
Kürzlich wurde der Hauptzeile des Clang-Compilers eine großartige Funktion hinzugefügt . Mit den Attributen
[[clang::musttail]]
oder können
__attribute__((musttail))
Sie jetzt garantierte Endaufrufe in C, C ++ und Objective-C erhalten.
int g(int);
int f(int x) {
__attribute__((musttail)) return g(x);
}
( Online-Compiler )
Normalerweise sind diese Aufrufe mit funktionaler Programmierung verbunden, aber ich bin nur unter Leistungsgesichtspunkten an ihnen interessiert. In einigen Fällen können Sie mit ihrer Hilfe - zumindest mit den verfügbaren Kompilierungstechnologien - besseren Code vom Compiler erhalten, ohne auf einen Assembler zurückgreifen zu müssen.
Die Verwendung dieses Ansatzes beim Parsen des Serialisierungsprotokolls ergab erstaunliche Ergebnisse: Wir konnten mit Geschwindigkeiten von mehr als 2 Gbit / s analysieren. , mehr als doppelt so schnell wie die bisher beste Lösung. Diese Beschleunigung ist in vielen Situationen nützlich, daher wäre es falsch, sich nur auf die Anweisung "Schwanzaufrufe == doppelte Beschleunigung" zu beschränken. Diese Herausforderungen sind jedoch ein Schlüsselelement, das solche Geschwindigkeitsgewinne ermöglicht hat.
Ich werde Ihnen sagen, welche Vorteile Tail Calls haben, wie wir das Protokoll mit ihnen analysieren und wie wir diese Technik auf Dolmetscher ausweiten können. Ich denke, dass dank ihm Dolmetscher aller in C geschriebenen Hauptsprachen (Python, Ruby, PHP, Lua usw.) erhebliche Leistungssteigerungen erzielen können. Der Hauptnachteil hängt mit der Portabilität zusammen: Heute handelt es sich
musttail
um eine nicht standardmäßige Compiler-Erweiterung. Ich hoffe, dass es sich durchsetzen wird, aber es wird einige Zeit dauern, bis sich die Erweiterung so weit verbreitet, dass der C-Compiler auf Ihrem System sie unterstützt. Beim Bauen können Sie die Effizienz im Austausch für die Portabilität opfern, wenn sich herausstellt, dass sie
musttail
nicht verfügbar ist.
Tail Call-Grundlagen
Ein Tail-Aufruf ist ein Aufruf einer Funktion in der Tail-Position, der letzten Aktion, bevor die Funktion ein Ergebnis zurückgibt. Bei der Optimierung von Tail-Aufrufen kompiliert der Compiler die Anweisung für den Tail-Aufruf
jmp
, nicht
call
. Dadurch werden keine Overhead-Aktionen ausgeführt, die es dem Angerufenen normalerweise ermöglichen würden,
g()
zum Aufrufer zurückzukehren
f()
, z. B. das Erstellen eines neuen Stapelrahmens oder das Übergeben einer Rücksprungadresse. Stattdessen
f()
verweist es direkt darauf
g()
, als wäre es ein Teil von sich selbst, und
g()
gibt das Ergebnis direkt an den Aufrufer zurück
f()
. Diese Optimierung ist sicher, weil der Stapelrahmen
f()
wird nach dem Start des Tail-Aufrufs nicht mehr benötigt, da es unmöglich wurde, auf eine lokale Variable zuzugreifen
f()
.
Auch wenn es trivial aussieht, bietet diese Optimierung zwei wichtige Funktionen, die neue Möglichkeiten für das Schreiben von Algorithmen eröffnen. Erstens wird durch Ausführen von n aufeinanderfolgenden Endaufrufen der Speicherstapel von O (n) auf O (1) reduziert. Dies ist wichtig, da der Stapel begrenzt ist und ein Überlauf das Programm zum Absturz bringen kann. Ohne diese Optimierung sind einige Algorithmen gefährlich. Zweitens wird
jmp
der Overhead von beseitigt
call
Infolgedessen wird der Funktionsaufruf so effizient wie jeder andere Zweig. Beide Funktionen ermöglichen die Verwendung von Tail-Aufrufen als effiziente Alternative zu herkömmlichen iterativen Steuerungsstrukturen wie
for
und
while
.
