
Bei Playrix wird eine erhebliche Menge an Ressourcen für die Datenaufbereitung und -analyse bereitgestellt. Wir versuchen, fortschrittliche Technologien einzusetzen und die Schulung der Mitarbeiter ernst zu nehmen. Das Unternehmen gehört zu den drei weltweit führenden Entwicklern von Handyspielen. Daher versuchen wir, bei der Datenanalyse und insbesondere bei Business Intelligence das entsprechende Niveau zu halten. Täglich spielen mehr als 27 Millionen Benutzer unsere Spiele. Diese Zahl kann einen groben Überblick über die Datenmenge geben, die täglich von Mobilgeräten generiert wird. Darüber hinaus werden Daten aus Dutzenden von Diensten in verschiedenen Formaten entnommen und anschließend aggregiert und in unsere Speicher geladen. Wir arbeiten mit AWS S3 als Data Lake, während Data Warehouse unter AWS Redshift und PostgreSQL nur begrenzt verwendet werden kann. Wir verwenden diese Datenbanken für Analysen. Rotverschiebung ist schneller, aber teurerDeshalb speichern wir dort die am häufigsten angeforderten Daten. PostgreSQL ist billiger und langsamer. Es speichert entweder kleine Datenmengen oder Daten, deren Lesegeschwindigkeit nicht kritisch ist. Für voraggregierte Daten verwenden wir Hadoop-Cluster und Impala.
Das wichtigste BI-Tool in Playrix ist Tableau. Dieses Produkt ist in der Welt bekannt, es bietet zahlreiche Möglichkeiten zur Datenanalyse und -visualisierung und arbeitet mit verschiedenen Quellen. Außerdem müssen Sie für einfache Analyseaufgaben keinen Code schreiben, sodass Sie Benutzer aus verschiedenen Abteilungen darin schulen können, ihre Geschäftsdaten selbst zu analysieren. Der Anbieter des Tools Tableau Software positioniert sein Produkt auch als Tool zur Selbstanalyse von Daten, dh zur Selbstbedienung.
Es gibt zwei Hauptansätze für die Datenanalyse in BI:
- Berichtsfabrik . Dieser Ansatz hat eine Abteilung und / oder Personen, die Berichte für Geschäftsbenutzer entwickeln.
- Self-Service. - .
Der erste Ansatz ist traditionell, und die meisten Unternehmen verfügen über eine unternehmensweite Berichtsfabrik wie diese. Der zweite Ansatz ist insbesondere für Russland relativ neu. Es ist gut, weil die Daten von Geschäftsbenutzern selbst recherchiert werden - sie kennen ihre lokalen Prozesse viel besser. Dies hilft, Entwickler zu entladen, sie von der Notwendigkeit zu entlasten, sich mit den Besonderheiten der Teamprozesse zu befassen und jedes Mal die grundlegendsten Berichte zu erstellen. Dies hilft bei der Lösung des wahrscheinlich größten Problems - der Überbrückung der Kluft zwischen Geschäftsbenutzern und Entwicklern. Schließlich besteht das Hauptproblem des Reporting Factory-Ansatzes darin, dass die meisten Berichte möglicherweise nur deshalb nicht beansprucht werden, weil Programmierer und Entwickler die Probleme von Geschäftsbenutzern falsch verstehen und dementsprechend unnötige Berichte erstellen.die entweder später überarbeitet oder einfach nicht verwendet werden.
Bei Playrix waren Programmierer und Analysten zunächst an der Entwicklung von Berichten im Unternehmen beteiligt, dh an Spezialisten, die täglich mit Daten arbeiten. Das Unternehmen entwickelt sich jedoch sehr schnell, und da die Anforderungen der Benutzer an Berichte steigen, sind die Berichtsentwickler nicht mehr rechtzeitig, um alle Aufgaben ihrer Erstellung und Unterstützung zu lösen. Dann stellte sich die Frage, ob entweder die BI-Entwicklungsgruppe erweitert oder Kompetenzen auf andere Abteilungen übertragen werden sollten. Die Self-Service- Richtung schien uns vielversprechend, daher haben wir beschlossen, Geschäftsanwendern beizubringen, ihre eigenen Projekte zu erstellen und Daten selbst zu analysieren.
In Playrix bearbeitet die Business Intelligence-Abteilung (BI-Team) die folgenden Aufgaben:
- Erhebung, Aufbereitung und Speicherung von Daten.
- Entwicklung interner Analysedienste.
- Integration mit externen Diensten.
- Entwicklung von Webschnittstellen.
- Berichtsentwicklung in Tableau.
Wir beschäftigen uns mit der Automatisierung interner Prozesse und Analysen. Vereinfacht kann unsere Struktur anhand des folgenden Diagramms dargestellt werden:

Mini-Teams BI-Team Die
Rechtecke hier stehen für Mini-Teams. Links hinten, rechts vorne. Jeder von ihnen verfügt über ausreichende Kompetenzen, um mit den Aufgaben verwandter Teams zu arbeiten und diese zu übernehmen, wenn die anderen Teams überlastet sind.
Das BI-Team verfügt über einen vollständigen Entwicklungszyklus: von der Erfassung der Anforderungen über die Bereitstellung in einer Produktumgebung bis hin zum anschließenden Support. Jedes Miniteam hat seinen eigenen Systemanalysten, Entwickler und Testingenieure. Sie dienen als Reporting Factory und bereiten Daten und Berichte für den internen Gebrauch vor.
Hierbei ist zu beachten, dass wir in den meisten Tableau-Projekten keine einfachen Berichte entwickeln, die normalerweise in Demos angezeigt werden, sondern Tools mit umfangreichen Funktionen, einer Vielzahl von Steuerelementen, umfangreichen Funktionen und dem Anschluss externer Module. Diese Tools werden ständig überarbeitet und neue Funktionen hinzugefügt.
