
!
, Head of AI Celsus. .
, , ML- . «» — , , .
ML- DS-, , CV .
Nehmen wir also an, Sie entscheiden sich für die Gründung eines KI-Start-ups zur Erkennung von Brustkrebs (übrigens die häufigste Art der Onkologie bei Frauen) und werden ein System entwickeln, das Anzeichen von Pathologie bei Mammographieuntersuchungen genau erkennt Arzt gegen Fehler und verkürzen Sie die Zeit, um eine Diagnose zu stellen ... Eine glänzende Mission, nicht wahr?

Sie haben ein Team von talentierten Programmierern, ML-Ingenieuren und Analysten zusammengestellt, teure Geräte gekauft, ein Büro gemietet und eine Marketingstrategie ausgearbeitet. Alles scheint bereit zu sein, die Welt zum Besseren zu verändern! Leider ist nicht alles so einfach, weil Sie das Wichtigste vergessen haben - Daten. Ohne sie können Sie kein neuronales Netzwerk oder ein anderes Modell für maschinelles Lernen trainieren.
Hier liegt eines der Haupthindernisse - die Quantität und Qualität der verfügbaren Datensätze. Leider gibt es auf dem Gebiet der diagnostischen Medizin immer noch sehr wenige qualitativ hochwertige, verifizierte und vollständige Datensätze, von denen noch weniger Forschern und KI-Unternehmen öffentlich zugänglich sind.
Betrachten Sie die Situation anhand des gleichen Beispiels für die Erkennung von Brustkrebs. Mehr oder weniger hochwertige öffentliche Datensätze können an den Fingern einer Hand gezählt werden: DDSM (ca. 2600 Fälle), InBreast (115), MIAS (161). Es gibt auch OPTIMAM und BCDR mit einem ziemlich komplizierten und verwirrenden Verfahren, um Zugang zu erhalten.
Und selbst wenn Sie in der Lage waren, eine ausreichende Menge öffentlicher Daten zu sammeln, erwartet Sie das nächste Hindernis: Fast alle diese Datensätze dürfen nur für nichtkommerzielle Zwecke verwendet werden. Darüber hinaus kann das Markup in ihnen völlig unterschiedlich sein - und es ist keine Tatsache, dass es für Ihre Aufgabe geeignet ist. Im Allgemeinen ist es ohne die Erfassung Ihrer eigenen Datensätze und deren Markups möglich, nur ein MVP, jedoch kein qualitativ hochwertiges Produkt, für den Einsatz unter Kampfbedingungen vorzubereiten.
Sie haben also Anfragen an medizinische Einrichtungen gesendet, alle Ihre Verbindungen und Kontakte hergestellt und eine bunte Sammlung verschiedener Bilder in Ihren Händen erhalten. Freuen Sie sich nicht im Voraus, Sie stehen ganz am Anfang des Weges! In der Tat, trotz des Vorhandenseins eines einheitlichen Standards für die Speicherung von medizinischen Bildern, DICOM(Digitale Bildgebung und Kommunikation in der Medizin), im wirklichen Leben ist nicht alles so rosig. Beispielsweise können Informationen über die Seite (links / rechts) und die Projektion ( CC / MLO ) eines Brustbildes in verschiedenen Datenquellen in völlig verschiedenen Feldern gespeichert werden. Die einzige Lösung besteht darin, Daten aus möglichst vielen Quellen zu sammeln und zu versuchen, alle möglichen Optionen in der Logik des Dienstes zu berücksichtigen.
Was Sie markieren, ist das, was Sie ernten
Wir haben endlich den lustigen Teil erreicht - den Daten-Markup-Prozess. Was macht es im medizinischen Bereich so besonders und unvergesslich? Erstens ist der Prozess der Kennzeichnung selbst viel komplizierter und länger als in den meisten Branchen. Röntgenstrahlen können nicht auf Yandex.Toloka hochgeladen werden, und Sie können einen mit Tags versehenen Datensatz für einen Cent erhalten. Dies erfordert mühsame Arbeit von Fachärzten, und es ist ratsam, jedes Bild zur Kennzeichnung mehreren Ärzten zu geben - und dies ist teuer und zeitaufwändig.
