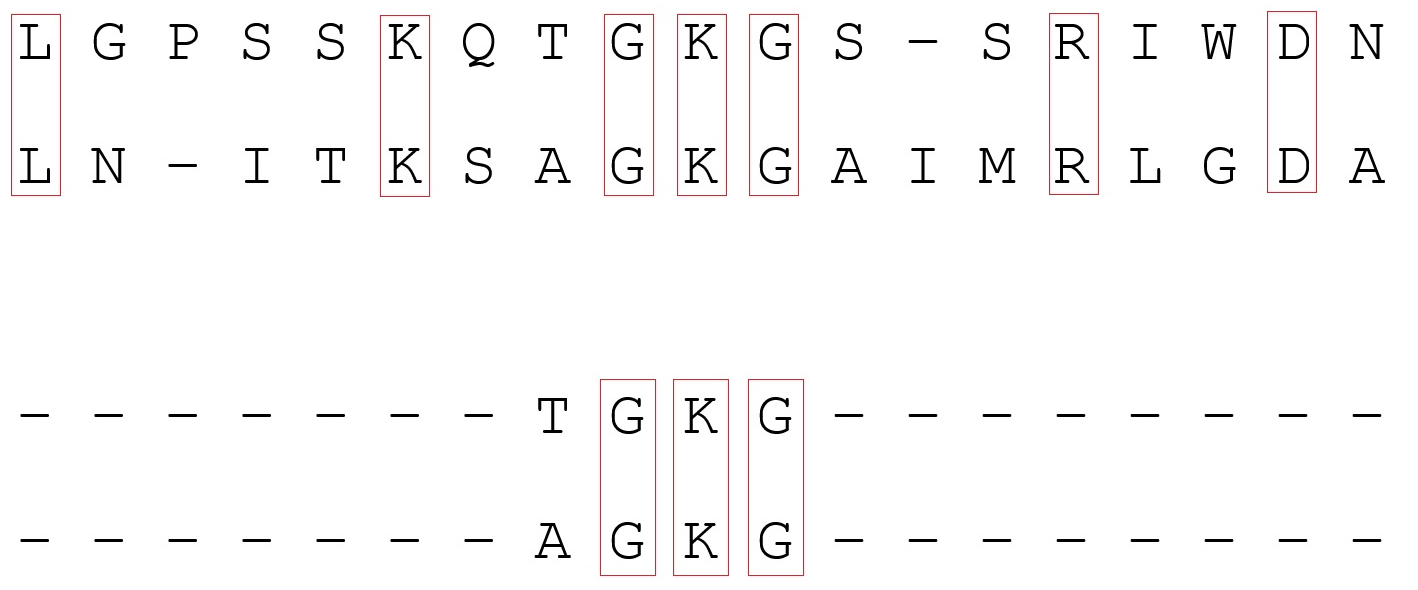
Ausrichtungsbeispiel: oben ist global, unten ist lokal. Im ersten Fall erfolgt die Ausrichtung entlang der gesamten Länge der Sequenzen, im zweiten Fall werden einige homologe Regionen gefunden.
Wie Sie sehen können, kann die biologische Aufgabe auf die Aufgabe von CS reduziert werden. Die paarweise Ausrichtung unter Verwendung der genannten Algorithmen erfordert etwa m * n zusätzlichen Speicher (m, n sind die Längen der Sequenzen), den moderne Heimcomputer leicht handhaben können. Die Bioinformatik hat jedoch auch nicht trivialere Aufgaben, beispielsweise die Mehrfachausrichtung (Ausrichtung mehrerer Sequenzen) zur Rekonstruktion phylogenetischer Bäume... Selbst wenn wir 10 sehr kleine Proteine mit einer Sequenzlänge von ungefähr 100 Zeichen vergleichen, wird eine unannehmbar große Menge an zusätzlichem Speicher benötigt (die Dimension des Arrays beträgt 100 ^ 10). Daher basiert die Ausrichtung in diesem Fall auf verschiedenen Heuristiken.
Modellierung der großräumigen Struktur des Universums
Im Gegensatz zur Biologie ist die Physik seit den Anfängen der Computer Seite an Seite mit der Informatik gegangen. Vor der Schaffung der ersten Computer wurde das Wort "Computer" (Taschenrechner) als Sonderstellung bezeichnet - dies waren Personen, die mathematische Berechnungen an Taschenrechnern durchführten. Während des Manhattan-Projekts war der Physiker Richard Feynman der Manager eines ganzen Teams von "Taschenrechnern", die Differentialgleichungen beim Hinzufügen von Maschinen verarbeiteten.