Es treten jedoch auch einfache lokale Probleme auf, die vom Kunden selbst gelöst werden können.
Kompetenztransfer und Start eines Pilotprojekts
Nach unserer Erfahrung in der Arbeit und Kommunikation mit anderen Unternehmen sind die Hauptprobleme bei der Übertragung von Datenkompetenzen auf Geschäftsbenutzer:
- Die Zurückhaltung der Benutzer selbst, neue Tools zu erlernen und mit Daten zu arbeiten.
- Mangelnde Unterstützung durch das Management (Investitionen in Schulungen, Lizenzen usw.).
Wir haben kolossale Unterstützung vom Management, außerdem hat das Management angeboten, Self-Service einzuführen. Benutzer möchten auch lernen, wie man mit Daten und Tableau arbeitet - dies ist für die Jungs interessant, und die Datenanalyse ist jetzt eine sehr wichtige Fähigkeit, die sich in Zukunft definitiv als nützlich erweisen wird.
Die Implementierung einer neuen Ideologie im gesamten Unternehmen erfordert normalerweise viele Ressourcen und Nerven. Deshalb haben wir mit einem Pilotprojekt begonnen. Das Self-Service-Pilotprojekt wurde vor anderthalb Jahren in der Abteilung für Benutzerakquisition gestartet. Während des Pilotprozesses wurden Fehler und Erfahrungen gesammelt, um sie in Zukunft an andere Abteilungen weiterzugeben.
Die Richtung Benutzerakquise befasst sich mit der Aufgabe, das Publikum unserer Produkte zu vergrößern, analysiert die Art und Weise, wie Traffic gekauft wird, und wählt aus, in welche Richtung es sich lohnt, die Mittel des Unternehmens zu investieren. Zuvor wurden für diese Richtung Berichte vom BI-Team erstellt, oder die Jungs selbst haben die Uploads aus der Datenbank mithilfe von Excel oder Google Sheets verarbeitet. In einer dynamischen Entwicklungsumgebung führt eine solche Analyse jedoch zu Verzögerungen, und die Anzahl der analysierten Daten wird durch die Funktionen dieser Tools begrenzt.
Zu Beginn des Pilotprojekts führten wir eine Grundschulung für Mitarbeiter durch, um mit Tableau zu arbeiten. Dabei wurde die erste gemeinsame Datenquelle erstellt - eine Tabelle in der Redshift-Datenbank, in der mehr als 500 Millionen Zeilen und die erforderlichen Metriken enthalten waren. Es ist zu beachten, dass Redshift eine spalten- (oder spalten-) Datenbank ist und diese Datenbank Daten viel schneller als relationale Datenbanken bereitstellt. Der Pilotentisch in Redshift war wirklich groß für Leute, die nie mit mehr als 1 Million Zeilen gleichzeitig gearbeitet haben. Aber es war eine Herausforderung für die Jungs, zu lernen, wie man mit Daten solcher Volumina arbeitet.
Wir wussten, dass Leistungsprobleme beginnen würden, wenn diese Berichte komplexer würden. Wir haben Benutzern keinen Zugriff auf die Datenbank selbst gewährt, aber auf dem Tableau-Server wurde eine Quelle implementiert, die im Live-Modus mit einer Tabelle in Redshift verbunden ist. Benutzer hatten Creator-Lizenzen und konnten entweder vom Tableau-Server aus, der dort Berichte erstellt, oder von Tableau Desktop aus eine Verbindung zu dieser Quelle herstellen. Ich muss sagen, dass es beim Entwickeln von Berichten im Web (Tableau verfügt über einen Webbearbeitungsmodus) einige Einschränkungen auf dem Server gibt. Tableau Desktop unterliegt keinen solchen Einschränkungen, daher entwickeln wir hauptsächlich auf dem Desktop. Wenn nur ein Geschäftsbenutzer eine Analyse benötigt, müssen solche Projekte nicht auf dem Server veröffentlicht werden. Sie können lokal arbeiten.
Ausbildung
In unserem Unternehmen ist es üblich, Webinare und Wissensaustausch durchzuführen, in denen jeder Mitarbeiter über neue Produkte, Funktionen oder Fähigkeiten der Tools sprechen kann, mit denen er arbeitet oder die er erforscht. Alle diese Aktivitäten werden aufgezeichnet und in unserer Wissensdatenbank gespeichert. Dieser Prozess funktioniert auch in unserem Team, sodass wir regelmäßig Wissen austauschen oder grundlegende Schulungswebinare vorbereiten.
Für alle Benutzer mit Tableau-Lizenzen haben wir ein halbstündiges Webinar zur Arbeit mit dem Server und den Dashboards veranstaltet und aufgezeichnet. Sie sprachen über Projekte auf dem Server und arbeiteten mit nativen Steuerelementen aller Dashboards - dies ist das oberste Bedienfeld (Aktualisieren, Anhalten, ...). Es ist unbedingt erforderlich, alle Tableau-Benutzer darüber zu informieren, damit sie vollständig mit nativen Funktionen arbeiten können und keine Anforderungen für die Entwicklung von Funktionen stellen, die die Arbeit nativer Steuerelemente wiederholen.
Das Haupthindernis für die Beherrschung eines Werkzeugs (und tatsächlich etwas Neues) ist normalerweise die Befürchtung, dass es nicht möglich sein wird, diese Funktionalität zu verstehen und damit zu arbeiten. Daher ist die Schulung möglicherweise der wichtigste Schritt bei der Implementierung des Self-Service-BI-Ansatzes. Das Ergebnis der Implementierung dieses Modells wird stark von ihm abhängen - ob und wie schnell es überhaupt im Unternehmen Fuß fassen wird. Beim Starten von Webinaren sollten die Hindernisse für die Verwendung von Tableau beseitigt werden.
