Viele Projekte verwenden jetzt die Microservice-Architektur. Wir sind auch keine Ausnahme, und seit mehr als 2 Jahren versuchen wir, RBS für juristische Personen in einer Bank mithilfe von Microservices aufzubauen.

Autoren des Artikels: ctimas und Alexey_Salaev
Die Bedeutung der Microservice-Architektur
Unser Projekt ist eine RBS für juristische Personen. Viele verschiedene Prozesse unter der Haube und eine schöne minimalistische Oberfläche. Das war aber nicht immer so. Lange Zeit verwendeten wir eine Lösung eines Auftragnehmers, aber eines schönen Tages wurde beschlossen, unser Produkt zu entwickeln.
Zu Beginn des Projekts gab es viele Diskussionen: Welchen Ansatz wählen Sie? Wie baue ich unser neues RBS-System? Alles begann mit Diskussionen „Monolith vs Microservices“: Erörterte mögliche Programmiersprachen, diskutierte über Frameworks („Soll ich Spring Cloud verwenden?“, „Welches Protokoll sollte ich für die Kommunikation zwischen Microservices wählen?“). Diese Fragen haben in der Regel nur eine begrenzte Anzahl von Antworten, und wir wählen einfach bestimmte Ansätze und Technologien aus, die von den Anforderungen und Fähigkeiten abhängen. Und die Antwort auf die Frage "Wie schreibe ich Microservices selbst?" war nicht ganz einfach.
Viele könnten sagen: „Warum ein allgemeines Architekturkonzept für den Microservice selbst entwickeln? Es gibt eine Unternehmensarchitektur und eine Projektarchitektur sowie einen allgemeinen Entwicklungsvektor. Wenn Sie dem Team eine Aufgabe zuweisen, wird diese abgeschlossen, der Microservice wird geschrieben und die Aufgaben werden ausgeführt. Dies ist schließlich die Essenz von Microservices - Unabhängigkeit. " Und sie werden absolut richtig sein! Mit der Zeit werden die Teams jedoch größer, daher wächst die Anzahl der Microservices und Mitarbeiter, und es gibt weniger Oldtimer. Es kommen neue Entwickler, die in das Projekt eintauchen müssen, einige Entwickler wechseln das Team. Außerdem existieren Teams im Laufe der Zeit nicht mehr, aber ihre Microservices leben weiter und in einigen Fällen müssen sie verbessert werden.
Während wir das allgemeine Konzept der Microservice-Architektur entwickeln, lassen wir uns eine große Reserve für die Zukunft:
- ;
- ;
- : .
Jeder, der mit Microservices arbeitet, ist sich seiner Vor- und Nachteile bewusst. Eine davon ist die Möglichkeit, eine alte Implementierung schnell durch eine neue zu ersetzen. Aber wie klein muss ein Microservice sein, damit er leicht ausgetauscht werden kann? Wo ist die Grenze, die die Größe des Mikrodienstes bestimmt? Wie man keinen Mini-Monolithen oder Nanservice macht? Und Sie können jederzeit direkt zur Seite von Funktionen gehen, die einen kleinen Teil der Logik ausführen und Geschäftsprozesse erstellen, indem Sie die Reihenfolge für den Aufruf solcher Funktionen
festlegen Rubelzahlungen) und bauen die Microservices selbst gemäß den Aufgaben dieser Domäne auf.
Betrachten wir ein Beispiel für einen Standardgeschäftsprozess für jede Bank - "Erstellen eines Zahlungsauftrags".

