"Ich sehe nichts in ihr", sagte ich und gab den Hut an Sherlock Holmes zurück.
"Nein, Watson, siehst du, aber du nimmst dir nicht die Mühe, über das nachzudenken, was du siehst.
Arthur Conan Doyle. Blauer Karbunkel
In der vorherigen Reihe für Anfänger (erster Beitrag hier ) aus einem Remix von Henry Garners Buch Clojure for Data Science in Python wurden verschiedene numerische und visuelle Ansätze vorgestellt, um zu verstehen, was eine Normalverteilung ist. Wir haben verschiedene deskriptive Statistiken wie Mittelwert und Standardabweichung erörtert und erläutert, wie sie verwendet werden können, um große Datenmengen auf den Punkt zu bringen.
Ein Datensatz ist normalerweise eine Stichprobe einer größeren Bevölkerung oder einer allgemeinen Bevölkerung. Manchmal ist diese Population zu groß, um vollständig gemessen zu werden. Manchmal ist es in der Natur unermesslich, weil es unendlich groß ist oder weil es nicht direkt zugänglich ist. In jedem Fall sind wir gezwungen, auf der Grundlage der uns zur Verfügung stehenden Daten Schlussfolgerungen zu ziehen.
In dieser Serie mit 4 Beiträgen werden wir die statistischen Implikationen untersuchen, wie Sie über die einfache Beschreibung von Stichproben hinausgehen und stattdessen die Population beschreiben können, aus der sie stammen. Wir werden unser Maß an Vertrauen in die Schlussfolgerungen, die wir aus den Stichprobendaten ziehen, genauer untersuchen. Wir werden die Essenz eines robusten Ansatzes zur Lösung von Problemen auf dem Gebiet der Datenwissenschaft aufzeigen, nämlich das Testen statistischer Hypothesen, der nur Wissenschaftlichkeit in das Studium von Daten einbringt .
Darüber hinaus werden im Verlauf der Präsentation die mit der terminologischen Abweichung in der nationalen Statistik verbundenen Schwachstellen hervorgehoben, die manchmal die Bedeutung verschleiern und Konzepte ersetzen. Am Ende des letzten Beitrags können Sie für oder gegen die nächste Reihe von Beiträgen stimmen. Bis dann ...
, AcmeContent, .
AcmeContent
, , , AcmeContent . -, .
, AcmeContent - — . , -. , , - , - , AcmeContent , .
(dwell time)— , - , .
(bounce) — , — .
, , - - - - - - AcmeContent.
, : scipy, pandas matplotlib. pandas Excel, read_excel
. . pandas read_csv
, URL- .
- AcmeContent — - . :
ex_N_M, ex - example (), N - M - . . , .. - . , .
def load_data( fname ):
return pd.read_csv('data/ch02/' + fname, '\t')
def ex_2_1():
return load_data('dwell-times.tsv').head()
( Python Jupyter), , :
|
|
date |
dwell-time |
0 |
2015-01-01T00:03:43Z |
74 |
1 |
2015-01-01T00:32:12Z |
109 |
2 |
2015-01-01T01:52:18Z |
88 |
3 |
2015-01-01T01:54:30Z |
17 |
4 |
2015-01-01T02:09:24Z |
11 |
… |
… |
… |
, .
, dwell-time hist:
def ex_2_2():
load_data('dwell-times.tsv')['dwell-time'].hist(bins=50)
plt.xlabel(' , .')
plt.ylabel('')
plt.show()
:
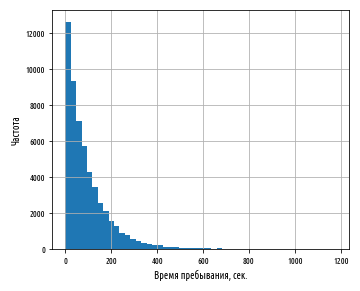
, ; . ( - 0 .). X , , .
, , , Y . , , . , « », . , , .
, , . , 10, , 5 10 4 . , — 30 10 20 . — .
Y logy=True
pandas plot.hist
:
def ex_2_3():
load_data('dwell-times.tsv')['dwell-time'].plot.hist(bins=20, logy=True)
plt.xlabel(' , .')
plt.ylabel(' ')
plt.show()
pandas , 10 . , , -. , - ( , loglog=True
).