Es gibt zwei Gruppen von Webinaren, die wir für Personen durchgeführt haben, die mit der Arbeit von Datenbanken nicht vertraut sind:
- Anfänger-Wissenskit für Anfänger:
- Datenverbindung, Verbindungstypen, Datentypen, grundlegende Datentransformationen, Datennormalisierung (1 Stunde).
- Grundlegende Visualisierungen, Datenaggregation, Grundberechnungen (1 Stunde).
- /, (2 ).
In diesem ersten Kick-off-Webinar behandeln wir alles, was mit Datenkonnektivität und Datentransformation in Tableau zu tun hat. Da die Benutzer in der Regel über grundlegende Kenntnisse in MS Excel verfügen, ist es hier wichtig zu erläutern, wie sich die Arbeit in Excel grundlegend von der Arbeit in Tableau unterscheidet. Dies ist ein sehr wichtiger Punkt, da Sie eine Person von der Logik von Tabellen mit farbigen Zellen auf die Logik normalisierter Datenbankdaten umstellen müssen. Im selben Webinar erklären wir die Arbeit von JOIN, UNION, PIVOT und gehen auch auf das Mischen ein. Im ersten Webinar wird die Datenvisualisierung kaum angesprochen. Ziel ist es, die Funktionsweise und Transformation Ihrer Daten für Tableau zu erläutern. Für die Menschen ist es wichtig zu verstehen, dass Daten primär sind und die meisten Probleme auf Datenebene und nicht auf Visualisierungsebene auftreten.
Das zweite Webinar zu Self-Service befasst sich mit der Logik der Erstellung von Visualisierungen in Tableau. Tableau unterscheidet sich von anderen BI-Tools gerade dadurch, dass es über eine eigene Engine und eine eigene Logik verfügt. In anderen Systemen, z. B. in PowerBI, gibt es eine Reihe vorgefertigter Grafiken (Sie können zusätzliche Module im Store herunterladen), diese Module können jedoch nicht angepasst werden. In Tableau haben Sie tatsächlich eine leere Tafel, auf der Sie bauen können, was Sie wollen. Natürlich verfügt Tableau über ShowMe - ein Menü mit grundlegenden Visualisierungen, aber all diese Grafiken und Diagramme können und sollten gemäß der Logik von Tableau erstellt werden. Wenn Sie jemandem die Arbeit mit Tableau beibringen möchten, müssen Sie unserer Meinung nach ShowMe nicht zum Erstellen von Diagrammen verwenden. Die meisten davon sind für die Benutzer am Anfang nicht nützlich, aber Sie müssen genau die Logik des Erstellens vermitteln Visualisierungen. Für Business-Dashboards reicht es zu wissenwie zu bauen:
- Zeitfolgen. Linien- / Flächendiagramme (Liniendiagramme),
- Balkendiagramme
- Streudiagramme,
- Tabellen
Diese Visualisierungen reichen für die Selbstanalyse der Daten aus.
Zeitreihen: Sie werden im Geschäftsleben sehr häufig verwendet, da es interessant ist, Metriken in verschiedenen Zeiträumen zu vergleichen. Wahrscheinlich betrachten alle Mitarbeiter des Unternehmens die Dynamik der Geschäftsergebnisse in unserem Land. Wir verwenden Balkendiagramme, um Metriken nach Kategorien zu vergleichen. Streudiagramme werden selten verwendet, um normalerweise Korrelationen zwischen Metriken zu finden. Tabellen: etwas, das Business-Dashboards nicht vollständig entfernen können, aber wann immer möglich versuchen wir, ihre Anzahl zu minimieren. In Tabellen sammeln wir die numerischen Werte von Metriken nach Kategorien.
Das heißt, wir schicken Menschen nach 1 Stunde Schulung in der Arbeit mit Daten und 1 Stunde Schulung in grundlegenden Berechnungen und Visualisierungen auf einen Streubesitz. Dann arbeiten die Jungs selbst einige Zeit mit ihren Daten, haben Probleme, sammeln Erfahrungen und greifen sie einfach in die Hände. Diese Phase dauert durchschnittlich 2-4 Wochen. Während dieser Zeit besteht natürlich die Möglichkeit, sich mit dem BI-Team in Verbindung zu setzen, wenn etwas nicht funktioniert.
Nach der ersten Phase müssen Kollegen ihre Fähigkeiten verbessern und neue Möglichkeiten ausloten. Zu diesem Zweck haben wir ausführliche Schulungswebinare vorbereitet. In ihnen zeigen wir, wie man mit LOD-Funktionen, Tabellenfunktionen und Python-Skripten für TabPy arbeitet. Wir arbeiten mit Live-Unternehmensdaten, die immer interessanter sind als Fälschungen oder Daten aus dem Tableau-Basisdatensatz - Superstore. In denselben Webinaren sprechen wir über die wichtigsten Funktionen und Tricks von Tableau, die in proprietären Dashboards verwendet werden, zum Beispiel:
- Blattwechsel (Austausch von Blättern),
- Aggregation von Diagrammen anhand von Parametern,
- Datums- und Metrikformate
- Verwerfen unvollständiger Zeiträume für wöchentliche / monatliche Aggregationen.
All diese Tricks und Funktionen waren vor ein paar Jahren üblich, sodass sich alle im Unternehmen daran gewöhnten und wir sie in die Dashboard-Entwicklungsstandards übernommen haben. Wir verwenden Python-Skripte, um einige interne Metriken zu berechnen. Alle Skripte sind bereits bereit. Für Self-Service müssen wir verstehen, wie sie in unsere Berechnungen eingefügt werden.
Daher führen wir nur 4 Stunden Webinare durch, um Self-Service zu starten. Dies reicht normalerweise aus, damit eine motivierte Person mit Tableau arbeitet und die Daten selbst analysiert. Darüber hinaus haben wir für Datenanalysten eigene Webinare, die öffentlich verfügbar sind und mit denen Sie sich vertraut machen können.
