
Mein Name ist Sasha, bei SberDevices arbeite ich an der Spracherkennung und wie Daten sie verbessern können. In diesem Artikel werde ich über den neuen Golos-Sprachdatensatz sprechen, der aus Audiodateien und entsprechenden Transkriptionen besteht. Die Gesamtdauer der Aufnahmen beträgt ca. 1240 Stunden, die Abtastrate beträgt 16 kHz. Im Moment ist dies das größte Korpus von Audioaufnahmen in russischer Sprache, die von Hand markiert wurden. Wir haben den Korpus unter einer Lizenz in der Nähe von CC Attribution ShareAlike veröffentlicht , die es ermöglicht, ihn sowohl für wissenschaftliche Forschung als auch für kommerzielle Zwecke zu verwenden. Ich werde darüber sprechen, woraus der Datensatz besteht, wie er zusammengestellt wurde und welche Ergebnisse er erzielen kann.
Golos-Datensatzstruktur
Bei der Erstellung des Datensatzes wurden wir von dem Wunsch geleitet, das Kaltstartproblem zu lösen, wenn Daten von echten Benutzern noch nicht verfügbar waren. Dies hat es letztendlich möglich gemacht, es öffentlich zugänglich zu machen, da die Sprache der echten Benutzer nicht da ist.
Die Audioaufnahmen im Datensatz stammen aus zwei Quellen. Die erste Quelle ist eine Crowdsourcing-Plattform, weshalb wir sie Crowd Domain nennen. Die zweite Quelle sind Aufnahmen, die im Studio mit dem SberPortal-Zielgerät erstellt wurden. Es verfügt über ein spezielles Mikrofonsystem, und dies ist eines der Geräte, auf denen unsere Spracherkennung funktionieren sollte.
Wir nennen diese Quelle Farfield-Domain, da die Entfernung vom Benutzer zum Gerät normalerweise recht groß ist. Für die Aufnahme über SberPortal im Studio haben wir drei Entfernungen verwendet: 1, 3 und 5 Meter vom Benutzer zum Gerät. Jede Domäne hat einen Trainings- und Testteil, die resultierende Struktur ist in der Tabelle gezeigt:
| Domänen | Trainingsteil | Testteil |
|---|---|---|
| Menge | 979 796 Dateien | 1095 Stunden | 9994 Dateien | 11,2 Stunden |
| Fernfeld | 124 003 Dateien | 132,4 Stunden | 1916 Dateien | 1,4 Stunden |
| Gesamt | 1 103 799 Dateien | 1227,4 Stunden | 11910 Dateien | 12,6 Stunden |
Der Datensatz enthält keine persönlichen Informationen wie Alter, Geschlecht oder Benutzer-ID - alles ist unpersönlich. Die Trainings- und Testteile können die Sprache desselben Benutzers enthalten.
