
Hallo Habr!
In diesem Artikel werden einige einfache Ansätze zur Vorhersage von Zeitreihen vorgestellt.
Das in dem Artikel vorgestellte Material ergänzt meiner Meinung nach die erste Woche des Kurses "Angewandte Probleme der Datenanalyse" von MIPT und Yandex. Auf dem angegebenen Kurs können Sie theoretisches Wissen erwerben, das ausreicht, um die Probleme der Vorhersage der Reihe von Dynamiken zu lösen. Als praktische Konsolidierung des Materials wird vorgeschlagen, das ARIMA- Modell der Scipy- Bibliothek zu verwenden, um eine Gehaltsprognose in russischer Sprache zu erstellen Föderation für das kommende Jahr. In dem Artikel werden wir auch eine Gehaltsprognose erstellen, aber gleichzeitig werden wir nicht die Scipy- Bibliothek , sondern die Bibliothek verwenden sklearn . Der Trick ist, dass scipy bereits ein ARIMA- Modell hat , aber sklearn kein fertiges Modell hat, also müssen wir hart mit Stiften arbeiten. Um das Problem in gewissem Sinne zu lösen, müssen wir also herausfinden, wie das Modell von innen funktioniert. Als zusätzliches Material wird in dem Artikel das Vorhersageproblem unter Verwendung eines einschichtigen neuronalen Netzwerks der Pytorch- Bibliothek gelöst .
Der gesamte Code ist in Python 3 im Jupyter-Notizbuch geschrieben . Darüber hinaus ist das Notebook so konzipiert, dass Sie anstelle von Daten zu Löhnen viele andere Dynamikreihen ersetzen können, z. B. Daten zu Zuckerpreisen, die Prognose-, Validierungs- und Schulungsdauer ändern, andere externe Faktoren hinzufügen und eine angemessene Prognose. Mit anderen Worten, in der Arbeit wird ein einfacher selbstgeschriebener Simulator verwendet, mit dessen Hilfe verschiedene Dynamikreihen vorhergesagt werden können. Der Code kann hier eingesehen werden
Artikelübersicht
- Kurze Beschreibung des Simulators.
- Eine direkte Lösung besteht darin, Zeitreihen nur mit "Rohdaten" vergangener Zeitreihenwerte vorherzusagen.
- Hinzufügen exogener Variablen.
- Korrektur der Heteroskedastizität durch den Logarithmus der Anfangsdaten.
- Bringen Sie die Reihe zu einer stationären.
- Vorhersage mit einem einschichtigen neuronalen Netzwerk.
- Vergleich der Ansätze.
- Nützliche Links
Kurze Beschreibung des Simulators
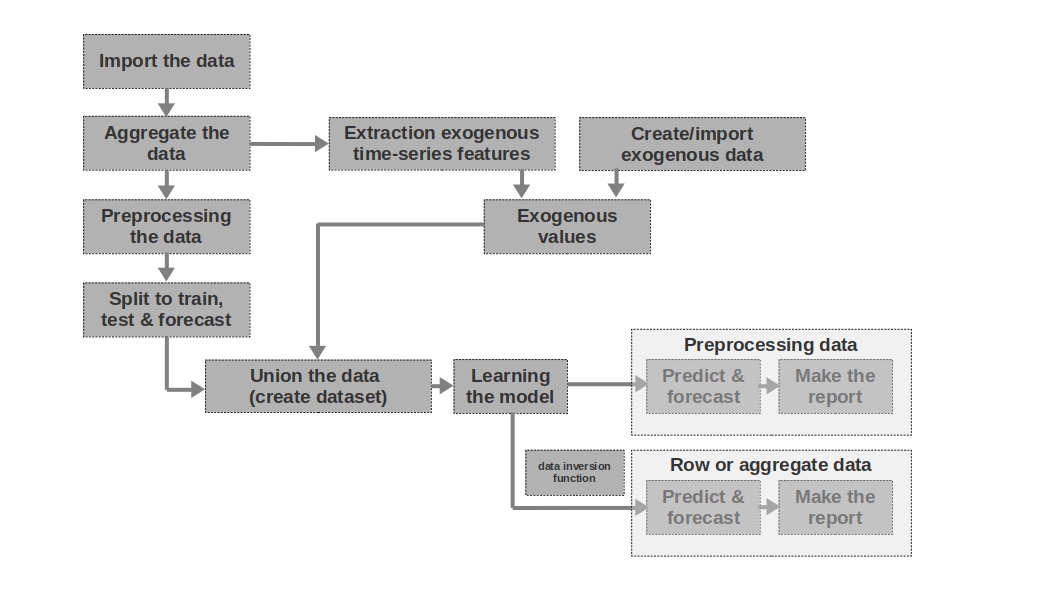
Daten
importieren Hier ist alles einfach - wir importieren die Daten. Manchmal reichen Rohdaten aus, um eine mehr oder weniger verständliche Prognose zu erstellen. Es sind die ersten und zweiten Prognosen im Artikel, die auf der Grundlage von Rohdaten modelliert werden, dh Rohdaten zu Löhnen in vergangenen Perioden werden zur Prognose von Löhnen verwendet.
Aggregieren Sie die Daten
Der Artikel verwendet keine Datenaggregation, da dies nicht erforderlich ist. Daten können jedoch häufig in ungleichen Zeitintervallen dargestellt werden. In diesem Fall müssen Sie sie nur aggregieren. Beispielsweise müssen Daten aus dem Handel mit Wertpapieren, Währungen und anderen Finanzinstrumenten aggregiert werden. Normalerweise wird der Durchschnittswert im Intervall genommen, aber auch die maximale, minimale, Standardabweichung und andere Statistiken sind möglich.