Diese Idee ist überhaupt nicht neu und stammt aus dem Jahr 1977, als Guy Steele ein ganzes Papier schrieb , in dem er argumentierte, dass Prozeduraufrufe sauberer sind als Architekturen
GOTO
, während die Optimierung von Tail-Aufrufen nicht an Geschwindigkeit verliert. Es war eines der "Lambda-Werke", die zwischen 1975 und 1980 geschrieben wurden und viele der Ideen formulierten, die hinter Lisp und Scheme stehen.
Die Tail Call-Optimierung ist selbst für Clang nichts Neues. Er konnte sie zuvor optimieren, wie GCC und viele andere Compiler. Tatsächlich
musttail
ändert das Attribut in diesem Beispiel die Ausgabe des Compilers überhaupt nicht: Clang hat die Tail-Aufrufe bereits optimiert
-O2
.
Neu hier ist eine Garantie . Während Compiler häufig erfolgreich Tail Calls optimieren, ist dies die "bestmögliche" Sache, auf die Sie sich nicht verlassen können. Insbesondere die Optimierung wird in nicht optimierten Builds sicherlich nicht funktionieren: dem Online-Compiler . In diesem Beispiel wird der Tail-Aufruf kompiliert
call
, sodass wir uns wieder auf einem Stapel der Größe O (n) befinden. Deshalb brauchen wir
musttail
: Bis wir vom Compiler die Garantie erhalten, dass unsere Tail-Aufrufe immer in allen Assembly-Modi optimiert werden, ist es unsicher, Algorithmen mit solchen Aufrufen zur Iteration zu schreiben. Das Festhalten an Code, der nur mit aktivierten Optimierungen funktioniert, ist eine ziemlich schwierige Einschränkung.
Das Problem mit Interpreter-Schleifen
Compiler sind eine unglaubliche Technologie, aber sie sind nicht perfekt. Mike Pall, der Autor von LuaJIT, entschied sich, den LuaJIT 2.x-Interpreter in Assemblersprache und nicht in C zu schreiben, und er nannte dies den Hauptfaktor, der den Interpreter so schnell machte . Paul erklärte später ausführlicher, warum es C-Compilern schwer fällt, die Hauptinterpreterschleifen zu finden . Zwei Hauptpunkte:
- , .
- , .
Diese Beobachtungen spiegeln gut unsere Erfahrung bei der Optimierung der Analyse des Serialisierungsprotokolls wider. Und Tail Calls helfen uns, beide Probleme zu lösen.
Es ist möglicherweise seltsam, Interpreter-Schleifen mit Parsern des Serialisierungsprotokolls zu vergleichen. Ihre unerwartete Ähnlichkeit wird jedoch durch die Art des Drahtformats des Protokolls bestimmt: Es handelt sich um eine Reihe von Schlüssel-Wert-Paaren, in denen der Schlüssel die Feldnummer und ihren Typ enthält. Der Schlüssel funktioniert wie ein Opcode im Interpreter: Er gibt an, welche Operation ausgeführt werden muss, um dieses Feld zu analysieren. Die Feldnummern im Protokoll können in beliebiger Reihenfolge angegeben werden. Sie müssen also jederzeit bereit sein, zu einem beliebigen Teil des Codes zu springen.
