
Sehr oft wird die Verwendung von vorgefertigten Werkzeugen in der Entwicklung zu einer suboptimalen Lösung. So ist es bei uns passiert. Um Datenpipelines zu verwalten, haben wir uns entschlossen, unser eigenes System zu entwickeln - Wombat. Wir werden Ihnen sagen, was daraus geworden ist und was uns die Weigerung, die fertige Lösung zu verwenden, gebracht hat.
Warum wir unser eigenes System entwickeln
Es ist nicht naheliegend, ein eigenes Datenpipeline-Managementsystem zu erstellen. Heute gibt es viele vorgefertigte Lösungen, die das Problem lösen können: Airflow, MLflow, Kubeflow, Luigi und viele andere. Wir haben mit vielen dieser Systeme experimentiert und sind zu dem Schluss gekommen, dass keines von ihnen zu uns passt.
Betrachten Sie beispielsweise die häufigste Lösung - den Luftstrom. Es kombiniert sechs Hauptblöcke: eine API zur Beschreibung von Pipelines, einen Wokflow-Kollektor, ein Control Panel und Schnittstellen, einen Taskplaner und einen Task-Orchestrator und schließlich die Überwachung von Airflow-Komponenten. Für die Verwaltung von Pipelines reichte diese Funktionalität in unserem Fall jedoch nicht aus.
Für uns waren Funktionen wie die Integration des Pipeline-Management-Systems in das Build-System und CI, die Integration in Kubernetes, die Fähigkeit zur Verwaltung von Artefakten und die Datenvalidierung von entscheidender Bedeutung.

Wir haben herausgefunden, was es uns kosten würde, die Funktionalität des fertigen Systems auf das erforderliche Niveau zu bringen, und haben erkannt, dass es viel einfacher und schneller sein würde, unser eigenes System zu entwickeln. Wir haben es Wombat genannt - weil das Tier sehr süß ist und zweitens, weil es als Retter der australischen Natur gilt. Und für uns wäre ein System, das es uns ermöglicht, Entwicklung und alle Phasen der Arbeit mit Daten zu kombinieren, auch eine echte Rettung.
Welche Probleme haben wir gelöst?
In unserem Entwicklungsteam unterstützen die DevOps-Ingenieure in der Vergangenheit Dienstleistungen in der Produktion. Und sie sind es gewohnt, mit Pipelines zu arbeiten, die nicht durch Code, sondern durch Konfigurationen in Formaten wie yaml beschrieben werden. Aufgrund dieser Diskrepanz müssen Sie entweder den Support teilen oder Ingenieure für die Arbeit mit einem nicht klassischen kontinuierlichen Integrationssystem schulen.
All dies wäre redundante und unnötige Arbeit, da Pipelines in Form von gerichteten azyklischen Graphen in dem Format, das in Standard-CI- und DevOps-Tools verwendet wird, perfekt beschrieben werden.

Das zweite Problem war die Speicherung und Versionierung von Artefakten. Durch die Arbeit mit Artefakten im Datenpipeline-Managementsystem erhalten Sie zwei sehr nützliche Möglichkeiten: Wiederverwenden der Ergebnisse der Arbeit mit Pipelines und Reproduzieren von Experimenten mit Daten, wodurch Zeit für die Organisation neuer Experimente gespart wird.
Wenn die Organisation des Speicherns von Artefakten nicht automatisiert ist, überschreiben früher oder später neue Artefakte alte oder auf Produktionsmaschinen geht der freie Speicherplatz zur Neige. Darüber hinaus muss die Produktion spezielle Anforderungen erfüllen, um die Zuverlässigkeit und Fehlertoleranz des Speichers sicherzustellen, was ein weiterer kostspieliger Prozess ist.
Daher wollten wir eine Lösung finden, die alle Aufgaben im Zusammenhang mit der Verwaltung von Pipelines im Hintergrund ausführt und es Datenspezialisten ermöglicht, mit Artefakten aus anderen Projekten zu arbeiten und gleichzeitig nicht an die Kosten der Datenspeicherung zu denken.
Das dritte Problem ist die Eingabe von Datenströmen. Ja, mit Python können Sie Prototypen entwickeln und verschiedene Hypothesen mit hoher Geschwindigkeit testen. Wenn Sie jedoch mit Daten arbeiten, müssen Sie auf die Typen achten, mit denen Sie arbeiten, wenn Sie keine unerwarteten Überraschungen wünschen. Um die Anzahl solcher Probleme in der Produktion zu verringern, benötigen wir Unterstützung bei der Beschreibung von Datenschemata bis hin zur Beschreibung von Datenrahmenschemata. Die Datentypisierung sollte für die Entwicklung und für die Produktion getrennt erfolgen.
Was ist am Ende passiert
Herkömmlicherweise kann die Wombat-Architektur folgendermaßen dargestellt werden:

Dieses Diagramm zeigt die Rolle des Systems. Es ist eine Zwischenschicht zwischen der Beschreibung von Pipelines und dem CI-System, mit deren Hilfe Sie in der Produktion mit ihnen arbeiten können.
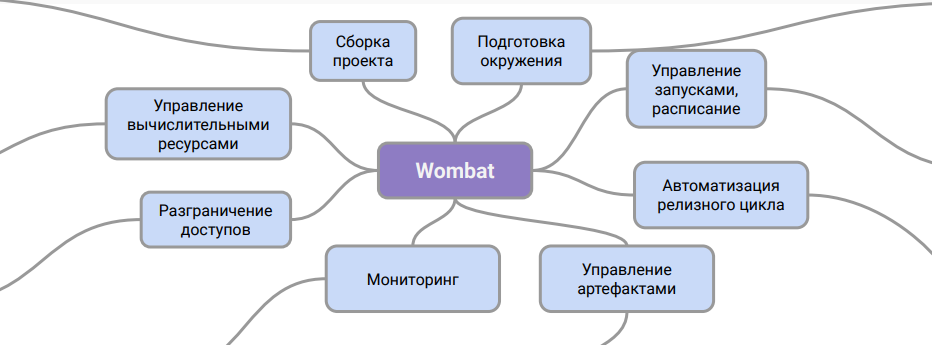
Dank dieses Arbeitsschemas können wir den Support für Pipelines in der DevOps-Abteilung organisieren, ohne zusätzliche Schulungen für Ingenieure und ohne Einbeziehung von Datenspezialisten in diesen Prozess. Außerdem ist das Problem beim Speichern von Datenartefakten und deren Versionierung gelöst.
Jetzt entwickeln wir Funktionen, die es ermöglichen, das Tool in einer für Data Scientists typischen Form in die frühe Phase des Prototyping und Experimentierens einzuführen, was den Start von Projekten in Pilot- und Produktionsphase erheblich beschleunigen wird.
Wir bereiten uns darauf vor, dieses Tool in naher Zukunft als Open Source zu veröffentlichen. Wir würden uns freuen, wenn Sie uns Ihre Meinung zu unserem Projekt und Ihre Erfahrungen mit modernen Datenpipelinesystemen mitteilen würden.
Da dieser Artikel eher informativer als technischer Natur ist, planen wir in naher Zukunft die Erstellung eines detaillierteren Hardcore-Textes. Schreiben Sie in die Kommentare, was Sie sehen und in technischer Hinsicht herausfinden möchten. Wir werden berücksichtigen, beschreiben und schreiben. Vielen Dank für Ihre Aufmerksamkeit!
PS Wir sind immer noch an talentierten Programmierern interessiert. Komm, es wird interessant sein !