Sie können sehen, dass eine scheinbar einfache Clientanforderung eine ziemlich große Anzahl von Vorgängen ist. Dieses Szenario ist ungefähr, einige Phasen sind der Einfachheit halber weggelassen, einige Phasen treten auf der Ebene der Infrastrukturkomponenten auf und erreichen nicht die Hauptgeschäftslogik im Produktservice, der andere Teil der Vorgänge arbeitet asynchron. Das Fazit ist, dass wir einen Prozess haben, der zu einem bestimmten Zeitpunkt viele benachbarte Dienste nutzen, die Funktionalität verschiedener Bibliotheken nutzen, eine Art Logik in sich selbst implementieren und Daten in verschiedenen Speichern speichern kann.
Bei näherer Betrachtung können Sie feststellen, dass der Geschäftsprozess ziemlich linear ist und im Verlauf seiner Arbeit entweder irgendwo Daten abrufen oder die vorhandenen Daten irgendwie verarbeiten muss. Dies erfordert möglicherweise die Arbeit mit externen Datenquellen ( Microservices, Datenbanken) oder Logik (Bibliotheken).

Einige Mikrodienste passen nicht zu diesem Konzept, aber die Anzahl solcher Mikrodienste im Gesamtprozentsatz ist gering und beträgt etwa 5%.
Saubere Architektur
Nachdem wir uns verschiedene Ansätze zum Organisieren von Code angesehen hatten, entschieden wir uns für einen Ansatz mit „sauberer Architektur“, indem wir den Code in unseren Microservices als Ebenen organisierten.
In Bezug auf die "saubere Architektur" selbst wurde mehr als ein Buch geschrieben, es gibt viele Artikel sowohl im Internet als auch über Habré ( Artikel 1 , Artikel 2 ), mehr als einmal wurden die Vor- und Nachteile besprochen.
Ein beliebtes Diagramm zu diesem Thema wurde von Bob Martin in seinem Buch Clean Architecture gezeichnet:

Hier zeigt das Kreisdiagramm links in der Mitte die Richtung der Abhängigkeiten zwischen Ebenen, und in der rechten Ecke sehen Sie bescheiden das Richtung des Ausführungsflusses.
Dieser Ansatz hat, wie in jeder Programmiertechnologie, Vor- und Nachteile. Für uns gibt es bei diesem Ansatz jedoch viel mehr positive als negative Aspekte.
Implementierung einer "sauberen Architektur" im Projekt
Wir haben dieses Diagramm basierend auf unserem Szenario neu gezeichnet.
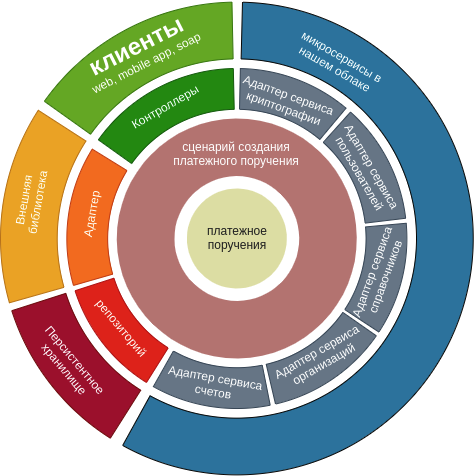
Natürlich spiegelt dieses Diagramm ein Szenario wider. Es kommt häufig vor, dass ein Microservice mehr Vorgänge für eine Domänenentität ausführt, aber fairerweise können viele Adapter wiederverwendet werden.
Es gibt verschiedene Ansätze, um den Microservice in Ebenen zu unterteilen. Wir haben uns jedoch für die Aufteilung in Module auf der Ebene des Projekt-Builders entschieden. Die Implementierung auf Modulebene erleichtert die visuelle Wahrnehmung des Projekts und bietet einen weiteren Schutz für Projekte vor Missbrauch des Architekturstils.
Aus Erfahrung haben wir festgestellt, dass sich ein neuer Entwickler beim Eintauchen in ein Projekt nur mit dem theoretischen Teil vertraut machen muss und fast jeden Mikroservice einfach und schnell navigieren kann.
Wir verwenden Gradle, um unsere Microservices in Java zu erstellen, sodass die Hauptschichten als eine Reihe ihrer Module gebildet werden:

