
Ich bin sicher, dass die meisten Leser mit den Begriffen "Unicode" und "UTF-8" zumindest ein wenig vertraut sind. Aber weiß jeder, was genau dahinter steckt? Im Wesentlichen beziehen sie sich auf Zeichenkodierungsstandards, die auch als Zeichensätze bezeichnet werden. Das Konzept erschien in den Tagen des optischen Telegraphen und nicht im Computerzeitalter, wie man meinen könnte. Bereits im 18. Jahrhundert bestand die Notwendigkeit einer schnellen Informationsübertragung über große Entfernungen, für die die sogenannten Telegraphencodes verwendet wurden. Die Informationen wurden mit optischen, elektronischen und anderen Mitteln codiert.
In den Hunderten von Jahren, die seit der Erfindung des ersten Telegraphencodes vergangen sind, gab es keinen wirklichen Versuch, solche Codierungsschemata international zu standardisieren. Selbst in den frühen Jahrzehnten des Teletyp- und Heimcomputerzeitalters änderte sich wenig. Während EBCDIC (IBMs 8-Bit-Zeichenkodierung, die auf einer Lochkarte in der Kopfzeile dargestellt ist) und ASCII die Dinge ein wenig verbesserten, gab es immer noch keine Möglichkeit, eine wachsende Sammlung von Zeichen ohne signifikante Speichernutzung zu kodieren.
Die Entwicklung von Unicode begann Ende der 1980er Jahre, als der zunehmende Austausch digitaler Informationen weltweit die Notwendigkeit eines einzigen Codierungssystems dringlicher machte. Heutzutage können wir mit Unicode ein einziges Kodierungsschema für alles verwenden, vom englischen Grundtext über traditionelles Chinesisch, Vietnamesisch, sogar Maya bis hin zu den Piktogrammen, die wir Emojis nannten.
Vom Code zu Grafiken
In den Tagen des Römischen Reiches war bekannt, dass die schnelle Übermittlung von Informationen wichtig ist. Für eine lange Zeit bedeutete dies die Anwesenheit von Boten zu Pferd, die Nachrichten über große Entfernungen oder deren Äquivalente übermittelten. Die Verbesserung des Informationslieferungssystems wurde bereits im 4. Jahrhundert v. Chr. Erfunden - so entstanden ein Wassertelegraph und ein System von Signallichtern. Aber erst im 18. Jahrhundert wurde die Datenübertragung über große Entfernungen wirklich effektiv.
Über den optischen Telegraphen, auch "Semaphor" genannt, haben wir bereits in einem Artikel über die Geschichte der optischen Kommunikation geschrieben. Es bestand aus einer Reihe von Relaisstationen, die jeweils mit einem Blinkersystem zur Anzeige von Telegraphencodesymbolen ausgestattet waren. Das System der Brüder Chappe, das zwischen 1795 und 1850 von den französischen Truppen verwendet wurde, basierte auf einer Holzstange mit zwei beweglichen Enden (Hebeln), die sich jeweils in eine von sieben Positionen bewegen konnten. Zusammen mit den vier Positionen für die Querlatte könnte das Semaphor theoretisch 196 Zeichen (4x7x7) anzeigen. In der Praxis wurde die Anzahl auf 92-94 Positionen reduziert.
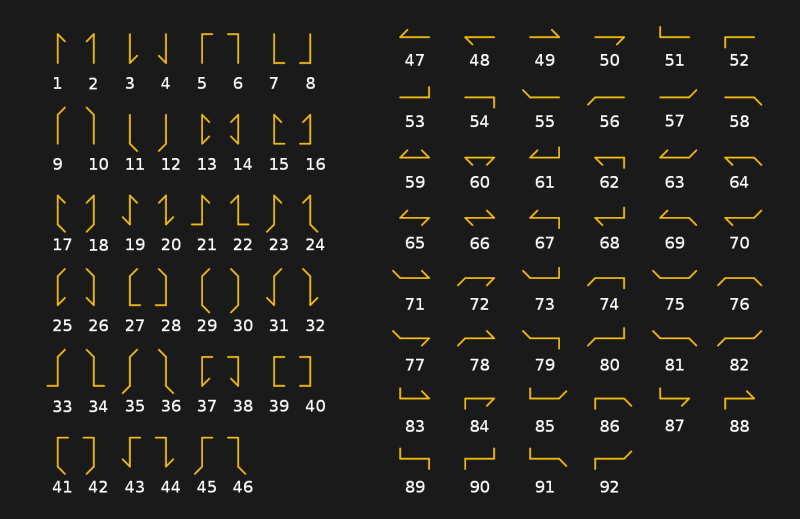
Das Semaphorsystem wurde weniger zum direkten Codieren von Zeichen als vielmehr zum Bezeichnen bestimmter Zeichenfolgen in einem Codebuch verwendet. Das Verfahren implizierte, dass es möglich war, die gesamte Nachricht unter Verwendung mehrerer Codesignale zu entschlüsseln. Dies beschleunigte die Übertragung und machte das Abfangen von Nachrichten bedeutungslos.
