
Daniel Lemire - Professor an der Korrespondenzuniversität von Quebec (TÉLUQ), der einen Weg gefunden hat, um das Doppelte sehr schnell zu analysieren - veröffentlichte zusammen mit dem Ingenieur John Kaiser von Microsoft einen weiteren Fund von ihnen: den UTF-8-Validator, der die UTF-8-CPP- Bibliothek übertrifft (2006) um 48..77 Uhr, DFA von Björn Hörmann (2009) - 20..45 Uhr und Google Fuchsia (2020) - 13..35 Uhr. Die Nachrichten zu dieser Veröffentlichung wurden bereits auf Habré veröffentlicht , jedoch ohne technische Details. Also machen wir dieses Manko wieder gut.
UTF-8-Anforderungen
Denken Sie zunächst daran, dass Unicode Codepunkte von U + 0000 bis U + 10FFFF zulässt, die in UTF-8 als Sequenzen von 1 bis 4 Byte codiert sind:
| Die Anzahl der Bytes in der Codierung | Die Anzahl der Bits im Codepunkt | Mindestwert | Höchster Wert |
|---|---|---|---|
| eins | 1..7 | U + 0000 = 0 0000000 | U + 007F = 0 1111111 |
| 2 | 8..11 | U + 0080 = 110 00010 10 000 000 | U + 07FF = 110 11111 10 111111 |
| 3 | 12..16 | U + 0800 = 1110 0000 10 100000 10 000000 | U + FFFF = 1110 1111 10 111111 10 111111 |
| vier | 17..21 | U + 010000 = 11110 000 10 010000 10 000000 10 000000 | U + 10FFFF = 11110 100 10 001111 10 111111 10 111111 |
Gemäß den Codierungsregeln bestimmen die höchstwertigen Bits des ersten Bytes der Sequenz die Gesamtzahl der Bytes in der Sequenz; Das höchstwertige Bit Null kann nur in ASCII-Zeichen (Single-Byte) stehen, zwei höchstwertige Einzelbits bezeichnen ein Multibyte-Zeichen, 1 und Null bezeichnen ein Fortsetzungsbyte> Multibyte-Zeichen.
Welche Art von Fehlern könnte eine auf diese Weise codierte Zeichenfolge enthalten?
- Unvollständige Sequenz : Ein führendes Byte oder ASCII-Zeichen wurde an der Stelle gefunden, an der ein Fortsetzungsbyte erwartet wurde.
- Ungeknöpfte Sequenz : Ein führendes Byte oder ein ASCII-Zeichen wurde an der Stelle erwartet, an der ein Fortsetzungsbyte angetroffen wurde.
- Sequenz zu lang : Das führende Byte
11111xxx
stimmt mit einer Sequenz von fünf Byte oder länger überein, die in UTF-8 nicht zulässig ist. - Über Unicode-Grenzen hinaus : Nach dem Decodieren der Vier-Byte-Sequenz ist der Codepunkt höher als U + 10FFFF.
Wenn die Zeile keinen dieser vier Fehler enthält, kann sie in eine Folge korrekter Codepunkte decodiert werden. UTF-8 erfordert jedoch mehr - dass jede Sequenz korrekter Codepunkte eindeutig codiert wird. Dies fügt zwei weitere Arten möglicher Fehler hinzu:
- : code point ;
- : code points U+D800 U+DFFF UTF-16, code point U+FFFF. UTF-8 , code points , .
Bei der selten verwendeten CESU-8- Codierung wird die letzte Anforderung aufgehoben (und bei MUTF-8 ist es auch die vorletzte), wodurch die Sequenzlänge auf drei Bytes begrenzt ist, die Entschlüsselung und Validierung von Zeichenfolgen jedoch kompliziert ist. Beispielsweise wird das Emoticon U + 1F600 GRINNING FACE in UTF-16 als Ersatzpaar dargestellt
0xD83D 0xDE00
, und CESU-8 / MUTF-8 übersetzt es in ein Paar von Drei-Byte-Sequenzen
0xED 0xA0 0xBD 0xED 0xB8 0x80
. In UTF-8 wird dieser Smiley jedoch in einer Vier-Byte-Sequenz codiert
0xF0 0x9F 0x98 0x80
.
