 Hallo, Bewohner! Wie kann ich alles aus Ihren Daten herausholen? Wie kann man datengesteuerte Entscheidungen treffen? Wie organisiere ich Data Science im Unternehmen? Wer soll einen Analysten einstellen? Wie können Projekte für maschinelles Lernen und künstliche Intelligenz auf die oberste Ebene gebracht werden? Roman Zykov kennt die Antwort auf diese und viele andere Fragen, weil er seit fast zwanzig Jahren Daten analysiert. Zu Romans Erfolgsbilanz gehört die Gründung eines eigenen Unternehmens mit Niederlassungen in Europa und Südamerika, das zum Marktführer für den Einsatz künstlicher Intelligenz (KI) auf dem russischen Markt geworden ist. Darüber hinaus hat der Autor des Buches Analytics bei Ozon.ru von Grund auf neu erstellt. Dieses Buch richtet sich an den denkenden Leser, der sich in der Datenanalyse versuchen und darauf basierende Dienste erstellen möchte. Es ist nützlich für Sie, wenn Sie ein Manager sind,Wer möchte Ziele setzen und Analysen verwalten? Wenn Sie ein Investor sind, können Sie das Potenzial eines Startups leichter verstehen. Diejenigen, die ihr Startup "gesehen" haben, finden hier Empfehlungen zur Auswahl der richtigen Technologie und zur Rekrutierung eines Teams. Und das Buch wird angehenden Spezialisten helfen, ihren Horizont zu erweitern und Praktiken anzuwenden, über die sie zuvor noch nicht nachgedacht haben, und dies wird sie von Fachleuten in einem so schwierigen und volatilen Bereich abheben.
Hallo, Bewohner! Wie kann ich alles aus Ihren Daten herausholen? Wie kann man datengesteuerte Entscheidungen treffen? Wie organisiere ich Data Science im Unternehmen? Wer soll einen Analysten einstellen? Wie können Projekte für maschinelles Lernen und künstliche Intelligenz auf die oberste Ebene gebracht werden? Roman Zykov kennt die Antwort auf diese und viele andere Fragen, weil er seit fast zwanzig Jahren Daten analysiert. Zu Romans Erfolgsbilanz gehört die Gründung eines eigenen Unternehmens mit Niederlassungen in Europa und Südamerika, das zum Marktführer für den Einsatz künstlicher Intelligenz (KI) auf dem russischen Markt geworden ist. Darüber hinaus hat der Autor des Buches Analytics bei Ozon.ru von Grund auf neu erstellt. Dieses Buch richtet sich an den denkenden Leser, der sich in der Datenanalyse versuchen und darauf basierende Dienste erstellen möchte. Es ist nützlich für Sie, wenn Sie ein Manager sind,Wer möchte Ziele setzen und Analysen verwalten? Wenn Sie ein Investor sind, können Sie das Potenzial eines Startups leichter verstehen. Diejenigen, die ihr Startup "gesehen" haben, finden hier Empfehlungen zur Auswahl der richtigen Technologie und zur Rekrutierung eines Teams. Und das Buch wird angehenden Spezialisten helfen, ihren Horizont zu erweitern und Praktiken anzuwenden, über die sie zuvor noch nicht nachgedacht haben, und dies wird sie von Fachleuten in einem so schwierigen und volatilen Bereich abheben.
Muss ich programmieren können?
Ja brauchen. Im 21. Jahrhundert ist es wünschenswert, dass jeder Mensch versteht, wie man Programmierung in seiner Arbeit einsetzt. Bisher stand die Programmierung nur einem engen Kreis von Ingenieuren zur Verfügung. Im Laufe der Zeit ist die angewandte Programmierung zugänglicher, demokratischer und bequemer geworden.