Entwicklung von Datenquellen für Self-Service
Nachdem das Pilotprojekt durchgeführt wurde, haben wir es als erfolgreich angesehen und die Anzahl der Self-Service-Benutzer erhöht. Eine der großen Herausforderungen bestand darin, Datenquellen für verschiedene Teams vorzubereiten. Die Mitarbeiter von Self-Service können mit mehr als 200 Millionen Zeilen arbeiten, daher musste das Data Engineering-Team herausfinden, wie solche Datenquellen implementiert werden können. Für die meisten analytischen Aufgaben verwenden wir Redshift aufgrund der Geschwindigkeit beim Lesen von Daten und der Benutzerfreundlichkeit. Unter dem Gesichtspunkt der Informationssicherheit war es jedoch riskant, jeder Person von Self-Service aus Zugriff auf die Datenbank zu gewähren.
Die erste Idee bestand darin, Quellen mit einer Live-Verbindung zur Datenbank zu erstellen. Das heißt, auf Tableau Server wurden mehrere Quellen veröffentlicht, die entweder in Tabellen oder in vorbereiteten Ansichten von Redshift angezeigt wurden. In diesem Fall haben wir keine Daten auf dem Tableau-Server gespeichert, und Benutzer über diese Quellen selbst sind von ihrem Tableau Desktop (Clients) in die Datenbank gewechselt. Dies funktioniert, wenn Tabellen klein (Millionen) sind oder Tableau-Abfragen nicht übermäßig komplex sind. Während der Entwicklung begannen die Jungs, ihre Dashboards in Tableau zu komplizieren, LODs, benutzerdefinierte Sortierungen und Python-Skripte zu verwenden. Dies führte natürlich zu einer Verlangsamung der Arbeit einiger Self-Service-Dashboards. Daher haben wir einige Monate nach dem Start von Self-Service den Ansatz für die Arbeit mit Quellen überarbeitet.
Der neue Ansatz, den wir bisher verwendet haben, hat auf Tableau Server veröffentlichte Auszüge implementiert. Ich muss sagen, dass Self-Service ständig neue Aufgaben hat und Anfragen zum Hinzufügen neuer Felder zur Quelle erhalten. Natürlich werden Datenquellen ständig geändert. Wir haben die folgende Strategie für die Arbeit mit Quellen entwickelt:
- Laut TOR für die Quelle von der Self-Service-Seite werden Daten in den Datenbanktabellen gesammelt.
- Im Testschema der Redshift-Datenbank wird eine immaterielle Ansicht erstellt.
- Die Einreichung wird vom QS-Team auf Richtigkeit der Daten geprüft.
- Im Falle eines positiven Ergebnisses der Prüfung wird die Sicht auf das Rotverschiebungsschema erhöht.
- Das Data Engineering-Team ist um Unterstützung bemüht - Skripte zur Analyse der Datengültigkeit werden verbunden, ETL-Alarme werden verbunden und dem Self-Service-Team werden Leserechte erteilt.
- Tableau Server (), .
- ETL .
- .
- , Self-Service.
Ein wenig zu Punkt 7. Nativ können Sie mit Tableau Auszüge nach einem Zeitplan mit einer Mindestdifferenz von 5 Minuten erstellen. Wenn Sie sicher sind, dass Ihre Tabellen in der Datenbank immer um 4 Uhr morgens aktualisiert werden, können Sie den Extrakt einfach um 5 Uhr morgens einstellen, damit Ihre Daten erfasst werden. Dies umfasst eine Reihe von Aufgaben. In unserem Fall werden Tabellen anhand von Daten verschiedener Anbieter erfasst, einschließlich. Wenn es einem Anbieter oder unserem internen Dienst nicht gelungen ist, seinen Teil der Daten zu aktualisieren, wird die gesamte Tabelle als ungültig betrachtet. Das heißt, Sie können nicht einfach einen Zeitplan für eine feste Zeit festlegen. Daher verwenden wir die Tableau-API, um Extrakte auszuführen, wenn Tabellen bereit sind. Extrakt-Startsignale werden von unserem ETL-Service generiert, nachdem sichergestellt wurde, dass alle neuen Daten eingetroffen und gültig sind.
Mit diesem Ansatz können Sie mit minimaler Latenzzeit frische gültige Daten im Extrakt haben.