Vorverarbeitung der Daten
In unserem Fall handelt es sich hauptsächlich um die Datenvorverarbeitung, aufgrund derer die Zeitreihen die Eigenschaft der Homoskedastizität (durch den Logarithmus der Daten) erwerben und stationär werden (durch die Differenzierung der Reihen).
Aufteilen, um zu trainieren, zu testen und zu prognostizieren
In diesem Codeblock wird die Zeitreihe in Trainings-, Test- und Prognoseperioden unterteilt, indem eine neue Spalte mit den entsprechenden Werten "Zug", "Test", "Prognose" hinzugefügt wird. Das heißt, wir erstellen nicht drei separate Tabellen für jeden Zeitraum, sondern fügen einfach eine Spalte hinzu, auf deren Grundlage wir die Daten weiter aufteilen.
Extraktion exogener Zeitreihenmerkmale
Es kann nützlich sein, zusätzliche externe (exogene) Merkmale aus einer Zeitreihe zu isolieren. Geben Sie beispielsweise an, ob es ein freier Tag ist oder nicht, geben Sie die Anzahl der Tage in einem Monat (oder die Anzahl der Arbeitstage in einem Monat) usw. an. In der Regel werden diese Zeichen aus der Zeitreihe "herausgezogen" selbst ohne manuellen Eingriff.
Exogene Daten erstellen / importieren
Nicht alle Informationen können aus der Zeitreihe „abgerufen“ werden. Manchmal sind zusätzliche externe Daten erforderlich. Zum Beispiel einige episodische Ereignisse, die einen starken Einfluss auf die Werte der Zeitreihen haben. Solche Ereignisse können die Daten des Beginns von Feindseligkeiten, der Verhängung von Sanktionen, Naturkatastrophen usw. sein. Die Arbeit berücksichtigt solche Faktoren nicht, aber die Möglichkeit ihrer Verwendung sollte berücksichtigt werden.
Exogene Werte
In diesem Codeblock kombinieren wir alle exogenen Daten in einer Tabelle.
Daten
vereinen (Datensatz erstellen) In diesem Codeblock kombinieren wir die Werte der Zeitreihen und der exogenen Merkmale in einer Tabelle. Mit anderen Worten, wir bereiten einen Datensatz vor, auf dessen Grundlage wir das Modell trainieren, die Qualität testen und eine Prognose erstellen.
Modell lernen Hier ist
alles klar - wir trainieren nur das Modell.
Vorverarbeitungsdaten: Vorhersagen und Prognosen
Wenn wir vorverarbeitete Daten zum Trainieren des Modells verwendet haben (logarithmisch, verarbeitet durch die Box-Coke-Funktion, stationäre Reihen usw.), wird die Qualität des Modells zuerst anhand der vorverarbeiteten Daten bewertet und nur dann auf die "Rohdaten". Wenn wir die Daten nicht vorverarbeitet haben, wird diese Phase übersprungen.
Zeilendaten: Vorhersagen & Prognosen
Diese Phase ist die letzte. Wenn das Modell beispielsweise auf vorverarbeiteten Daten trainiert wurde, haben wir diese prologisiert. Um die Lohnprognose in Rubel und nicht den Logarithmus der Rubel zu erhalten, sollten wir die Prognose wieder in Rubel übersetzen.
Ich möchte auch darauf hinweisen, dass der Artikel eine eindimensionale Zeitreihe verwendet, um die Löhne vorherzusagen. Nichts hindert Sie jedoch daran, eine mehrdimensionale Reihe zu verwenden, z. B. Daten zum Wechselkurs des Rubels zum Dollar oder einer anderen Reihe hinzuzufügen.
Entscheidung in der Stirn
Wir gehen davon aus, dass die Daten zu den Löhnen in der Vergangenheit die Löhne in der Zukunft annähern können. Mit anderen Worten, die Höhe der Löhne, zum Beispiel im Januar, hängt davon ab, wie hoch die Löhne im Dezember, November, Oktober usw. waren.
Nehmen wir die Lohnwerte der letzten 12 Monate, um die Löhne im 13. Monat vorherzusagen. Mit anderen Worten, für jeden Zielwert haben wir 12 Merkmale.
Die Zeichen werden dem Ridge Regression-Eingang der sklearn-Bibliothek zugeführt. Wir nehmen die Standardparameter des Modells, mit Ausnahme des Alpha-Parameters, der auf 0 gesetzt wurde, dh wir verwenden tatsächlich die reguläre Regression.
Dies ist eine unkomplizierte Lösung - es ist die einfachste :) Es gibt Situationen, in denen Sie zumindest dringend einige Ergebnisse liefern müssen, aber es bleibt einfach keine Zeit für eine Vorverarbeitung oder es gibt nicht genügend Erfahrung, um Daten schnell zu verarbeiten oder hinzuzufügen. In solchen Situationen können Sie Rohdaten als Basis für die Erstellung einer Prognose verwenden. Mit Blick auf die Zukunft stelle ich fest, dass die Qualität des Modells mit der Qualität von Modellen vergleichbar ist, die Datenvorverarbeitung verwenden.
Mal sehen, was wir haben.