Weiter noch schlimmer: Experten sind sich oft nicht einig und geben am Ausgang völlig unterschiedliche Markierungen derselben Bilder. Ärzte haben unterschiedliche Qualifikationen, Ausbildung, "Verdacht". Jemand markiert alle Objekte im Bild sauber entlang der Kontur und jemand - mit breiten Rahmen. Schließlich ist einer von ihnen voller Energie und Begeisterung, während ein anderer nach einer zwanzigstündigen Schicht Bilder auf einem kleinen Laptop-Bildschirm markiert. All diese Diskrepanzen "treiben" natürlich verrückte neuronale Netze an, und Sie werden unter solchen Bedingungen kein qualitativ hochwertiges Modell erhalten.
Die Situation wird auch nicht dadurch verbessert, dass die meisten Fehler und Diskrepanzen genau in den komplexesten Fällen auftreten, die für das Training von Neuronen am wertvollsten sind. Zum Beispiel Forschungzeigen, dass die meisten Fehler, die Ärzte bei der Diagnose von Mammographien mit einer erhöhten Dichte an Brustgewebe machen, nicht überraschend sind, dass sie auch für KI-Systeme am schwierigsten sind.
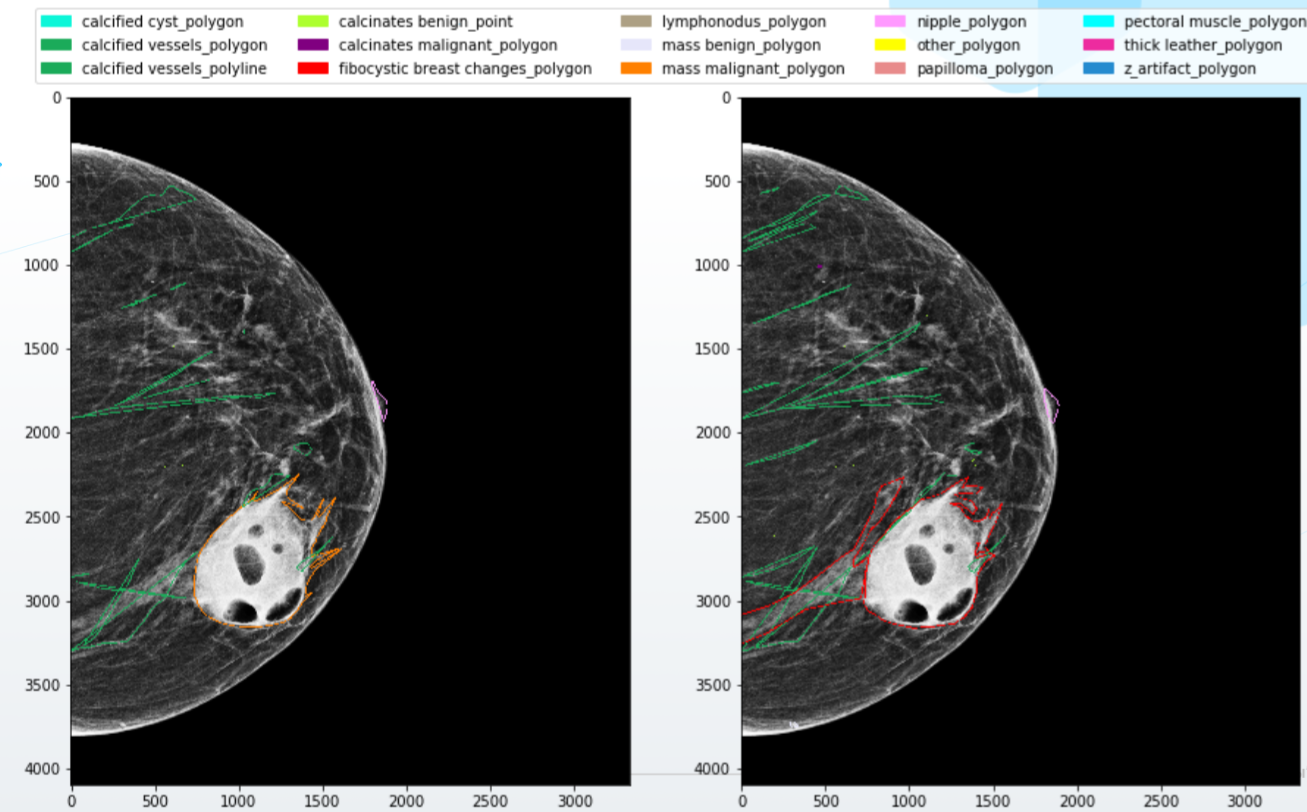
Was zu tun ist? Zunächst müssen Sie natürlich ein qualitativ hochwertiges System für die Interaktion mit Ärzten aufbauen. Schreiben Sie detaillierte Regeln für das Markup mit Beispielen und Visualisierungen, stellen Sie Spezialisten hochwertige Software und Ausrüstung zur Verfügung, schreiben Sie die Logik für die Kombination kleinerer Konflikte im Markup auf und fragen Sie bei schwerwiegenderen Konflikten nach einer zusätzlichen Meinung.
