Einführung
Meine Hauptaufgabe ist die mobile Werbung, und von Zeit zu Zeit muss ich mit Daten über mobile Anwendungen arbeiten. Ich habe beschlossen, einige der Daten für diejenigen öffentlich zugänglich zu machen, die das Erstellen von Modellen üben oder sich ein Bild von den Daten machen möchten, die aus offenen Quellen gesammelt werden können. Ich glaube, dass offene Datensätze für die Community immer nützlich sind. Das Sammeln von Daten ist oft schwierig und langweilig, und nicht jeder hat die Möglichkeit, dies zu tun. In diesem Artikel werde ich einen Datensatz vorstellen und daraus ein Modell erstellen.
Daten
Der Datensatz wird auf der Kaggle- Website veröffentlicht .
DOI: 10.34740/KAGGLE/DSV/2107675.
Für 293.392 Anwendungen (die beliebtesten) werden Beschreibungstoken und Anwendungsdaten selbst, einschließlich der ursprünglichen Beschreibung, gesammelt. Der Datensatz enthält keine Anwendungsnamen. Sie werden durch eindeutige Kennungen identifiziert. Vor der Tokenisierung wurden die meisten Beschreibungen ins Englische übersetzt.
Der Datensatz enthält 4 Dateien:
bundles_desc.csv - enthält nur Beschreibungen;
bundles_desc_tokens.csv - enthält Token und Genres;
bundles_prop.csv, bundles_summary.csv - enthält verschiedene Anwendungseigenschaften und Veröffentlichungs- / Aktualisierungsdaten.
EDA
Schauen wir uns zunächst an, wie Daten auf Betriebssysteme verteilt sind.

Android-Apps dominieren Daten. Dies ist höchstwahrscheinlich auf die Tatsache zurückzuführen, dass mehr Android-Apps erstellt werden.
, , , .
histnorm ='probability' # type of normalization

, .

2021 .

- .
df['bundle_update_period'] = \
(pd.to_datetime(
df['bundle_updated_at'], utc=True).dt.tz_convert(None).dt.to_period('M').astype('int') -
df['bundle_released_at'].dt.to_period('M').astype('int'))