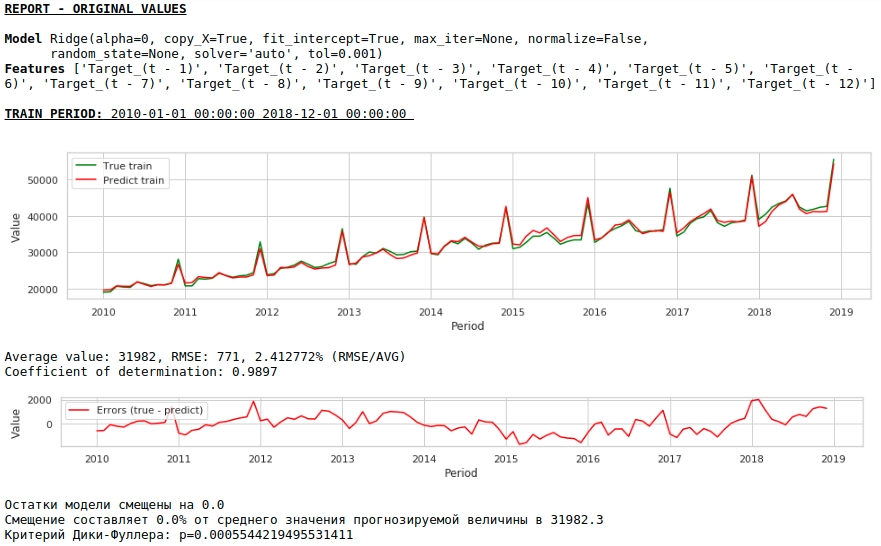
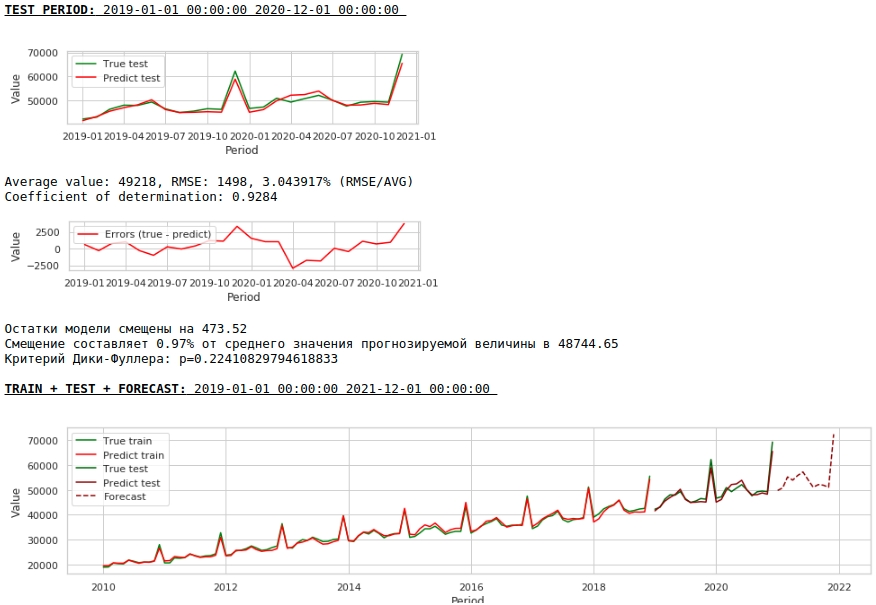
Auf den ersten Blick sieht das Ergebnis zwar unvollkommen, aber realitätsnah aus.
Entsprechend den Werten der Regressionskoeffizienten hat der Wert des Gehalts vor genau einem Jahr den größten Einfluss auf die Lohnprognose.
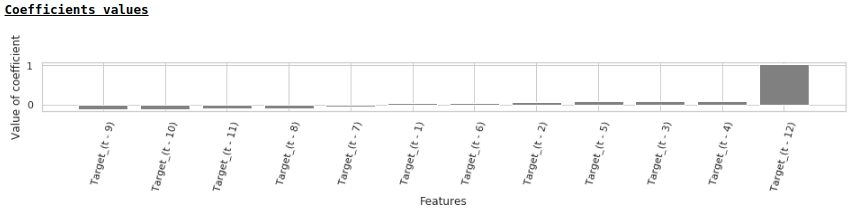
Versuchen wir, dem Modell exogene Variablen hinzuzufügen.
Hinzufügen exogener Variablen
Wir werden 2 externe Zeichen verwenden: die Anzahl der Tage in einem Monat und die Anzahl des Monats (von 1 bis 12). Wir binärisieren das Attribut "Monatszahl", als Ergebnis erhalten wir 12 Spalten für jeden Monat mit Werten von 0 oder 1.
Bilden wir einen neuen Datensatz und betrachten die Qualität des Modells.