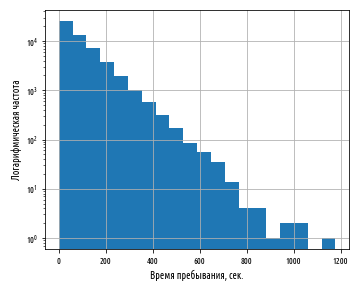
, — . , 10, , , .
— .
( ) , . , , , .
, — . , , . , — , -.
. :
def ex_2_4():
ts = load_data('dwell-times.tsv')['dwell-time']
print(': ', ts.mean())
print(': ', ts.median())
print(' :', ts.std())
: 93.2014074074074
: 64.0
: 93.96972402519819
. , . — .
.
( ). . , -, , , -, . 93 ., , 93 ., - .
, , - 93 . , , - 93 ., 5 . , .
x .
, . , ( ).
64 ., - . 93 . , . 6 . , . .
- . , , . Python, pandas — to_datetime.
, date-time, , , 1- Series
pandas , . , errors='ignore'
, . , mean_dwell_times_by_date
resample
. -, . 'D'
, mean
. , dt.resample('D').mean()
:
def with_parsed_date(df):
''' date date-time'''
df['date'] = pd.to_datetime(df['date'], errors='ignore')
return df
def filter_weekdays(df):
''' '''
return df[df['date'].index.dayofweek < 5] # ..
def mean_dwell_times_by_date(df):
''' '''
df.index = with_parsed_date(df)['date']
return df.resample('D').mean() #
def daily_mean_dwell_times(df):
''' - '''
df.index = with_parsed_date(df)['date']
df = filter_weekdays(df)
return df.resample('D').mean()
, :
def ex_2_5():
df = load_data('dwell-times.tsv')
mus = daily_mean_dwell_times(df)
print(': ', float(means.mean()))
print(': ', float(means.median()))
print(' : ', float(means.std()))
: 90.21042865056198
: 90.13661202185793
: 3.7223429053200348
90.2 . , , . , 3.7 . , , . :
def ex_2_6():
df = load_data('dwell-times.tsv')
daily_mean_dwell_times(df)['dwell-time'].hist(bins=20)
plt.xlabel(' , .')
plt.ylabel('')
plt.show()
:
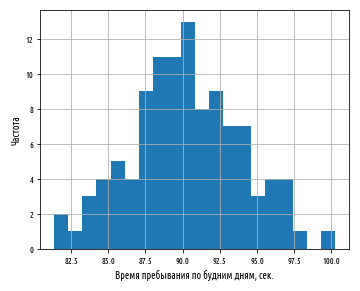
, 90 . 3.7 . , , .. , .
, . , , .
, , .
, - , — , , , . , , .
. , , . ( dropna, , ):
def ex_2_7():
''' '''
df = load_data('dwell-times.tsv')
means = daily_mean_dwell_times(df)['dwell-time'].dropna()
ax = means.hist(bins=20, normed=True)
xs = sorted(means) #
df = pd.DataFrame()
df[0] = xs
df[1] = stats.norm.pdf(xs, means.mean(), means.std())
df.plot(0, 1, linewidth=2, color='r', legend=None, ax=ax)
plt.xlabel(' , .')
plt.ylabel('')
plt.show()
:
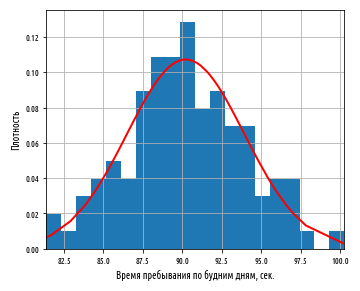
, , , 3.7 . , , 90 . , . 3.7 . — , , .
, (Standard Error, . SE) , , .
— .
, 6 . , , :

σx — , x, n — . , . . , — , :
def variance(xs):
''' () n <= 30'''
x_hat = xs.mean()
n = len(xs)
n = n-1 if n in range(1, 30) else n
square_deviation = lambda x : (x – x_hat) ** 2
return sum( map(square_deviation, xs) ) / n
def standard_deviation(xs):
return sp.sqrt(variance(xs))
def standard_error(xs):
return standard_deviation(xs) / sp.sqrt(len(xs))
:
. , , , .
, , , . , .
Das Thema des nächsten Beitrags, Beitrag Nr. 2 , wird der Unterschied zwischen Stichproben und der Population sowie das Konfidenzintervall sein. Ja, es ist das Konfidenzintervall , nicht das Konfidenzintervall.