Ich habe als Kind gelernt, alleine zu programmieren. Mein Vater kaufte Ende der 1980er Jahre, als ich ungefähr elf Jahre alt war, einen Computer "Partner 01.01" und begann, mich mit dem Programmieren zu beschäftigen. Zuerst beherrschte ich die BASIC-Sprache, dann kam ich zum Assembler. Ich habe alles aus Büchern studiert - dann gab es niemanden zu fragen. Die Grundlagen, die in der Kindheit gemacht wurden, waren für mich im Leben sehr nützlich. Zu dieser Zeit war mein Hauptinstrument ein blinkender weißer Cursor auf einem schwarzen Bildschirm, Programme mussten auf einem Kassettenrekorder aufgezeichnet werden - all dies kann nicht mit den Möglichkeiten verglichen werden, die wir jetzt haben. Die Grundlagen der Programmierung sind nicht so schwer zu erlernen. Als meine Tochter fünfeinhalb Jahre alt war, habe ich sie in einen einfachen Scratch-Programmierkurs versetzt. Mit meinen kleinen Tipps nahm sie an diesem Kurs teil und erhielt sogar ihre MIT-Einstiegszertifizierung.
Mit der Anwendungsprogrammierung können Sie einen Teil der Funktionen eines Mitarbeiters automatisieren. Die ersten Kandidaten für die Automatisierung sind sich wiederholende Aktionen.
In der Analytik gibt es zwei Möglichkeiten. Die erste besteht darin, vorgefertigte Tools (Excel, Tableau, SAS, SPSS usw.) zu verwenden, bei denen alle Aktionen mit der Maus ausgeführt werden, und die maximale Programmierung besteht darin, eine Formel zu schreiben. Die zweite besteht darin, in Python, R oder SQL zu schreiben. Dies sind zwei grundlegend unterschiedliche Ansätze, aber ein guter Mensch sollte beide beherrschen. Wenn Sie mit einer Aufgabe arbeiten, müssen Sie ein Gleichgewicht zwischen Geschwindigkeit und Qualität finden. Dies gilt insbesondere für die Suche nach Erkenntnissen. Ich habe sowohl begeisterte Anhänger der Programmierung als auch hartnäckige getroffen, die nur eine Maus und höchstens ein Programm benutzen konnten. Ein guter Spezialist wählt für jede Aufgabe sein eigenes Werkzeug aus. In einigen Fällen schreibt er ein Programm, in einem anderen Fall erledigt er alles in Excel. Im dritten Fall werden beide Ansätze kombiniert: Daten werden in SQL hochgeladen, das Dataset in Python verarbeitet und in einer Pivot-Tabelle in Excel oder Google Text & Tabellen analysiert.Die Arbeitsgeschwindigkeit eines solchen fortgeschrittenen Spezialisten kann um eine Größenordnung höher sein als die eines Einzeilers. Wissen gibt Freiheit.
Schon als Student sprach ich fließend mehrere Programmiersprachen und konnte sogar anderthalb Jahre als Softwareentwickler arbeiten. Die Zeiten waren damals schwierig - ich trat im Juni 1998 in das Moskauer Institut für Physik und Technologie ein, und im August gab es einen Ausfall. Es war unmöglich, von einem Stipendium zu leben, ich wollte meinen Eltern kein Geld abnehmen. In meinem zweiten Jahr hatte ich das Glück, als Entwickler in einem der Unternehmen von MIPT eingestellt zu werden - dort vertiefte ich mein Wissen über Assembler und C. Nach einiger Zeit bekam ich einen Job im technischen Support von StatSoft Russia - hier habe ich meine statistische Analyse verbessert. Bei Ozon.ru absolvierte er eine Ausbildung, erhielt ein SAS-Zertifikat und schrieb auch viel in SQL. Die Programmiererfahrung hat mir sehr geholfen - ich hatte keine Angst vor etwas Neuem, ich habe es einfach genommen und getan. Wenn ich keine solche Programmiererfahrung hätte, gäbe es nicht viele interessante Dinge in meinem Leben, einschließlich der Retail Rocket Company,was wir mit meinen Partnern gegründet haben.