Charts anschauen
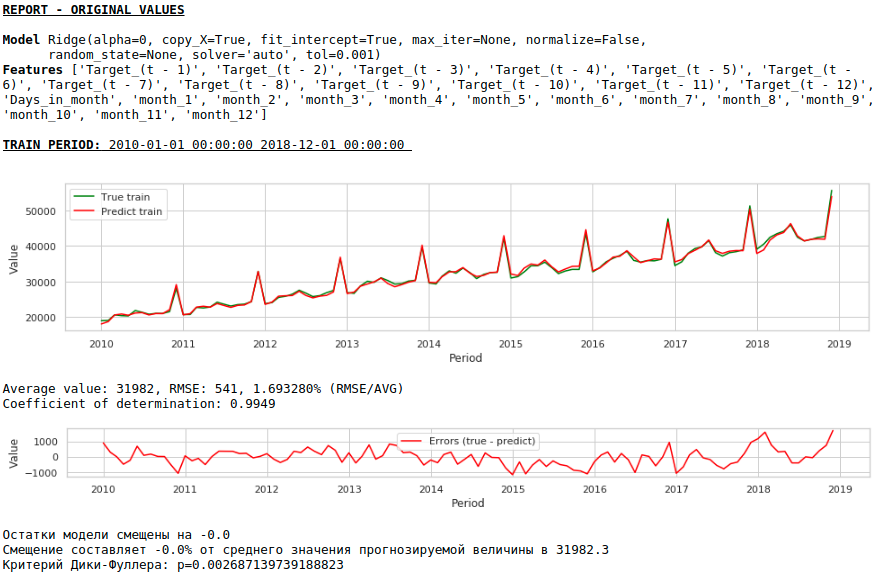
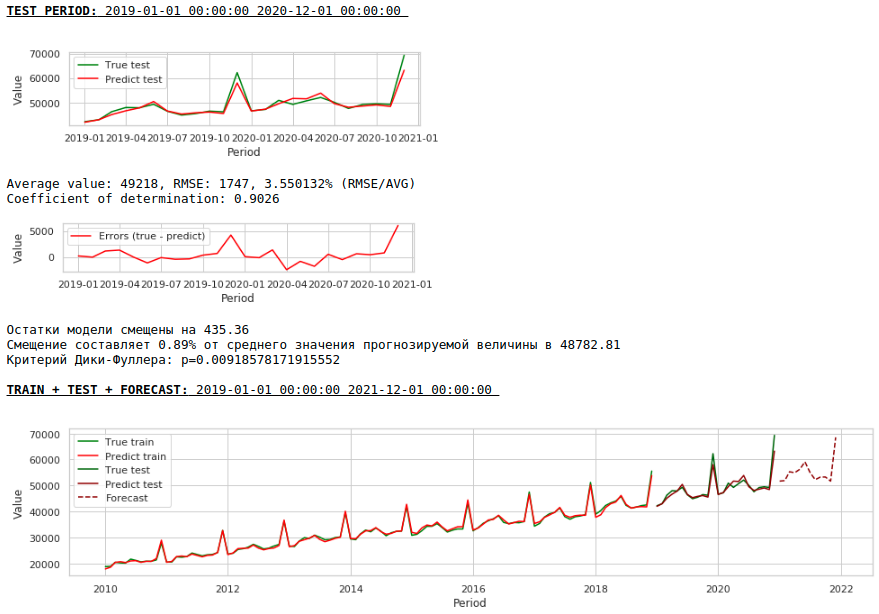
Die Qualität ist geringer. Optisch fällt auf, dass die Prognose hinsichtlich des Lohnwachstums im Dezember nicht ganz plausibel erscheint.
Lassen Sie uns nun die erste Datenvorverarbeitung durchführen.
Korrektur der Heteroskedastizität.
Wenn wir uns das Lohndiagramm für den Zeitraum von 2010 bis 2020 ansehen, können wir sehen, dass die Verteilung der Löhne innerhalb des Jahres zwischen den Monaten jedes Jahr zunimmt.
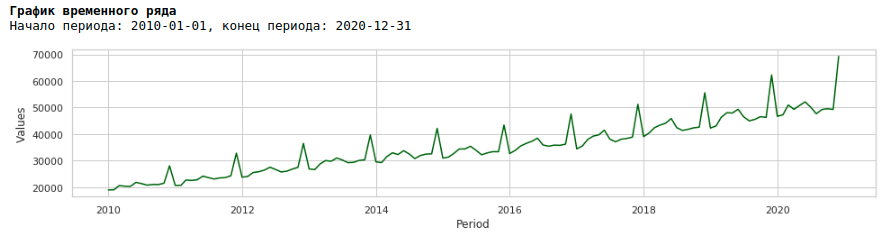
Eine jährliche Zunahme der Varianz von Monat zu Monat führt zu Heteroskedastizität. Um die Qualität der Prognose zu verbessern, sollten wir diese Eigenschaft der Daten entfernen und sie zur Homoskedastizität bringen.
Dazu verwenden wir den üblichen Logarithmus und sehen, wie die logarithmische Reihe aussieht.