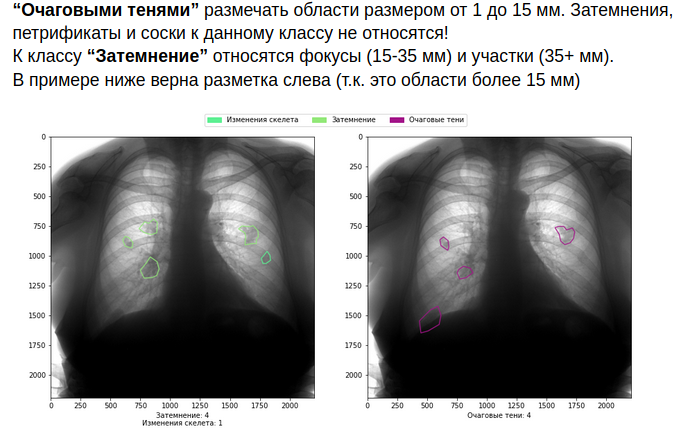
Wie Sie sich vorstellen können, erhöht dies die Kosten für das Markup. Aber wenn Sie nicht bereit sind, sie auf sich zu nehmen, ist es besser, nicht in die Medizin zu gehen.
Wenn Sie den Prozess mit Bedacht angehen, können und sollten natürlich die Kosten gesenkt werden - zum Beispiel durch aktives Lernen. In diesem Fall fordert das ML-System selbst die Ärzte auf, welche Bilder zusätzlich markiert werden müssen, um die Qualität der Pathologieerkennung zu maximieren. Es gibt verschiedene Möglichkeiten, das Vertrauen eines Modells in seine Vorhersagen zu bewerten - Lernverlust, diskriminatives aktives Lernen, MC-Ausfall, Entropie vorhergesagter Wahrscheinlichkeiten, Vertrauenszweig und viele andere. Welches ist besser zu verwenden, zeigen nur Experimente mit Ihren Modellen und Datensätzen.
Schließlich können Sie den Aufschlag von Ärzten vollständig aufgeben und sich nur auf die endgültigen, bestätigten Ergebnisse verlassen - zum Beispiel auf den Tod oder die Genesung des Patienten. Vielleicht ist dies der beste Ansatz (obwohl es hier viele Nuancen gibt), aber er kann erst in zehn bis fünfzehn Jahren funktionieren, wenn PACS (Bildarchivierungs- und Kommunikationssysteme) und medizinische Informationssysteme (MIS) vollwertig sind ) und wenn genügend Daten gesammelt wurden. Aber auch in diesem Fall garantiert niemand die Reinheit und Qualität dieser Daten.
