
YELP ist ein Netzwerk in Übersee, das Menschen hilft, lokale Unternehmen und Dienstleistungen basierend auf Feedback, Vorlieben und Empfehlungen zu finden. In den aktuellen Artikeln wird eine bestimmte Analyse davon unter Verwendung der Neo4j-Plattform durchgeführt, die sich auf das Graph-DBMS sowie die Python-Sprache bezieht.
Was wir sehen werden:
- wie man mit Neo4j und großen Datensätzen am Beispiel von YELP arbeitet;
- wie der YELP-Datensatz nützlich sein kann;
- teilweise: Was sind die Funktionen in den neuen Versionen von Neo4j und warum ist das Buch "Graph Algorithms" 2019 von O'REILLY bereits veraltet.
Was ist YELP und Yelp-Datensatz?
Das YELP-Netzwerk umfasst derzeit 30 Länder, die Russische Föderation ist noch nicht in ihrer Anzahl enthalten. Die russische Sprache wird vom Netzwerk nicht unterstützt. Das Netzwerk selbst enthält eine ziemlich umfangreiche Menge an Informationen über verschiedene Arten von Unternehmen sowie Bewertungen über diese. Yelp kann auch sicher als soziales Netzwerk bezeichnet werden, da es Daten über Benutzer enthält, die Bewertungen abgegeben haben. Dort gibt es keine persönlichen Daten, nur Namen. Trotzdem bilden Benutzer Communities, Gruppen, oder sie können nach verschiedenen Kriterien weiter zu diesen Gruppen und Communities zusammengeschlossen werden. Zum Beispiel durch die Anzahl der Sterne (Sterne), die dem Punkt (Restaurant, Tankstelle usw.) zugewiesen wurden, den Sie besucht haben.
YELP beschreibt sich wie folgt:
- 8,635,403 Bewertungen
- 160.585 Unternehmen
- 200.000 Bilder
- 8 Großstädte
1.162.119 Empfehlungen von 2.189.457 Benutzern.
Über 1,2 Millionen Geschäftsutensilien: Öffnungszeiten, Parken, Verfügbarkeit und mehr.
Seit 2013 veranstaltet Yelp regelmäßig
den Yelp-Datensatzwettbewerb , der alle dazu ermutigt , den offenen Yelp-Datensatz zu erkunden und zu erkunden.
Der Datensatz selbst ist unter dem Link verfügbar. Der
Datensatz ist ziemlich umfangreich und besteht nach dem Entpacken aus 5 JSON-Dateien:
Alles wäre in Ordnung, aber nur YELP lädt unverarbeitete Rohdaten hoch, und um mit ihnen arbeiten zu können, ist eine Vorverarbeitung erforderlich.
Installation und schnelle Einrichtung von Neo4j
Für die Analyse wird Neo4j verwendet. Wir werden die Funktionen des Diagramm-DBMS und dessen einfache Verschlüsselungssprache verwenden, um mit dem Datensatz zu arbeiten.
Über Neo4j als Graphendatenbank, die wiederholt auf Habre geschrieben wurde ( hier und hier für einen Artikel für Anfänger), also macht es keinen Sinn, es erneut einzureichen .
Um mit der Plattform arbeiten zu können, müssen Sie die Desktop-Version (ca. 500 MB) herunterladen oder in der Online-Sandbox arbeiten. Zum Zeitpunkt dieses Schreibens sind Neo4j Enterprise 4.2.6 für Entwickler sowie andere frühere Versionen für die Installation verfügbar.
Außerdem wird die Option verwendet - Arbeiten Sie in der Desktop-Version in der Windows-Umgebung (Neo4j Desktop 1.4.5, Datenbankversionen 4.2.5, 4.2.1).
Trotz der Tatsache, dass die neueste Version 4.2.6 ist, ist es besser, sie noch nicht zu installieren, da alle in neo4j verwendeten Plugins noch nicht dafür aktualisiert wurden. Die vorherige Version - 4.2.5 wird ausreichen.
Nach der Installation des heruntergeladenen Pakets müssen Sie:
- Erstellen Sie eine neue lokale Datenbank unter Angabe des Benutzers neo4j und des Kennworts 123 (warum genau werden sie unten erläutert).
Bild