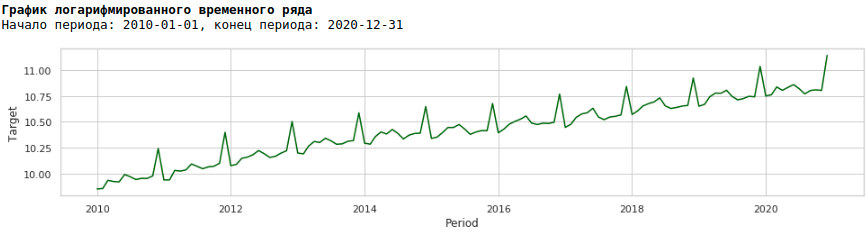
Lassen Sie uns das Modell auf der logarithmischen Reihe trainieren
Charts anschauen
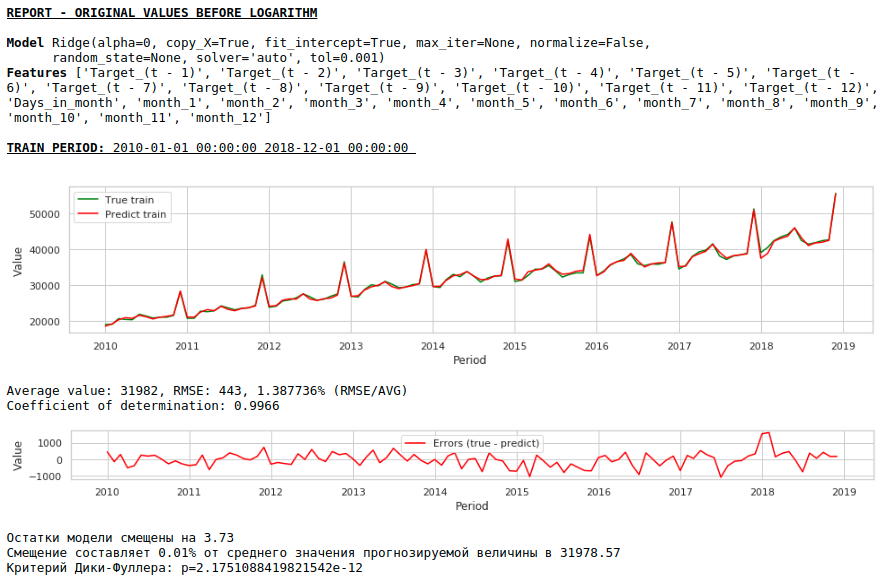
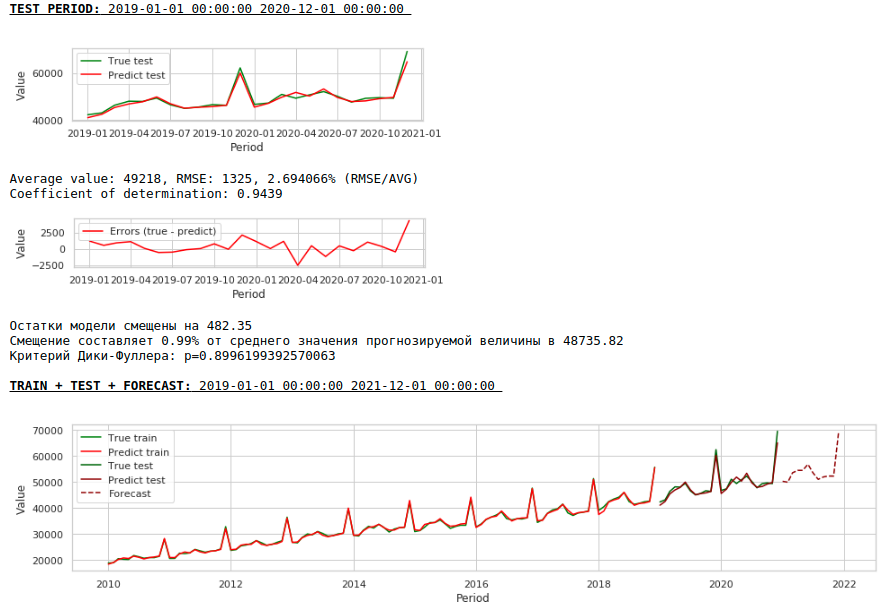
Infolgedessen hat sich die Qualität der Vorhersagen für die Trainings- und Testmuster verbessert. Die Vorhersage für 2021 erscheint jedoch optisch weniger plausibel als die Vorhersage des ersten Modells. Höchstwahrscheinlich verschlechtert die Verwendung exogener Faktoren das Modell.
Bringen Sie eine Reihe zu einem stationären
Wir werden die Serie wie folgt auf eine stationäre reduzieren:
- Bestimmen Sie die Differenz zwischen dem Zielgehalt und dem Wert vor einem Jahr: t - (t-12) = dif_1
- Bestimmen Sie die Differenz zwischen dem empfangenen und dem um 1 Monat verschobenen Wert: dif_1 - (dif_1-1) = dif_2
Als Ergebnis erhalten wir die folgenden Zeitreihen.
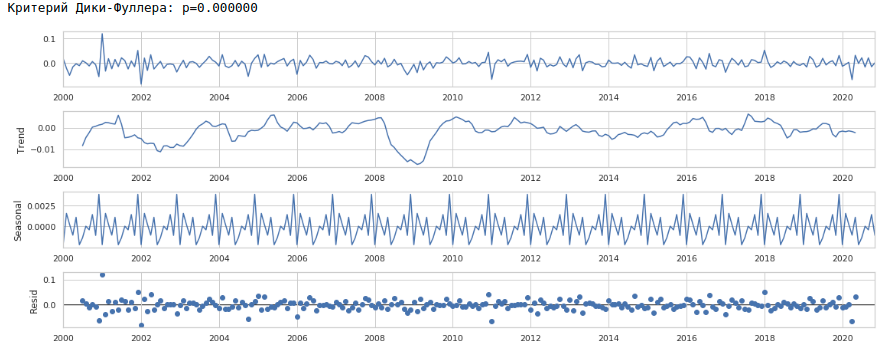
Die Serie sieht wirklich stationär aus, dies wird auch durch den Wert des Dickey-Fuller-Kriteriums angezeigt.
Es ist nicht erforderlich, eine gute Qualität der Vorhersagen für die Trainings- und Testproben für die verarbeiteten Daten zu erwarten, dh für eine stationäre Serie, da das Modell in diesem Fall tatsächlich die Werte des weißen Rauschens vorhersagen sollte. Um die Löhne vorherzusagen, ist es für uns jedoch überhaupt nicht erforderlich, eine Regression zu verwenden, da wir durch Reduzieren der Reihe auf eine stationäre Zahl in einfachen Worten eine Formel zur Approximation der Zielvariablen festgelegt haben. Aber wir werden nicht von den Kanonen abweichen und ein Regressionsmodell verwenden, außerdem haben wir exogene Faktoren.
Lass uns nachsehen, was passiert ist.