"Computerraum" des Flugforschungszentrums. Armstrong. USA, 1949
Derzeit sind CS-Methoden in verschiedenen Bereichen der Physik weit verbreitet. Beispielsweise untersucht die Computerphysik numerische Algorithmen zur Lösung physikalischer Probleme, für die bereits eine quantitative Theorie entwickelt wurde. In Situationen, in denen die direkte Beobachtung von Objekten schwierig ist (dies kommt in der Astronomie häufig vor), hilft die Computermodellierung Wissenschaftlern. Genau ein solcher Fall ist die Untersuchung der großräumigen Struktur des Universums : Beobachtungen entfernter Objekte sind aufgrund der Absorption elektromagnetischer Strahlung in der Ebene der Milchstraße schwierig , weshalb die Modellierung zur Hauptforschungsmethode geworden ist.

,
Eine der Aufgaben der modernen Kosmologie ist es, das beobachtete Bild der Vielfalt der Galaxien und ihrer Entwicklung zu erklären. Auf qualitativer Ebene sind die in Galaxien ablaufenden physikalischen Prozesse bekannt, daher zielen die Bemühungen der Wissenschaftler darauf ab, quantitative Vorhersagen zu erhalten. Dies ermöglicht die Beantwortung einer Reihe grundlegender Fragen, beispielsweise zu den Eigenschaften der Dunklen Materie. Bevor jedoch die beobachteten Manifestationen der Dunklen Materie isoliert werden, ist es notwendig, das Verhalten der gewöhnlichen Materie zu verstehen. In großem Maßstab (mehrere Millionen Lichtjahre) verhält sich gewöhnliche Materie genauso wie Dunkelheit: Sie unterliegt einer Schwerkraft, man kann den Gasdruck vergessen. Dies macht es relativ einfach, die Entwicklung der großräumigen Struktur des Universums zu simulieren (Numerische Methoden,Seit den 1980er Jahren begann sich die Entwicklung von Galaxien zu entwickeln, die nur dunkle oder staubartige Materie enthielten und die großräumige Struktur der Verteilung von Galaxien gut reproduzierten.
Dunkle Materie wird wie folgt modelliert. Der virtuelle Würfel mit einer Größe von Hunderten Millionen Lichtjahren ist fast gleichmäßig mit Testpartikeln - Körpern - gefüllt. Von Anfang an waren im Universum kleine Inhomogenitäten vorhanden, aus denen die gesamte beobachtete Struktur hervorging, daher ist die Füllung "fast gleichmäßig". Dann beginnen die Teilchen unter dem Einfluss der Schwerkraft „ihr eigenes Leben zu führen“: Das Problem der N Körper ist gelöst . Die aus dem Würfel austretenden Partikel werden auf die gegenüberliegende Fläche übertragen, und die Gravitationskräfte breiten sich auch mit der Übertragung aus. Dank dessen wird der Würfel sozusagen unendlich wie das Universum.

Ungefähre Flugbahnen von drei identischen Körpern, die sich an den Eckpunkten eines nicht gleichschenkligen Dreiecks befinden und keine Anfangsgeschwindigkeiten
von Null aufweisen. Eines der bekanntesten numerischen Modelle dieses Typs ist das Millenium mit einer Würfelgröße von mehr als 1,5 Milliarden Lichtjahren und etwa 10 Milliarden Teilchen. In den folgenden Jahren wurden mehrere größere Modelle hergestellt: der Horizon Run mit einer Würfelseite, die viermal größer als das Millenium ist, und der Dark Sky mit dem 16-fachen des Millenium. Diese und ähnliche Modelle haben eine Schlüsselrolle in Projekten zur Validierung des inzwischen allgemein anerkannten Lambda-CDM- Modells gespielt. (Ein Universum mit etwa 70% dunkler Energie, 25% dunkler Materie und 5% gewöhnlicher Materie).

