Es ist normalerweise nicht üblich, über solche Fehler zu sprechen, da in allen Integratoren nur sündlose, himmlische Menschen arbeiten. Wie Sie wissen, gibt es auf DNA-Ebene keine Möglichkeit, falsch oder falsch zu liegen.
Aber ich werde es riskieren. Ich hoffe, meine Erfahrung wird jemandem nützlich sein. Wir haben einen Hauptkunden, den Online-Einzelhandel, für den wir die Cisco ACI-Fabrik voll unterstützen. Das Unternehmen verfügt nicht über einen eigenen Administrator, der für dieses System zuständig ist. Eine Netzwerkstruktur ist eine Gruppe von Switches mit einem einzigen Kontrollzentrum. Außerdem gibt es eine Reihe nützlicher Funktionen, auf die der Hersteller sehr stolz ist, aber am Ende benötigen Sie einen Administrator, nicht Dutzende, um alles fallen zu lassen. Und ein Kontrollzentrum, nicht Dutzende von Konsolen.
Die Geschichte beginnt folgendermaßen: Der Kunde möchte den Kern des gesamten Netzwerks auf diese Gruppe von Switches übertragen. Diese Entscheidung beruht auf der Tatsache, dass die ACI-Architektur, in der diese Gruppe von Switches "gesammelt" wird, sehr fehlertolerant ist. Obwohl dies nicht typisch ist und im Allgemeinen, wird eine Fabrik in einem Rechenzentrum nicht als Transitnetzwerk für andere Netzwerke verwendet und dient nur zum Verbinden der Endlast (Stub-Netzwerk). Aber ein solcher Ansatz ist durchaus möglich, also will der Kunde - wir machen es.
Dann passierte eine banale Sache - ich verwechselte zwei Schaltflächen: Löschen der Richtlinie und Löschen der Konfiguration eines Fragmentes des Netzwerks:
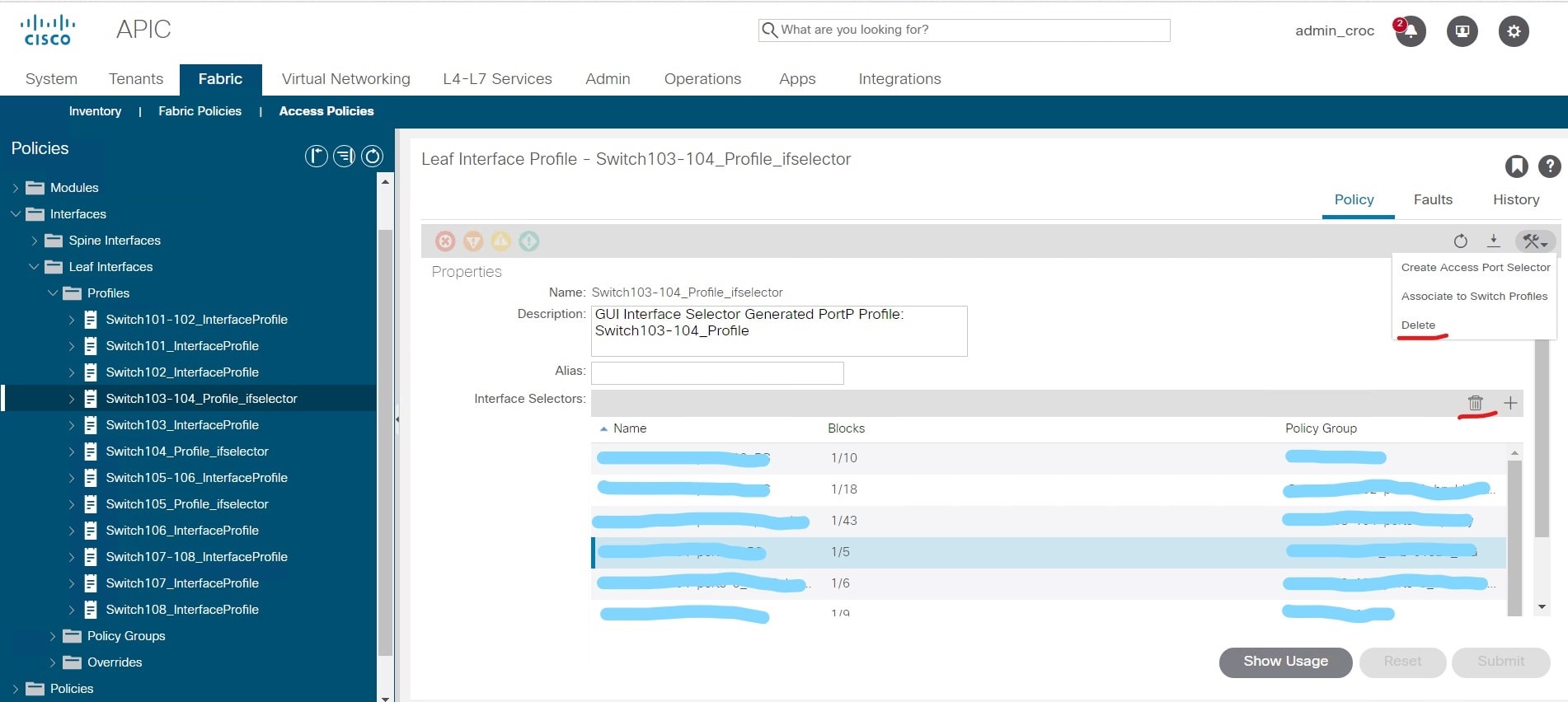
Nun, laut den Klassikern war es notwendig, einen Teil des zusammengebrochenen Netzwerks wieder zusammenzusetzen.