Datensatz
Ein Dataset ist ein Datensatz, meist in Form einer Tabelle, der aus dem Speicher entladen wurde (z. B. über SQL) oder auf andere Weise abgerufen wurde. Eine Tabelle besteht aus Spalten und Zeilen, die üblicherweise als Datensätze bezeichnet werden. Beim maschinellen Lernen sind die Spalten selbst unabhängige Variablen oder Prädiktoren oder häufiger Merkmale und abhängige Variablen. Sie finden diese Einteilung in der Literatur. Die Aufgabe des maschinellen Lernens besteht darin, ein Modell zu trainieren, das unter Verwendung der unabhängigen Variablen (Merkmale) den Wert der abhängigen Variablen korrekt vorhersagen kann (in der Regel gibt es nur eine im Datensatz).
Die beiden wichtigsten Arten von Variablen sind kategorial und quantitativ. Eine kategoriale Variable enthält den Text oder die numerische Codierung von "Kategorien". Im Gegenzug kann es sein:
- Binär - kann nur zwei Werte annehmen (Beispiele: Ja / Nein, 0/1).
- Nominal - kann mehr als zwei Werte annehmen (Beispiel: Ja / Nein / Weiß nicht).
- Ordnungszahl - wenn die Reihenfolge wichtig ist (z. B. der Rang des Athleten, die Zeilennummer in den Suchergebnissen).
Eine quantitative Variable kann sein:
- Diskret (diskret) - Der Wert wird vom Konto berechnet, z. B. die Anzahl der Personen im Raum.
- Kontinuierlich - ein beliebiger Wert aus dem Intervall, z. B. Kartongewicht, Produktpreis.
Schauen wir uns ein Beispiel an. Es gibt eine Tabelle mit Wohnungspreisen (abhängige Variable), eine Zeile (Datensatz) für eine Wohnung, jede Wohnung hat eine Reihe von Attributen (unabhängig) mit den folgenden Spalten:
- Der Preis der Wohnung ist kontinuierlich und abhängig.
- Der Bereich der Wohnung ist durchgehend.
- Die Anzahl der Räume ist diskret (1, 2, 3, ...).
- Das Badezimmer ist kombiniert (ja / nein) - binär.
- Stockwerksnummer - ordinal oder nominal (je nach Aufgabe).
- Der Abstand zum Zentrum ist kontinuierlich.
Beschreibende Statistik
Der allererste Schritt nach dem Entladen von Daten aus dem Lager ist die explorative Datenanalyse, die beschreibende Statistiken und Datenvisualisierung umfasst und möglicherweise die Daten durch Entfernen von Ausreißern löscht.
Beschreibende Statistiken enthalten normalerweise unterschiedliche Statistiken für jede der Variablen im Eingabedatensatz:
- Die Anzahl der nicht fehlenden Werte.
- Die Anzahl der eindeutigen Werte.
- Minimum Maximum.
- Mittlere Bedeutung.
- Median.
- Standardabweichung.
- Perzentile - 25%, 50% (Median), 75%, 95%.
Es können nicht alle Arten von Variablen berechnet werden. Beispielsweise kann der Durchschnitt nur für quantitative Variablen berechnet werden. Statistikpakete und statistische Analysebibliotheken verfügen bereits über sofort einsatzbereite Funktionen, die beschreibende Statistiken zählen. Beispielsweise verfügt die pandas Python-Bibliothek über eine Beschreibungsfunktion, mit der sofort mehrere Statistiken für eine oder alle Variablen im Datensatz angezeigt werden:
s = pd.Series([4-1, 2, 3])
s.describe()
count 3.0
mean 2.0
std 1.0
min 1.0
25% 1.5
50% 2.0
75% 2.5
max 3.0
Obwohl dieses Buch kein Lehrbuch zur Statistik sein soll, gebe ich Ihnen einige hilfreiche Hinweise. Theoretisch wird häufig davon ausgegangen, dass wir mit normalverteilten Daten arbeiten, deren Histogramm wie eine Glocke aussieht (Abbildung 4.1).