Gutes Modell - gute Vorverarbeitung

Hurra! Das Modell wurde trainiert, zeigt hervorragende Ergebnisse und ist bereit, pilotiert zu werden. Mit mehreren medizinischen Organisationen wurden Kooperationsvereinbarungen geschlossen, das System wurde installiert und konfiguriert, Ärzten wurde eine Demonstration durchgeführt und die Leistungsfähigkeit des Systems wurde gezeigt.
Und jetzt, da der erste Tag des Systembetriebs vorbei ist, öffnen Sie das Dashboard mit Metriken mit sinkendem Herzen ... Und Sie sehen das folgende Bild: eine Reihe von Anforderungen an das System, bei denen vom System keine Objekte erkannt wurden und von Natürlich eine negative Reaktion von Ärzten. Wie? Immerhin hat sich das System in internen Tests als hervorragend erwiesen!
Bei weiterer Analyse stellt sich heraus, dass es in dieser medizinischen Einrichtung eine Art Röntgengerät gibt, das Ihnen mit seinen eigenen Einstellungen nicht vertraut ist, und daher sehen die Bilder völlig anders aus. Das neuronale Netzwerk wurde nicht auf solche Bilder trainiert, daher ist es nicht überraschend, dass es auf ihnen "ausfällt" und nichts erkennt. In der Welt des maschinellen Lernens werden solche Fälle üblicherweise als Out-of-Distribution-Daten bezeichnet. Modelle schneiden bei solchen Daten normalerweise erheblich schlechter ab, und dies ist eines der Hauptprobleme des maschinellen Lernens.
Anschauliches Beispiel: Unser Team hat ein öffentliches Modell getestet von Forschern der New York University, die auf eine Million Bilder trainiert wurden. Die Autoren des Artikels argumentieren, dass das Modell eine hohe Qualität des Nachweises der Onkologie in Mammographien zeigte, und sprechen insbesondere von der ROC-AUC-Genauigkeitsrate im Bereich von 0,88 bis 0,89. In unseren Daten zeigt dasselbe Modell signifikant schlechtere Ergebnisse - von 0,65 bis 0,70, abhängig vom Datensatz.
Die einfachste Lösung für dieses Problem an der Oberfläche besteht darin, alle möglichen Arten von Bildern von allen Geräten mit allen Einstellungen zu sammeln, sie zu markieren und das System darauf zu trainieren. Minuspunkte? Wieder lang und teuer. In einigen Fällen können Sie auf Markup verzichten - unbeaufsichtigtes Lernen hilft Ihnen dabei. Unbeschriftete Bilder werden dem Neuron auf eine bestimmte Weise übergeben, und das Modell "gewöhnt" sich an seine Merkmale, wodurch es in Zukunft erfolgreich Objekte in ähnlichen Bildern erkennen kann. Dies kann zum Beispiel durch Pseudo-Markup von Bildern ohne Tags oder durch verschiedene Hilfsaufgaben erfolgen.
Dies ist jedoch auch kein Allheilmittel. Darüber hinaus müssen Sie bei dieser Methode alle Arten von Bildern sammeln, die auf der Welt existieren, was im Prinzip eine unmögliche Aufgabe zu sein scheint. Und die beste Lösung wäre hier die universelle Vorverarbeitung.
Die Vorverarbeitung ist ein Algorithmus zum Verarbeiten von Eingabedaten, bevor diese in ein neuronales Netzwerk eingespeist werden. Dieses Verfahren kann automatische Änderungen von Kontrast und Helligkeit, verschiedene statistische Normalisierungen und das Entfernen unnötiger Bildteile (Artefakte) umfassen.
Zum Beispiel gelang es unserem Team nach vielen Experimenten, eine universelle Vorverarbeitung für Röntgenbilder der Brustdrüse zu erstellen, die fast alle Eingabebilder in eine einheitliche Form bringt, sodass das neuronale Netzwerk sie korrekt verarbeiten kann.