Es wäre logisch, einen solchen Parser mit einer Schleife
while
mit einem verschachtelten Ausdruck zu schreiben
switch
... Dies war der beste Ansatz zum Parsen eines Serialisierungsprotokolls über die Lebensdauer des Protokolls. Hier ist beispielsweise der Parsing-Code aus der aktuellen C ++ - Version . Wenn wir den Kontrollfluss grafisch darstellen, erhalten wir das folgende Schema:
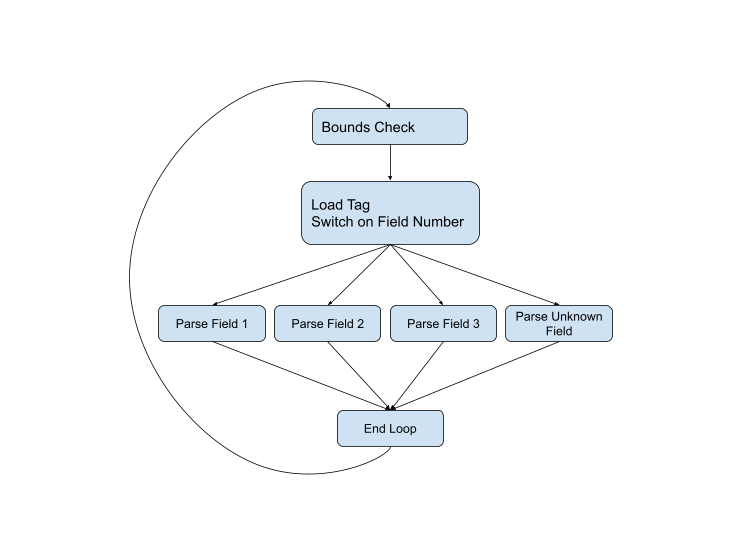
Das Diagramm ist jedoch nicht vollständig, da in fast jeder Phase Probleme auftreten können. Der Feldtyp ist möglicherweise falsch oder die Daten sind möglicherweise beschädigt, oder wir springen einfach zum Ende des aktuellen Puffers. Das vollständige Diagramm sieht folgendermaßen aus:
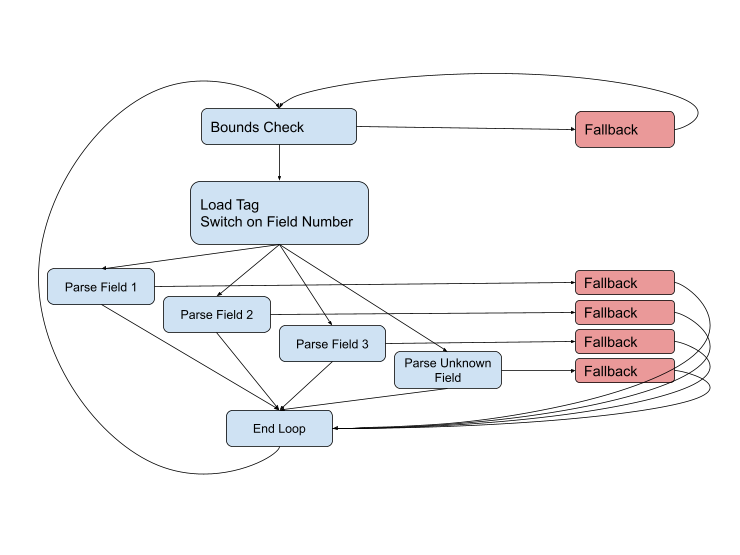
Wir müssen so lange wie möglich auf den schnellen Pfaden (blau) bleiben, aber in einer schwierigen Situation müssen wir mit dem Fallback-Code umgehen. Solche Pfade sind normalerweise länger und komplexer als schnelle Pfade, sie enthalten mehr Daten und verwenden häufig umständliche Aufrufe anderer Funktionen, um noch komplexere Fälle zu behandeln.
Wenn Sie dieses Schema mit dem Profil kombinieren, erhält der Compiler theoretisch alle Informationen, die zum Generieren des optimalsten Codes erforderlich sind. In der Praxis haben wir bei dieser Funktionsgröße und der Anzahl der Verbindungen häufig Probleme mit dem Compiler. Es wirft eine wichtige Variable aus, die wir im Register speichern möchten. Es wendet die Manipulation des Stapelrahmens an, den wir um den Aufruf der Fallback-Funktion wickeln möchten. Es verkettet identische Codepfade, die wir für die Verzweigungsvorhersage getrennt halten möchten. Es sieht alles so aus, als würde man versuchen, mit Fäustlingen Klavier zu spielen.
Verbessern von Interpreter-Schleifen mit Tail-Aufrufen
Die oben beschriebene Argumentation ist größtenteils eine Neuformulierung der Beobachtungen von Paulus über die Hauptzyklen des Dolmetschers . Aber anstatt uns in Assembler zu stürzen, haben wir festgestellt, dass eine maßgeschneiderte Architektur uns die Kontrolle geben kann, die wir brauchen, um aus C nahezu optimalen Code herauszuholen. Daran habe ich mit meinem Kollegen Gerben Stavenga gearbeitet, der den größten Teil der Architektur entworfen hat. Unser Ansatz ähnelt dem wasm3 WebAssembly-Interpreter , der dieses Muster als "Metamaschine" bezeichnet .
