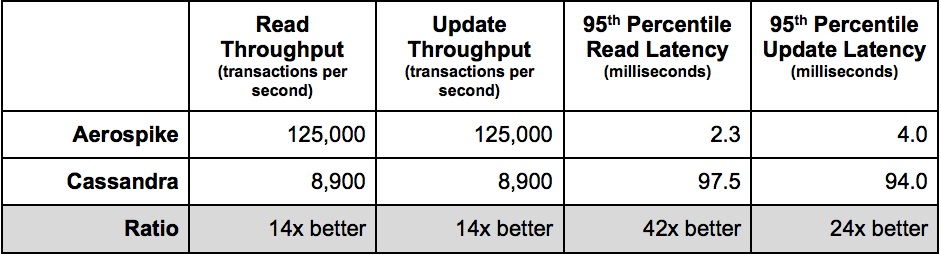
Durch einen erstaunlichen Zufall schlägt Scylla (im Folgenden: SC) auch CS leicht, was stolz direkt auf seiner Homepage ankündigt :

Es stellt sich natürlich die Frage, wer wen, den Wal oder den Elefanten umzäunen wird.
In meinem Test arbeitet die optimierte Version von HBase (im Folgenden als HB bezeichnet) mit CS auf gleicher Augenhöhe. Hier wird es also kein Anwärter auf den Sieg sein, sondern nur insoweit, als unsere gesamte Verarbeitung auf HB basiert und ich möchte verstehen seine Fähigkeiten im Vergleich zu den Führern.
Es ist klar, dass HB und CS kostenlos sind. Wenn Sie jedoch X-mal mehr Hardware benötigen, um die gleiche Leistung zu erzielen, ist es rentabler, für Software zu bezahlen, als eine Etage im Rechenzentrum für teure zu reservieren Heizkissen. Besonders wenn man bedenkt, dass, wenn es um Leistung geht, Festplatten im Prinzip nicht in der Lage sind, zumindest eine akzeptable Geschwindigkeit für Direktzugriffslesungen zu liefern (siehe " Warum Festplatten- und Schnellzugriffslesungen nicht kompatibel sind "), was wiederum bedeutet Der Kauf einer SSD, die in den für eine echte BigData erforderlichen Mengen vorhanden ist, ist ein ziemlich teures Vergnügen.
Also wurde folgendes getan. Ich habe 4 Server in der AWS-Cloud in der i3en.6xlarge-Konfiguration gemietet, von denen jeder an Bord ist:
CPU - 24 vcpu
MEM - 192 GB
SSD - 2 x 7500 GB
Wenn jemand es wiederholen möchte, stellen wir sofort fest, dass es für die Reproduzierbarkeit sehr wichtig ist, Konfigurationen mit dem Gesamtvolumen der Festplatten (7500 GB) vorzunehmen. Andernfalls müssen die Festplatten mit unvorhersehbaren Nachbarn geteilt werden, was Ihre Tests sicherlich ruinieren wird, da sie wahrscheinlich eine sehr wertvolle Last darstellen.
Als nächstes habe ich SC mit dem Konstruktor eingeführt , der freundlicherweise vom Hersteller auf seiner eigenen Website zur Verfügung gestellt wurde. Dann habe ich das YCSB-Dienstprogramm (das fast ein Standard für vergleichende Datenbanktests ist) für jeden Clusterknoten hochgeladen.
Es gibt nur eine wichtige Nuance. In fast allen Fällen verwenden wir das folgende Muster: Lesen Sie den Datensatz, bevor Sie ihn ändern, und schreiben Sie den neuen Wert.
Also habe ich das Update wie folgt geändert :
@Override
public Status update(String table, String key,
Map<String, ByteIterator> values) {
read(table, key, null, null); // << added read before write
return write(table, key, updatePolicy, values);
}
Dann habe ich das Laden gleichzeitig von allen 4 Hosts gestartet (die gleichen, auf denen sich die Datenbankserver befinden). Dies geschieht absichtlich, da Clients einiger Datenbanken manchmal mehr CPU verbrauchen als andere. In Anbetracht der begrenzten Größe des Clusters möchte ich die Gesamteffizienz der Implementierung sowohl des Server- als auch des Client-Teils verstehen.