| Statistik \ Domains | Menge | Fernfeld |
|---|---|---|
| Nummer | 979796 Dateien | 124003 Dateien |
| Durchschnittlich | 4,0 Sek. | 3,8 Sek. |
| Standardabweichung | 1,9 Sek. | 1,6 Sek. |
| 1. Perzentil | 1,4 Sek. | 2,0 Sek. |
| 50. Perzentil | 3,7 Sek. | 3,5 Sek. |
| 95. Perzentil | 7,3 Sek. | 6,8 Sek. |
| 99. Perzentil | 10,5 Sek. | 9,6 Sek. |
Die obige Tabelle enthält einige statistische Informationen zu den Einträgen: Mittelwert, Standardabweichung und Perzentile. Zur Verdeutlichung zeigt die Abbildung zwei Histogramme der Verteilung der Datensatzlängen:
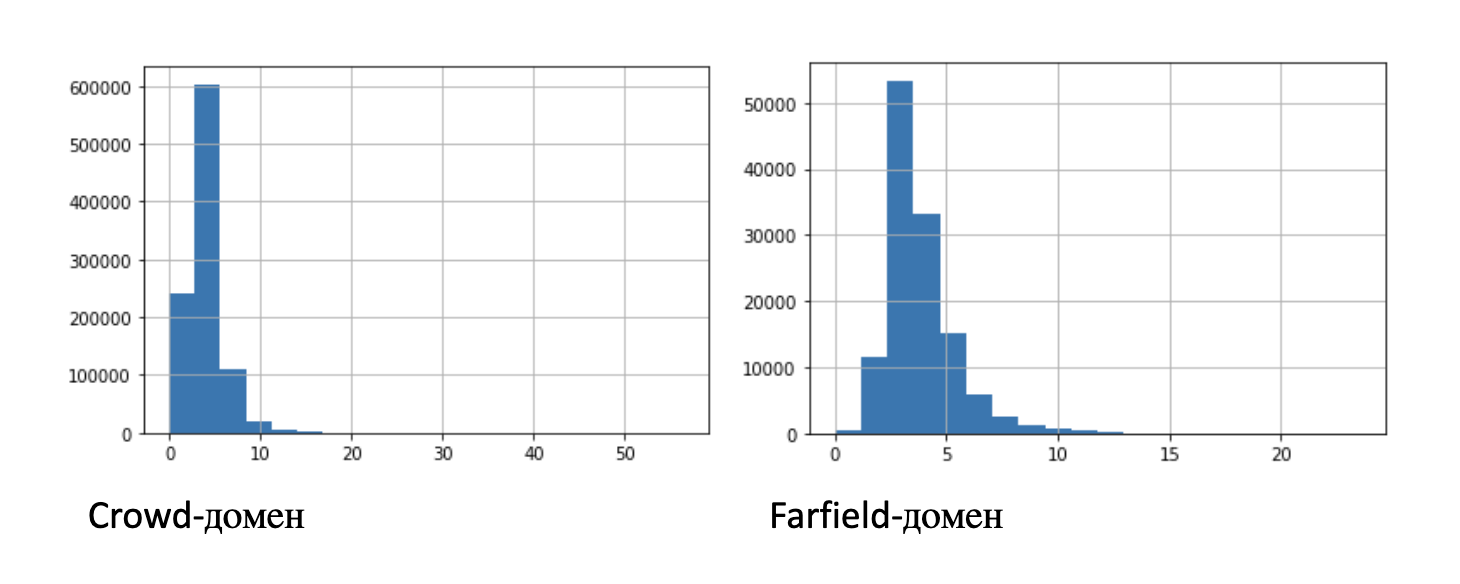
Für Experimente mit einer begrenzten Anzahl von Datensätzen haben wir Teilmengen mit kürzerer Länge identifiziert: 100 Stunden, 10 Stunden, 1 Stunde, 10 Minuten.
Datensammlung
Bei SberDevices entwickeln wir die Salute-Familie virtueller Assistenten, sodass wir eine Sprache generieren, die den Benutzeranfragen für einen Assistenten ähnelt. Wir haben ein Vorlagensystem erstellt, um Anfragen in verschiedenen Bereichen zu beschreiben - Musik, Filme, Bestellung von Produkten und andere. Sie sind Ausdrücke, die die Struktur einer Anforderung beschreiben und in Komponenten zerlegen. Mithilfe von Vorlagen können wir sinnvolle Abfragen generieren, das akustische Modell neu trainieren, ein Sprachmodell erstellen, das auf diesen Abfragen basiert, und vieles mehr.