Wir haben den Code für unseren 2- Gigabit- Parser in upb eingefügt, eine kleine Protobuf-Bibliothek in C. Sie funktioniert voll und besteht alle Tests zur Einhaltung des Serialisierungsprotokolls, wurde jedoch noch nirgendwo bereitgestellt, und die Architektur wurde in der C ++ - Version des Protokolls nicht implementiert. Aber als die Erweiterung zu Clang kam
musttail
(und upb aktualisiert wurde, um sie zu verwenden ), fiel eines der Haupthindernisse für die vollständige Implementierung unseres schnellen Parsers.
Wir haben uns von einer großen Analysefunktion entfernt und wenden für jede Operation eine eigene kleine Funktion an. Jede Endfunktion ruft die nächste Operation in der Sequenz auf. Hier ist zum Beispiel eine Funktion zum Parsen eines einzelnen Feldes fester Größe (der Code ist im Vergleich zu upb vereinfacht, ich habe viele kleine Details der Architektur entfernt).
Der Code
#include <stdint.h>
#include <stddef.h>
#include <string.h>
typedef void *upb_msg;
struct upb_decstate;
typedef struct upb_decstate upb_decstate;
// The standard set of arguments passed to each parsing function.
// Thanks to x86-64 calling conventions, these will be passed in registers.
#define UPB_PARSE_PARAMS \
upb_decstate *d, const char *ptr, upb_msg *msg, intptr_t table, \
uint64_t hasbits, uint64_t data
#define UPB_PARSE_ARGS d, ptr, msg, table, hasbits, data
#define UNLIKELY(x) __builtin_expect(x, 0)
#define MUSTTAIL __attribute__((musttail))
const char *fallback(UPB_PARSE_PARAMS);
const char *dispatch(UPB_PARSE_PARAMS);
// Code to parse a 4-byte fixed field that uses a 1-byte tag (field 1-15).
const char *upb_pf32_1bt(UPB_PARSE_PARAMS) {
// Decode "data", which contains information about this field.
uint8_t hasbit_index = data >> 24;
size_t ofs = data >> 48;
if (UNLIKELY(data & 0xff)) {
// Wire type mismatch (the dispatch function xor's the expected wire type
// with the actual wire type, so data & 0xff == 0 indicates a match).
MUSTTAIL return fallback(UPB_PARSE_ARGS);
}
ptr += 1; // Advance past tag.
// Store data to message.
hasbits |= 1ull << hasbit_index;
memcpy((char*)msg + ofs, ptr, 4);
ptr += 4; // Advance past data.
// Call dispatch function, which will read the next tag and branch to the
// correct field parser function.
MUSTTAIL return dispatch(UPB_PARSE_ARGS);
}
Für eine so kleine und einfache Funktion generiert Clang Code, der kaum zu übertreffen ist:
upb_pf32_1bt: # @upb_pf32_1bt
mov rax, r9
shr rax, 24
bts r8, rax
test r9b, r9b
jne .LBB0_1
mov r10, r9
shr r10, 48
mov eax, dword ptr [rsi + 1]
mov dword ptr [rdx + r10], eax
add rsi, 5
jmp dispatch # TAILCALL
.LBB0_1:
jmp fallback # TAILCALL
Beachten Sie, dass es keinen Prolog oder Epilog, keine Registerpräferenz und überhaupt keine Stapelverwendung gibt. Die einzigen Exits stammen
jmp
von zwei Tail-Aufrufen, es wird jedoch kein Code zum Übergeben von Parametern benötigt, da sich die Argumente bereits in den richtigen Registern befinden. Vielleicht ist die einzig mögliche Verbesserung, die wir hier sehen, ein bedingter Sprung für einen Endanruf
jne fallback
anstelle
jne
eines nachfolgenden Anrufs
jmp
.