Für jede Art von Fehler sind die folgenden Bitsequenzen, die dazu führen:
| Unvollendete Sequenz | 2. Byte fehlt | 11xxxxxx 0xxxxxxx
|
11xxxxxx 11xxxxxx
|
||
| Fehlendes 3. Byte | 111xxxxx 10xxxxxx 0xxxxxxx
|
|
111xxxxx 10xxxxxx 11xxxxxx
|
||
| 4. Byte fehlt | 1111xxxx 10xxxxxx 10xxxxxx 0xxxxxxx
|
|
1111xxxx 10xxxxxx 10xxxxxx 11xxxxxx
|
||
| Ungeätzte Sequenz | Zusätzliches 2. Byte | 0xxxxxxx 10xxxxxx
|
| Zusätzliches 3. Byte | 110xxxxx 10xxxxxx 10xxxxxx
|
|
| Zusätzliches 4. Byte | 1110xxxx 10xxxxxx 10xxxxxx 10xxxxxx
|
|
| Zusätzliches 5. Byte | 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
|
|
| Zu lange Sequenz | 11111xxx
|
|
| Unicode-Grenzen überschreiten | U + 110000..U + 13FFFF | 11110100 1001xxxx
|
11110100 101xxxxx
|
||
| ≥ U + 140.000 | 11110101
|
|
1111011x
|
||
| Nicht minimale Konsistenz | 2 Byte | 1100000x
|
| 3 Byte | 11100000 100xxxxx
|
|
| 4 Byte | 11110000 1000xxxx
|
|
| Surrogate | 11101101 101xxxxx
|
|
Validierung von UTF-8
Mit dem naiven Ansatz, der in der UTF-8-CPP-Bibliothek des Serben Nemanja Trifunovic verwendet wird, wird die Validierung in einer Kaskade verschachtelter Zweige durchgeführt:
const octet_difference_type length = utf8::internal::sequence_length(it);
// Get trail octets and calculate the code point
utf_error err = UTF8_OK;
switch (length) {
case 0:
return INVALID_LEAD;
case 1:
err = utf8::internal::get_sequence_1(it, end, cp);
break;
case 2:
err = utf8::internal::get_sequence_2(it, end, cp);
break;
case 3:
err = utf8::internal::get_sequence_3(it, end, cp);
break;
case 4:
err = utf8::internal::get_sequence_4(it, end, cp);
break;
}
if (err == UTF8_OK) {
// Decoding succeeded. Now, security checks...
if (utf8::internal::is_code_point_valid(cp)) {
if (!utf8::internal::is_overlong_sequence(cp, length)){
// Passed! Return here.
Innen
sequence_length()
und
is_overlong_sequence()
auch verzweigt je nach Länge der Sequenz. Wenn Sequenzen unterschiedlicher Länge unvorhersehbar in der Eingabezeichenfolge verschachtelt sind, kann der Verzweigungsprädiktor nicht vermeiden, die Pipeline für jedes verarbeitete Zeichen mehrmals zu leeren.
Ein effizienterer Ansatz für die UTF-8-Validierung besteht darin, eine Zustandsmaschine mit 9 Zuständen zu verwenden: (Der Fehlerzustand wird im Diagramm nicht angezeigt.)
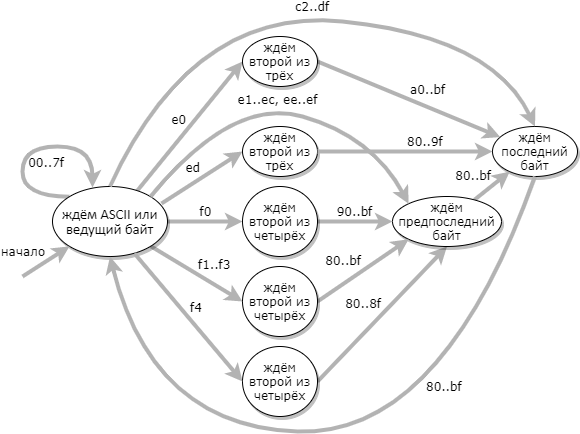
Wenn die Automatenübergangstabelle erstellt wird, ist der Validierungscode sehr einfach:
uint32_t type = utf8d[byte];
*codep = (*state != UTF8_ACCEPT) ?