Leistungsverbesserung
Dann wurde der optische Telegraph durch einen elektrischen ersetzt. Dies bedeutete, dass die Zeiten vorbei waren, in denen Codierungen von Personen erfasst wurden, die den nächsten Relaisturm beobachteten. Mit zwei durch einen Metalldraht verbundenen Telegraphengeräten wurde elektrischer Strom zum Instrument zur Informationsübertragung. Diese Änderung führte zu neuen elektrischen Telegraphencodes, und der Morsecode wurde schließlich seit seiner Erfindung in Deutschland im Jahr 1848 zu einem internationalen Standard (mit Ausnahme der Vereinigten Staaten, die weiterhin amerikanischen Morsecode außerhalb der Funktelegraphie verwendeten).
Internationaler Morsecode hat einen Vorteil gegenüber seinem amerikanischen Gegenstück: Er verwendet mehr Striche als Punkte. Dieser Ansatz verlangsamt die Übertragungsgeschwindigkeit, verbessert jedoch den Nachrichtenempfang am anderen Ende der Leitung. Dies war notwendig, wenn lange Nachrichten von Betreibern mit unterschiedlichen Fähigkeiten über kilometerlange Kabel übertragen wurden.
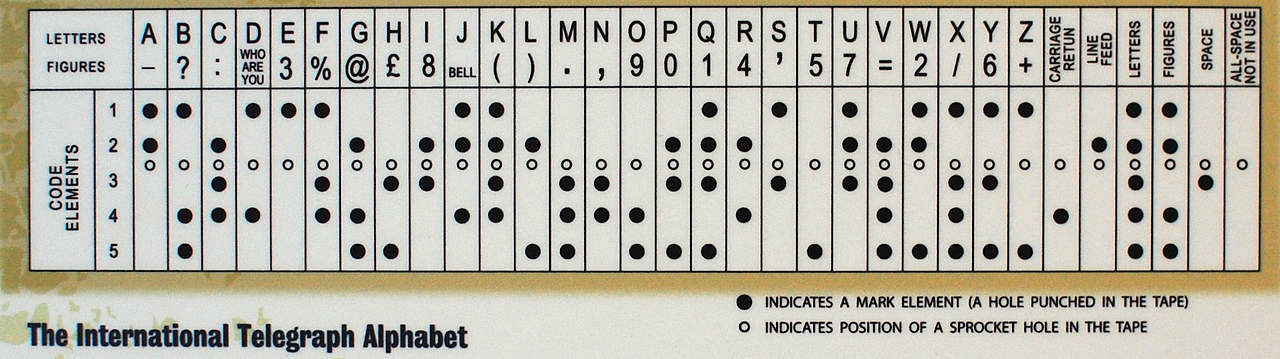
Mit der Entwicklung der Technologie wurde der manuelle Telegraph im Westen durch einen automatischen ersetzt. Es wurde der 5-Bit-Baudot-Code sowie der daraus abgeleitete Murray-Code verwendet (letzterer basierte auf der Verwendung von Papierband, in das Löcher gestanzt wurden). Murrays System ermöglichte es, ein Band mit Nachrichten im Voraus vorzubereiten und es dann in ein Lesegerät zu laden, damit die Nachricht automatisch übertragen werden kann. Der Baudot-Code bildete die Grundlage für das International Telegraphic Alphabet Version 1 (ITA 1), und der modifizierte Baudot-Murray-Code bildete die Grundlage für ITA 2, das bis in die 1960er Jahre verwendet wurde.