, . , .
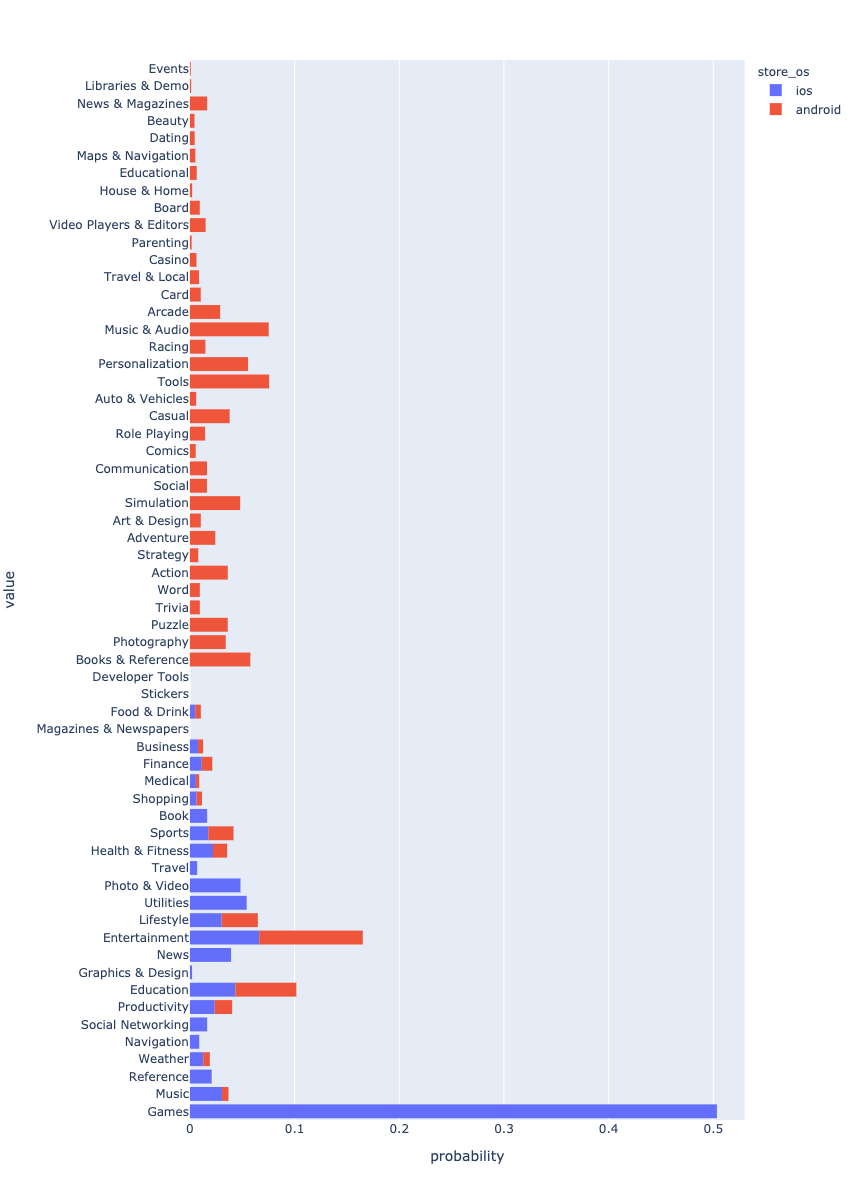
, . . . ? - Android , iOS Games. , , . . , .
, .
def get_lengths(df, columns=['tokens', 'description']):
lengths_df = pd.DataFrame()
for i, c in enumerate(columns):
lengths_df[f"{c}_len"] = df[c].apply(len)
if i > 0:
lengths_df[f"{c}_div"] = \
lengths_df.iloc[:, i-1] / lengths_df.iloc[:, i]
lengths_df[f"{c}_diff"] = \
lengths_df.iloc[:, i-1] - lengths_df.iloc[:, i]
return lengths_df
df = pd.concat([df, get_lengths(df)], axis=1, sort=False, copy=False)
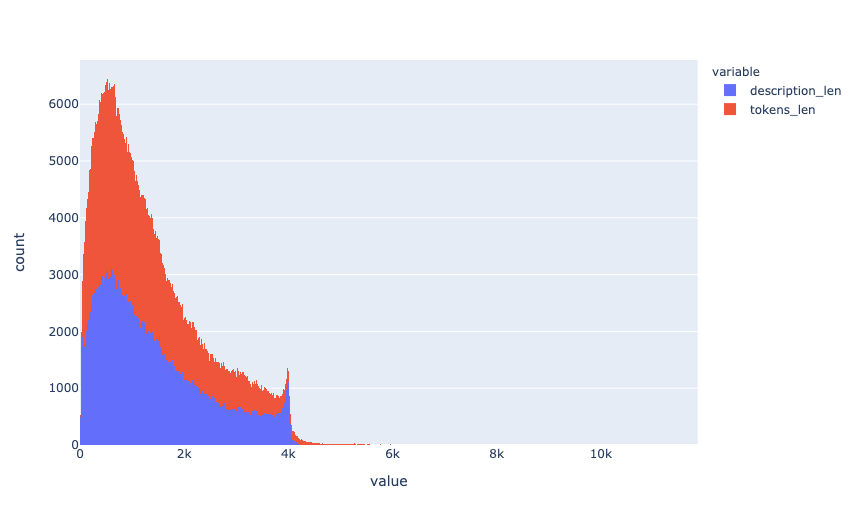
, . , - .