Veröffentlichen von Self-Service-Dashboards auf Tableau Server
Wir beschränken Menschen bewusst nicht auf Experimente mit ihren Daten und erlauben uns, unsere Arbeitsmappen zu veröffentlichen und zu teilen. Wenn eine Person in jedem Team der Meinung ist, dass ihr Dashboard für andere nützlich ist oder dass ein Mitarbeiter ein Dashboard auf dem Server benötigt, kann er es veröffentlichen. Das BI-Team greift nicht in die internen Experimente der Teams ein, sondern erarbeitet die gesamte Logik der Dashboards und Berechnungen selbst. Es gibt Fälle, in denen aus Self-Service ein interessantes Projekt entsteht, das dann vollständig an den Support des BI-Teams übertragen wird und in die Produktion geht. Dies ist genau der Effekt von Self-Service, wenn Menschen, die ihre Geschäftsaufgaben gut verstehen, beginnen, mit ihren Daten zu arbeiten und eine neue Strategie für ihre Arbeit zu entwickeln. Auf dieser Grundlage haben wir das folgende Schema von Projekten auf dem Server erstellt:
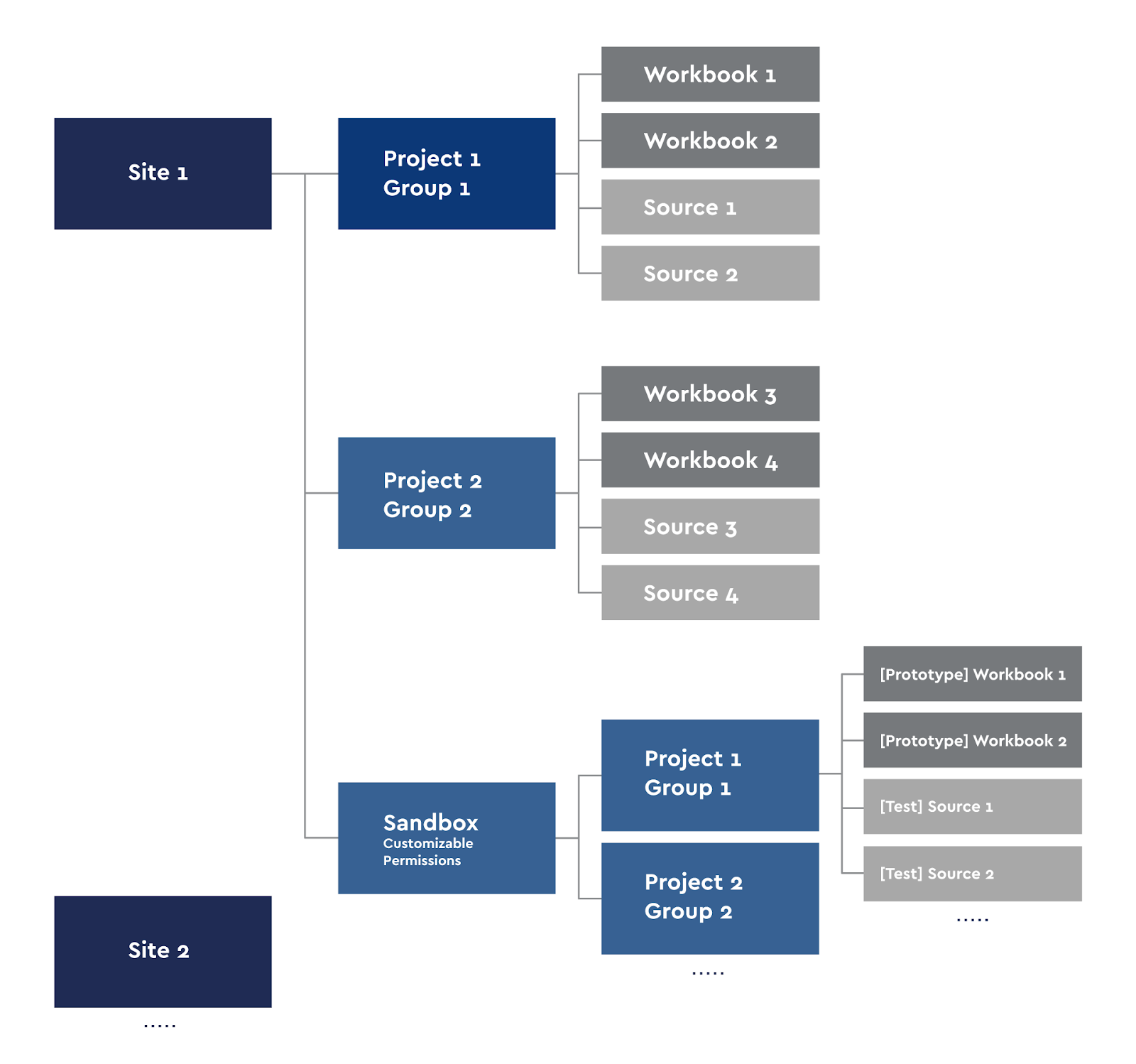
Tableau Server-Projektdiagramm
Jeder Creator-Benutzer kann seine Arbeitsmappen auf dem Server veröffentlichen oder die Analyse lokal durchführen. Für Self-Service haben wir mit unseren Projektgruppen unsere eigene Sandbox erstellt.
Websites in Tableau sind ideologisch unterteilt, sodass Benutzer einer Website den Inhalt einer anderen Website nicht sehen. Daher haben wir den Server in Websites in Bereichen unterteilt, die sich nicht überschneiden: z. B. Spieleanalyse und Finanzen. Wir verwenden Gruppenzugriff. Jede Site verfügt über Projekte, in denen die Rechte an ihren Arbeitsmappen und Quellen vererbt werden. Das heißt, die Benutzergruppe Gruppe 1 sieht nur ihre Arbeitsmappen und Datenquellen. Die Ausnahme von dieser Regel ist die Sandbox-Site, die auch Unterprojekte enthält. Wir verwenden Sandbox für das Prototyping, die Entwicklung neuer Dashboards, das Testen und für die Anforderungen von Self-Service. Jeder, der Zugriff auf sein Sandbox-Projekt veröffentlicht, kann seine Prototypen veröffentlichen.
Überwachen von Quellen und Dashboards auf Tableau Server
Da wir die Last der Self-Service-Dashboard-Anforderungen von der Datenbank auf den Tableau Server übertragen haben, arbeiten wir mit großen Datenquellen und beschränken die Anzahl der Anfragen nicht auf veröffentlichte Quellen. Ein weiteres Problem trat auf - die Überwachung der Leistung solcher Dashboards und die Überwachung der erstellten Quellen.
Die Überwachung der Leistung von Dashboards und der Leistung von Tableau-Servern ist eine Aufgabe für mittlere und große Unternehmen. Daher wurden zahlreiche Artikel über die Leistung von Dashboards und deren Optimierung verfasst. Wir sind in diesem Bereich keine Pioniere geworden. Unsere Überwachung umfasst mehrere Dashboards, die auf der internen PostgreSQL Tableau Server-Datenbank basieren. Diese Überwachung funktioniert mit allen Inhalten, Sie können jedoch Self-Service-Dashboards auswählen und deren Leistung anzeigen.
