Kürzlich hat Sberbank in dem Artikel Alles, was wir brauchen, ist die Generierung eines ungewöhnlichen Ansatzes zum Herausfiltern von Texten mit geringer Qualität (technischer Junk und Vorlagen-Spam).
Wir haben diesen Ansatz durch eine weitere Heuristik ergänzt: Wir haben Texte mit zlib komprimiert und die am stärksten und am schwächsten komprimierten verworfen und dann die Klassifizierung angewendet. Empirisch ausgewählter Komprimierungsbereich für normalen Text × 1,2 - × 8 (weniger als 1,2 - zufällige Zeichen und technischer Müll, mehr als 8 - Vorlagen-Spam).
Der Ansatz ist sicherlich interessant und eine Übernahme wert. Aber hat das zlib-Komprimierungsverhältnis für Qualitätstexte keine nichtlineare Abhängigkeit von der Länge des zu komprimierenden Texts? Lass uns nachsehen.
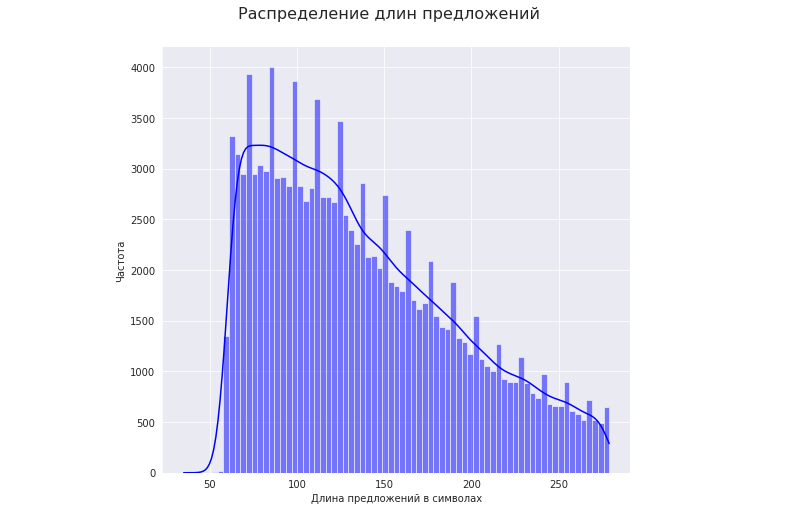
Nehmen wir einen Textkorpus von Sätzen mit einer Länge von 50 bis 280 Zeichen:
import zlib
import numpy as np
import matplotlib
import matplotlib.pyplot as plt
import seaborn as sns
from scipy.optimize import curve_fit
with open('/content/test.txt', 'r', encoding='utf-8') as f:
text = f.read()
sntc = text.split('\n')
l_sntc = [] #
k_zlib = [] #
for s in sntc:
l_sntc.append(len(s))
k_zlib.append(len(s) / len(zlib.compress(s.encode(), -1)))
Mal sehen, wie sich die Länge hochwertiger Sätze auf das Komprimierungsverhältnis auswirkt.
Dafür:
1. Nehmen wir den Bereich der Satzlängen mit der höchsten Häufigkeit (25 - 75 Perzentil). In unserem Fall sind dies Längen von 92 bis 175 Zeichen:
mp_1 = np.percentile(np.array(l_sntc), [25, 75])
print(': ' + str(mp_1))
2. . 25 (25 + w) 75 (75 - w) ( ), w - ( 2.5 ).
:
w = 2.5 #
mp_2 = np.percentile(np.array(l_sntc), [25 + w, 75 - w])
dl = int(min(mp_2[0] - mp_1[0], mp_1[1] - mp_2[1]))
print(' : ' + str(dl))
3 .
+- 3 :
#
id_sntc = range(len(sntc)) #
x = zip(l_sntc, id_sntc)
xs = sorted(x, key = lambda tup: tup[0])
l_sntc_s = [x[0] for x in xs]
id_snt_s = [x[1] for x in xs]
gr = 0 #
k_gr = [[]] #
l_gr = [[]] #
sl0 = l_sntc_s[l_sntc_s.index(mp_1[0])] #
nt = l_sntc_s.index(mp_1[1])
for i in range(nt, len(l_sntc_s)):
if l_sntc_s[i] > l_sntc_s[nt]:
nt = i
break
for i in range(l_sntc_s.index(mp_1[0]), nt):
if l_sntc_s[i] > sl0 + dl:
sl0 = l_sntc_s[i]
k_gr.append([])
l_gr.append([])
gr += 1
else:
k_gr[gr].append(k_zlib[id_snt_s[i]])
l_gr[gr].append(l_sntc_s[i])
print(' : ' + str(gr))
20 .
3. , :
x = [0]
y = [0]
for i in range(gr + 1):
x.append(np.percentile(np.array(l_gr[i]), 50))
y.append(np.percentile(np.array(k_gr[i]), 50))

:

x - , y - .
x = np.array(x)
y = np.array(y)
#
def func(x, a, b):
return a * x ** b
popt, pcov = curve_fit(func, x, y, (0.27, 0.24), maxfev=10 ** 6)
a, b = popt
print('a = {0}\nb = {1}'.format(*tuple(popt)))
print(' : ' + str(np.corrcoef(y, a * x ** b)[0][1]))
a = 0.17601951773514363, b = 0.3256903074228561, : 0.9999489378452683
:

( 50 - 280 ) , . "c" "y = " ( ), , :
c = np.percentile(np.array(k_zlib), 50)
graph = plt.figure()
axes = graph.add_axes([0, 0, 1, 1])
axes.set_xlabel(' ')
axes.set_ylabel(' ')
axes.set_title(' ')
axes.plot([60, 280], [c, c], color='r')
axes.plot(range(60, 281), a * np.array(range(60, 281)) ** b, color='b')

. ~130 , ~130 - . . , .
, . , .
k_zlib_f = np.array(k_zlib) * c / (a * np.array(l_sntc) ** b)
, :
In unserem Fall wurden die Sätze bereits von technischem Müll befreit. Als Beispiel filtern wir nur Spam-Sätze heraus:
p_zlib_1 = np.percentile(np.array(k_zlib), 99.95)
p_zlib_2 = np.percentile(np.array(k_zlib_f), 99.95)
for i in range(len(sntc)):
if k_zlib_f[i] > p_zlib_2 and k_zlib[i] <= p_zlib_1:
print(sntc[i])

Wie Sie sehen, handelt es sich um kurze Sätze, für die das Komprimierungsverhältnis unterschätzt wurde . In der Praxis sind gleich lange Sätze im Korpus eher selten. In der Regel ist der Längenbereich sehr bedeutend.
Der vollständige Laptop-Code wird auf GitHub veröffentlicht .
Vielleicht ist es für jemanden nützlich. Ich habe diesen Ansatz für mich als einen relativ einfachen und effektiven Weg gewählt, um technischen Müll und Vorlagen-Spam loszuwerden.