- Installieren Sie die benötigten Plugins - APOC, Graph Data Science Library.
Bild

- Überprüfen Sie, ob die Datenbank gestartet wird und ob der Browser geöffnet wird, wenn Sie auf die Schaltfläche Start klicken
Bild


* - Aktivieren Sie den Offline-Modus, damit die Datenbank nicht ernsthaft versucht, neue Versionen vorzuschlagen.
Bild

Laden von Daten in Neo4j
Wenn bei der Installation von Neo4j alles reibungslos verlief, können Sie fortfahren und es gibt drei Möglichkeiten.
Der erste Weg besteht darin, Daten von Grund auf neu in die Datenbank zu importieren, einschließlich ihrer anfänglichen Bereinigung und Umwandlung.
Die zweite Möglichkeit besteht darin, die fertige Datenbank aus dem Speicherauszug zu laden und mit der Arbeit zu beginnen.
Die dritte Möglichkeit besteht darin, die fertige Datenbank direkt in den Ordner mit der neu erstellten Datenbank zu laden.
Daher sollten Sie in jedem Fall eine Datenbank mit den folgenden Parametern erhalten:

und dem endgültigen Schema:
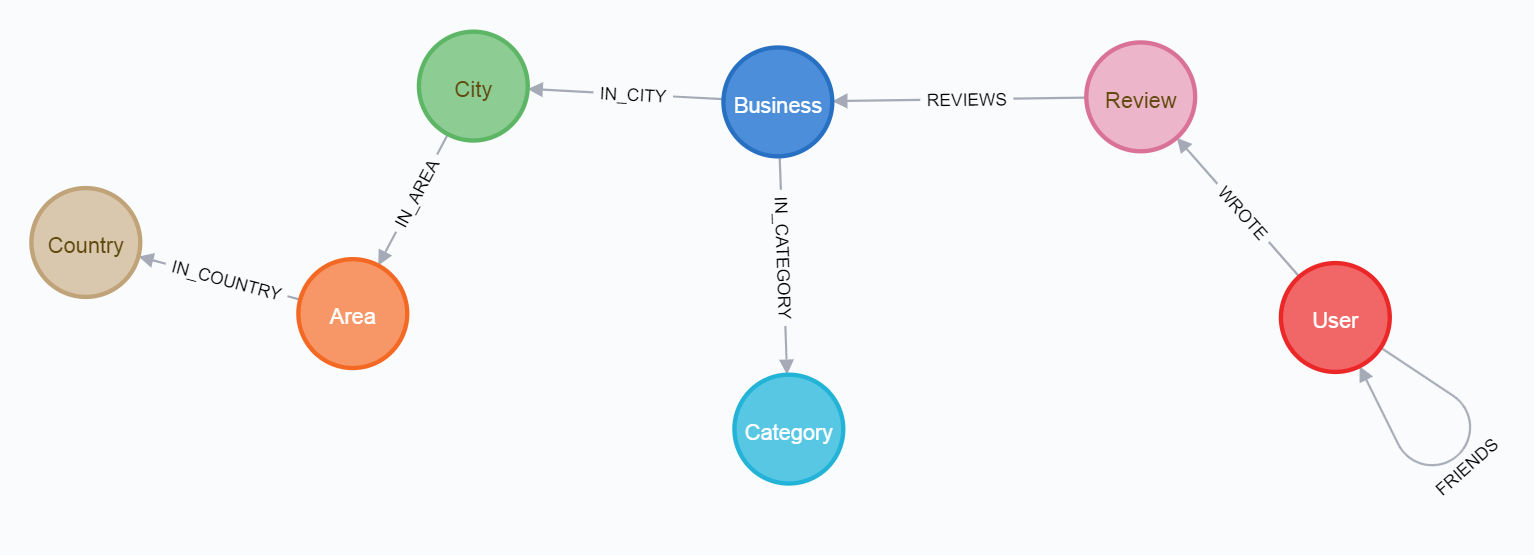
Um den ersten Pfad zu durchlaufen, ist es besser, den Artikel zuerst auf Medium zu lesen .
* Vielen Dank an TRAN Ngoc Thach dafür.
Und verwenden Sie ein fertiges Jupyter-Notizbuch (von mir für Windows angepasst) - Link .
Der Importvorgang ist nicht einfach und dauert ziemlich lange.