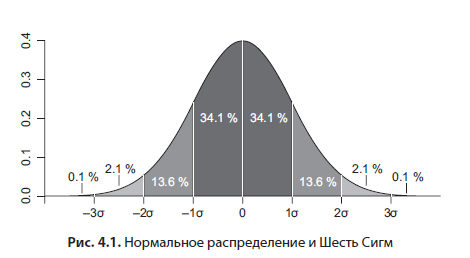
Ich empfehle dringend, diese Annahme zumindest mit dem Auge zu überprüfen. Der Median ist der Wert, der die Stichprobe halbiert. Befinden sich beispielsweise das 25. und das 75. Perzentil in unterschiedlichen Abständen vom Median, deutet dies bereits auf eine verschobene Verteilung hin. Ein weiterer Faktor ist der starke Unterschied zwischen Mittelwert und Median; in einer Normalverteilung fallen sie praktisch zusammen. Bei der Analyse des Kundenverhaltens handelt es sich häufig um eine Exponentialverteilung. In Ozon.ru ist beispielsweise die Zeit zwischen aufeinanderfolgenden Kundenaufträgen exponentiell verteilt. Der Mittelwert und der Median dafür unterscheiden sich signifikant. Daher ist die richtige Zahl der Median, der Wert, der die Stichprobe halbiert. Im Beispiel mit Ozon.ru ist dies die Zeit, in der 50% der Benutzer die nächste Bestellung nach der ersten aufgeben. Der Median ist auch gegenüber Ausreißern in den Daten robuster.Wenn Sie beispielsweise aufgrund der Einschränkungen des Statistikpakets mit Durchschnittswerten arbeiten möchten und der Durchschnitt technisch schneller als der Median berechnet wird, können Sie ihn bei einer Exponentialverteilung mit dem natürlichen Logarithmus verarbeiten. Um zur ursprünglichen Datenskala zurückzukehren, müssen Sie den resultierenden Durchschnitt mit dem üblichen Exponenten verarbeiten.
Perzentil ist ein Wert, den eine bestimmte Zufallsvariable mit einer festen Wahrscheinlichkeit nicht überschreitet. Zum Beispiel bedeutet der Ausdruck "das 25. Perzentil des Warenpreises ist gleich 150 Rubel", dass 25% der Waren einen Preis von weniger als oder gleich 150 Rubel haben, die restlichen 75% der Waren sind teurer als 150 Rubel.
Wenn für eine Normalverteilung der Mittelwert und die Standardabweichung bekannt sind, gibt es nützliche theoretisch abgeleitete Muster - 95% aller Werte fallen in einem Abstand von zwei Standardabweichungen vom Mittelwert in beide Richtungen in das Intervall, d. H. Die Breite des Intervalls beträgt vier Sigma. Möglicherweise haben Sie einen Begriff wie Six Sigma gehört (Abbildung 4.1) - diese Abbildung kennzeichnet die Produktion ohne Schrott. Dieses empirische Gesetz folgt also aus der Normalverteilung: Im Intervall von sechs Standardabweichungen um den Mittelwert (drei in jede Richtung) passen 99,99966% der Werte - ideale Qualität. Perzentile sind sehr nützlich, um Ausreißer zu finden und aus Daten zu entfernen. Wenn Sie beispielsweise experimentelle Daten analysieren, können Sie davon ausgehen, dass alle Daten außerhalb des 99. Perzentils Ausreißer sind, und diese löschen.
Diagramme
Ein guter Graph sagt mehr als tausend Worte. Die wichtigsten Arten von Diagrammen, die ich verwende:
- Histogramme;
- Streudiagramm;
- Zeitreihendiagramm mit einer Trendlinie;
- Box-Plot, Box- und Whisker-Plot.