Android-.
android_df = df[df['store_os']=='android']
ios_df = df[df['store_os']=='ios']
:
columns = [
'genre', 'tokens', 'bundle_update_period', 'tokens_len',
'description_len', 'description_div', 'description_diff',
'description', 'rating', 'reviews', 'score',
'released_at_month'
]
- train validation. , .
train_df, test_df = train_test_split(
android_df[columns], train_size=0.7, random_state=0, stratify=android_df['genre'])
y_train, X_train = train_df['genre'], train_df.drop(['genre'], axis=1)
y_test, X_test = test_df['genre'], test_df.drop(['genre'], axis=1)
CatBoost. CatBoost - . , CatBoost . 0.19.1
: BERT vs CatBoost , CatBoost BERT.
!pip install -U catboost
CatBoost Pool. , , . , .
train_pool = Pool(
data=X_train,
label=y_train,
text_features=['tokens', 'description']
)
test_pool = Pool(
data=X_test,
label=y_test,
text_features=['tokens', 'description']
)
. ; .
def fit_model(train_pool, test_pool, **kwargs):
model = CatBoostClassifier(
random_seed=0,
task_type='GPU',
iterations=10000,
learning_rate=0.1,
eval_metric='Accuracy',
od_type='Iter',
od_wait=500,
**kwargs
)
return model.fit(
train_pool,
eval_set=test_pool,
verbose=1000,
plot=True,
use_best_model=True
)
. CatBoost, .
CatBoostClassifier :
tokenizers — ;
dictionaries — ;
feature_calcers — ;
text_processing — JSON- , , , .
, , , , .
tpo = {
'tokenizers': [
{
'tokenizer_id': 'Sense',
'separator_type': 'BySense',
}
],
'dictionaries': [
{
'dictionary_id': 'Word',
'token_level_type': 'Word',
'occurrence_lower_bound': '10'
},
{
'dictionary_id': 'Bigram',
'token_level_type': 'Word',
'gram_order': '2',
'occurrence_lower_bound': '10'
},
{
'dictionary_id': 'Trigram',
'token_level_type': 'Word',
'gram_order': '3',
'occurrence_lower_bound': '10'
},
],
'feature_processing': {
'0': [
{
'tokenizers_names': ['Sense'],
'dictionaries_names': ['Word'],
'feature_calcers': ['BoW']
},
{
'tokenizers_names': ['Sense'],
'dictionaries_names': ['Bigram', 'Trigram'],
'feature_calcers': ['BoW']
},
],
'1': [
{
'tokenizers_names': ['Sense'],
'dictionaries_names': ['Word'],
'feature_calcers': ['BoW', 'BM25']
},
{
'tokenizers_names': ['Sense'],
'dictionaries_names': ['Bigram', 'Trigram'],
'feature_calcers': ['BoW']
},
]
}
}
:
model_catboost = fit_model( train_pool, test_pool, text_processing = tpo )