(byte & 0x3fu) | (*codep << 6) :
(0xff >> type) & (byte);
*state = utf8d[256 + *state + type];
Hier werden für jedes verarbeitete Zeichen dieselben Aktionen ohne bedingte Übergänge wiederholt - daher sind keine Pipe-Resets erforderlich. Andererseits wird bei jeder Iteration
utf8d
zusätzlich zum Lesen des Eingabezeichens ein zusätzlicher Speicherzugriff (auf die Sprungtabelle ) durchgeführt.
Lemir und Kaiser nahmen das gleiche DFA als Grundlage für ihren Validator und erreichten aufgrund der Anwendung von drei Verbesserungen eine zehnfache Beschleunigung:
- Die Sprungtabelle wurde von 364 Bytes auf 48 reduziert, so dass sie vollständig in drei Vektorregister (jeweils 128 Bit) passt und Speicherzugriffe nur zum Lesen der Eingabezeichen erforderlich sind.
- Blöcke von 16 benachbarten Bytes werden parallel verarbeitet;
- Wenn ein 16-Byte-Block vollständig aus ASCII-Zeichen besteht, ist bekannt, dass er korrekt ist, und es ist keine gründlichere Prüfung erforderlich. Dieses "Stück des Pfades" beschleunigt die Verarbeitung von "realistischen" Texten, die ganze Sätze im lateinischen Alphabet enthalten, zwei- bis dreimal; Bei zufälligen Texten, bei denen das lateinische Alphabet, Hieroglyphen und Emoticons gleichmäßig gemischt sind, beschleunigt sich dies jedoch nicht.
Die Implementierung jeder dieser Verbesserungen weist subtile Feinheiten auf, die es wert sind, im Detail betrachtet zu werden.
Sprungtabelle reduzieren
Die erste Verbesserung basiert auf der Beobachtung, dass es zur Erkennung der meisten Fehler (12 ungültige Bitsequenzen von den 19 in der obigen Tabelle aufgeführten) ausreicht, die ersten 12 Bits der Sequenz zu überprüfen:
| Unvollendete Sequenz | 2. Byte fehlt | 11xxxxxx 0xxxxxxx
|
0x02
|
11xxxxxx 11xxxxxx
|
|||
| Ungeätzte Sequenz | Zusätzliches 2. Byte | 0xxxxxxx 10xxxxxx
|
0x01
|
| Zu lange Sequenz | 11111xxx 1000xxxx
|
0x20
|
|
11111xxx 1001xxxx
|
0x40
|
||
11111xxx 101xxxxx
|
|||
| Unicode-Grenzen überschreiten | U + 1 [1235679ABDEF] xxxx | 111101xx 1001xxxx
|
|
111101xx 101xxxxx
|
|||
| U + 1 [48C] xxxx | 11110101 1000xxxx
|
0x20
|
|
1111011x 1000xxxx
|
|||
| Nicht minimale Konsistenz | 2 Byte | 1100000x
|
0x04
|
| 3 Byte | 11100000 100xxxxx
|
0x10
|
|
| 4 Byte | 11110000 1000xxxx
|
0x20
|
|
| Surrogate | 11101101 101xxxxx
|
0x08
|
|
Für jeden dieser potenziellen Fehler haben die Forscher eines von sieben Bits zugewiesen, wie in der Spalte ganz rechts gezeigt. (Die zugewiesenen Bits unterscheiden sich zwischen ihrem veröffentlichten Artikel und ihrem GitHub-Code . Hier sind die Werte aus dem Artikel.) Um mit sieben Bits auszukommen, mussten die beiden Unicode-Unterfälle außerhalb der Grenzen neu partitioniert werden, sodass der zweite neu partitioniert wurde ist mit einer nicht-minimalen 4-Byte-Sequenz verkettet; und der zu lange Sequenzfall wird in drei Unterfälle aufgeteilt und mit den Unicode-Unterfällen außerhalb der Grenzen kombiniert.