Beispielvorlagen:
| Vorlage | Beispiel |
|---|---|
| [command_demands_vp] + [film_syn_vp] + [film_title_ip] | Spielen Sie das grüne Buch des Films |
| [command_demands_ip] + [film_syn_ip] + [film_title_ip] | Sie haben ein grünes Filmbuch |
| [command_demands_ip] + [film_title_ip] | Hast du ein grünes Buch? |
| [film_title_ip] + [command_demands_vp] | lege grünes Buch |
| [film_syn_ip] + [film_title_ip] + [command_demands_vp] | Film das grüne Buch setzen |
| [film_title_ip] | grünes Buch |
| [command_demands_vp] + [film_title_ip] | Schalten Sie das grüne Buch ein |
| [film_syn_ip] + [film_title_ip] | Film grünes Buch |
| [command_demands_vp] + [film_title_ip] | Schalten Sie das grüne Buch ein |
| ... | ... |
In eckigen Klammern - die Bezeichnung der entsprechenden Entität. Weiter in der Tabelle für zwei Entitäten "film_title_ip" und "film_title_vp" gibt es mögliche Optionen zum Ausfüllen:
| film_title_ip | film_title_vp |
|---|---|
| Obsession | Obsession |
| die Flucht | die Flucht |
| Die Schöne und das Biest | die Schöne und das Biest |
| die Insel | die Insel |
| Jane Eyre | Jane Eyre |
| Wuthering Heights | Wuthering Heights |
| ... | ... |
Das Erstellen eines mit Tags versehenen Audiodatensatzes besteht aus mehreren Schritten:
- Schritt 1. Zuerst erstellen wir Vorlagen für eine bestimmte Domain.
- 2. - . , :
- 3. «» :
- 4. – , , . – . 80% Golos. , “”, , . , , .
- 4*. - , , , , , , . , . , , , , , . , .

- 5*. , . , . , , , . , , , . , , , . , . :

:
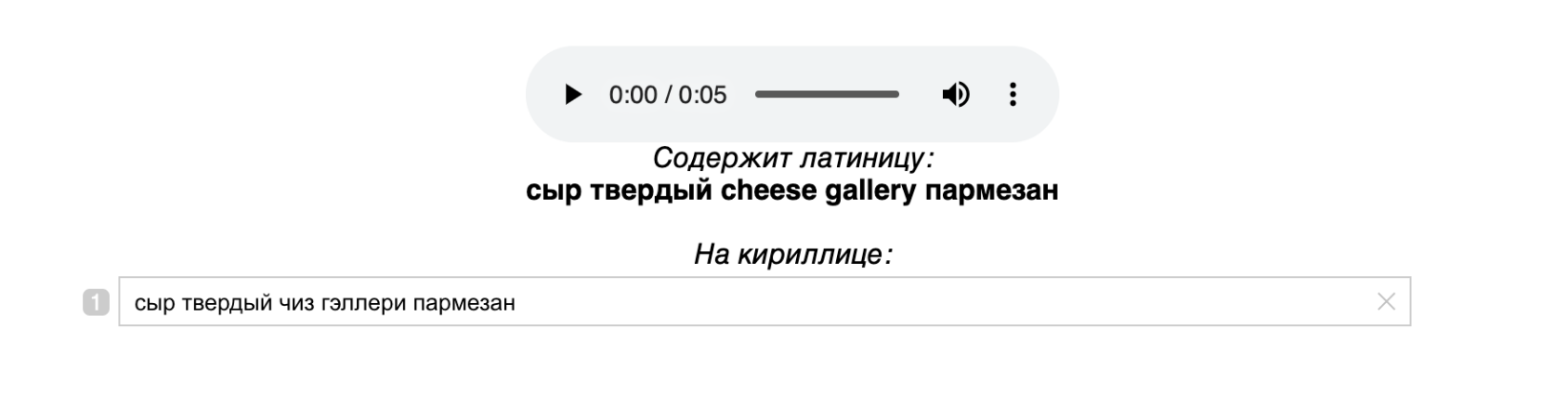
, . .
