Post # 3 für Anfänger widmet sich der Generierung von Verteilungen, ihren Eigenschaften und Diagrammen für ihre vergleichende Analyse.
Bäcker und Poincaré
Es gibt eine Legende, mit ziemlicher Sicherheit apokryphisch, die es ermöglicht, die Frage, wie der zentrale Grenzwertsatz es erlaubt, über das Prinzip der Bildung statistischer Verteilungen nachzudenken, genauer zu betrachten. Es handelt sich um den bekannten französischen Polymath Henri Poincaré aus dem 19. Jahrhundert, der der Legende nach jeden Tag ein Jahr damit verbracht hat, ein frisches Brot zu wiegen.
Zu dieser Zeit wurde das Backen vom Staat geregelt, und Poincaré stellte fest, dass die Ergebnisse des Wiegens von Brotlaiben zwar einer Normalverteilung entsprachen, der Höchstwert jedoch nicht bei den öffentlich beworbenen 1 kg lag, sondern bei 950 g. Er informierte die Behörden über die Bäcker, von dem er regelmäßig Brot kaufte, und er wurde bestraft. Das ist die Legende ;-).
Im folgenden Jahr wog Poincaré weiterhin Brote desselben Bäckers. Er fand heraus, dass der Mittelwert jetzt 1 kg betrug, die Verteilung jedoch nicht mehr symmetrisch zum Mittelwert war. Es wurde jetzt nach rechts verschoben. Dies stimmte mit der Tatsache überein, dass der Bäcker Poincaré nur noch das schwerste seiner Brote gab. Poincare meldete den Bäcker erneut bei den Behörden und der Bäcker wurde ein zweites Mal mit einer Geldstrafe belegt.
Ob es wirklich war oder nicht, ist hier nicht wichtig; Dieses Beispiel dient nur zur Veranschaulichung eines wichtigen Punktes: Die statistische Verteilung einer Folge von Zahlen kann uns etwas Wichtiges über den Prozess sagen, der sie erzeugt hat.
Verteilungen generieren
, , stats.norm.rvs. (rvs . normal variates, .. ). 1000, 1 . , 30.
def honest_baker(mu, sigma):
''' '''
return pd.Series( stats.norm.rvs(loc, scale, size=10000) )
def ex_1_18():
''' '''
honest_baker(1000, 30).hist(bins=25)
plt.xlabel(' ')
plt.ylabel('')
plt.show()
, :

, . ( « ») :
def dishonest_baker(mu, sigma):
''' '''
xs = stats.norm.rvs(loc, scale, size=10000)
return pd.Series( map(max, bootstrap(xs, 13)) )
def ex_1_19():
''' '''
dishonest_baker(950, 30).hist(bins=25)
plt.xlabel(' ')
plt.ylabel('')
plt.show()
, :
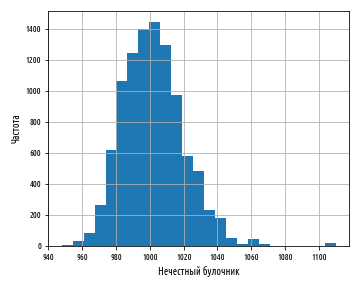
, , , . - 1 , . , .
. , , , . , , , .

pandas skew
:
def ex_1_20():
''' '''
s = dishonest_baker(950, 30)
return { '' : s.mean(),
'' : s.median(),
'': s.skew() }
{'': 0.4202176889083849,
'': 998.7670301469957,
'': 1000.059263920949}
, 0.4. , .
. , quantile
0 1 . 0.5- .
, . , -, Q-Q, . Q-Q plot. . , , . , .
. qqplot
, :
def qqplot( xs ):
''' ( -, Q-Q plot)'''
d = {0:sorted(stats.norm.rvs(loc=0, scale=1, size=len(xs))),
1:sorted(xs)}
pd.DataFrame(d).plot.scatter(0, 1, s=5, grid=True)
df.plot.scatter(0, 1, s=5, grid=True)
plt.xlabel(' ')
plt.ylabel(' ')
plt.title (' ', fontweight='semibold')
def ex_1_21():
'''
'''
qqplot( honest_baker(1000, 30) )
plt.show()
qqplot( dishonest_baker(950, 30) )
plt.show()
:

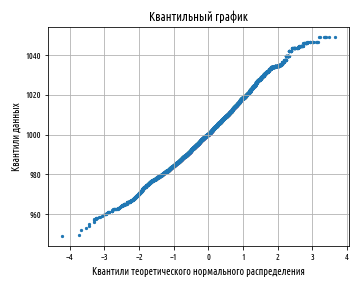
. :
, , , ; . , :

: , , , , ,
. ( ) .
() . , . , , .
, « », — , . :
def ex_1_22():
'''
'''
d = {' ' :honest_baker(1000, 30),
' ':dishonest_baker(950, 30)}
pd.DataFrame(d).boxplot(sym='o', whis=1.95, showmeans=True)
plt.ylabel(' (.)')
plt.show()
:

. — . — . , , . , .
. . , .
(), , . Cumulative Distribution Function (CDF), , , , x. , 0 1, 0 — , 1 — . , , . , 6?
5/6. , , , 1/6. — 50%.
, — , . , , , .
— . 0.5- 1000, 1000 0.5.
, pandas quantile
, empirical_cdf
0 1. , .. ( ) , , , , .
— , .
. pandas plot
, — — , . plot
, x y . pandas DataFrame
.
, plot
. pandas , . plot
, (ax
) plot
, (ax=ax
). . , . , (tp[1]
tp[3]
) , :
def empirical_cdf(x):
''' x'''
sx = sorted(x)
return pd.DataFrame( {0: sx, 1:sp.arange(len(sx))/len(sx)} )
def ex_1_23():
'''
'''
df = empirical_cdf(honest_baker(1000, 30))
df2 = empirical_cdf(dishonest_baker(950, 30))
ax = df.plot(0, 1, label=' ')
df2.plot(0, 1, label=' ', grid=True, ax=ax)
plt.xlabel(' ')
plt.ylabel('')
plt.legend(loc='best')
plt.show()
:
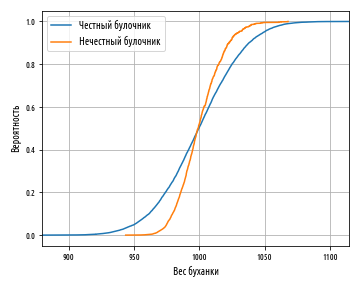
, -, , . , 0.5, 1000 . , .
, 4, «Python, » .