So wurden mit der Hörmann DKA folgende Änderungen vorgenommen:
- Die Eingabe erfolgt nicht per Byte, sondern per Tetrade (Nibble);
- Der Automat wird als nicht deterministische Verarbeitung jeder Tetrade verwendet, die den Automaten zwischen Teilmengen aller möglichen Zustände überträgt;
- Acht korrekte Zustände werden zu einem zusammengefasst, aber ein fehlerhafter Zustand wird in sieben geteilt;
- Drei benachbarte Tetraden werden nicht nacheinander, sondern unabhängig voneinander verarbeitet, und das Ergebnis wird als Schnittpunkt von drei Sätzen von Endzuständen erhalten.
Dank dieser Änderungen reichen drei Tabellen mit 16 Bytes aus, um alle möglichen Übergänge zu beschreiben: Jedes Element der Tabelle wird als Bitfeld verwendet, in dem alle möglichen Endzustände aufgelistet sind. Drei dieser Elemente sind miteinander UND-verknüpft. Wenn das Ergebnis Bits ungleich Null enthält, wurde ein Fehler festgestellt.
| Tetrad | Wert | Mögliche Fehler | Der Code |
|---|---|---|---|
| Hoch im ersten Byte | 0-7 | 2- | 0x01
|
| 8–11 | () | 0x00
|
|
| 12 | 2- ; 2- | 0x06
|
|
| 13 | 2- | 0x02
|
|
| 14 | 2- ; 2- ; | 0x0E
|
|
| 15 | 2- ; ; Unicode; 4- | 0x62
|
|
| 0 | 2- ; 2- ; | 0x37
|
|
| 1 | 2- ; 2- ; 2- | 0x07
|
|
| 2–3 | 2- ; 2- | 0x03
|
|
| 4 | 2- ; 2- ; Unicode | 0x43
|
|
| 5–7 | 0x63
|
||
| 8–10, 12–15 | 2- ; 2- ; | ||
| 11 | 2- ; 2- ; ; | 0x6B
|
|
| 0–7, 12–15 | Das 2. Byte fehlt; zu lange Sequenz; Nicht-minimale 2-Byte-Sequenz | 0x06
|
|
| 8 | Zusätzliches 2. Byte; zu lange Sequenz; über Unicode-Grenzen hinausgehen; nicht minimale Konsistenz | 0x35
|
|
| neun | 0x55
|
||
| 10-11 | Zusätzliches 2. Byte; zu lange Sequenz; über Unicode-Grenzen hinausgehen; Nicht-minimale 2-Byte-Sequenz; Ersatz | 0x4D
|
Es gibt 7 weitere ungültige Bitsequenzen, die nicht verarbeitet wurden:
| Unvollendete Sequenz | Fehlendes 3. Byte | 111xxxxx 10xxxxxx 0xxxxxxx
|
111xxxxx 10xxxxxx 11xxxxxx
|
||
| 4. Byte fehlt | 1111xxxx 10xxxxxx 10xxxxxx 0xxxxxxx
|
|
1111xxxx 10xxxxxx 10xxxxxx 11xxxxxx
|
||
| Ungeätzte Sequenz | Zusätzliches 3. Byte | 110xxxxx 10xxxxxx 10xxxxxx
|
| Zusätzliches 4. Byte | 1110xxxx 10xxxxxx 10xxxxxx 10xxxxxx
|
|
| Zusätzliches 5. Byte | 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
|
Und hier ist das höchstwertige Bit nützlich, das in den Übergangstabellen umsichtig nicht verwendet wird: Es entspricht einer Folge von Bits
10xxxxxx 10xxxxxx
, d. H. zwei aufeinanderfolgende Bytes. Wenn Sie nun drei Notebooks überprüfen, können Sie entweder einen Fehler erkennen oder ein Ergebnis liefern
0x00
oder
0x80
. Und dieses Ergebnis der ersten Prüfung - zusammen mit dem ersten Notizbuch - reicht uns:
| Fehlendes 3. Byte | 111xxxxx 10xxxxxx 0xxxxxxx
|
|
111xxxxx 10xxxxxx 11xxxxxx
|
||
| 4. Byte fehlt | 1111xxxx 10xxxxxx 10xxxxxx 0xxxxxxx
|
|
1111xxxx 10xxxxxx 10xxxxxx 11xxxxxx
|
||
| Zusätzliches 3. Byte | 110xxxxx 10xxxxxx 10xxxxxx
|
|
| Zusätzliches 4. Byte | 1110xxxx 10xxxxxx 10xxxxxx 10xxxxxx
|
|
| Zusätzliches 5. Byte | 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
|
|
| Zulässige Kombinationen |
|
|
|
||
Dies bedeutet, dass zur Durchführung der Prüfung ausreichend ist, um sicherzustellen, dass jedes Ergebnis
0x80
einer der beiden gültigen Kombinationen entspricht.