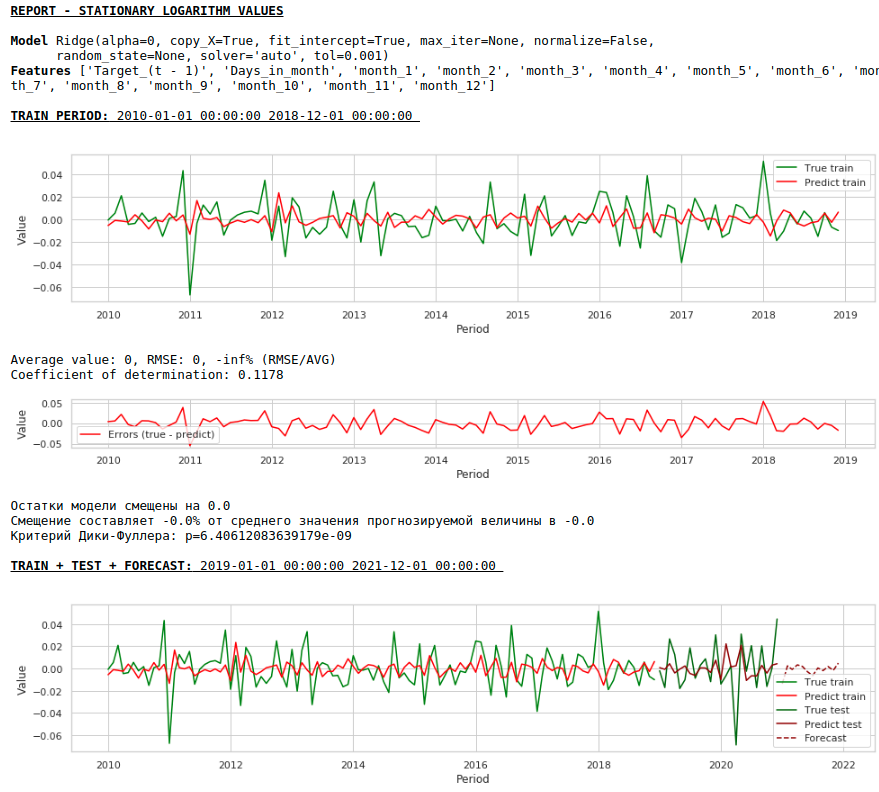
So sieht die Vorhersage einer stationären Serie aus. Wie erwartet - nicht sehr gut :)
Und hier ist die Vorhersage und Prognose der Löhne.
Charts anschauen
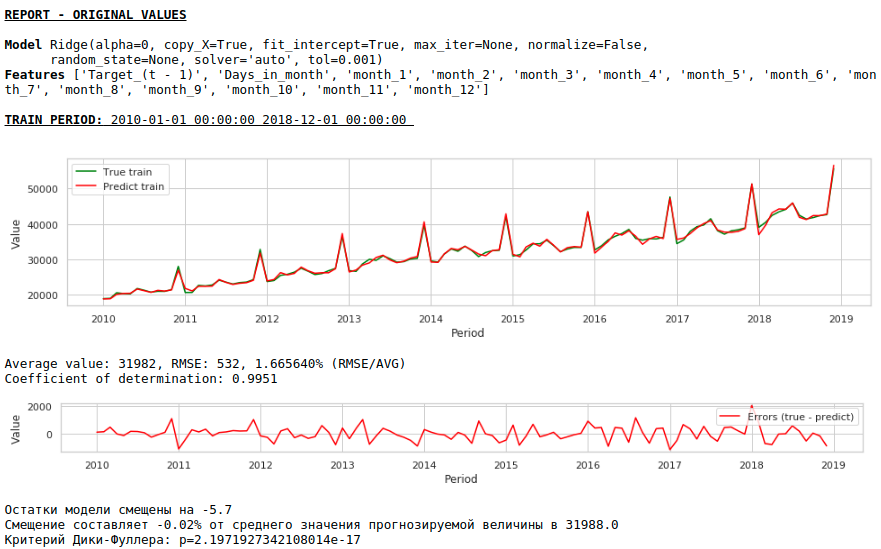
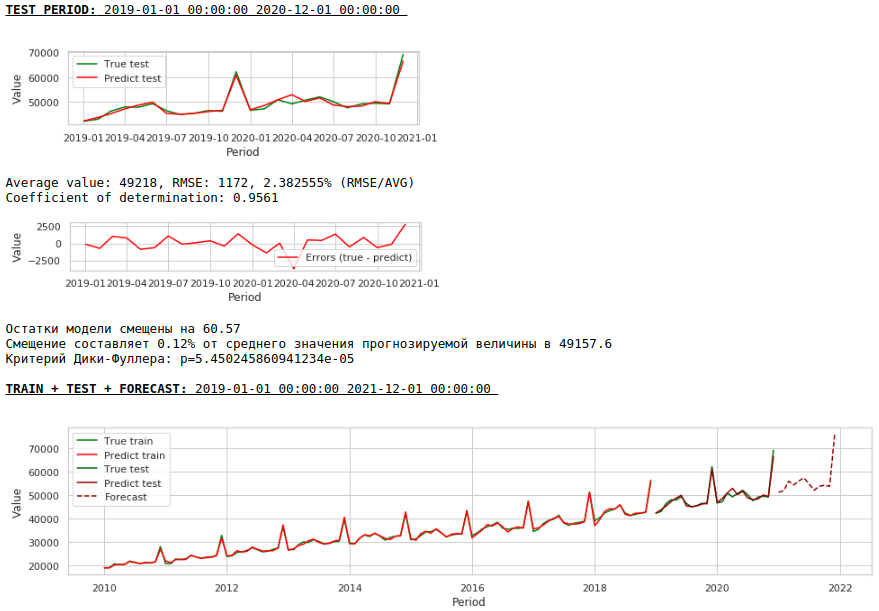
Die Qualität hat sich deutlich verbessert und die Prognose ist visuell glaubwürdig.