bestTest = 0.6454657601
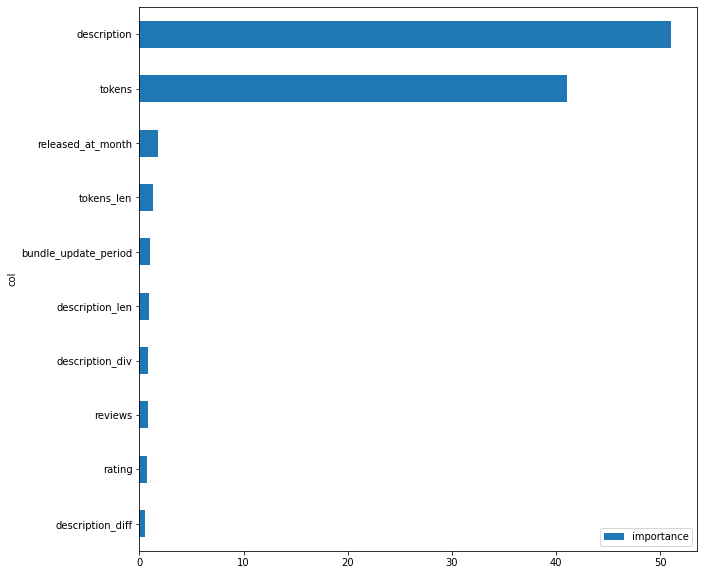
. , summary, , iOS, . , . .
, . , , . , . , .
, , OOF (Out-of-Fold). ; .
def get_oof(n_folds, x_train, y, x_test, text_features, seeds):
ntrain = x_train.shape[0]
ntest = x_test.shape[0]
oof_train = np.zeros((len(seeds), ntrain, 48))
oof_test = np.zeros((ntest, 48))
oof_test_skf = np.empty((len(seeds), n_folds, ntest, 48))
test_pool = Pool(data=x_test, text_features=text_features)
models = {}
for iseed, seed in enumerate(seeds):
kf = StratifiedKFold(
n_splits=n_folds,
shuffle=True,
random_state=seed)
for i, (tr_i, t_i) in enumerate(kf.split(x_train, y)):
print(f'\nSeed {seed}, Fold {i}')
x_tr = x_train.iloc[tr_i, :]
y_tr = y[tr_i]
x_te = x_train.iloc[t_i, :]
y_te = y[t_i]
train_pool = Pool(
data=x_tr, label=y_tr, text_features=text_features)
valid_pool = Pool(
data=x_te, label=y_te, text_features=text_features)
model = fit_model(
train_pool, valid_pool,
random_seed=seed,
text_processing = tpo
)
x_te_pool = Pool(
data=x_te, text_features=text_features)
oof_train[iseed, t_i, :] = \
model.predict_proba(x_te_pool)
oof_test_skf[iseed, i, :, :] = \
model.predict_proba(test_pool)
models[(seed, i)] = model
oof_test[:, :] = oof_test_skf.mean(axis=1).mean(axis=0)
oof_train = oof_train.mean(axis=0)
return oof_train, oof_test, models
, :
oof_train — OOF- Android
oof_test — OOF- iOS
models — all OOF-
from sklearn.metrics import accuracy_score
accuracy_score(
android_df['genre'].values,
np.take(models[(0,0)].classes_, oof_train.argmax(axis=1)))
.
OOF accuracy: 0.6560790777135628
android_genre_vec, oof_train Android oof_test iOS.
idx = df[df['store_os']=='ios'].index
df.loc[df['store_os']=='ios', 'android_genre_vec'] = \
pd.Series(list(oof_test), index=idx)
idx = df[df['store_os']=='android'].index
df.loc[df['store_os']=='android', 'android_genre_vec'] = \
pd.Series(list(oof_train), index=idx)
android_genre, .
df.loc[df['store_os']=='ios', 'android_genre'] = \
np.take(models[(0,0)].classes_, oof_test.argmax(axis=1))
df.loc[df['store_os']=='android', 'android_genre'] = \
np.take(models[(0,0)].classes_, oof_train.argmax(axis=1))
Nach all den Manipulationen können Sie endlich die Verteilung der Anwendungen nach Genre sehen und vergleichen.
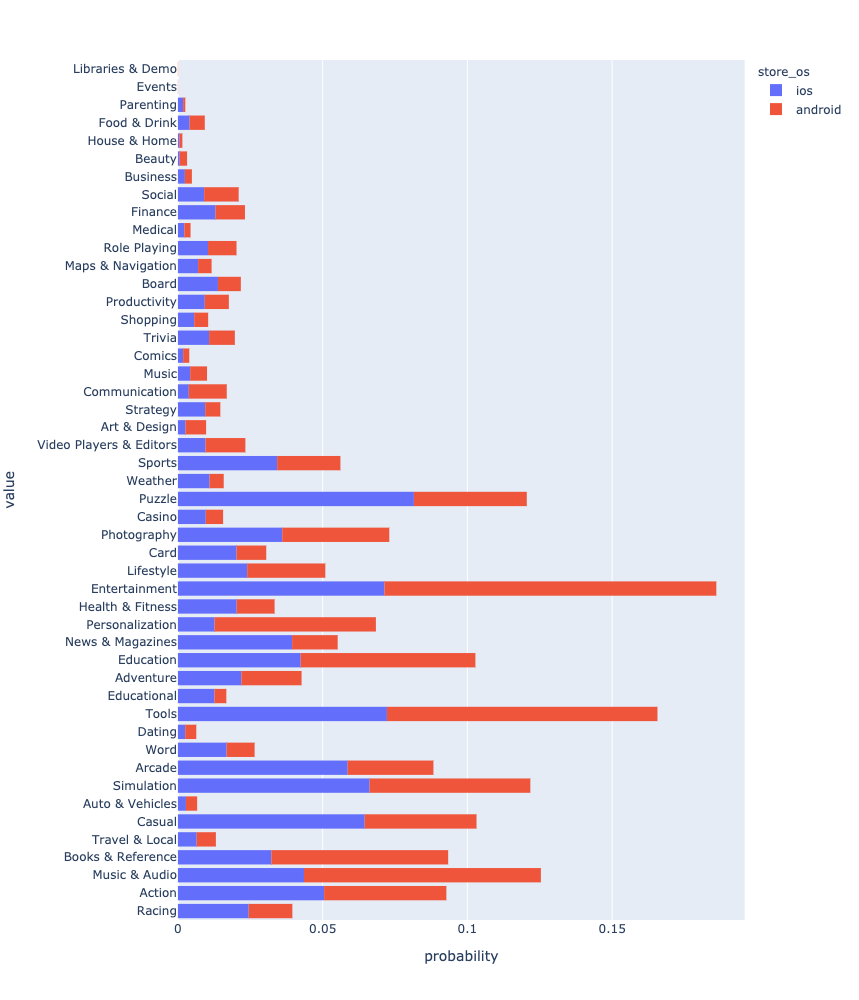
Ergebnisse
Im Artikel:
neuer kostenloser Datensatz eingeführt;
machte eine kleine EDA;
Es wurden mehrere neue Funktionen erstellt.
Es wurde ein Modell erstellt, um die Genres von Anwendungen anhand von Beschreibungen vorherzusagen.
Ich hoffe, dieser Datensatz wird für die Community nützlich sein und sowohl in Modellen als auch für weitere Studien verwendet werden. Ich werde versuchen, es so weit wie möglich zu aktualisieren.
Der Code aus dem Artikel kann hier eingesehen werden .