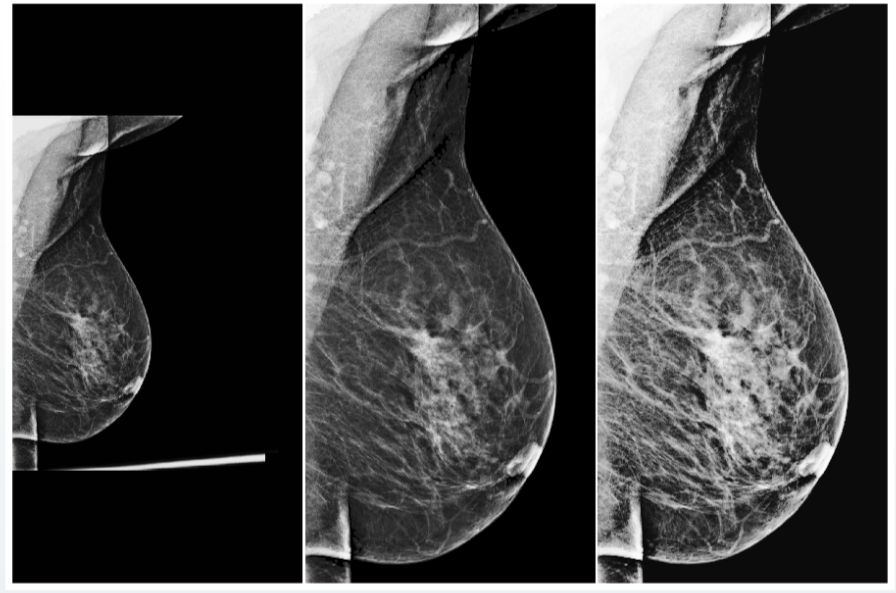
Aber auch bei der universellen Vorverarbeitung sollten Sie die Qualitätsprüfungen der Eingabedaten nicht vergessen. Beispielsweise stießen wir in fluorografischen Datensätzen häufig auf Testbilder, darunter Beutel, Flaschen und andere Objekte. Wenn das System eine Wahrscheinlichkeit für das Vorhandensein einer Pathologie in einem solchen Bild festlegt, erhöht dies eindeutig nicht das Vertrauen der medizinischen Gemeinschaft in Ihr Modell. Um solche Probleme zu vermeiden, müssen KI-Systeme auch ihr Vertrauen in korrekte Vorhersagen und in die Gültigkeit der Eingabedaten signalisieren.

Unterschiedliche Hardware ist nicht das einzige Problem mit der Fähigkeit von KI-Systemen, neue Daten zu verallgemeinern, zu verallgemeinern und damit zu arbeiten. Ein sehr wichtiger Parameter sind die demografischen Merkmale des Datensatzes. Wenn Ihre Trainingsstichprobe beispielsweise von Russen über 60 dominiert wird, kann niemand garantieren, dass das Modell bei jungen Asiaten korrekt funktioniert. Die Ähnlichkeit der statistischen Indikatoren der Trainingsstichprobe und der tatsächlichen Bevölkerung, für die das System verwendet wird, muss unbedingt überwacht werden.
Wenn Unstimmigkeiten festgestellt werden, müssen unbedingt Tests und höchstwahrscheinlich zusätzliche Schulungen oder Feinabstimmungen des Modells durchgeführt werden. Es ist unbedingt erforderlich, das System ständig zu überwachen und regelmäßig zu überarbeiten. In der realen Welt können eine Million Dinge passieren: Das Röntgengerät wurde ersetzt, ein neuer Laborassistent ist gekommen, der auf andere Weise forscht, Massen von Migranten aus einem anderen Land strömten plötzlich in die Stadt. All dies kann zu einer Verschlechterung der Qualität Ihres KI-Systems führen.
Wie Sie vielleicht erraten haben, ist Lernen jedoch nicht alles. Das System muss mindestens bewertet werden, und Standardmetriken sind im medizinischen Bereich möglicherweise nicht anwendbar. Dies macht es auch schwierig, konkurrierende KI-Dienste zu bewerten. Dies ist jedoch das Thema für den zweiten Teil des Materials - wie immer, basierend auf unserer persönlichen Erfahrung.