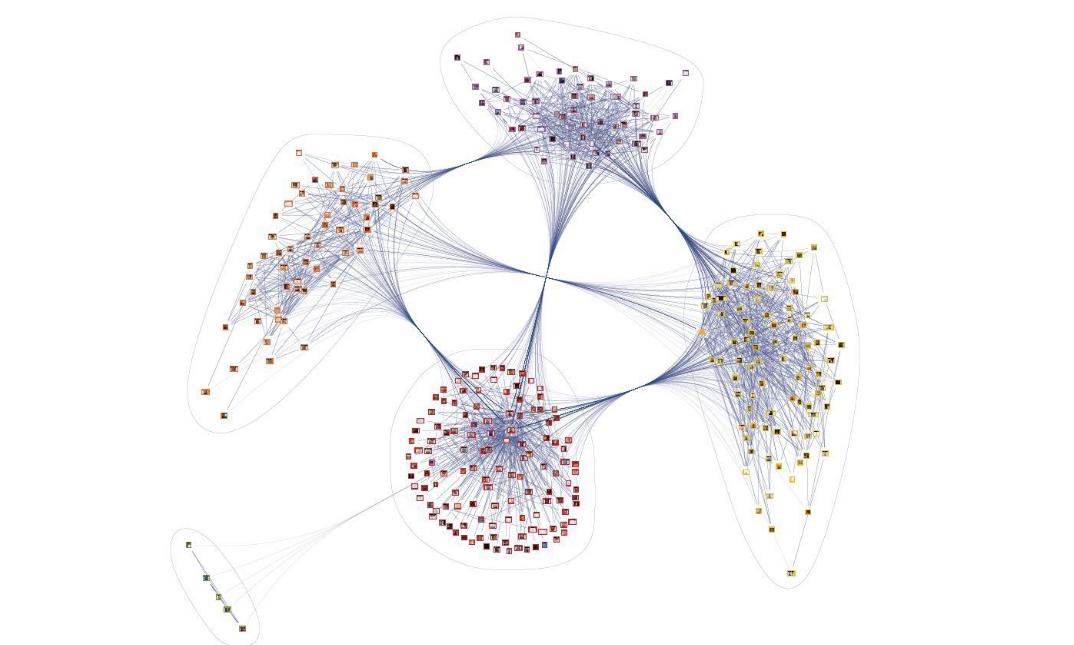
Anhand eines einfachen Beispiels werden wir heute überlegen, wie ein kurzer Überblick über unstrukturierte Daten in Form eines Wissensdiagramms erstellt werden kann.
Nehmen wir zum Beispiel eine Reihe von Texten aus Anfragen aus dem mos.ru- Portal . In diesem Fall besteht das Set aus 90.000 Treffern. Die mittlere Anruflänge beträgt 9 Wörter. Im Allgemeinen können die Texte in drei Hauptthemen unterteilt werden: Umweltqualität; die Qualität der städtischen Umwelt; Anteil der Straßenumgebung, der den Vorschriften entspricht.
Importieren wir zunächst die erforderlichen Bibliotheken:
import pandas as pd
from tqdm import tqdm
import stanza
from nltk.tokenize import word_tokenize, sent_tokenize
Stanza NLP , , , , . nltk . Stanza , , .
, :
df = pd.read_excel('fill_info.xlsx')
df_ml = df[df["CATEGORY"]=="Machine Learning"]
:
full_corpus = df_ml["TEXT"].values
sentences = [sent for corp in full_corpus for sent in sent_tokenize(corp, language="russian")]
long_sents = [i for i in sentences if len(i) > 30]
stanza Pipeline:
nlp = stanza.Pipeline(lang='ru', processors='tokenize,pos,lemma,ner,depparse')
, 5 , .. («depparse») 4 («tokenize, pos, lemma, ner») . , , 2 («tokenize, ner»), . , Stanza – - , 90 . . , Stanza CUDA. , 3000 CPU 26 , 3 . GPU CUDA, Pipeline «Use devise: gpu». , .
(Subject – relation - Object) - triplet, . 6 (nsubj, nsubj:pass, obj, obl, nmod, nummod). , . .
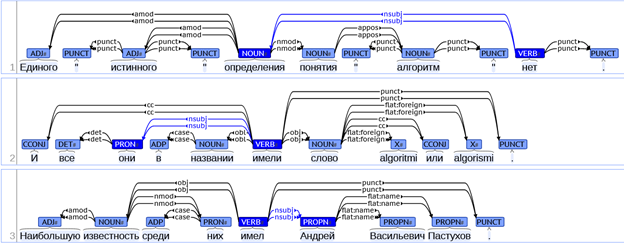
, Subject Object , relation – . 3- , Subject – «», relation – «» Object – «». , «» Subject Object .