In Ordnung
Die Anfrage des Kunden klang folgendermaßen: Es war notwendig, separate Portgruppen für den Transfer von Geräten direkt zu dieser Fabrik zu erstellen.
Kollegen, übertragen Sie bitte die Einstellungen der Ports Blatt 1-1 101 und Blatt 1-2 102, Port 43 und 44, auf Blatt 1-3 103 und Blatt 1-4 104, Port 43 und 44. Zu den Ports 43 und 44 auf Blatt 1- 1 und 1-2 ist der 3650-Stack angeschlossen, er wurde noch nicht in Betrieb genommen, Sie können die Porteinstellungen jederzeit übertragen.
Das heißt, sie wollten den Servercluster übertragen. Es war erforderlich, eine neue virtuelle Portgruppe für die Serverumgebung zu konfigurieren. Tatsächlich ist dies eine Routineaufgabe, für eine solche Aufgabe gibt es normalerweise keine Ausfallzeiten. Im Wesentlichen ist eine Portgruppe in der APIC-Terminologie eine VPC, die aus Ports zusammengesetzt ist, die sich physisch auf verschiedenen Switches befinden.
Das Problem ist, dass die Einstellungen dieser Portgruppen im Werk an eine separate Entität gebunden sind (was darauf zurückzuführen ist, dass das Werk vom Controller aus gesteuert wird). Dieses Objekt wird als Portrichtlinie bezeichnet. Das heißt, für die Gruppe von Ports, die wir hinzufügen, müssen wir auch eine allgemeine Richtlinie von oben als Entität anwenden, die diese Ports verwaltet.
Das heißt, es war notwendig zu analysieren, welche EPGs an den Ports 43 und 44 auf den Knoten 101 und 102 verwendet werden, um eine ähnliche Konfiguration auf den Knoten 103-104 zusammenzustellen. Nachdem ich die notwendigen Änderungen analysiert hatte, begann ich mit der Konfiguration der Knoten 103-104. Um eine neue VPC in der vorhandenen Schnittstellenrichtlinie für die Knoten 103 und 104 zu konfigurieren, musste eine Richtlinie erstellt werden, in die die Schnittstellen 43 und 44 eingebracht werden.
Und es gibt eine Nuance in der GUI. Ich habe diese Richtlinie erstellt und festgestellt, dass ich während des Konfigurationsprozesses einen kleinen Fehler gemacht habe - ich habe sie anders benannt als beim Kunden. Dies ist nicht kritisch, da die Richtlinie neu ist und nichts beeinflusst. Und ich musste diese Richtlinie löschen, da keine Änderungen mehr daran vorgenommen werden können (der Name ändert sich nicht) - Sie können die Richtlinie nur löschen und neu erstellen.