In den 1960er Jahren war die Beschränkung auf 5 Bit pro Zeichen nicht mehr erforderlich, was zur Entwicklung von 7-Bit-ASCII in den USA und Standards wie JIS X 0201 (für japanische Katakana-Zeichen) in Asien führte. In Kombination mit Teletypewritern, die damals weit verbreitet waren, ermöglichte dies die Übertragung ziemlich komplexer Nachrichten, einschließlich Groß- und Kleinbuchstaben.
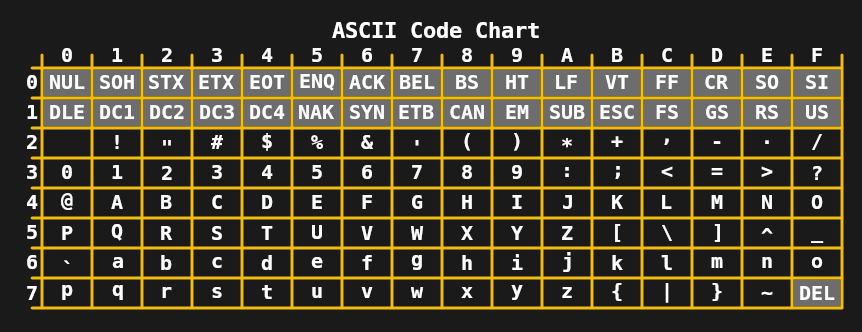
In den 1970er und frühen 1980er Jahren waren die Einschränkungen von 7- und 8-Bit-Codierungen wie erweitertem ASCII (wie ISO 8859-1 oder Latin 1) für die gängigen Heimcomputer und Büroanforderungen ausreichend. Trotzdem war der Verbesserungsbedarf klar, da häufige Aufgaben wie der Austausch digitaler Dokumente und Texte bei den vielen ISO 8859-Codierungen häufig zu Chaos führten. Der erste Schritt wurde 1991 mit 16-Bit-Unicode 1.0 unternommen.
Entwicklung von 16-Bit-Codierungen
Überraschenderweise gelang es Unicode in nur 16 Bit, nicht nur alle westlichen Schriftsysteme abzudecken, sondern auch viele chinesische Schriftzeichen und viele Sonderzeichen, die beispielsweise in der Mathematik verwendet werden. Mit 16 Bit, die bis zu 65.536 Codepunkte zulassen, konnte Unicode 1.0 problemlos 7.129 Zeichen aufnehmen. Zum Zeitpunkt der Veröffentlichung von Unicode 3.1 im Jahr 2001 enthielt es jedoch mindestens 94.140 Zeichen.
In seiner 13. Version enthält Unicode jetzt insgesamt 143.859 Zeichen ohne Steuerzeichen. Ursprünglich sollte Unicode nur zum Codieren der derzeit verwendeten Notationssysteme verwendet werden. Mit der Veröffentlichung von Unicode 2.0 im Jahr 1996 wurde jedoch klar, dass dieses Ziel überdacht werden musste, um selbst seltene und historische Zeichen zu kodieren. Um dies ohne die obligatorische 32-Bit-Codierung jedes Zeichens zu erreichen, hat sich Unicode geändert: Es ermöglichte nicht nur die direkte Codierung von Zeichen, sondern auch die Verwendung ihrer Komponenten oder Grapheme.
Das Konzept ähnelt etwas Vektorbildern, bei denen nicht jedes Pixel angegeben wird, sondern die Elemente, aus denen das Bild besteht, beschrieben werden. Infolgedessen unterstützt die UTF-8-Codierung (Unicode Transformation Format 8) 2 31 Codepunkt, wobei die meisten Zeichen im aktuellen Unicode-Zeichensatz normalerweise ein oder zwei Bytes erfordern.
Unicode für jeden Geschmack und jede Farbe
An diesem Punkt sind wahrscheinlich einige Leute durch die verschiedenen Begriffe verwirrt, die verwendet werden, wenn es um Unicode geht. Daher ist es wichtig zu beachten, dass sich Unicode auf den Standard bezieht und die verschiedenen Unicode-Transformationsformate Implementierungen davon sind. UCS-2 und USC-4 sind ältere 2- und 4-Byte-Implementierungen von Unicode, wobei UCS-4 mit UTF-32 identisch ist und UCS-2 UTF-16 ersetzt.
UCS-2, als früheste Form von Unicode, gelangte in den 1990er Jahren in viele Betriebssysteme und machte den Übergang zu UTF-16 zur am wenigsten gefährlichen Option. Aus diesem Grund verwenden Windows und MacOS, Fenstermanager wie KDE sowie die Java- und .NET-Laufzeiten UTF-16 intern.