:
triplets = []
for s in tqdm(long_sents):
doc = nlp(s)
for sent in doc.sentences:
entities = [ent.text for ent in sent.ents]
, «Subject – relation – Object» (). (doc), . entities.
res_d = dict()
temp_d = dict()
for word in sent.words:
temp_d[word.text] = {"head": sent.words[word.head-1].text, "dep": word.deprel, "id": word.id}
temp_d , (head), (dep), :
{"": {"head": "", "dep": "nsubj"}, .....}
res_d, .
for k in temp_d.keys():
nmod_1 = ""
nmod_2 = ""
if (temp_d[k]["dep"] in ["nsubj", "nsubj:pass"]) & (k in entities):
res_d[k] = {"head": temp_d[k]["head"]}
temp_d, «nsubj» «nsubj:pass», , . res_d , - (head) . (nmod_1 nmod_2).
for k_0 in temp_d.keys():
if (temp_d[k_0]["dep"] in ["obj", "obl"]) &\
(temp_d[k_0]["head"] == res_d[k]["head"]) &\
(temp_d[k_0]["id"] > temp_d[res_d[k]["head"]]["id"]):
res_d[k]["obj"] = k_0
break
Subject relation, Object. temp_d, relation, obj obl. , Object relation, .. . :
{"": {'head': , 'obj': ""}}
, .. «», :
for k_1 in temp_d.keys():
if (temp_d[k_1]["head"] == res_d[k]["head"]) & (k_1 == ""):
res_d[k]["head"] = " "+res_d[k]["head"]
. : « .»
: {"": {"head": "", "obj": ""}}. , . «» . Object:
if "obj" in res_d[k].keys():
for k_4 in temp_d.keys():
if (temp_d[k_4]["dep"] =="nmod") &\
(temp_d[k_4]["head"] == res_d[k]["obj"]):
nmod_1 = k_4
break
for k_5 in temp_d.keys():
if (temp_d[k_5]["dep"] =="nummod") &\
(temp_d[k_5]["head"] == nmod_1):
nmod_2 = k_5
break
res_d[k]["obj"] = res_d[k]["obj"]+" "+nmod_2+" "+nmod_1
, Object, nmod. , , nummod nmod_1. , : {"": {"head": "", "obj": " "}}, . , Stanza «» .
.)))
%%time
triplets = []
for s in tqdm(long_sents):
doc = nlp(s)
for sent in doc.sentences:
entities = [ent.text for ent in sent.ents]
res_d = dict()
temp_d = dict()
for word in sent.words:
temp_d[word.text] = {"head": sent.words[word.head-1].text, "dep": word.deprel, "id": word.id}
for k in temp_d.keys():
nmod_1 = ""
nmod_2 = ""
if (temp_d[k]["dep"] in ["nsubj", "nsubj:pass"]) & (k in entities):
res_d[k] = {"head": temp_d[k]["head"]}
for k_0 in temp_d.keys():
if (temp_d[k_0]["dep"] in ["obj", "obl"]) &\
(temp_d[k_0]["head"] == res_d[k]["head"]) &\
(temp_d[k_0]["id"] > temp_d[res_d[k]["head"]]["id"]):
res_d[k]["obj"] = k_0
break
for k_1 in temp_d.keys():
if (temp_d[k_1]["head"] == res_d[k]["head"]) & (k_1 == ""):
res_d[k]["head"] = " "+res_d[k]["head"]
if "obj" in res_d[k].keys():
for k_4 in temp_d.keys():
if (temp_d[k_4]["dep"] =="nmod") &\
(temp_d[k_4]["head"] == res_d[k]["obj"]):
nmod_1 = k_4
break
for k_5 in temp_d.keys():
if (temp_d[k_5]["dep"] =="nummod") &\
(temp_d[k_5]["head"] == nmod_1):
nmod_2 = k_5
break
res_d[k]["obj"] = res_d[k]["obj"]+" "+nmod_2+" "+nmod_1
if len(res_d) > 0:
triplets.append([s, res_d])
. , . , Object:
clear_triplets = []
for tr in triplets:
for k in tr[1].keys():
if "obj" in tr[1][k].keys():
clear_triplets.append([tr[0], k, tr[1][k]['head'], tr[1][k]['obj']])
, , .
[[' .', '', '', ' '], ……]
. , NetworkX, Graphviz, Gephi .
Vis.js, .. . Vis.js, , . , notebook. , , .
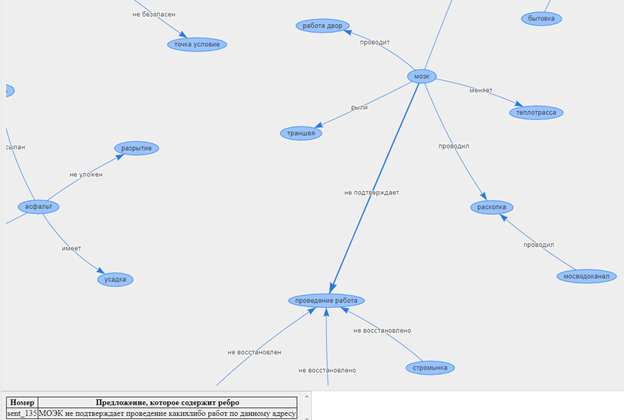
Auf diese Weise können wir die Textdaten analysieren und den Hauptinhalt von Beschwerden und Dankbarkeit ermitteln sowie die Beziehung zwischen verschiedenen Einsprüchen ermitteln.