Es gibt keine Probleme mit dem Speicher, selbst wenn Sie nur 8 GB RAM haben, da der Stapelimport verwendet wird.
Sie müssen jedoch eine 10-GB-Auslagerungsdatei erstellen, da beim Überprüfen der importierten Daten ein Absturz des Jupyter auftritt und dieser Punkt im obigen Jupiter-Notizbuch erwähnt wird.
Der zweite Weg ist einfacher.
Erstellen Sie eine Datenbank, wechseln Sie in den Ordner mit dem neo4j-admin (jede Datenbank hat ihre eigene) und führen Sie Folgendes aus:
neo4j-admin load --from=G:\neo4j\dumps\neo4j.dump --database=neo4j --force
Dabei ist G: \ neo4j \ dumps \ neo4j.dump der Pfad zum Datenbankspeicherauszug.
Der dritte Weg ist der schnellste und wurde zufällig entdeckt. Dies bedeutet, dass eine vorgefertigte neo4j-Datenbank direkt in eine vorhandene neo4j-Datenbank kopiert wird. Von den bisher entdeckten Minuspunkten können Sie die Datenbank nicht mit Neo4j sichern (neo4j-admin dump --database = neo4j --to = D: \ neo4j \ neo4j.dump). Dies kann jedoch auf unterschiedliche Versionen zurückzuführen sein. In Version 4.2.1 wurde die Datenbank aus Version 4.2.5 kopiert. Darüber hinaus erscheinen im allgemeinen Datenbankschema Artefakte, die sich jedoch nicht auf dessen Betrieb auswirken.
Wie diese Methode implementiert wird:
- Öffnen Sie die Registerkarte Verwalten der Datenbank, in die der Import erfolgen soll
Bild


- Gehen Sie in den Ordner mit der Datenbank und kopieren Sie den Datenordner dort, wobei Sie mögliche Übereinstimmungen überschreiben
Bild

In diesem Fall sollte die Datenbank selbst, in der die Kopie erstellt wurde, nicht gestartet werden.
- Starten Sie Neo4j neu.
Und hier ist das zuvor verwendete Login-Passwort (neo4j, 123) nützlich, um Konflikte zu vermeiden.
Nach dem Starten der kopierten Datenbank steht eine Datenbank mit einem Yelp-Datensatz zur Verfügung:

YELP beobachten
Sie können YELP sowohl über den Neo4j-Browser als auch durch Senden von Abfragen an die Datenbank von demselben Jupyter-Notizbuch aus studieren.
Aufgrund der Tatsache, dass die Datenbank grafisch ist, wird der Browser von einem angenehmen visuellen Bild begleitet, auf dem diese Grafiken angezeigt werden.
Um sich mit YELP vertraut zu machen, muss reserviert werden, dass die Datenbank nur 3 Länder enthält, USA, KG und CA:

Sie können das Datenbankschema anzeigen, indem Sie eine Anfrage in der Chiffriersprache im neo4j-Browser schreiben:
CALL db.schema.visualization()
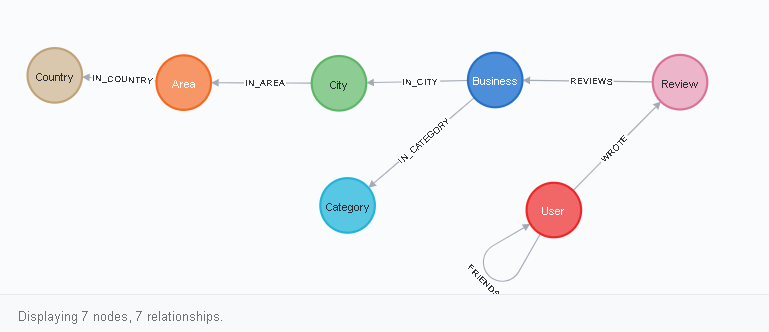
Wie lese ich dieses Diagramm? Alles sieht so aus. Der Benutzerknoten hat eine Verknüpfung zu sich selbst vom Typ FRIENDS sowie eine WROTE-Verknüpfung zum Überprüfungsknoten. Rewiew hat wiederum eine REVIEWS-Verbindung mit Business und so weiter. Sie können dies visuell sehen, nachdem Sie auf einen der Scheitelpunkte (Knotenbezeichnungen) geklickt haben, z. B. auf Benutzer: Die