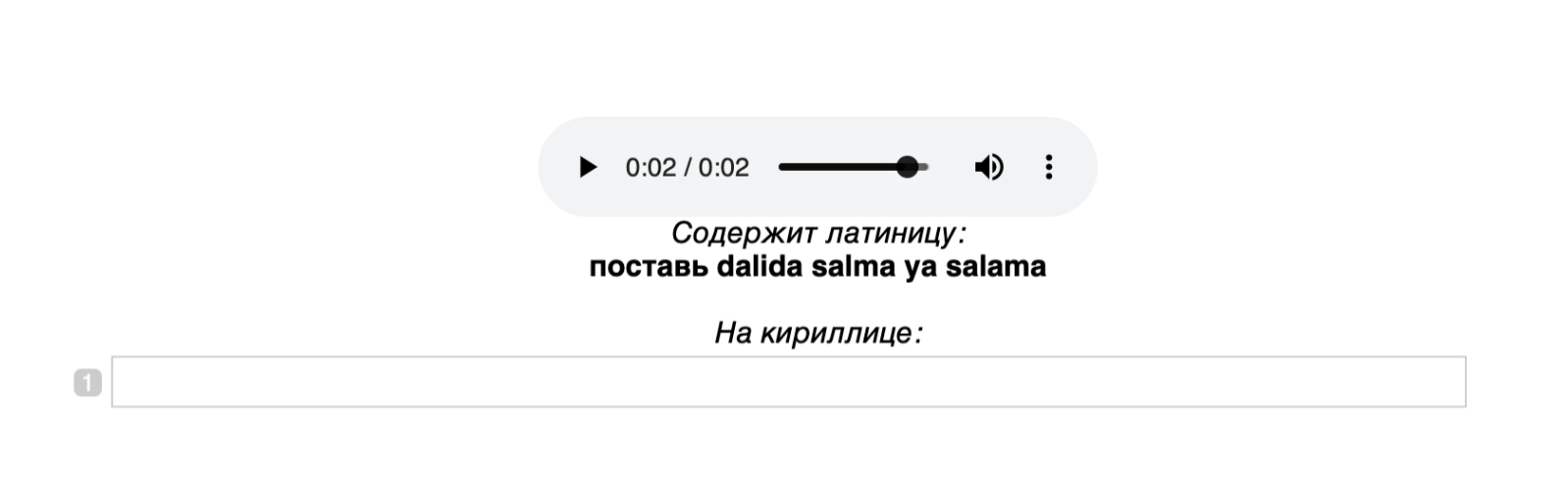
, , , .
- 5 . 3 , .
. -, , . -, . , .
, , “” – , “” - . , , , ( ) . bias , , . , . , .
Der beschriebene Prozess zum Erstellen eines Datasets ermöglicht es Ihnen, Markups so hochwertig wie möglich zu gestalten, wodurch sie sich von anderen unterscheiden, die automatisch oder halbautomatisch erstellt wurden. Wir verwenden diese Daten, um ein Spracherkennungssystem in unseren Geräten zu erstellen. Aufgrund der hohen Qualität der Markierungen ist die Genauigkeit des resultierenden Systems mit der eines Menschen vergleichbar. Alle Daten sowie trainierte Akustik- und Sprachmodelle für die Spracherkennung sind auf der GitHub- Seite des Projekts sowie in ML Space von Sbercloud verfügbar , einem Dienst zum Trainieren von Modellen für maschinelles Lernen, bei dem unser Datensatz nahtlos direkt in die Benutzeroberfläche heruntergeladen werden kann . Im nächsten Artikel erfahren Sie mehr über die Verwendung von ML Space und wie wir damit Spracherkennungsmodelle vermittelt haben.
Derzeit gibt es viele offene Daten auf Englisch, aber es gab keinen so hochwertigen russischsprachigen Datensatz. Jetzt ist auch ein Korpus in russischer Sprache erhältlich, der zur Spracherkennung und -synthese verwendet werden kann, und das darauf trainierte Modell weist eine sehr hohe Qualität auf. Wir glauben, dass der Golos-Datensatz es der russischen Wissenschaft ermöglichen wird, die russischsprachigen Sprachtechnologien noch schneller zu verbessern.