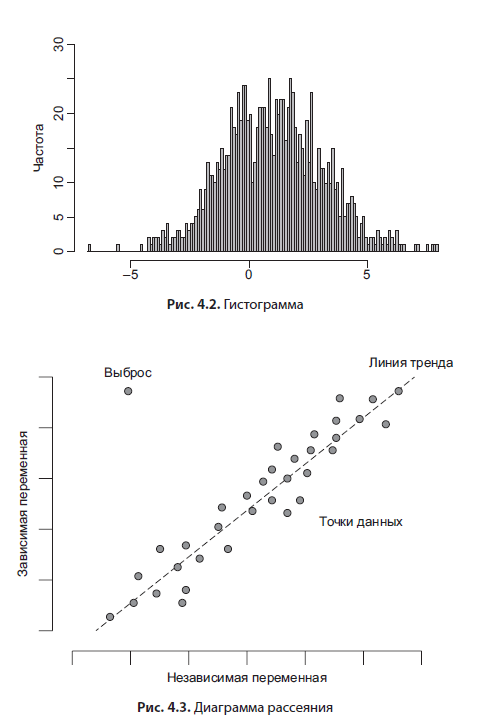
Das Histogramm (Abbildung 4.2) ist das nützlichste Analysewerkzeug. Sie können die Häufigkeitsverteilung des Auftretens eines Werts (für eine kategoriale Variable) visualisieren oder eine kontinuierliche Variable in Bereiche (Bins) aufteilen. Die zweite wird häufiger verwendet. Wenn Sie einem solchen Diagramm zusätzlich beschreibende Statistiken bereitstellen, erhalten Sie ein vollständiges Bild, das die Variable beschreibt, an der Sie interessiert sind. Das Histogramm ist ein einfaches und intuitives Werkzeug.
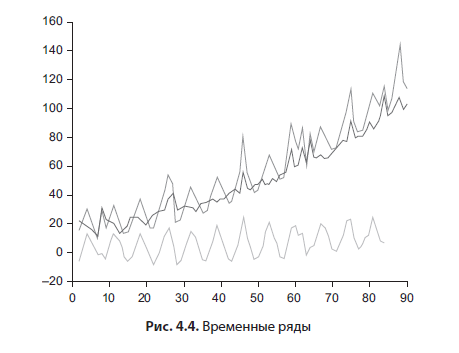
Anhand eines Streudiagramms (Abbildung 4.3) können Sie sehen, wie zwei Variablen voneinander abhängen. Es ist einfach konstruiert: auf der horizontalen Achse - der Skala der unabhängigen Variablen, auf der vertikalen Achse - der Skala der abhängigen. Werte (Datensätze) sind als Punkte markiert. Eine Trendlinie kann ebenfalls hinzugefügt werden. In erweiterten Statistikpaketen können Sie Ausreißer interaktiv kennzeichnen.
Zeitreihendiagramme (Abbildung 4.4) ähneln weitgehend einem Streudiagramm, bei dem die unabhängige Variable (auf der horizontalen Achse) die Zeit ist. Normalerweise können zwei Komponenten von einer Zeitreihe unterschieden werden - zyklisch und Trend. Es kann ein Trend erstellt werden, der die Länge des Zyklus kennt. Beispielsweise ist ein siebentägiger Trend ein Standardverkaufszyklus in Lebensmittelgeschäften. Alle 7 Tage wird ein sich wiederholendes Bild in der Tabelle angezeigt. Als nächstes wird dem Diagramm ein gleitender Durchschnitt mit einer Fensterlänge gleich dem Zyklus überlagert - und Sie erhalten eine Trendlinie. Fast alle Statistikpakete, Excel und Google Sheets können dies. Wenn Sie die zyklische Komponente benötigen, wird dazu die Trendlinie von der Zeitreihe subtrahiert. Auf der Grundlage dieser einfachen Berechnungen werden die einfachsten Algorithmen zur Vorhersage von Zeitreihen erstellt.