Die Testergebnisse werden im Folgenden vorgestellt, aber bevor wir zu ihnen übergehen, sollten einige wichtigere Nuancen in Betracht gezogen werden.
Wie für AS, ist dies eine sehr attraktive Datenbank, die führend in der Kundenzufriedenheit Kategorie nach zur g2 Ressource.
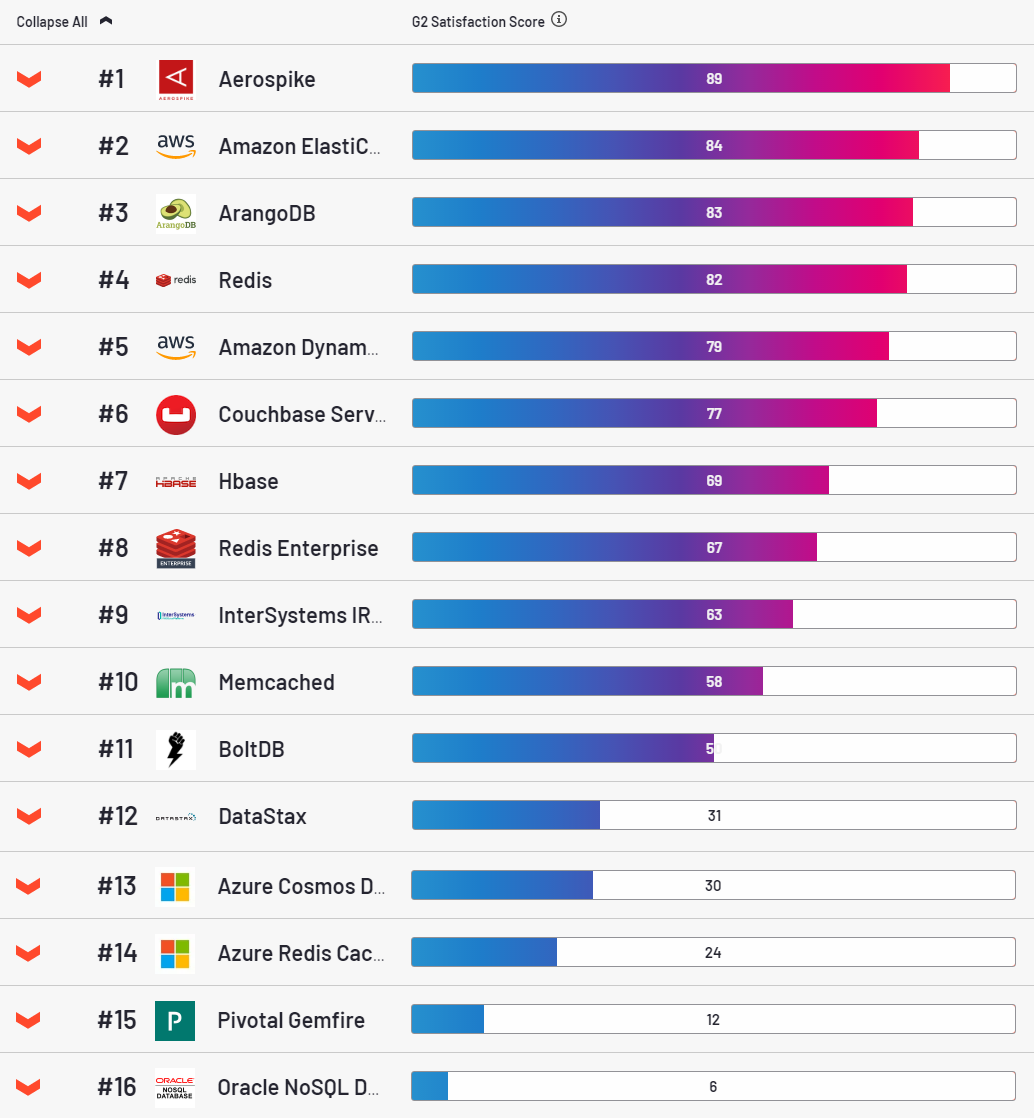
Ehrlich gesagt hat es mir auch irgendwie gefallen. Mit diesem Skript wird es einfach ausgedrückt rollt ganz leicht in die Wolke. Stabil, es ist eine Freude zu konfigurieren. Es hat jedoch einen sehr großen Nachteil. Für jeden Schlüssel werden 64 Byte RAM zugewiesen. Es scheint ein wenig, aber in industriellen Mengen wird es ein Problem. Ein typischer Eintrag in unseren Tabellen ist 500 Bytes. Es ist diese Menge an Wert, die ich in fast * allen Tests verwendet habe (* warum fast unten gesagt wird).