Datenbank wählt 25 Benutzer aus und zeigt sie an:

Wenn Sie auf das entsprechende Symbol direkt auf dem Benutzer klicken, dann auf alle Es werden direkte Verbindungen von ihm angezeigt, und als Verbindungen für Benutzer zweier Typen - FREUNDE und BEWERTUNG - werden alle angezeigt:
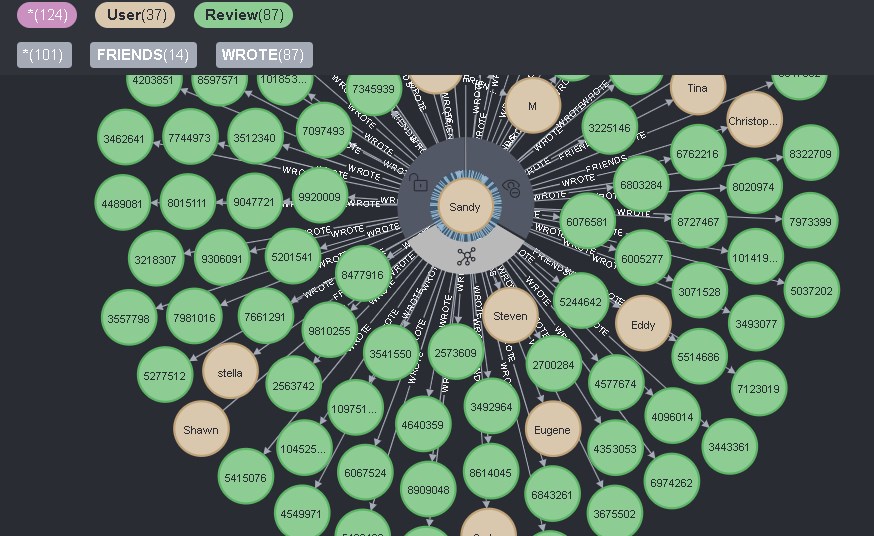
Dies ist gleichzeitig bequem und unpraktisch. Einerseits können Sie alle Informationen über den Benutzer mit einem Klick anzeigen, gleichzeitig können Sie mit diesem Klick keine unnötigen Informationen entfernen.
Aber es gibt nichts zu befürchten, Sie können diesen Benutzer und nur alle seine Freunde anhand der ID finden:
MATCH p=(:User {user_id:"u-CFWELen3aWMSiLAa_9VANw"}) -[r:FRIENDS]->() RETURN p LIMIT 25

Auf die gleiche Weise können Sie sehen, welche Bewertungen eine bestimmte Person geschrieben hat:

YELP speichert Bewertungen bereits ab 2010! Zweifelhafte Nützlichkeit, aber dennoch.
Um diese Bewertungen zu lesen, müssen

Sie zur Textansicht wechseln, indem Sie auf A klicken. - Schauen wir uns den Ort an, den Sandy vor etwa 10 Jahren geschrieben hat, und finden Sie ihn auf yelp.com. -

Ein solcher Ort existiert wirklich - www.yelp.com/ biz / cafe-sushi- cambridge ,
und hier ist Sandy selbst mit ihrer eigenen Bewertung - www.yelp.com/biz/cafe-sushi-cambridge?q=I%20was%20really%20excited
Bild