Das Boxplot (Abb. 4.5) ist sehr interessant; Bis zu einem gewissen Grad werden die Histogramme dupliziert, da auch eine Schätzung der Verteilung angezeigt wird.
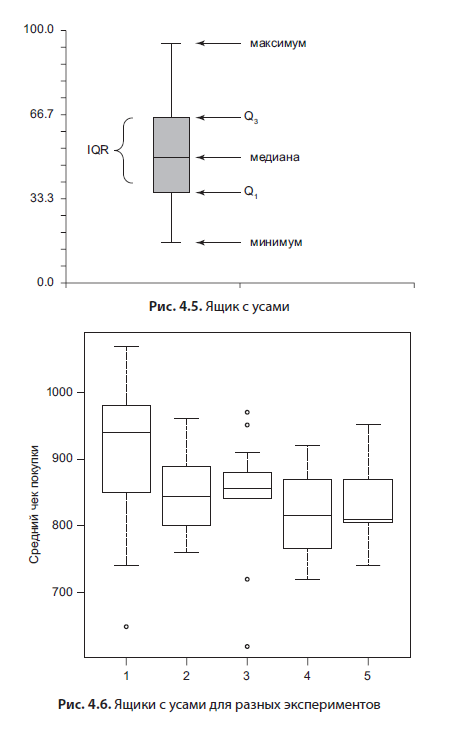
Es besteht aus mehreren Elementen: einem Schnurrbart, der das Minimum und Maximum bezeichnet, einem Kästchen, dessen Oberkante das 75. Perzentil und dessen Unterkante das 25. Perzentil ist. In der Box ist die Linie der Median, der Wert "in der Mitte", der die Stichprobe in zwei Hälften teilt. Diese Art von Grafik ist nützlich, um experimentelle Ergebnisse oder Variablen miteinander zu vergleichen. Ein Beispiel für ein solches Diagramm finden Sie unten (Abb. 4.6). Ich denke, dies ist der beste Weg, um die Ergebnisse von Hypothesentests zu visualisieren.
Allgemeiner Ansatz zur Datenvisualisierung
Die Datenvisualisierung wird aus zwei Gründen benötigt: um die Daten zu untersuchen und dem Kunden die Ergebnisse zu erklären. Oft werden verschiedene Methoden verwendet, um die Ergebnisse zu präsentieren: ein einfacher Kommentar mit einigen Zahlen, Excel oder ein anderes Tabellenformat, eine Präsentation mit Folien. Alle drei Methoden kombinieren Schlussfolgerung und Beweis - das heißt, eine Erklärung, wie diese Schlussfolgerung gezogen wurde. Es ist zweckmäßig, den Beweis in Grafiken auszudrücken. In 90% der Fälle reichen hierfür die Diagramme der oben beschriebenen Typen aus.
Erkundungsdiagramme und Präsentationsdiagramme unterscheiden sich voneinander. Der Zweck der Forschung besteht darin, ein Muster oder eine Ursache zu finden. In der Regel gibt es viele davon, und es kommt vor, dass sie zufällig erstellt werden. Der Zweck der Präsentationsdiagramme besteht darin, den Entscheidungsträger (Entscheidungsträger) zu den Schlussfolgerungen im Problem zu führen. Hier ist alles wichtig - sowohl der Titel der Folie als auch ihre einfache Reihenfolge, die zum gewünschten Ergebnis führt. Ein wichtiges Kriterium für das Inferenzschema ist, wie schnell der Kunde Sie versteht und Ihnen zustimmt. Es muss keine Präsentation sein. Persönlich bevorzuge ich einfachen Text - ein paar Sätze mit Schlussfolgerungen, ein paar Grafiken und ein paar Zahlen, die diese Schlussfolgerungen belegen, nichts weiter.