Lassen Sie uns nun eine Prognose erstellen, ohne exogene Variablen zu verwenden.
Charts anschauen
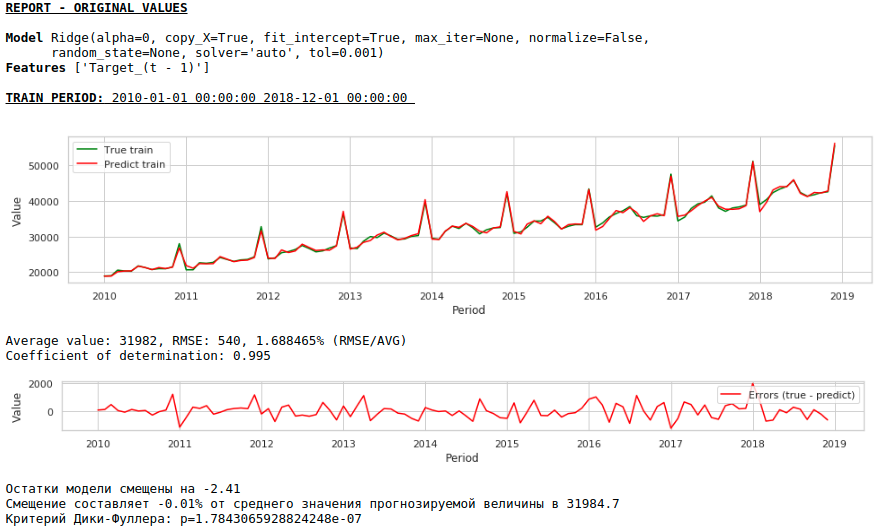
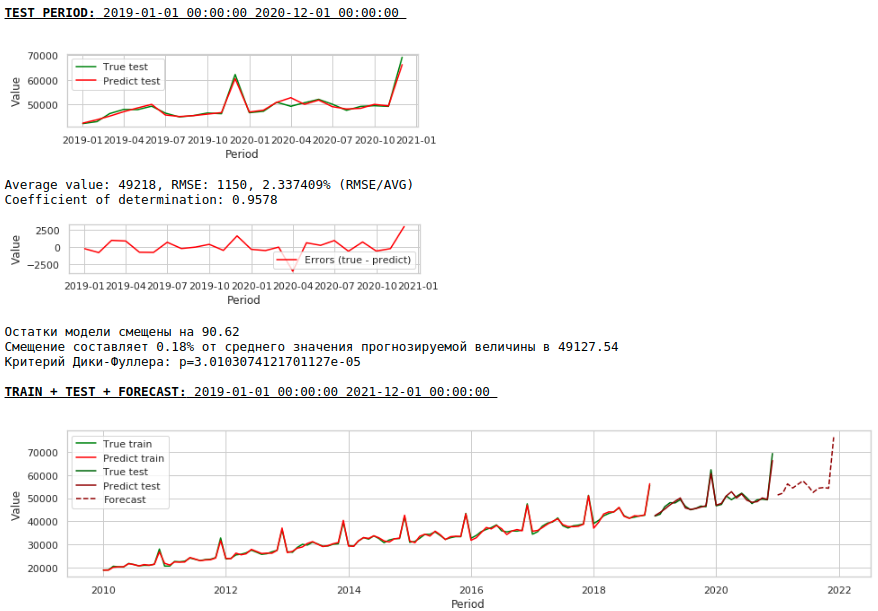
Die Qualität hat sich weiter verbessert und die Plausibilität der Prognose bleibt erhalten :)
Vorhersage mit einem einschichtigen neuronalen Netzwerk
Wir werden die vorhandenen Datensätze in die Eingabe des neuronalen Netzwerks einspeisen. Da unser Netzwerk einschichtig ist, handelt es sich tatsächlich um dieselbe lineare Regression mit einfachen Änderungen, und Sie sollten keinen sehr großen Unterschied in der Qualität der Vorhersagen erwarten.
Schauen wir uns zunächst das Netzwerk selbst an.
Siehe den Code
class Model_1(nn.Module):
def __init__(self, input_size, output_size):
super(Model_1, self).__init__()
self.input_size = input_size
self.output_size = output_size
self.linear = nn.Linear(self.input_size, self.output_size)
def forward(self, x):
output = self.linear(x)
return output
Nun ein paar Worte darüber, wie wir sie trainieren werden.
- Wir legen einen zufälligen Startwert fest, um das Ergebnis reproduzierbar zu machen
- Modell initialisieren
- Verlustfunktion einstellen - MSELoss
- Auswahl des Adam-Optimierers als Optimierer
- Wir geben den ersten Trainingsschritt an und bestimmen die Bedingung, unter der der Schritt abgesenkt wird. Beachten Sie, dass die richtige Auswahl eines Schritts und seine weitere Änderung (normalerweise eine Verringerung) gute Ergebnisse bringt.
- Geben Sie die Anzahl der Lernepochen an
- Wir fangen an zu trainieren
- Wir liefern den gesamten Datensatz an den Netzwerkeingang, da dieser sehr klein ist und es keinen Sinn macht, ihn in Stapel aufzuteilen
- Während des Trainings bilden wir alle tausend Epochen Diagramme des Wertes der Verlustfunktion auf den Trainings- und Testproben. Dies ermöglicht es uns, die Überanpassung oder Nichtumschulung des Modells zu kontrollieren.
