In diesem letzten Beitrag geht es um die Varianzanalyse. Siehe den vorherigen Beitrag hier .
Varianzanalyse
Varianzanalyse (Varianz), die in der Fachliteratur auch als ANOVA aus dem Englischen bezeichnet wird. Die Analyse von VAriance ist eine Reihe statistischer Methoden, mit denen die statistische Signifikanz von Unterschieden zwischen Gruppen gemessen wird. Es wurde von dem äußerst begabten Statistiker Ronald Fisher entwickelt, der den statistischen Signifikanztest auch in seinen Forschungsarbeiten zu biologischen Tests populär machte.
Hinweis... In den vorherigen und dieser Reihe von Beiträgen wurde der Begriff „Varianz“ in unserem akzeptierten Begriff „Varianz“ verwendet, und der Begriff „Varianz“ wurde stellenweise in Klammern angegeben. Das ist kein Zufall. Im Ausland gibt es gepaarte Begriffe "Varianz" und "Kovarianz", und theoretisch sollten sie mit einer Wurzel übersetzt werden, zum Beispiel als "Varianz" und "Kovarianz", aber tatsächlich haben wir eine unterbrochene gepaarte Verbindung, und das sind sie übersetzt als völlig unterschiedliche "Varianz" und "Kovarianz". Aber das ist nicht alles. "Dispersion" (statistische Varianz) im Ausland ist ein separates generisches Konzept der Dispersion, d.h. Das Ausmaß, in dem sich die Verteilung ausdehnt oder zusammenzieht, und die Maße der statistischen Varianz sind Varianz, Standardabweichung und Interquartilbereich. Dispersion als generisches Konzept der Dispersion und Varianz als eine ihrer Maßnahmen,Die Messung des Abstands vom Mittelwert sind zwei verschiedene Konzepte. Weiter im Text für Varianz wird der allgemein akzeptierte Begriff "Varianz" durchgehend verwendet. Diese Diskrepanz in der Terminologie sollte jedoch berücksichtigt werden.
z- t- . , , , .
, . , .
, Seite für Seite und kombiniert")
, , . - . , , .
— . , , . , , .
F-
F- — .
— 1, — . k , n — , :


F- pandas plot
:
def ex_2_Fisher():
''' F- '''
mu = 0
d1_values, d2_values = [4, 9, 49], [95, 90, 50]
linestyles = ['-', '--', ':', '-.']
x = sp.linspace(0, 5, 101)[1:]
ax = None
for (d1, d2, ls) in zip(d1_values, d2_values, linestyles):
dist = stats.f(d1, d2, mu)
df = pd.DataFrame( {0:x, 1:dist.pdf(x)} )
ax = df.plot(0, 1, ls=ls,
label=r'$d_1=%i,\ d_2=%i$' % (d1,d2), ax=ax)
plt.xlabel('$x$\nF-')
plt.ylabel(' \n$p(x|d_1, d_2)$')
plt.show()

F- , 100 , 5, 10 50 .
F-
, , F-. F- , . F- :
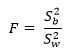
S2b — , S2w — .
F . , , . , , , .
F- , F. F .
F- . , . , k , x̅k, :

SSW — , xjk — j- .
SSW , Python, ssdev
, :
def ssdev( xs ):
'''
'''
mu = xs.mean()
square_deviation = lambda x : (x - mu) ** 2
return sum( map(square_deviation, xs) )
F- :

SST — , SSW — , . «» , :

, SST — - . Python SST SSW , .
ssw = sum( groups.apply( lambda g: ssdev(g) ) ) #
#
sst = ssdev( df['dwell-time'] ) #
ssb = sst – ssw #
F- . ssb
ssw
, F-.
Python F- :
msb = ssb / df1 #
msw = ssw / df2 #
f_stat = msb / msw
F- , F-.
F-
, , () , , .
scipy stats.f.sf
, . F- 20 , . , , F-. F-, F- F-, . f_test
, :
def f_test(groups):
m, n = len(groups), sum(groups.count())
df1, df2 = m - 1, n - m
ssw = sum( groups.apply(lambda g: ssdev(g)) )
sst = ssdev( df['dwell-time'] )
ssb = sst - ssw
msb = ssb / df1
msw = ssw / df2
f_stat = msb / msw
return stats.f.sf(f_stat, df1, df2)
def ex_2_24():
''' - F-'''
df = load_data('multiple-sites.tsv')
groups = df.groupby('site')['dwell-time']
return f_test(groups)
0.014031745203658217
F- p-, scipy stats.f.sf
, . P- , .. - . . 5%- .
p-, 0.014, .. . - , .

- , :
def ex_2_25():
'''
- '''
df = load_data('multiple-sites.tsv')
df.boxplot(by='site', showmeans=True)
plt.xlabel(' -')
plt.ylabel(' , .')
plt.title('')
plt.suptitle('')
plt.show()
boxplot
, -. - 0, .

, - 10 , . , , , , 6, 144 .:
def ex_2_26():
'''T- 0 10 -'''
df = load_data('multiple-sites.tsv')
groups = df.groupby('site')['dwell-time']
site_0 = groups.get_group(0)
site_10 = groups.get_group(10)
_, p_val = stats.ttest_ind(site_0, site_10, equal_var=False)
return p_val
0.0068811940138903786
F-, , - 6 :
def ex_2_27():
'''t- 0 6 -'''
df = load_data('multiple-sites.tsv')
groups = df.groupby('site')['dwell-time']
site_0 = groups.get_group(0)
site_6 = groups.get_group(6)
_, p_val = stats.ttest_ind(site_0, site_6, equal_var=False)
return p_val
0.005534181712508717
, , , - 6 -. AcmeContent -. - - !
, , . , — , . . , , .
d
d — , , , , . , :
Sab — ( ) . :
def pooled_standard_deviation(a, b):
'''
( )'''
return sp.sqrt( standard_deviation(a) ** 2 +
standard_deviation(b) ** 2)
, 6 - d :
def ex_2_28():
''' d
- 6'''
df = load_data('multiple-sites.tsv')
groups = df.groupby('site')['dwell-time']
a = groups.get_group(0)
b = groups.get_group(6)
return (b.mean() - a.mean()) / pooled_standard_deviation(a, b)
0.38913648705499848
p-, d . , , . 0.5, , , 0.38 — . - , -, .
, . , , z-, t- F-.
, , , . — , — . , , F- 1- 2- .
.
Wenn die Leser dies wünschen, werden wir in der nächsten Reihe von Beiträgen das Gelernte über Varianz und den F- Test auf einzelne Stichproben anwenden . Wir werden eine Regressionsanalysemethode vorstellen und sie verwenden, um Korrelationen zwischen Variablen in einer Stichprobe olympischer Athleten zu finden.