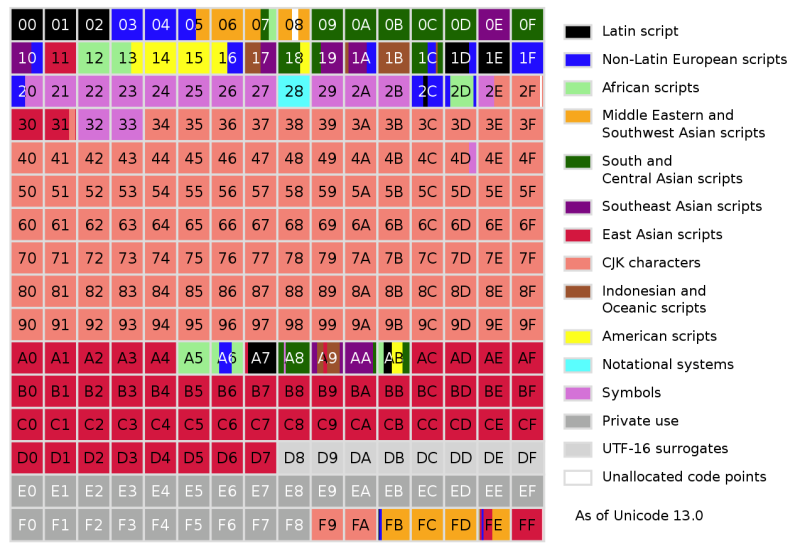
UTF-32, codiert, wie der Name schon sagt, jedes Zeichen in vier Bytes. Es ist ein bisschen verschwenderisch, aber völlig vorhersehbar. Das gleiche UTF-8-Zeichen kann ein Zeichen im Bereich von einem bis vier Bytes codieren. Im Fall von UTF-32 ist das Bestimmen der Anzahl von Zeichen in einer Zeichenfolge eine einfache Arithmetik: Nehmen Sie die gesamte Anzahl von Bytes und dividieren Sie durch vier. Dies hat zu Compilern und einigen Sprachen wie Python geführt, die es UTF-32 ermöglichen, Unicode-Zeichenfolgen darzustellen.
Von allen Unicode-Formaten ist UTF-8 jedoch bei weitem das beliebteste. Dies wurde weitgehend durch das World Wide Web erleichtert, wo die meisten Websites ihre HTML-Dokumente in UTF-8-Codierung bereitstellen. Aufgrund des Layouts der verschiedenen Ebenen von Codepunkten in UTF-8 passen Western und viele andere gängige Schriftsysteme in zwei Bytes. Im Vergleich zu den alten ISO 8859- und Shift JIS-Codierungen nimmt der gleiche Text in UTF-8 nicht mehr Platz ein als zuvor.
Von optischen Türmen zum Internet
Die Zeiten der Pferdeboten, Relaistürme und kleinen Telegraphenstationen sind vorbei. Die Kommunikationstechnologie hat sich stark weiterentwickelt. Selbst die Zeiten, in denen Teletypen in Büros üblich waren, sind schwer zu merken. In jeder Phase der Entwicklung der Geschichte musste die Menschheit jedoch Informationen verschlüsseln, speichern und übertragen. Und dies führte uns zu dem Punkt, an dem wir jetzt sofort eine Nachricht in einem Symbolsystem auf der ganzen Welt übertragen können, das unabhängig von Ihrem Standort entschlüsselt werden kann.
Für diejenigen, die zufällig zwischen ISO 8859-Codierungen in E-Mail-Clients und Webbrowsern gewechselt haben, um etwas zu erhalten, das der ursprünglichen Textnachricht ähnelt, war die Unicode-Unterstützung ein Segen. Ich kann diese Leute verstehen. Wenn 7-Bit-ASCII (oder EBCDIC) die unbestrittene Technologie war, war es manchmal notwendig, Stunden damit zu verbringen, die symbolische Verwirrung eines digitalen Dokuments zu beseitigen, das von einem europäischen oder amerikanischen Büro empfangen wurde.
Auch wenn Unicode nicht ohne Probleme ist, ist es schwer, nicht dankbar zu sein, wenn man es mit dem vergleicht, was es früher war. Hier sind sie, 30 Jahre Unicode.