Das BI-Team löst von Zeit zu Zeit Probleme bei der Dashboard-Optimierung. Benutzer haben manchmal die Frage „Warum ist das Dashboard langsam?“. Wir müssen verstehen, was „langsam“ aus Sicht des Benutzers ist und welche numerischen Kriterien dieses „langsam“ charakterisieren können. Um den Benutzer nicht zu interviewen und ihm nicht die Arbeitszeit für eine detaillierte Nacherzählung der Probleme zu nehmen, überwachen und analysieren wir http-Anfragen, finden die langsamsten und finden die Gründe heraus. Danach werden wir die Dashboards optimieren, wenn dies zu einer Leistungssteigerung führen kann. Es ist klar, dass bei einer Live-Verbindung zu den Quellen Verzögerungen mit der Bildung einer Ansicht in der Datenbank und Verzögerungen beim Empfang von Daten verbunden sind. Es gibt auch Netzwerkverzögerungen, die wir mit unserem Support-Team für die gesamte IT-Infrastruktur untersuchen, auf die wir in diesem Artikel jedoch nicht näher eingehen werden.
Ein bisschen über http-Anfragen
Jede Benutzerinteraktion mit dem Dashboard im Browser initiiert eine eigene http-Anforderung, die an den Tableau Server übertragen wird. Der gesamte Verlauf solcher Abfragen wird in der internen PostgreSQL Tableau Server-Datenbank gespeichert. Die Standardspeicherdauer beträgt 7 Tage. Dieser Zeitraum kann durch Ändern der Tableau Server-Einstellungen verlängert werden. Wir wollten jedoch die Tabelle der http-Anforderungen nicht vergrößern. Daher erfassen wir einfach einen inkrementellen Extrakt, der nur täglich neue Daten enthält, während die alten nicht überschrieben werden. Dies ist eine gute Möglichkeit, mit einem Minimum an Ressourcen im Extrakt auf den Server-Verlaufsdaten zu bleiben, die sich nicht mehr in der Datenbank befinden.
Jede http-Anfrage hat einen eigenen Typ (action_type). Beispiel: _bootstrap ist das anfängliche Laden der Ansicht, relativer Datumsfilter ist der Datumsfilter (Schieberegler). Die meisten Typen können anhand des Namens identifiziert werden, sodass klar ist, was jeder Benutzer mit dem Dashboard macht: Jemand schaut sich mehr QuickInfos an, jemand ändert Parameter, jemand erstellt seine eigenen benutzerdefinierten Ansichten und jemand entlädt Daten.
Im Folgenden finden Sie unser Service-Dashboard, mit dem wir langsame Dashboards, langsame Anforderungstypen und Benutzer definieren können, die warten müssen.
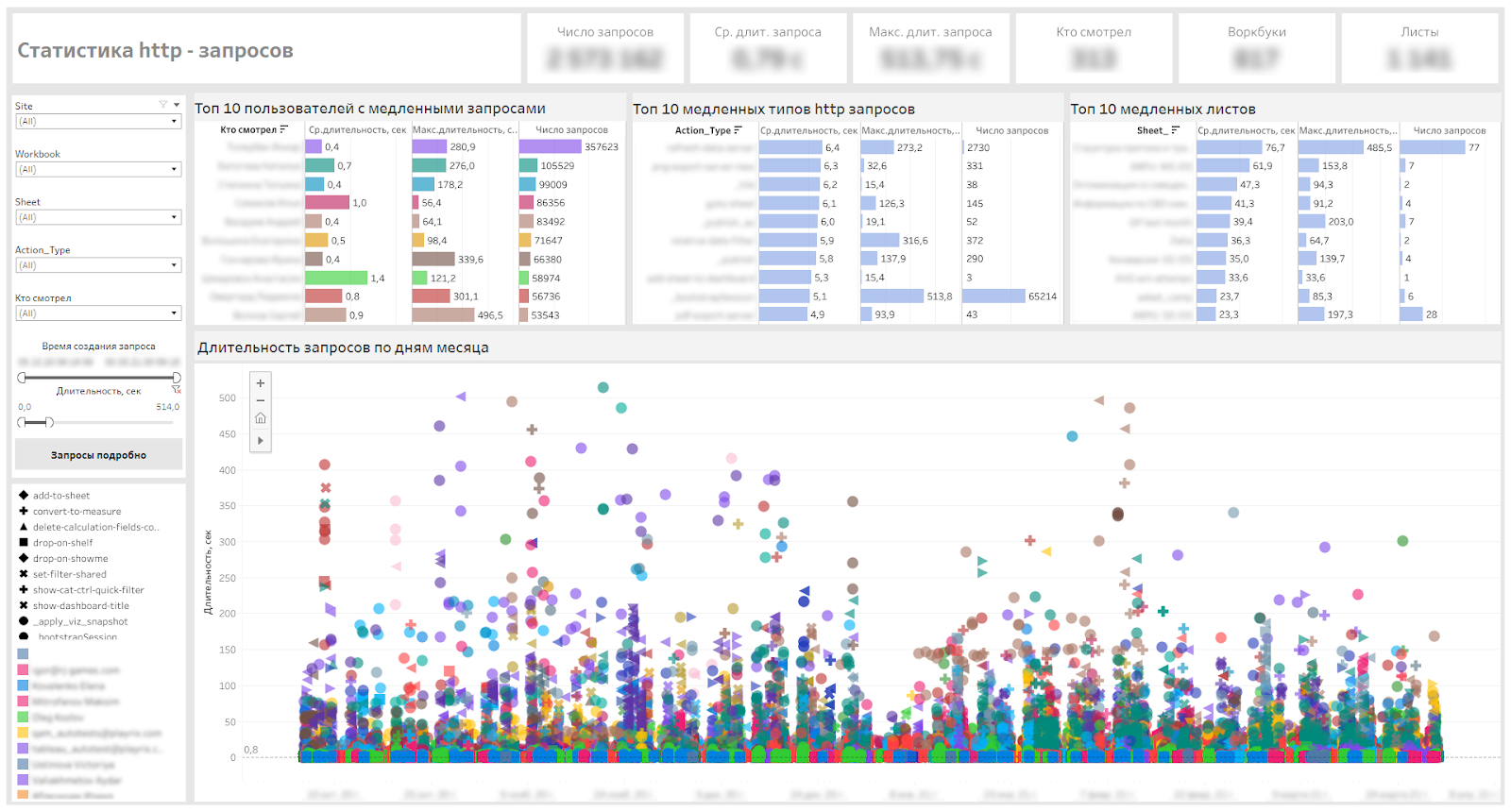
Dashboard zur Überwachung von http-Anfragen
Überwachen von VizQL-Sitzungen
Wenn ein Dashboard im Browser geöffnet wird, wird auf dem Tableau-Server eine VizQL-Sitzung gestartet, in der Visualisierungen gerendert werden. Außerdem werden Ressourcen für die Verwaltung der Sitzung zugewiesen. Diese Sitzungen werden standardmäßig nach 30 Minuten Inaktivität abgebrochen.