Vektorisierung
Wie werden Blöcke mit 16 benachbarten Bytes parallel verarbeitet? Die zentrale Idee besteht darin, den Befehl
pshufb
als 16 gleichzeitige Ersetzungen gemäß einer 16-Byte-Tabelle zu verwenden. Für die zweite Prüfung müssen Sie im Block alle Bytes des Formulars finden
111xxxxx
und
1111xxxx
; Da es bei Intel keinen vorzeichenlosen Vektorvergleich gibt, wird er durch Sättigungssubtraktion (
psubusb
) ersetzt.
Die Simdjson-Quellen sind schwer zu lesen, da der gesamte Code in einzeilige Funktionen unterteilt ist. Der gesamte Validator-Pseudocode sieht ungefähr so aus:
prev = vector(0)
while !input_exhausted:
input = vector(...)
prev1 = prev<<120 | input>>8
prev2 = prev<<112 | input>>16
prev3 = prev<<104 | input>>24
#
nibble1 = prev1.shr(4).lookup(table1)
nibble2 = prev1.and(15).lookup(table2)
nibble3 = input.shr(4).lookup(table3)
result1 = nibble1 & nibble2 & nibble3
#
test1 = prev2.saturating_sub(0xDF) # 111xxxxx => >0
test2 = prev3.saturating_sub(0xEF) # 1111xxxx => >0
result2 = (test1 | test2).gt(0) & vector(0x80)
# result1 0x80 , result2,
#
if result1 != result2:
return false
prev = input
return true
Befindet sich eine falsche Sequenz am rechten Rand des allerletzten Blocks, wird sie von diesem Code nicht erkannt. Um sich nicht darum zu kümmern, können Sie die Eingabezeichenfolge mit Null Bytes ergänzen, sodass Sie am Ende einen Block vollständig Null erhalten. Stattdessen hat simdjson eine spezielle Prüfung für die letzten Bytes durchgeführt: Damit eine Zeichenfolge korrekt ist, muss das allerletzte Byte streng kleiner
0xC0
, das vorletzte Byte streng kleiner
0xE0
und das dritte vom Ende streng weniger sein
0xF0
.
Die letzte Verbesserung, die Lemierre und Kaiser entwickelt haben, ist der ASCII-Cut-Off. Es ist sehr einfach festzustellen, dass der aktuelle Block nur ASCII-Zeichen enthält:
input & vector(0x80) == vector(0)
... In diesem Fall reicht es aus, sicherzustellen, dass sich keine falschen Sequenzen an der Grenze befinden,
prev
und
input
- und Sie können mit dem nächsten Block fortfahren. Diese Prüfung wird auf die gleiche Weise wie am Ende der Eingabezeichenfolge durchgeführt. Der vorzeichenlose Vektorvergleich mit
[..., 0x0, 0xE0, 0xC0]
, der bei Intel nicht verfügbar ist, wird durch die Berechnung des Vektormaximums (
pmaxub
) und dessen Vergleich mit demselben Vektor ersetzt.
Das Überprüfen auf ASCII stellt sich als der einzige Zweig innerhalb der Validator-Iteration heraus. Um diesen Zweig erfolgreich vorherzusagen, reicht es aus, dass die Eingabezeichenfolge ASCII-Blöcke nicht vollständig mit Blöcken verschachtelt, die Nicht-ASCII-Zeichen enthalten. Die Forscher fanden heraus, dass noch bessere Ergebnisse bei realen Texten erzielt werden können, indem die ODER-Verkettung von vier benachbarten Blöcken auf ASCII überprüft und bei ASCII alle vier Blöcke übersprungen werden. In der Tat kann man erwarten, dass, wenn der Autor des Textes im Prinzip Nicht-ASCII-Zeichen verwendet, diese mindestens alle 64 Zeichen auftreten, was ausreicht, um den Übergang vorherzusagen.