Wenn Sie eine Demontage dieses Codes ohne symbolische Informationen sehen würden, würden Sie nicht erkennen, dass dies die gesamte Funktion ist. Es könnte ebenso gut die Basiseinheit einer größeren Funktion sein. Und genau das tun wir: Wir nehmen die Interpreter-Schleife, eine große und komplexe Funktion, und programmieren sie Block für Block, wobei wir den Kontrollfluss zwischen ihnen über Tail-Aufrufe weiterleiten. Wir haben die vollständige Kontrolle über die Verteilung der Register an der Grenze jedes Blocks (mindestens sechs Register), und da die Funktion einfach genug ist und keine Register vorwegnimmt, haben wir unser Ziel erreicht, den wichtigsten Zustand während des gesamten Fastens zu speichern Pfade.
Wir können jede Anweisungssequenz unabhängig optimieren. Und der Compiler behandelt alle Sequenzen auch unabhängig voneinander, da sie sich in separaten Funktionen befinden (falls erforderlich, können Sie das Inlining mit verhindern
noinline
). Auf diese Weise lösen wir das oben beschriebene Problem, bei dem der Code aus den Fallback-Pfaden die Qualität des Codes der schnellen Pfade verschlechtert. Durch Platzieren der langsamen Pfade in völlig getrennten Funktionen kann die Geschwindigkeitsstabilität der schnellen Pfade gewährleistet werden. Der schöne Assembler bleibt unverändert, er wird von Änderungen in anderen Teilen des Parsers nicht beeinflusst.
Wenn wir dieses Muster auf das Beispiel von Paulus aus LuaJIT anwenden , können wir es grob sagenKorrelieren Sie seinen handgeschriebenen Assembler mit kleinen Verschlechterungen der Codequalität :
#define PARAMS unsigned RA, void *table, unsigned inst, \
int *op_p, double *consts, double *regs
#define ARGS RA, table, inst, op_p, consts, regs
typedef void (*op_func)(PARAMS);
void fallback(PARAMS);
#define UNLIKELY(x) __builtin_expect(x, 0)
#define MUSTTAIL __attribute__((musttail))
void ADDVN(PARAMS) {
op_func *op_table = table;
unsigned RC = inst & 0xff;
unsigned RB = (inst >> 8) & 0xff;
unsigned type;
memcpy(&type, (char*)®s[RB] + 4, 4);
if (UNLIKELY(type > -13)) {
return fallback(ARGS);
}
regs[RA] += consts[RC];
inst = *op_p++;
unsigned op = inst & 0xff;
RA = (inst >> 8) & 0xff;
inst >>= 16;
MUSTTAIL return op_table[op](ARGS);
}
Der resultierende Assembler:
ADDVN: # @ADDVN
movzx eax, dh
cmp dword ptr [r9 + 8*rax + 4], -12
jae .LBB0_1
movzx eax, dl
movsd xmm0, qword ptr [r8 + 8*rax] # xmm0 = mem[0],zero
mov eax, edi
addsd xmm0, qword ptr [r9 + 8*rax]
movsd qword ptr [r9 + 8*rax], xmm0
mov edx, dword ptr [rcx]
add rcx, 4
movzx eax, dl
movzx edi, dh
shr edx, 16
mov rax, qword ptr [rsi + 8*rax]
jmp rax # TAILCALL
.LBB0_1:
jmp fallback
Die einzige Verbesserung, die ich hier neben den oben genannten sehe, ist,
jne fallback
dass der Compiler aus irgendeinem Grund nicht generieren möchte
jmp qword ptr [rsi + 8*rax]
, sondern in ihn lädt
rax
und dann ausführt
jmp rax
. Dies sind kleinere Codierungsprobleme, die Clang hoffentlich bald ohne allzu große Schwierigkeiten beheben wird.
Einschränkungen
Einer der Hauptnachteile dieses Ansatzes besteht darin, dass all diese schönen Assembler-Sequenzen ohne Tail-Calls katastrophal pessimiert werden. Jeder nicht zugeschnittene Aufruf erstellt einen Stapelrahmen und überträgt viele Daten auf den Stapel.