Gene Zelazny, Direktor für visuelle Kommunikation bei McKinsey & Company, erklärt in seinem Buch Speak the Language of Diagrams:
„Die Art des Diagramms wird nicht durch die Daten (Dollar oder Zinsen) oder durch bestimmte Parameter (Gewinn, Rentabilität oder Gehalt) bestimmt. und Ihre Idee ist das, was Sie in das Diagramm einfügen möchten. "
Ich empfehle Ihnen, in Präsentationen und Artikeln auf Grafiken zu achten - beweisen sie die Schlussfolgerungen des Autors? Magst du alles an ihnen? Könnten sie überzeugender sein?
Und hier ist, was Jean Zelazny über Folien in Präsentationen schreibt:
"Der weit verbreitete Einsatz von Computertechnologie hat dazu geführt, dass Sie jetzt in wenigen Minuten die bisher erforderlichen Stunden mühsamer Arbeit erledigen können - und die Folien werden wie Kuchen gebacken ... fade und geschmacklos."
Ich habe ziemlich viele Berichte gemacht: mit und ohne Folien, kurz, für 5-10 Minuten und lang - für eine Stunde. Ich kann Ihnen versichern, dass es für mich viel schwieriger ist, einen überzeugenden Text für eine kurze Präsentation ohne Folien zu erstellen als für eine PowerPoint-Präsentation. Schauen Sie sich die Politiker an, die sprechen: Ihre Aufgabe ist es zu überzeugen, wie viele von ihnen in ihren Reden Folien zeigen? Das Wort ist überzeugender, die Folien sind nur visuelles Material. Und es erfordert mehr Arbeit, um Ihr Wort klar und überzeugend zu machen, als Folien zu werfen. Ich dachte darüber nach, wie die Präsentation beim Verfassen der Folien aussieht. Und wenn ich einen mündlichen Bericht schreibe - wie überzeugend sind meine Argumente, wie man mit Intonation arbeitet, wie klar meine Gedanken sind. Beachten Sie bitteBenötigen Sie wirklich eine Präsentation? Möchten Sie ein Meeting in langweilige Folien verwandeln, anstatt Entscheidungen zu treffen?
„Meetings sollten sich auf kurze, schriftliche Berichte auf Papier konzentrieren und nicht auf Abstracts oder Listenfetzen, die auf die Wand projiziert werden“, sagt Edward Tufty, ein bekannter Sprecher der Schule für Datenvisualisierung in PowerPoint Cognitive Style.
Analyse gepaarter Daten
Ich habe von den Entwicklern [30] Retail Rocket etwas über Paarprogrammierung gelernt. Es ist eine Programmiertechnik, bei der der Quellcode von Personenpaaren erstellt wird, die dieselbe Aufgabe programmieren und an derselben Arbeitsstation sitzen. Ein Programmierer sitzt an der Tastatur, der andere arbeitet mit dem Kopf, konzentriert sich auf das Gesamtbild und betrachtet kontinuierlich den vom ersten Programmierer erstellten Code. Sie können von Zeit zu Zeit den Ort wechseln.
Und wir haben es geschafft, es an die Bedürfnisse der Analytik anzupassen! Analytik ist wie Programmierung ein kreativer Prozess. Stellen Sie sich vor, Sie müssen eine Mauer bauen. Sie haben einen Arbeiter. Wenn Sie eine weitere hinzufügen, verdoppelt sich die Geschwindigkeit ungefähr. Im kreativen Prozess funktioniert dies nicht. Die Geschwindigkeit der Projekterstellung wird sich nicht verdoppeln. Ja, Sie können ein Projekt zerlegen, aber ich diskutiere jetzt eine Aufgabe, die nicht zerlegt werden kann und die von einer Person ausgeführt werden sollte. Der gepaarte Ansatz ermöglicht es Ihnen, diesen Prozess um ein Vielfaches zu beschleunigen. Eine Person sitzt an der Tastatur, die zweite sitzt neben ihm. Zwei Köpfe arbeiten an demselben Problem. Wenn ich schwierige Probleme löse, spreche ich mit mir. Wenn zwei Köpfe miteinander sprechen, suchen sie nach einem besseren Grund. Wir verwenden das gepaarte Arbeitsschema für die folgenden Aufgaben.