Das Problem ist, dass die GUI über Löschsymbole verfügt, die auf Schnittstellenrichtlinien verweisen, und dass es Symbole gibt, die auf Switch-Richtlinien verweisen. Optisch sind sie fast identisch. Und anstatt die von mir erstellte Richtlinie zu löschen, habe ich die gesamte Konfiguration für die Schnittstellen auf den Switches 103-104 gelöscht:
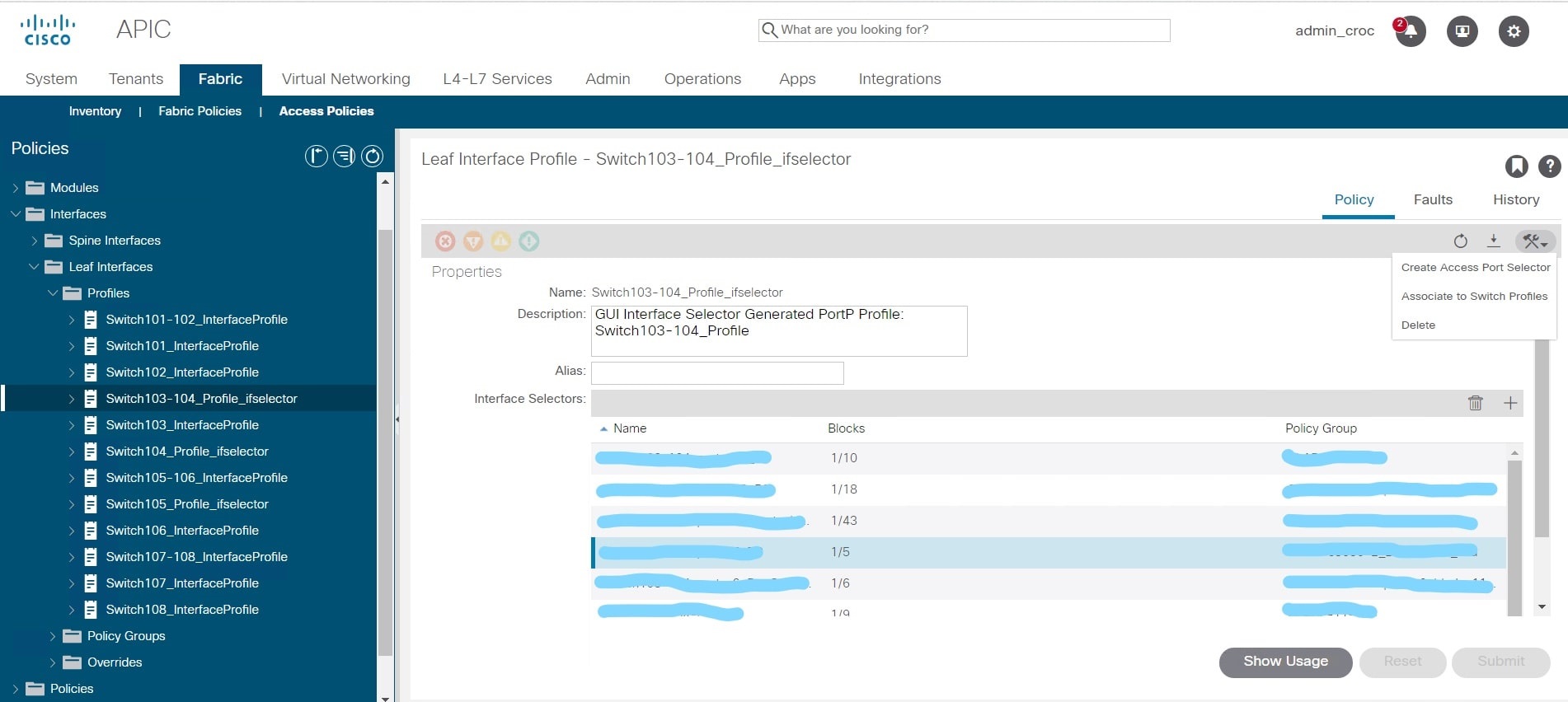
Anstatt eine Gruppe zu löschen, habe ich tatsächlich alle VPCs aus den Knoteneinstellungen gelöscht und anstelle des Papierkorbs "Löschen" verwendet.
Diese Links hatten geschäftskritische VLANs. Tatsächlich habe ich nach dem Löschen der Konfiguration einen Teil des Rasters deaktiviert. Darüber hinaus war dies nicht sofort erkennbar, da die Factory nicht über den Kernel gesteuert wird, sondern über eine separate Verwaltungsschnittstelle verfügt. Ich wurde nicht sofort rausgeworfen, es gab keinen Fehler in der Fabrik, da die Aktion vom Administrator ausgeführt wurde. Und die Benutzeroberfläche denkt - wenn Sie sagen, dass Sie löschen sollen, sollte es so sein. Es gab keine Hinweise auf Fehler. Die Software entschied, dass eine Neukonfiguration durchgeführt wurde. Wenn der Administrator das Blattprofil löscht, ist es für die Factory nicht mehr vorhanden und es wird kein Fehler geschrieben, der besagt, dass es nicht funktioniert. Es funktioniert nicht - weil es absichtlich entfernt wurde. Es sollte nicht für Software funktionieren.