Python-Abfragen in Neo4j db vom jupyter notebook
Es werden teilweise Informationen aus dem erwähnten kostenlosen Buch "Graph Algorithms" 2019 von O'REILLY verwendet. Zum Teil, weil die Syntax im Buch vielerorts veraltet ist.
Die Basis, mit der wir arbeiten werden, muss gestartet werden, während der neo4j-Browser selbst nicht gestartet werden muss.
Bibliotheken importieren:
from neo4j import GraphDatabase
import pandas as pd
from tabulate import tabulate
import matplotlib
matplotlib.use('TkAgg')
import matplotlib.pyplot as plt
DB-Verbindung:
driver = GraphDatabase.driver("bolt://localhost", auth=("neo4j", "123"))
Zählen wir die Anzahl der Eckpunkte für jedes Etikett in der Datenbank:
result = {"label": [], "count": []}
with driver.session() as session:
labels = [row["label"] for row in session.run("CALL db.labels()")]
for label in labels:
query = f"MATCH (:`{label}`) RETURN count(*) as count"
count = session.run(query).single()["count"]
result["label"].append(label)
result["count"].append(count)
df = pd.DataFrame(data=result)
print(tabulate(df.sort_values("count"), headers='keys',
tablefmt='psql', showindex=False))
Ausgabe:
+ ---------- + --------- +
| Etikett | count |
| ---------- + --------- |
| Land | 3 |
| Bereich | 15 |
| Stadt | 355 |
| Kategorie | 1330 |
| Geschäft | 160585 |
| Benutzer | 2189457 |
| Rückblick | 8635403 |
+ ---------- + --------- +
Es scheint wahr zu sein, in unserer Datenbank gibt es 3 Länder, wie wir zuvor über den neo4j-Browser gesehen haben.
Und dieser Code zählt die Anzahl der Links (Kanten):
result = {"relType": [], "count": []}
with driver.session() as session:
rel_types = [row["relationshipType"] for row in session.run
("CALL db.relationshipTypes()")]
for rel_type in rel_types:
query = f"MATCH ()-[:`{rel_type}`]->() RETURN count(*) as count"
count = session.run(query).single()["count"]
result["relType"].append(rel_type)
result["count"].append(count)
df = pd.DataFrame(data=result)
print(tabulate(df.sort_values("count"), headers='keys',
tablefmt='psql', showindex=False))
Ausgabe:
+ ------------- + --------- +
| relType | count |
| ------------- + --------- |
| IN_COUNTRY | 15 |
| IN_AREA | 355 |
| IN_CITY | 160585 |
| IN_CATEGORY | 708884 |
| BEWERTUNGEN | 8635403 |
| WROTE | 8635403 |
| FREUNDE | 8985774 |
+ ------------- + --------- +
Ich denke, das Prinzip ist klar. Zum Schluss schreiben wir eine Anfrage und rendern sie.
Top 10 Vancouver Hotels mit den meisten Bewertungen
# Find the 10 hotels with the most reviews
query = """
MATCH (review:Review)-[:REVIEWS]->(business:Business),
(business)-[:IN_CATEGORY]->(category:Category {category_id: $category}),
(business)-[:IN_CITY]->(:City {name: $city})
RETURN business.name AS business, collect(review.stars) AS allReviews
ORDER BY size(allReviews) DESC
LIMIT 10
"""
#MATCH (review:Review)-[:REVIEWS]->(business:Business),
#(business)-[:IN_CATEGORY]->(category:Category {category_id: "Hotels"}),
#(business)-[:IN_CITY]->(:City {name: "Vancouver"})
#RETURN business.name AS business, collect(review.stars) AS allReviews
#ORDER BY size(allReviews) DESC
#LIMIT 10
fig = plt.figure()
fig.set_size_inches(10.5, 14.5)
fig.subplots_adjust(hspace=0.4, wspace=0.4)
with driver.session() as session:
params = { "city": "Vancouver", "category": "Hotels"}
result = session.run(query, params)
for index, row in enumerate(result):
business = row["business"]
stars = pd.Series(row["allReviews"])
#print(dir(stars))
total = stars.count()
#s = pd.concat([pd.Series(x['A']) for x in data]).astype(float)
s = pd.concat([pd.Series(row['allReviews'])]).astype(float)
average_stars = s.mean().round(2)
# Calculate the star distribution
stars_histogram = stars.value_counts().sort_index()
stars_histogram /= float(stars_histogram.sum())
# Plot a bar chart showing the distribution of star ratings
ax = fig.add_subplot(5, 2, index+1)
stars_histogram.plot(kind="bar", legend=None, color="darkblue",
title=f"{business}\nAve:{average_stars}, Total: {total}")
#print(business)
#print(stars)
plt.tight_layout()
plt.show()
Das Ergebnis sollte folgendermaßen aussehen: Die