Als die Anzahl der Benutzer auf dem Server zunahm und der Self-Service eingeführt wurde, erhielten wir mehrere Anfragen, die VizQL-Sitzungslimits zu erhöhen. Das Problem für Benutzer bestand darin, dass sie Dashboards öffneten, Filter festlegten, etwas betrachteten und zu ihren anderen Aufgaben außerhalb von Tableau Server übergingen. Nach einer Weile kehrten sie zum Öffnen von Dashboards zurück, wurden jedoch auf die Standardansicht zurückgesetzt und mussten dies tun wiederverwendete Melodie. Unsere Aufgabe war es, die Benutzererfahrung komfortabler zu gestalten und sicherzustellen, dass die Belastung des Servers nicht kritisch zunimmt.
Die nächsten beiden Parameter auf dem Server können geändert werden. Sie müssen jedoch verstehen, dass die Belastung des Servers zunehmen kann.
vizqlserver.session.expiry.minimum 5
Anzahl der Minuten Leerlaufzeit, nach denen eine VizQL-Sitzung verworfen werden kann, wenn der VizQL-Prozess nicht mehr über genügend Arbeitsspeicher verfügt.
vizqlserver.session.expiry.timeout 30 Anzahl der Minuten Leerlaufzeit, nach denen eine VizQL-Sitzung verworfen wird.
Aus diesem Grund haben wir uns entschlossen, VizQL-Sitzungen zu überwachen und Folgendes zu verfolgen:
- Anzahl der Sitzungen,
- Anzahl der Sitzungen pro Benutzer,
- Durchschnittliche Sitzungsdauer,
- Die maximale Sitzungsdauer.
Außerdem mussten wir wissen, an welchen Tagen und zu welchen Stunden die meisten Sitzungen geöffnet sind.
Das Ergebnis ist ein Dashboard wie folgt:

Dashboard zur Überwachung von VizQL-Sitzungen
Seit Anfang Januar dieses Jahres haben wir begonnen, die Grenzwerte schrittweise zu erhöhen und die Dauer von Sitzungen und Ladevorgängen zu überwachen. Die durchschnittliche Sitzungsdauer wurde von 13 auf 35 Minuten erhöht - dies ist in den Diagrammen der durchschnittlichen Sitzungsdauer ersichtlich. Die endgültigen Einstellungen sind wie folgt:
vizqlserver.session.expiry.minimum 120 vizqlserver.session.expiry.timeout 240
Danach erhielten wir positive Rückmeldungen von Benutzern, die die Arbeit viel angenehmer machten - die Sitzungen hörten auf zu verblassen.
Die Heatmaps dieses Dashboards ermöglichen es uns auch, Servicearbeiten während der Stunden mit minimalem Serverbedarf zu planen.
Wir überwachen die Änderung der Auslastung des Clusters - CPU und RAM - in der Zabbix- und AWS-Konsole. Wir haben während der Zunahme der Zeitüberschreitungen keine signifikanten Änderungen der Last festgestellt.
Wenn wir darüber sprechen, was Ihren Tableau-Server stark verbiegen kann, kann es sich beispielsweise um ein nicht optimiertes Dashboard handeln. Erstellen Sie beispielsweise in Tableau eine Tabelle mit Zehntausenden von Zeilen nach Kategorien und ID einiger Ereignisse, und verwenden Sie in Measure LOD-Berechnungen auf ID-Ebene. Mit hoher Wahrscheinlichkeit funktioniert die Anzeige der Tabelle auf dem Server nicht und Sie erhalten einen Absturz mit einem unerwarteten Fehler, da alle LODs mit minimaler Granulation sehr viel Speicher verbrauchen und der Prozess sehr bald zu 100% ausgeführt wird des Speicherverbrauchs.
Dieses Beispiel wird hier gegeben, um zu verdeutlichen, dass ein nicht optimales Dashboard alle Serverressourcen verbrauchen kann und selbst 100 VizQL-Sitzungen der optimalen Dashboards nicht so viele Ressourcen verbrauchen.
Überwachen von Serverdatenquellen
Oben haben wir festgestellt, dass wir für Self-Service mehrere Datenquellen auf dem Server vorbereitet und veröffentlicht haben. Alle Quellen sind Datenextrakte. Die veröffentlichten Quellen werden auf dem Server gespeichert und den Mitarbeitern von Tableau Desktop zur Verfügung gestellt.
Tableau kann Quellen als zertifiziert markieren. Dies tut das BI-Team bei der Vorbereitung von Datenquellen für Self-Service. Dies stellt sicher, dass die Quelle selbst getestet wurde.
Veröffentlichte Quellen können bis zu 200 Millionen Zeilen und 100 Felder umfassen. Für Self-Service ist dies ein sehr großes Volumen, da nicht viele Unternehmen Quellen für solche Volumina für unabhängige Analysen haben.