#define PARAMS unsigned RA, void *table, unsigned inst, \
int *op_p, double *consts, double *regs
#define ARGS RA, table, inst, op_p, consts, regs
typedef void (*op_func)(PARAMS);
void fallback(PARAMS);
#define UNLIKELY(x) __builtin_expect(x, 0)
#define MUSTTAIL __attribute__((musttail))
void ADDVN(PARAMS) {
op_func *op_table = table;
unsigned RC = inst & 0xff;
unsigned RB = (inst >> 8) & 0xff;
unsigned type;
memcpy(&type, (char*)®s[RB] + 4, 4);
if (UNLIKELY(type > -13)) {
// When we leave off "return", things get real bad.
fallback(ARGS);
}
regs[RA] += consts[RC];
inst = *op_p++;
unsigned op = inst & 0xff;
RA = (inst >> 8) & 0xff;
inst >>= 16;
MUSTTAIL return op_table[op](ARGS);
}
Plötzlich bekommen wir das
ADDVN: # @ADDVN
push rbp
push r15
push r14
push r13
push r12
push rbx
push rax
mov r15, r9
mov r14, r8
mov rbx, rcx
mov r12, rsi
mov ebp, edi
movzx eax, dh
cmp dword ptr [r9 + 8*rax + 4], -12
jae .LBB0_1
.LBB0_2:
movzx eax, dl
movsd xmm0, qword ptr [r14 + 8*rax] # xmm0 = mem[0],zero
mov eax, ebp
addsd xmm0, qword ptr [r15 + 8*rax]
movsd qword ptr [r15 + 8*rax], xmm0
mov edx, dword ptr [rbx]
add rbx, 4
movzx eax, dl
movzx edi, dh
shr edx, 16
mov rax, qword ptr [r12 + 8*rax]
mov rsi, r12
mov rcx, rbx
mov r8, r14
mov r9, r15
add rsp, 8
pop rbx
pop r12
pop r13
pop r14
pop r15
pop rbp
jmp rax # TAILCALL
.LBB0_1:
mov edi, ebp
mov rsi, r12
mov r13d, edx
mov rcx, rbx
mov r8, r14
mov r9, r15
call fallback
mov edx, r13d
jmp .LBB0_2
Um dies zu vermeiden, haben wir versucht, andere Funktionen nur durch Inlining- oder Tail-Aufrufe aufzurufen. Dies kann mühsam sein, wenn die Operation viele Stellen hat, an denen eine ungewöhnliche Situation auftreten kann, die kein Fehler ist. Wenn wir beispielsweise das Serialisierungsprotokoll analysieren, sind ganzzahlige Variablen oft ein Byte lang, aber längere Variablen sind kein Fehler. Das Einfügen der Behandlung solcher Situationen kann die Qualität des schnellen Pfades beeinträchtigen, wenn der Fallback-Code zu komplex ist. Der Tail-Aufruf der Fallback-Funktion macht es jedoch nicht einfach, bei der Behandlung einer Abnormalität zur Operation zurückzukehren, sodass die Fallback-Funktion in der Lage sein muss, die Operation abzuschließen. Dies führt zu einer Vervielfältigung und Komplikation des Codes.
Idealerweise kann dieses Problem durch Hinzufügen von __attribute __ ((erve_most)) gelöst werden. in einer Fallback-Funktion, gefolgt von einem normalen Aufruf, nicht einem Tail-Aufruf. Das Attribut
preserve_most
macht den Angerufenen für die Aufbewahrung fast aller Register verantwortlich. Auf diese Weise können Sie die Aufgabe, Register zu verhindern, bei Bedarf an Fallback-Funktionen delegieren. Wir haben mit diesem Attribut experimentiert, sind aber auf mysteriöse Probleme gestoßen, die wir nicht lösen konnten. Vielleicht haben wir irgendwo einen Fehler gemacht, wir werden in Zukunft darauf zurückkommen.
Die Hauptbeschränkung besteht darin, dass
musttail
es nicht tragbar ist. Ich hoffe wirklich, dass das Attribut Wurzeln schlägt, in GCC, Visual C ++ und anderen Compilern implementiert wird und eines Tages sogar standardisiert wird. Dies wird aber nicht bald geschehen, aber was sollen wir jetzt tun?
Bei der Erweiterung
musttail
ist nicht verfügbar, müssen Sie für jede theoretische Iteration der Schleife mindestens einen korrekten
return
ohne Tail-Aufruf ausführen . Wir haben einen solchen Fallback in der upb-Bibliothek noch nicht implementiert, aber ich denke, dass daraus ein Makro wird, das je nach Verfügbarkeit
musttail
entweder Tail Calls ausführt oder einfach zurückkehrt.