Unten finden Sie den Code zum Trainieren des Netzwerks für den ersten Datensatz. Für jeden Datensatz haben sich die Parameter geringfügig geändert: die Anzahl der Trainingsepochen und der Trainingsschritt.
Siehe den Code
# fix the random seed
SEED = 42
random_init(SEED)
# initialization model, loss function, optimizator
model = Model_1(len(features),1)
loss_func = nn.MSELoss()
opt = torch.optim.Adam(model.parameters(), lr=5e-2)
# set the epoch numbers, initialization list for every loss after learning on epoch
epochs = 15000
losses_train = []
losses_test = []
# initialization counter for calculation epoch numbers
counter = 0
# start the learning model
for epoch in range(epochs):
model.train()
# make prediction targets on train data
y_pred_train = model(torch.tensor(X_train.to_numpy(), dtype=torch.float))
# calculate loss
loss = loss_func(y_pred_train,
torch.reshape(torch.tensor(y_train.to_numpy(), dtype=torch.float),(-1,1)))
# bacward loss to model and calculate new parameters (coefficients) with fixed learning rate
loss.backward()
opt.step()
opt.zero_grad()
# add loss to list losses
losses_train.append(loss)
model.eval()
y_pred_test = model(torch.tensor(X_test.to_numpy(), dtype=torch.float))
loss_test = loss_func(y_pred_test,
torch.reshape(torch.tensor(y_test.to_numpy(), dtype=torch.float),(-1,1)))
losses_test.append(loss_test)
# make the mini report for every 1000 epoch
if epoch % 1000 == 0 and epoch > 0:
print ('Epoch:', epoch // 1000)
print ('Learning rate:', opt.param_groups[0]['lr'])
print ('Last loss on TRAIN data:', losses_train[-1].cpu().detach().numpy(),
' Last loss on TEST data:', losses_test[-1].cpu().detach().numpy())
# print ('Last loss on TEST data:', losses_test[-1].cpu().detach().numpy())
fig, (ax1, ax2) = plt.subplots(1, 2)
# fig.suptitle('MSE on TRAIN & TEST DATA')
fig.set_figheight(3)
fig.set_figwidth(12)
ax1.plot(np.arange(counter,epoch,1), np.array([float(i) for i in losses_train][-1000:]), color = 'darkred')
plt.xlabel("Epoch")
plt.ylabel("Loss on TRAIN data")
ax2.plot(np.arange(counter,epoch,1), np.array([float(i) for i in losses_test][-1000:]), color = 'darkred')
plt.xlabel("Epoch")
plt.ylabel("Loss on TEST data")
plt.show()
counter += 1000
# reduce learning rate
if epoch == 1000:
opt = torch.optim.Adam(model.parameters(), lr=7e-3)
Wir werden die Qualität der Vorhersagen für jeden Datensatz nicht separat betrachten (diejenigen, die dies wünschen, können die Details auf der Gita sehen). Vergleichen wir die Endergebnisse.
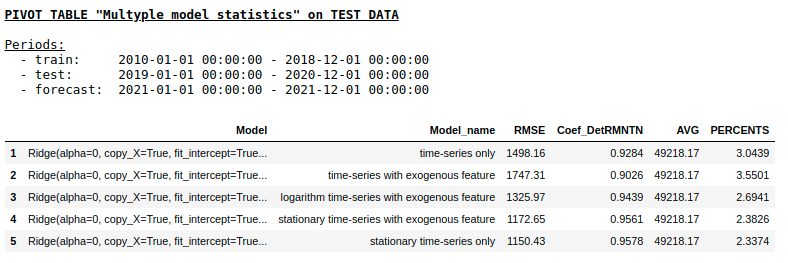
Qualität einer Testprobe mit Ridge Regression
Qualität einer Testprobe mit Single Layer NN
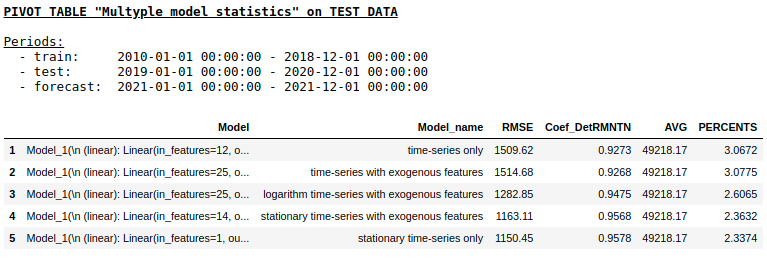
Wie wir erwartet hatten, gab es keinen grundlegenden Unterschied zwischen der regulären Regression und einem einfachen einschichtigen neuronalen Netzwerk. Natürlich bieten Neuronen mehr Lernmanöver: Sie können Optimierer ändern, Lernschritte anpassen, verborgene Ebenen und Aktivierungsfunktionen verwenden, Sie können noch weiter gehen und wiederkehrende neuronale Netze (RNNs) verwenden. Persönlich konnte ich mit RNN bei diesem Problem keine vernünftige Qualität erzielen. Im Internet finden Sie jedoch viele interessante Beispiele für die Vorhersage von Zeitreihen mit LSTM.
Zu diesem Zeitpunkt endete der Artikel. Ich hoffe, dass das Material als eine Art Überblick über die in der Vorhersage von Zeitreihen verwendeten Basisansätze nützlich ist und als praktische Ergänzung zum Kurs "Angewandte Probleme der Datenanalyse" von MIPT und Yandex dient.