- Wenn es beispielsweise erforderlich ist, das Wissen eines Projekts von einem Mitarbeiter auf einen anderen zu übertragen, wurde ein Neuankömmling eingestellt. Der „Kopf“ ist ein Mitarbeiter, der Wissen überträgt, „Hände“ an der Tastatur - an den es übertragen wird.
- Wenn das Problem komplex und unverständlich ist. Dann lösen zwei erfahrene Mitarbeiter in einem Paar das Problem viel effizienter als einer. Es wird schwieriger sein, die Analyseaufgabe einseitig zu gestalten.
Normalerweise übertragen wir während der Planung eine Aufgabe in die Kategorie der gepaarten, wenn klar ist, dass sie den Kriterien einer solchen entspricht.
Die Vorteile des Paaransatzes sind, dass die Zeit viel effizienter genutzt wird, beide Menschen sehr konzentriert sind und sich gegenseitig disziplinieren. Komplexe Aufgaben werden kreativer und um eine Größenordnung schneller gelöst. Minus - es ist unmöglich, länger als ein paar Stunden in diesem Modus zu arbeiten, man wird sehr müde.
Technische Schulden
Eine weitere wichtige Sache, die ich von Ingenieuren von Retail Rocket gelernt habe, ist der Umgang mit technischen Schulden. Technische Schulden arbeiten mit alten Projekten, optimieren die Arbeitsgeschwindigkeit, wechseln zu neuen Versionen von Bibliotheken, entfernen alten Code aus Hypothesentests und vereinfachen die technische Vereinfachung von Projekten. All diese Aufgaben nehmen ein gutes Drittel der Entwicklungszeit für Analysen in Anspruch. Ich werde den technischen Direktor von Retail Rocket Andrey Chizh zitieren:
„Ich habe noch keine Unternehmen in meiner Praxis getroffen (und dies sind mehr als 10 Unternehmen, in denen ich selbst gearbeitet habe, und ungefähr die gleiche Anzahl, die ich von innen gut kenne). , mit Ausnahme unserer, bei denen es Aufgaben geben würde, die Funktionalität zu entfernen, obwohl es wahrscheinlich solche gibt. "
Ich habe mich auch nicht getroffen. Ich habe die "Sümpfe" von Softwareprojekten gesehen, in denen altes Zeug die Schaffung von etwas Neuem stört. Der Kern der technischen Verschuldung besteht darin, dass alles, was Sie zuvor getan haben, gewartet werden muss. Es ist wie bei einer Autowartung - es muss regelmäßig durchgeführt werden, sonst fällt das Auto im unerwartetsten Moment aus. Code, der lange Zeit nicht geändert oder aktualisiert wurde, ist fehlerhafter Code. Normalerweise funktioniert es bereits nach dem Prinzip "Werke - nicht anfassen". Vor vier Jahren habe ich mit einem Entwickler bei Bing gesprochen. Er sagte, dass es in der Architektur dieser Suchmaschine eine kompilierte Bibliothek gibt, deren Code verloren geht. Und niemand weiß, wie man es wiederherstellt. Je länger es dauert, desto schlimmer werden die Folgen sein.
Wie Analysten von Einzelhandelsraketen technische Schulden bedienen:
- , . .
- - — , . , Spark , 1.0.0.
- - — .
- - — , , .
Der Umgang mit technischen Schulden ist der Weg zur Qualität. Davon war ich überzeugt, als ich am Retail Rocket-Projekt arbeitete. Aus technischer Sicht wird das Projekt wie in den "besten Häusern in Kalifornien" durchgeführt.
Weitere Details zum Buch finden Sie auf der Website des Verlags
» Inhaltsverzeichnis
» Auszug
für Einwohner 25% Rabatt auf den Gutschein - Data Science
Nach Zahlungseingang für die Papierversion des Buches wird ein E-Book an das gesendet Email.