Also entschied die Software, dass ich Chuck Norris war und wusste genau, was ich tat. Alles ist unter Kontrolle. Der Administrator kann sich nicht irren, und selbst wenn er sich in den Fuß schießt, ist dies Teil eines listigen Plans.
Aber nach ungefähr zehn Minuten wurde ich aus dem VPN geworfen, das ich anfangs nicht mit der APIC-Konfiguration verknüpft hatte. Aber das ist zumindest verdächtig, und ich habe den Kunden kontaktiert, um zu klären, was passiert ist. Und für die nächsten paar Minuten dachte ich, dass das Problem technische Arbeit, ein plötzlicher Bagger oder ein Stromausfall war, aber nicht die Werkskonfiguration.
Das Netzwerk des Kunden ist komplex. Wir sehen nur einen Teil der Umwelt durch unseren Zugang. Beim Wiederherstellen von Ereignissen sieht alles so aus, als hätte die Neuausrichtung des Datenverkehrs begonnen. Nach einigen Sekunden wurde das dynamische Routing der verbleibenden Systeme einfach nicht beendet.
Das von mir verwendete VPN war das Admin-VPN. Normale Angestellte saßen auf der anderen Seite, alles arbeitete weiter für sie.
Im Allgemeinen dauerte es noch ein paar Minuten, bis ich verstanden hatte, dass das Problem immer noch in meiner Konfiguration liegt. Die erste Aktion in einem Kampf in einer solchen Situation besteht darin, zu früheren Konfigurationen zurückzukehren und erst dann die Protokolle zu lesen, da dies ein Produkt ist.
Werksrestaurierung
Die Wiederherstellung der Fabrik dauerte 30 Minuten - einschließlich aller Anrufe und des Sammelns aller Beteiligten.
Wir haben ein anderes VPN gefunden, das Sie durchlaufen können (dies erforderte eine Vereinbarung mit den Sicherheitskräften), und ich habe die Werkskonfiguration zurückgesetzt - in Cisco ACI erfolgt dies mit zwei Klicks. Es ist nichts kompliziert. Der Wiederherstellungspunkt wird einfach ausgewählt. Es dauert 10-15 Sekunden. Das heißt, die Wiederherstellung selbst dauerte 15 Sekunden. Der Rest der Zeit wurde damit verbracht, herauszufinden, wie man eine Fernbedienung bekommt.
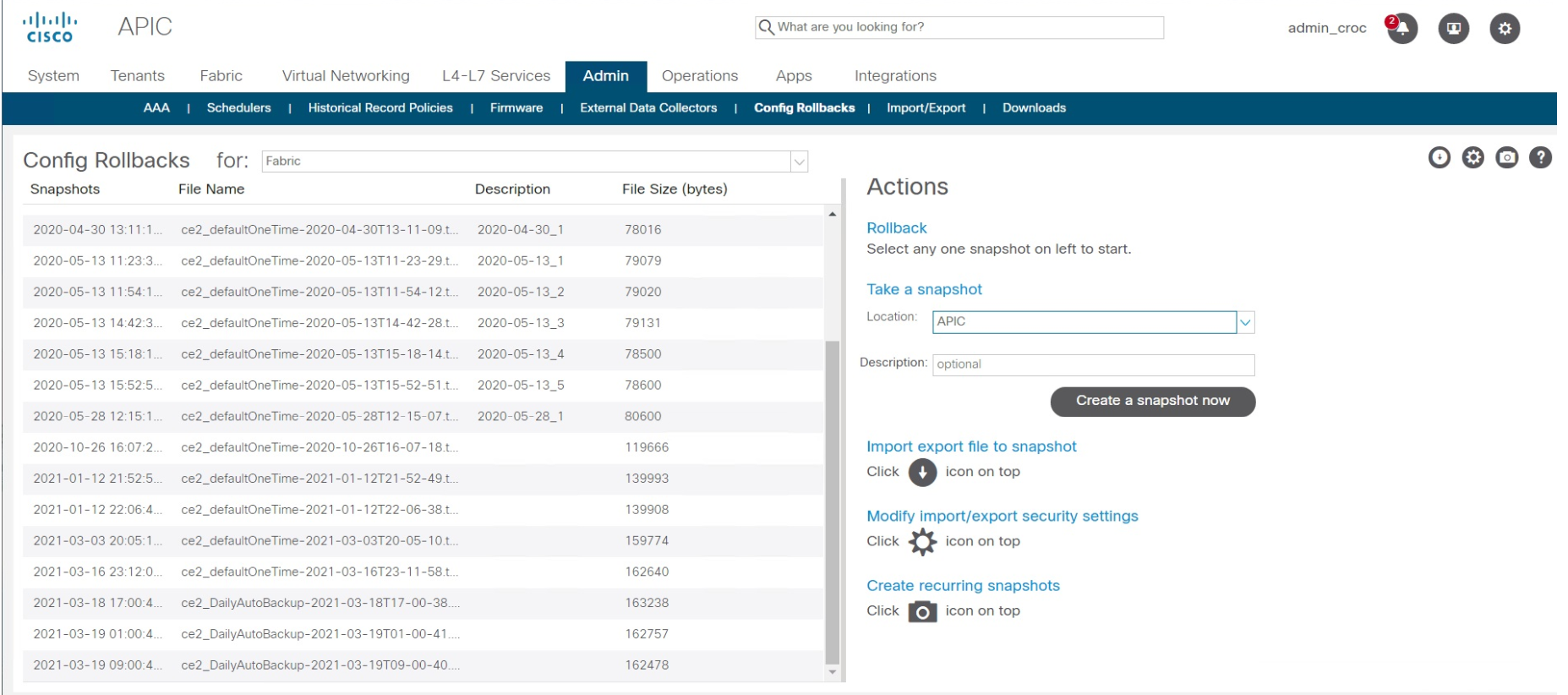
Nach dem Vorfall