Da wir 3 Kopien jedes Datensatzes speichern, stellt sich heraus, dass zum Speichern von 1 PB sauberer Daten (3 PB schmutziger Daten) nur 400 TB RAM zugewiesen werden müssen. Weitermachen ... nein was ?! Moment mal, können Sie etwas dagegen tun? - Wir haben den Verkäufer gefragt.
Ha, natürlich kannst du viele Dinge tun, deine Finger beugen:
Ok, jetzt beschäftigen wir uns mit HB und wir können die Testergebnisse bereits berücksichtigen. Für die Installation von Hadoop stellt Amazon die EMR-Plattform zur Verfügung, mit der Sie den benötigten Cluster problemlos bereitstellen können. Ich musste nur die Anzahl der Prozesse und geöffneten Dateien erhöhen, sonst stürzte es unter Last ab und ersetzte den hbase-Server durch meine optimierte Assembly (siehe Details hier ). Der zweite Punkt, HB verlangsamt sich schamlos, wenn mit einzelnen Anfragen gearbeitet wird, das ist eine Tatsache. Daher arbeiten wir nur in Chargen. In diesem Test ist Batch = 100. Die Tabelle enthält 100 Regionen.
Nun, und im letzten Moment wurden alle Datenbanken im Modus "Starke Konsistenz" getestet. Für HB ist es out of the box. AS ist nur in der Unternehmensversion verfügbar (d. H. Es wurde in diesem Test aktiviert). SC lief in Schreibkonsistenz = Alle-Modus. Replikationsfaktor ist überall 3.
Also, lass uns gehen. Einfügen in AS:
10 Sek.: 360554 Operationen; 36055,4 aktuelle Operationen / Sek.;
20 Sek.: 698872 Operationen; 33831,8 aktuelle Operationen / Sek.;
...
230 Sek.: 7412626 Operationen; 22938,8 aktuelle Operationen / Sek.;
240 Sek.: 7542091 Operationen; 12946,5 aktuelle Operationen / Sek.;
250 Sek.: 7589682 Operationen; 4759,1 aktuelle Operationen / Sek.;
260 Sek.: 7599525 Operationen; 984,3 aktuelle Operationen / Sek.;
270 Sek.: 7602150 Operationen; 262,5 aktuelle Operationen / Sek.;
280 Sek.: 7602752 Operationen; 60,2 aktuelle Operationen / Sek.;
290 Sek.: 7602918 Operationen; 16,6 aktuelle Operationen / Sek.;
300 Sek.: 7603269 Operationen; 35,1 aktuelle Operationen / Sek.;
310 Sek.: 7603674 Operationen; 40,5 aktuelle Operationen / Sek.;
Fehler beim Schreiben des Schlüssels user4809083164780879263: com.aerospike.client.AerospikeException $ Timeout: Client-Timeout: Timeout = 10000 Iterationen = 1 failedNodes = 0 failedConns = 0 lastNode = 5600000A 127.0.0.1:3000
Fehler beim Einfügen, kein erneuter Versuch. Anzahl der Versuche: 1Insertion Retry Limit: 0 Ups
, Sie sind definitiv ein
Okay, lass uns weitermachen. Wir beginnen mit dem Laden von 200 Millionen Datensätzen (INSERT), dann UPDATE und dann GET. Folgendes ist passiert (Operationen - Operationen pro Sekunde):

WICHTIG! Dies ist die Geschwindigkeit eines Knotens! Es gibt insgesamt 4 von ihnen, d.h. Um die Gesamtgeschwindigkeit zu erhalten, müssen Sie mit 4 multiplizieren.