X-Achse repräsentiert die Sternebewertung des Hotels und die Y-Achse repräsentiert den Gesamtprozentsatz jeder Bewertung.
Wie YELP-Dataset nützlich sein kann
Zu den Vorteilen gehören :
- ein inhaltlich ziemlich reichhaltiges Informationsfeld. Insbesondere können Sie einfach Bewertungen mit 1,0 oder 5,0 Sternen sammeln und jedes Unternehmen als Spam versenden. Hm. Ein wenig in die falsche Richtung, aber der Vektor ist klar;
- Der Datensatz ist groß, was zusätzliche angenehme Schwierigkeiten beim Testen der Leistung verschiedener Data Mining-Plattformen verursacht.
- Die präsentierten Daten haben eine gewisse Rückschau und im Prinzip ist es möglich zu verstehen, wie sich das Unternehmen verändert hat, basierend auf den Überprüfungen darüber.
- Die Daten können als Benchmark für Unternehmen verwendet werden, sofern Adressen verfügbar sind.
- Benutzer im Datensatz bilden häufig interessante miteinander verbundene Strukturen, die so genommen werden können, wie sie sind, ohne Benutzer zu einem künstlichen sozialen Umfeld zu formen. Netzwerk und nicht sammeln dieses Netzwerk von anderen bestehenden sozialen Netzwerken. Netzwerke.
Nachteile :
- Nur drei von 30 Ländern sind vertreten, und es besteht der Verdacht, dass dies nicht vollständig ist.
- Bewertungen werden 10 Jahre lang gespeichert, was die Merkmale eines bestehenden Unternehmens verzerren und häufig beeinträchtigen kann.
- Es gibt nur wenige Daten über Benutzer, sie sind unpersönlich, daher werden Empfehlungssysteme, die auf dem Datensatz basieren, eindeutig lahm.
- FRIENDS-Links verwenden gerichtete Grafiken, dh Anya ist Freunde -> Petja. Es stellt sich heraus, dass Petja nicht mit Anya befreundet ist. Dies kann programmgesteuert gelöst werden, ist aber immer noch unpraktisch.
- Der Datensatz ist "roh" angelegt und erfordert einen erheblichen Aufwand für die Vorverarbeitung.
Neo4j
Neo4j wird dynamisch aktualisiert und die neue Version der in Neo4j Desktop 1.4.5 verwendeten Benutzeroberfläche ist meiner Meinung nach nicht sehr praktisch. Insbesondere mangelt es an Klarheit hinsichtlich der Informationen über die Anzahl der Knoten und Links in der Datenbank, die in früheren Versionen vorhanden waren. Außerdem wurde die Benutzeroberfläche zum Navigieren durch die Registerkarten beim Arbeiten mit der Datenbank geändert, und Sie müssen sich auch daran gewöhnen.
Das Hauptproblem bei den Updates ist die Integration von Graph-Algorithmen in das Plugin der Graph Data Science Library. Sie wurden zuvor als neo4j-graph-Algorithmen bezeichnet .
Nach der Integration haben viele Algorithmen ihre Syntax erheblich geändert. Aus diesem Grund kann es schwierig sein, das Buch Graph Algorithms 2019 von O'REILLY zu studieren.
Yelp-Datenbank-Dump für neo4j - herunterladen...