Jetzt besteht unser Projekt aus Modulen, die Verträge entweder implementieren oder verwenden. Damit diese Module funktionieren und Probleme lösen können, müssen wir die Abhängigkeitsinjektion implementieren und einen Einstiegspunkt erstellen, der unsere gesamte Anwendung startet. Und hier gibt es eine interessante Frage in dem Buch Onkel Bob "Reine Architektur". Es gibt ganze Kapitel, die uns über die Details, Modelle und Frameworks berichten, aber wir bauen ihre Architektur nicht um das Framework oder um die Datenbank herum auf, wir verwenden sie als Eine der Komponenten ...
Wenn wir die Entität speichern müssen, verweisen wir beispielsweise auf die Datenbank. Damit unser Skript die Vertragsimplementierungen erhält, die es zum Zeitpunkt der Ausführung benötigt, verwenden wir das Framework, das unsere Architektur DI.
Es gibt Aufgaben, bei denen wir einen Mikroservice ohne Datenbank implementieren müssen, oder wir können DI aufgeben, weil die Aufgabe zu einfach ist und sie schneller direkt gelöst werden kann. Und wenn wir die gesamte Arbeit mit der Datenbank im "Repository" -Modul ausführen, wo verwenden wir dann das Framework, um den gesamten DI für uns vorzubereiten? Es gibt nicht so viele Optionen: Entweder fügen wir jedem Modul unserer Anwendung eine Abhängigkeit hinzu, oder wir versuchen, den gesamten DI als separates Modul auszuwählen.
Wir haben einen separaten neuen Modulansatz gewählt und ihn entweder "Infrastruktur" oder "Anwendung" genannt.
Richtig, wenn ein solches Modul eingeführt wird, wird das Prinzip leicht verletzt, wonach wir alle Abhängigkeiten zum Zentrum auf die Domänenschicht lenken, da Es muss Zugriff auf alle Klassen in der Anwendung haben.
Es wird nicht funktionieren, unserer Zwiebel eine Infrastrukturschicht in Form einer Schicht hinzuzufügen, es gibt dort einfach keinen Platz dafür, aber hier können Sie alles aus einem anderen Blickwinkel betrachten, und es stellt sich heraus, dass wir einen Kreis haben. “ Infrastruktur “und unsere Puffzwiebel ist drauf ... Versuchen wir zur Verdeutlichung, die Ebenen ein wenig auseinander zu verschieben, um sie besser sichtbar zu machen:

Fügen Sie ein neues Modul hinzu und sehen Sie sich den Abhängigkeitsbaum auf der Infrastrukturebene an, um die endgültigen Abhängigkeiten zwischen den Modulen zu sehen:

Jetzt müssen Sie nur noch die hinzufügen DI-Framework selbst. Wir verwenden Spring in unserem Projekt, dies ist jedoch nicht erforderlich. Sie können jedes Framework verwenden, das DI implementiert (z. B. Mikronaut).
Wie man einen Microservice erstellt und wo welcher Teil des Codes sein wird - wir haben uns bereits entschieden, und es lohnt sich, das Geschäftsszenario noch einmal zu betrachten, weil Es gibt noch einen weiteren interessanten Punkt.
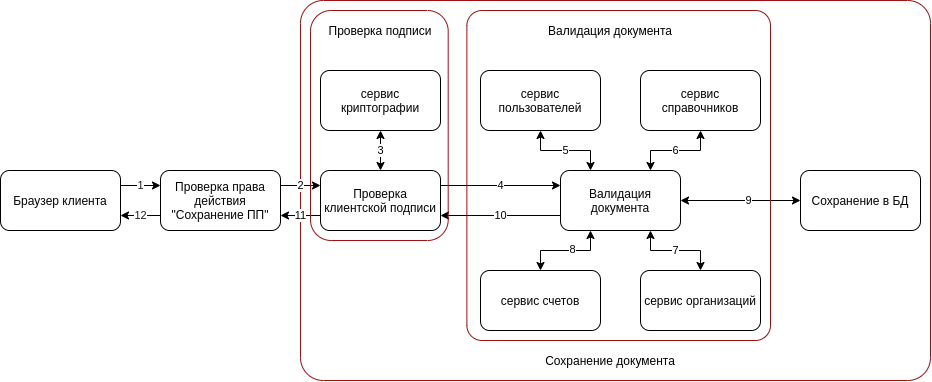
Das Diagramm zeigt, dass die Überprüfung des Aktionsrechts im Hauptskript möglicherweise nicht durchgeführt wird. Dies ist eine separate Aufgabe, die nicht davon abhängt, was als nächstes passiert. Die Signaturüberprüfung könnte in einen separaten Microservice verschoben werden. Hier gibt es jedoch viele Widersprüche bei der Definition der Microservice-Grenze, und wir haben beschlossen, unserer Architektur einfach eine weitere Ebene hinzuzufügen.
In separaten Ebenen müssen die Phasen hervorgehoben werden, die in unserer Anwendung wiederholt werden können, z. B. die Überprüfung der Signatur. Dieser Vorgang kann beim Erstellen, Ändern oder Signieren eines Dokuments auftreten. Viele Hauptskripte starten zuerst die kleineren Operationen und dann nur das Hauptskript. Daher ist es für uns einfacher, kleinere Vorgänge in kleine Skripte zu isolieren, die in Ebenen unterteilt sind, damit sie bequemer wiederverwendet werden können.
Dieser Ansatz erleichtert das Verständnis der Geschäftslogik, und im Laufe der Zeit wird eine Reihe von Bausteinen für kleine Unternehmen gebildet, die wiederverwendet werden können.
Über den Code von Adaptern, Controllern und Repositorys gibt es nicht viel zu sagen. Sie sind ganz einfach. Adapter für einen anderen Microservice verwenden einen generierten Client aus einem Swagger, einem Spring RestTemplate oder einem Grpc-Client. In Repositorys - eine der Varianten der Verwendung von Hibernate oder anderen ORMs. Die Controller gehorchen der Bibliothek, die Sie verwenden werden.
Fazit
In diesem Artikel wollten wir zeigen, warum wir eine Microservice-Architektur erstellen, welche Ansätze wir verwenden und wie wir uns entwickeln. Unser Projekt ist jung und steht erst am Anfang seiner Reise, aber bereits jetzt können wir die Hauptpunkte seiner Entwicklung unter dem Gesichtspunkt der Architektur des Mikrodienstes selbst hervorheben.
Wir bauen Mikrodienste mit mehreren Modulen, wobei die Vorteile Folgendes umfassen:
- , - , , - , ;
- , , - ;
- , Api, , , , ;
- , , , , .
Nicht ohne natürlich eine Fliege in der Salbe. Am offensichtlichsten ist beispielsweise, dass jedes Modul häufig mit seinen eigenen kleinen Modellen arbeitet. Im Controller haben Sie beispielsweise eine Beschreibung der übrigen Modelle, und im Repository befinden sich Datenbankentitäten. In diesem Zusammenhang müssen Sie Objekte häufig miteinander abbilden, aber mit Tools wie „mapstruct“ können Sie dies schnell und zuverlässig tun.
Zu den Nachteilen gehört auch die Tatsache, dass Sie andere Entwickler ständig überwachen müssen, da die Versuchung besteht, weniger Arbeit zu erledigen, als es kostet. Wenn Sie beispielsweise das Framework etwas weiter als ein Modul verschieben, führt dies zu einer Erosion der Verantwortung dieses Frameworks in der gesamten Architektur, was sich in Zukunft negativ auf die Geschwindigkeit der Verbesserungen auswirken kann.
Dieser Ansatz zur Implementierung von Microservices eignet sich für Projekte mit langer Lebensdauer und Projekte mit komplexem Verhalten. Da die Implementierung der gesamten Infrastruktur Zeit braucht, zahlt sie sich in Zukunft mit Stabilität und schnellen Verbesserungen aus.