Die erste Spalte besteht aus 10 Feldern. Dies ist kein fairer Test. Jene. Dies ist der Fall, wenn sich der Index im Speicher befindet, was in einer realen BigData-Situation nicht erreichbar ist.
In der zweiten Spalte werden 10 Datensätze in 1 gepackt. Es gibt bereits echte Speichereinsparungen, genau zehnmal. Wie Sie dem Test deutlich entnehmen können, ist dieser Trick nicht umsonst, die Leistung sinkt erheblich. Der Grund liegt auf der Hand: Jedes Mal, wenn Sie einen Datensatz verarbeiten, müssen Sie sich mit 9 benachbarten Datensätzen befassen. Der Overhead ist kürzer.
Und schließlich All-Flush, hier ist ungefähr das gleiche Bild. Spüleinsätze sind schlechter, aber der Schlüsselaktualisierungsvorgang ist schneller, sodass wir uns nur mit All-Flush-Einsätzen vergleichen werden.
Lassen Sie uns die Katze eigentlich nicht gleich ziehen:

Alles ist im Allgemeinen klar, aber was sollte hier hinzugefügt werden.
- AS , .
- SC - , :

Vielleicht ist irgendwo ein Pfosten mit den Einstellungen oder der Fehler mit dem Kernel aufgetaucht, ich weiß es nicht. Aber ich habe alles vom und zum Drehbuch des Anbieters eingerichtet, also gehört das Moped nicht mir, alle Fragen sind für ihn.