An einem anderen Tag haben wir die Protokolle analysiert und die Ereigniskette wiederhergestellt. Dann versammelten sie sich mit dem Kunden, erklärten ruhig das Wesentliche und die Ursachen des Vorfalls und schlugen eine Reihe von Maßnahmen vor, um das Risiko solcher Situationen und den menschlichen Faktor zu minimieren.
Wir waren uns einig, dass wir die Konfigurationen der Fabrik nur außerhalb der Arbeitszeit berühren: nachts und abends. Wir arbeiten mit einer doppelten Remote-Verbindung (es gibt funktionierende VPN-Kanäle, es gibt Backup-Kanäle). Der Kunde erhält eine Warnung von uns und überwacht zu diesem Zeitpunkt die Leistungen.
Der Ingenieur (das heißt ich) blieb bei dem Projekt derselbe. Ich kann sagen, dass das Gefühl des Vertrauens in mich noch größer geworden ist als vor dem Vorfall - ich denke, gerade weil wir schnell in der Situation gearbeitet haben und keine Panikwelle den Kunden erfasst hat. Die Hauptsache ist, dass sie nicht versucht haben, das Gelenk zu verstecken. Aus der Praxis weiß ich, dass es in dieser Situation am einfachsten ist, zum Anbieter zu wechseln.
Wir haben ähnliche Netzwerkrichtlinien auf andere ausgelagerte Kunden angewendet: Es ist schwieriger für Kunden (zusätzliche VPN-Kanäle, zusätzliche Administratoränderungen außerhalb der Geschäftszeiten), aber viele haben verstanden, warum dies notwendig ist.
Wir haben uns auch eingehender mit der NAE-Software (Cisco Network Assurance Engine) befasst, bei der wir die Möglichkeit gefunden haben, zwei einfache, aber sehr wichtige Dinge in der ACI-Fabrik zu erledigen:
- Erstens ermöglicht uns die NAE, die geplante Änderung zu analysieren, noch bevor wir sie in der Fabrik eingeführt und alles für uns selbst aufgenommen haben, um vorherzusagen, wie sich die Änderung positiv oder negativ auf die vorhandene Konfiguration auswirken wird.
- Zweitens können Sie mit der NAE nach der Änderung die Gesamttemperatur der Fabrik messen und sehen, wie sich diese Änderung letztendlich auf den Gesundheitszustand auswirkt.
Wenn Sie an weiteren Details interessiert sind - morgen haben wir ein Webinar über die interne Küche des technischen Supports. Wir werden Ihnen sagen, wie alles bei uns und bei Anbietern funktioniert. Wir werden auch Fehler analysieren)