Millenium: , ; — . .
Das Downscaling verursacht Probleme beim Abgleichen von Beobachtungen und numerischen Modellen mit einer dunklen Materie. In kleinerem Maßstab (dem Ausmaß der Ausbreitung von Stoßwellen aus Supernovae) kann Materie nicht mehr als staubig angesehen werden. Es ist notwendig, die Hydrodynamik, das Kühlen und Erwärmen von Gas durch Strahlung und vieles mehr zu berücksichtigen. Um alle Gesetze der Physik bei der Modellierung zu berücksichtigen, werden einige Vereinfachungen vorgenommen: Sie können beispielsweise den Modellwürfel in ein Gitter von Zellen aufteilen (Untergitterphysik) und davon ausgehen, dass eine bestimmte Dichte und Temperatur in der Zelle erreicht ist Ein Teil des Gases verwandelt sich sofort in einen Stern. Diese Modellklasse umfasst die Projekte EAGLE und illustris . Eines der Ergebnisse dieser Projekte ist die Reproduktion der Tully-Fisher-Beziehung zwischen der Leuchtkraft der Galaxie und der Rotationsgeschwindigkeit der Scheibe.
Linguistik und maschinelles Lernen: Ein Schritt näher an der Lösung eines 4.000 Jahre alten Rätsels
CS-Methoden finden Anwendung in unerwarteten Bereichen, beispielsweise beim Studium alter Sprachen und Schriftsysteme. So beleuchtete eine Studie einer Gruppe von Wissenschaftlern unter der Leitung von Rajesh P. N. Rao, Professor an der University of Washington, das Geheimnis des Indus Valley-Schreibens.
Die Indus-Schrift, die zwischen 2600 und 1900 v. Chr. Im heutigen Ostpakistan und im Nordwesten Indiens verwendet wurde, gehörte zu einer Zivilisation, die nicht weniger komplex und mysteriös war als ihre mesopotamischen und ägyptischen Zeitgenossen. Es gibt nur noch sehr wenige schriftliche Quellen: Archäologen haben nur etwa 1.500 einzigartige Inschriften auf Fragmenten von Keramik, Tafeln und Siegeln gefunden. Die längste Beschriftung ist nur 27 Zeichen lang.

Inschriften auf Robben aus dem Industal
In der wissenschaftlichen Gemeinschaft gab es verschiedene Hypothesen über die "mysteriösen Symbole". Einige Experten betrachteten Symbole als nichts anderes als "hübsche Bilder". So veröffentlichte der Linguist Steve Farmer 2004 einen Artikel, in dem argumentiert wurde, dass die Indus-Schrift nichts anderes als politische und religiöse Symbole sei. Obwohl seine Version umstritten war, fand sie immer noch ihre Anhänger.
Rajesha P. N. Rao, ein Wissenschaftler für maschinelles Lernen, las über Indus-Schreiben in der High School. Eine Gruppe von Wissenschaftlern unter seiner Leitung beschloss, eine statistische Analyse vorhandener zuverlässiger Dokumente durchzuführen. Im Laufe der Forschung mit Markov-Ketten(Eine der ersten Disziplinen, in denen Markov-Ketten praktische Anwendung fanden, war die Textkritik) Die bedingte Entropie wurde verglichen Symbole aus der Indus-Schrift mit der Entropie sprachlicher und nichtsprachlicher Zeichenfolgen. Bedingte Entropie ist die Entropie für ein Alphabet, für das die Wahrscheinlichkeiten eines Buchstabens nach dem anderen bekannt sind. Zum Vergleich wurden mehrere Systeme ausgewählt. Zu den Sprachsystemen gehörten: Sumerisches logografisches Schreiben, Altes Tamil Abugida, Sanskrit des Rig Veda, modernes Englisch (Wörter und Buchstaben wurden getrennt studiert) und die Programmiersprache Fortran. Nichtsprachliche Systeme wurden in zwei Gruppen eingeteilt. Das erste umfasste Systeme mit einer starren Zeichenreihenfolge (künstlicher Zeichensatz Nr. 1), das zweite - Systeme mit einer flexiblen Reihenfolge (Bakterienproteine, menschliche DNA, künstlicher Zeichensatz Nr. 2). Infolgedessen stellte sich heraus, dass die proto-indische Schrift wie das Schreiben der gesprochenen Sprachen mäßig geordnet war:Die Entropie vorhandener Dokumente ähnelt der Entropie der sumerischen und tamilischen Schriften.

Bedingte Entropie für verschiedene sprachliche und nichtsprachliche Systeme
Dieses Ergebnis widerlegte die Hypothese über die ornamentale Verwendung von Zeichen. Und obwohl CS-Methoden dazu beigetragen haben, die Version zu bestätigen, dass die Symbole aus dem Indus-Tal höchstwahrscheinlich ein Schriftsystem sind, ist die Angelegenheit noch nicht entschlüsselt.
Fazit
Natürlich sind viele Bereiche, in denen CS-Methoden Anwendung finden, über Bord. In einem Artikel ist es einfach unmöglich aufzuzeigen, wie die moderne Wissenschaft auf Computertechnologie beruht. Ich hoffe jedoch, dass die angegebenen Beispiele zeigen, wie verschiedene Probleme gelöst werden können, auch mit CS-Methoden.
Cloud-Server von Macleod sind schnell und sicher.
Registrieren Sie sich über den obigen Link oder indem Sie auf das Banner klicken und erhalten Sie 10% Rabatt für den ersten Monat der Anmietung eines Servers einer beliebigen Konfiguration!