Sie müssen auch verstehen, dass dies eine sehr bescheidene Datenmenge ist und sich bei großen Mengen die Situation ändern kann. Während der Experimente habe ich mehrere hundert Dollar verbrannt, sodass die Begeisterung nur für einen langfristigen Leader-Test und in einem auf einen Server beschränkten Modus ausreichte.
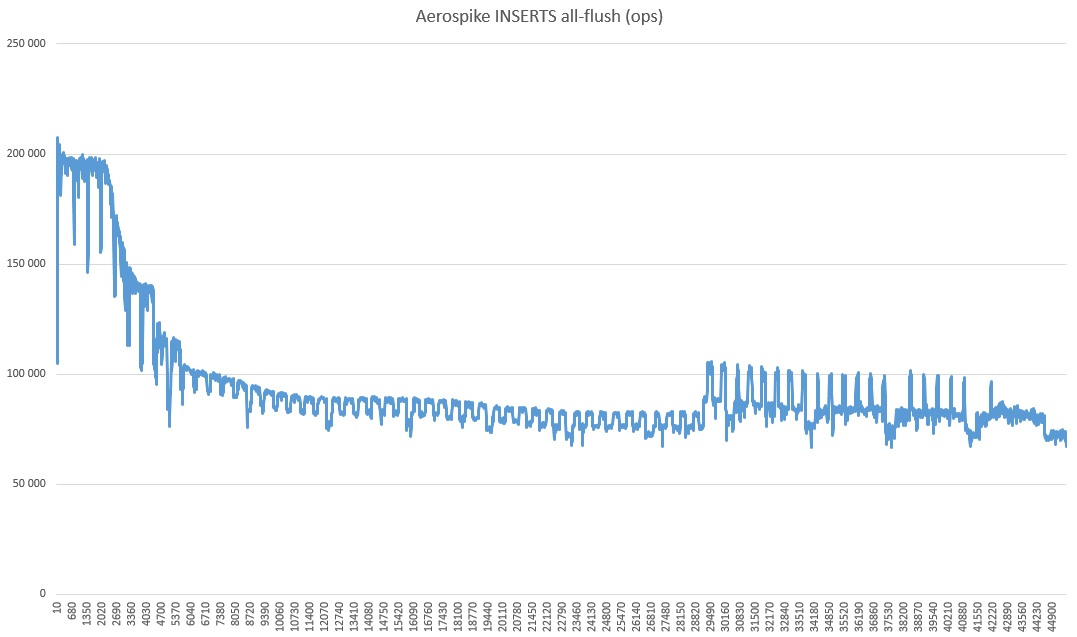
Warum es so stark abgeklungen ist und welche Art von Wiederbelebung im letzten Drittel ein Geheimnis der Natur ist. Sie können auch feststellen, dass die Geschwindigkeit radikal höher ist als in den Tests, etwas höher. Ich nehme an, das liegt daran, dass der starke Konsistenzmodus deaktiviert ist (da es nur einen Server gibt).
Und schließlich GET + WRITE (zusätzlich zu über drei Milliarden mit dem Test überfluteten Datensätzen):
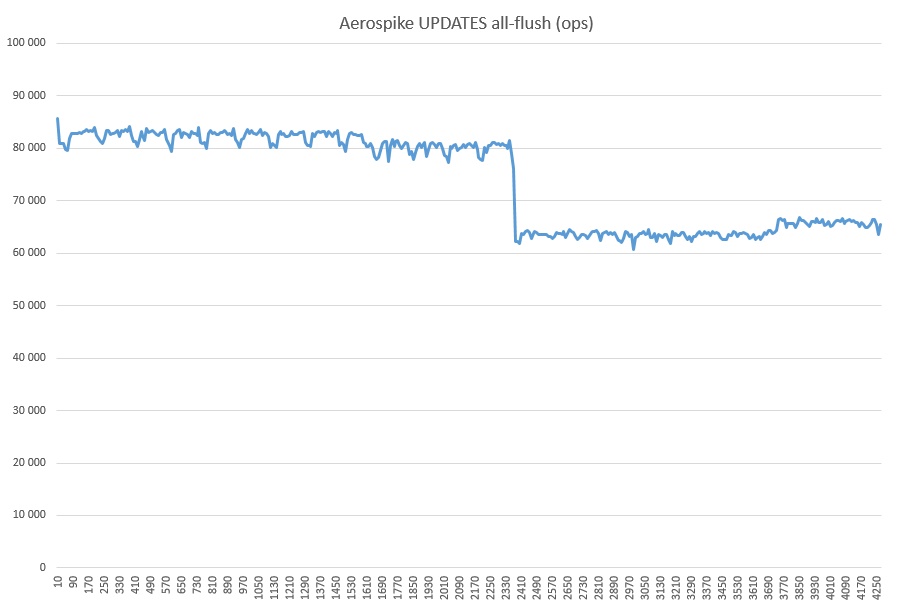
Was für ein Drawdown das ist, schätze ich nicht in meinem Herzen. Es wurden keine fremden Prozesse gestartet. Vielleicht hat es etwas mit dem SSD-Cache zu tun, weil die Auslastung während des gesamten AS-Tests im All-Flush-Modus 100% betrug.

Das ist alles. Die Schlussfolgerungen sind im Allgemeinen klar, es sind weitere Tests erforderlich. Es ist wünschenswert für alle gängigen Datenbanken unter den gleichen Bedingungen. Im Internet ist dieses Genre irgendwie nicht sehr viel. Und es wäre gut, dann werden die Basisanbieter motiviert sein, zu optimieren, und wir werden bewusst die besten auswählen.