Wenn wir Anforderungen zum Generieren einer Quelle erfassen, prüfen wir natürlich, wie wir die Datenmenge in der Quelle reduzieren können, indem wir Kategorien gruppieren, Quellen nach Projekten aufteilen oder Zeiträume begrenzen. Dennoch werden Quellen in der Regel aus 10 Millionen Zeilen bezogen.
Da die Quellen groß sind, Speicherplatz auf dem Server beanspruchen, Serverressourcen zum Aktualisieren von Auszügen verwenden, müssen alle überwacht werden, um festzustellen, wie oft sie verwendet werden und wie schnell sie an Volumen zunehmen. Zu diesem Zweck haben wir eine Überwachung durchgeführt von veröffentlichten Datenquellen. Es zeigt Benutzer, die eine Verbindung zu Quellen herstellen, Arbeitsmappen, die diese Quellen verwenden. Auf diese Weise können Sie irrelevante oder problematische Quellen finden, die der Extrakt nicht sammeln kann.
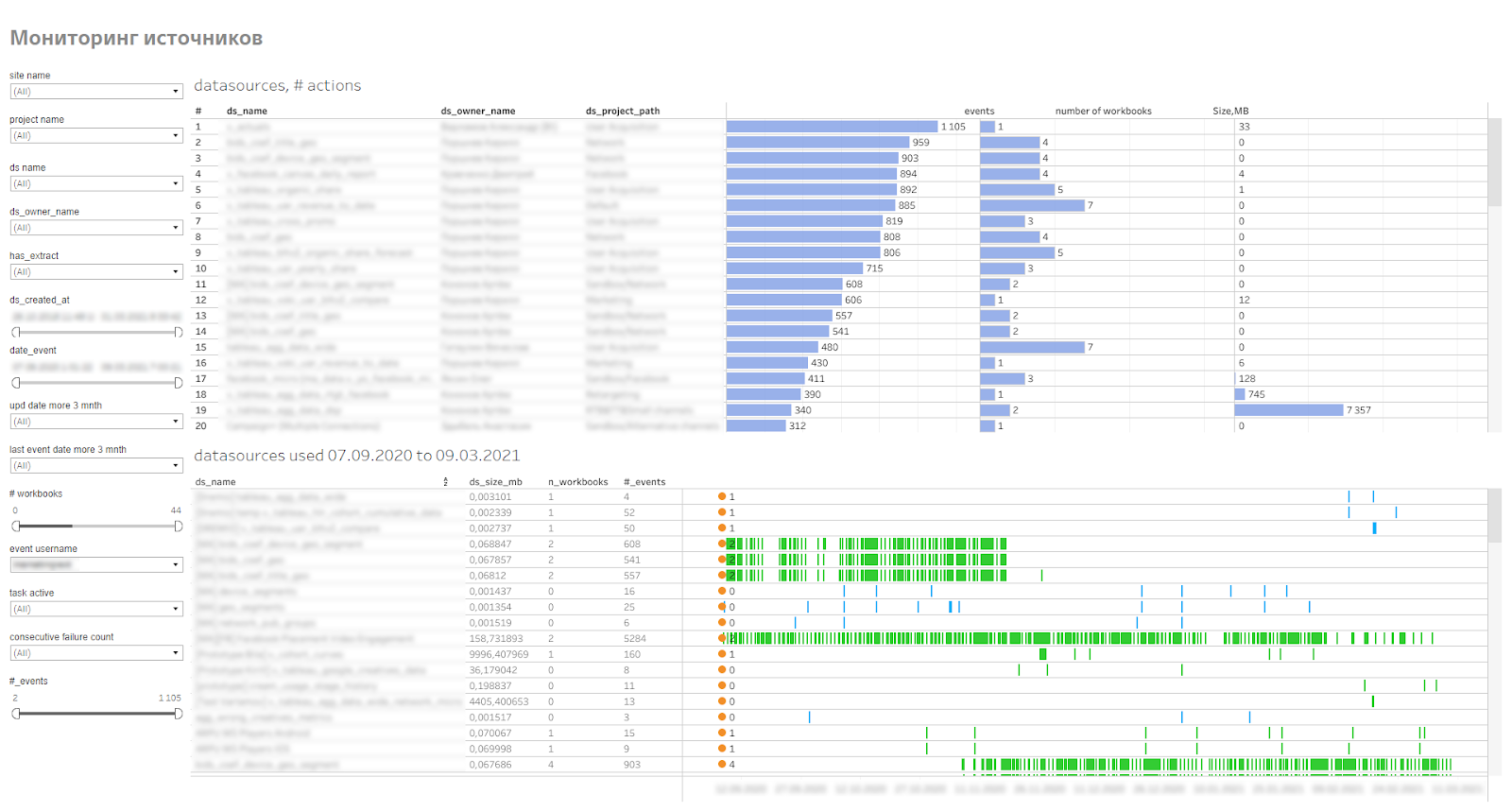
Quellüberwachungs-Dashboard
Ergebnis
Wir verwenden seit 1,5 Jahren den Self-Service-Ansatz. Während dieser Zeit begannen 50 Benutzer, unabhängig mit Daten zu arbeiten. Dies reduzierte die Belastung des BI-Teams und ermöglichte es den Jungs, nicht zu warten, bis das BI-Team zu seiner spezifischen Aufgabe gekommen war, ein Dashboard zu entwickeln. Vor ungefähr 5 Monaten haben wir begonnen, andere Bereiche mit der Selbstanalyse zu verbinden.
Wir planen Schulungen zu Best Practices für Datenkompetenz und Visualisierung.
Es ist wichtig zu verstehen, dass der Self-Service-Prozess nicht schnell im gesamten Unternehmen implementiert werden kann. Dies wird einige Zeit dauern. Wenn der Übergangsprozess organisch ist, ohne die Mitarbeiter zu schockieren, können Sie nach einigen Jahren der Implementierung grundlegend unterschiedliche Prozesse für die Arbeit mit Daten in verschiedenen Abteilungen und Bereichen des Unternehmens erhalten.