In der Anfangszeit waren Router normale Computer mit an den Bus angeschlossenen Netzwerkkarten (Network Interface Cards, NICs).

Abbildung 1 - An den Bus angeschlossene Netzwerkkarten.
Bis zu einem gewissen Punkt funktionierte ein solches System. In dieser Architektur wurden Pakete in die Netzwerkkarte eingegeben und von der CPU von der Netzwerkkarte in den Speicher übertragen. Die CPU traf die Weiterleitungsentscheidung und gab das Paket an die externe Netzwerkkarte aus. CPU und Speicher sind zentralisierte Ressourcen mit eingeschränkter Geräteunterstützung. Der Bus war auch eine zusätzliche Einschränkung: Die Busbandbreite musste gleichzeitig die Bandbreite aller Netzwerkkarten unterstützen.
Wenn das Netzwerk vergrößert werden muss, treten sehr schnell Probleme auf. Sie können einen schnelleren Prozessor kaufen, aber wie erhöhen Sie die Busleistung? Wenn Sie die Busgeschwindigkeit verdoppeln, müssen Sie die Busschnittstellengeschwindigkeit auf jeder Netzwerkkarte und CPU verdoppeln. Dies erhöht die Kosten aller Karten, auch wenn sich die Kapazität einer einzelnen Netzwerkkarte nicht erhöht.
Lektion eins: Die Kosten eines Routers sollten linear mit seinen Fähigkeiten steigen
Trotz der gewonnenen Erkenntnisse bestand eine bequeme Lösung für das Upscaling darin, einen weiteren Bus und Prozessor hinzuzufügen:

Abbildung 2 - Die Lösung für das Problem der Skalierung des Systems bestand darin, einen neuen Bus und einen neuen Prozessor hinzuzufügen.
Die Arithmetic Logic Unit (ALU) war ein DSP-Chip (Digital Signal Processing), der aufgrund seines überlegenen Preis-Leistungs-Verhältnisses ausgewählt wurde. Der zusätzliche Bus erhöhte die Bandbreite, aber die Architektur wurde ohnehin nicht größer. Mit anderen Worten, es hätten nicht mehr ALUs und Busse hinzugefügt werden können, um die Produktivität zu steigern.
Da ALUs immer noch eine erhebliche Einschränkung darstellten, bestand der nächste Schritt darin, der Architektur ein Field Programmable Gate Array (FPGA) hinzuzufügen, um die LPM-Suchlast (Longest Prefix Match) zu verringern.

Abbildung 3 - Der nächste Schritt war das Hinzufügen des Field Programmable Gate Array.
Obwohl dies half, löste es das Problem nicht vollständig. ALU war immer noch überwältigt. LPMs machten den größten Teil der Last aus, aber die zentralisierte Architektur war immer noch nicht gut skalierbar, selbst wenn wir einige Probleme beseitigt hatten.
Lektion zwei: LPM kann in Silizium implementiert werden und ist kein Hindernis für die Leistung
Trotz dieser Lektion wurde der nächste Schritt in eine andere Richtung unternommen: Ersetzen von ALU und FPGA durch einen Standardprozessor. Die Designer versuchten zu skalieren, indem sie mehr CPUs und mehr Busse hinzufügten. Selbst eine geringfügige Leistungssteigerung erforderte viel Aufwand, und das System litt immer noch unter den Bandbreitenbeschränkungen des zentralisierten Busses.
In dieser Phase der Entwicklung des Internets kamen ernstere Kräfte ins Spiel. Als das Web in der Öffentlichkeit populär wurde, wurde das Potenzial des Internets immer deutlicher. Telcos erwarb regionale NSFnet-Netze und begann mit dem Bau von Gewerbekomplexen. Anwendungsspezifische integrierte Schaltkreise (ASICs) haben sich als bewährte Technologien erwiesen, mit denen mehr Funktionen direkt in Silizium implementiert werden können. Die Nachfrage nach Routern ist in die Höhe geschossen, und die Notwendigkeit signifikanter Verbesserungen der Skalierbarkeit hat den technischen Konservatismus endgültig zunichte gemacht. Um dieser Nachfrage gerecht zu werden, haben viele Startups eine breite Palette möglicher Lösungen entwickelt.
Die geplante Querlatte wurde zu einer der Alternativen:

Abbildung 4 - Geplante Querlatte.
In dieser Architektur hatte jede Netzwerkkarte einen Eingang und einen Ausgang. Der NIC-Prozessor traf die Weiterleitungsentscheidung, wählte die Ausgangs-NIC aus und schickte eine Planungsanforderung an den Switch (Crossbar). Der Scheduler erhielt alle Anforderungen von den NICs, erarbeitete die optimale Lösung, programmierte die Lösung in den Switch und leitete die Eingaben für die Übertragung.
Das Problem bei diesem Schema bestand darin, dass jeder Ausgang jeweils einen Eingang "abhören" konnte und der Internetverkehr pulsierte. Wenn zwei Pakete denselben Ausgang erreichen mussten, musste eines von ihnen warten. Das Warten auf ein Paket führte dazu, dass andere Pakete auf denselben Eingang warteten. Danach litt das System unter Head Of Line Blocking (HOLB), was zu einer sehr schlechten Routerleistung führte.
Lektion drei: Die interne Struktur des Routers sollte auch unter Lastbedingungen keine Signale blockieren
Die Migration zu spezialisierten Chips motivierte Designer auch zur Migration zu internen zellbasierten Strukturen, da das Wechseln kleiner Zellen mit fester Größe viel einfacher ist als der Umgang mit Paketen variabler Länge, die manchmal groß sind. Die Verwendung der Vermittlungszellen bedeutete jedoch auch, dass der Scheduler mit einer höheren Frequenz ausgeführt werden musste, was das Scheduling viel schwieriger machte.
Ein weiterer innovativer Ansatz bestand darin, die Netzwerkkarte in einen Torus zu integrieren:

Abbildung 5 - Torusförmige Netzwerkkarte.
In einem solchen Schema hatte jede Netzwerkkarte Verbindungen zu vier Nachbarn, und die Eingangs-Netzwerkkarte musste einen Pfad durch die Struktur berechnen, um die Ausgangsleitungskarte zu erreichen. Dieses System hatte Probleme - die Bandbreite war nicht dieselbe. Die Übertragungsbreite in Nord-Süd-Richtung war höher als in Ost-West-Richtung. Wenn sich das eingehende Verkehrsmuster von Ost nach West bewegen würde, würde es zu einer Überlastung kommen.
Lektion 4: Die interne Struktur des Routers muss eine gleichmäßige Bandbreitenverteilung aufweisen, da wir die Verteilung des Datenverkehrs nicht vorhersagen können.
Ein völlig anderer Ansatz bestand darin, ein vollständiges NIC-NIC-Kommunikationsnetzwerk zu erstellen und Zellen auf alle NICs zu verteilen:
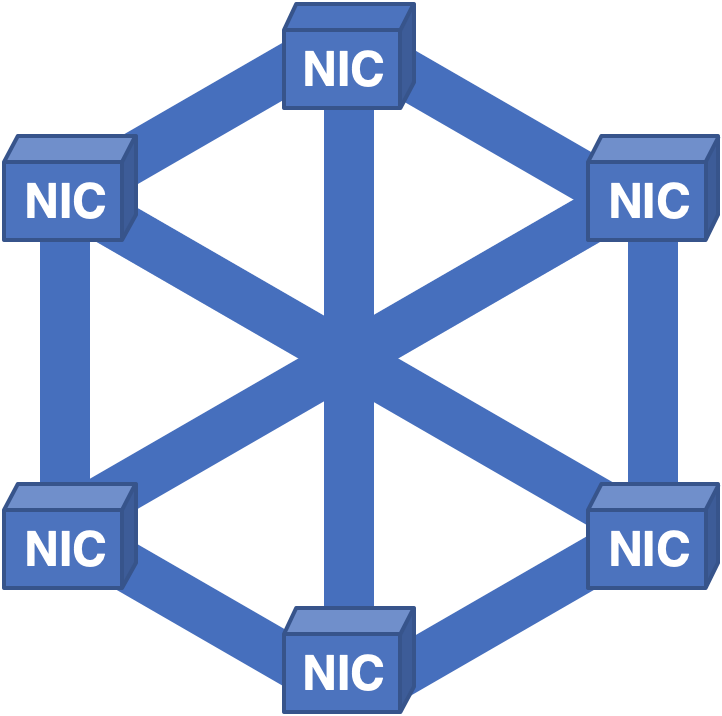
Abbildung 6 - Vollständig verbundene Struktur mit Verteilung der Zellen auf alle Netzwerkkarten.
Trotz des Lernens der vorherigen Lektionen wurden neue Probleme identifiziert. In dieser Architektur funktionierte alles gut genug, bis die Platine zur Reparatur entfernt werden musste. Da jede Netzwerkkarte Zellen für alle Pakete im System enthielt, konnte beim Entfernen der Karte keines der Pakete neu erstellt werden, was zu kurzen, aber schmerzhaften Ausfallzeiten führte.
Lektion 5: Router sollten keinen einzigen Fehlerpunkt haben
Wir haben diese Architektur sogar auf den Kopf gestellt:
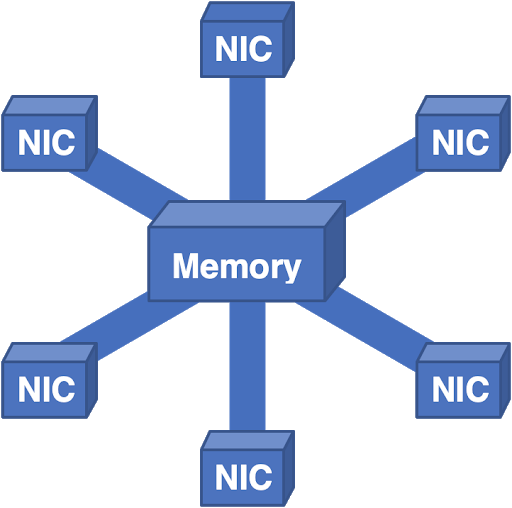
Abbildung 7 - Hier gehen alle Pakete in den zentralen Speicher und dann in die Ausgangs-NIC.
Dieses System funktionierte ziemlich gut, aber die Speicherskalierung wurde zu einem Problem. Sie können nur einige Controller und Speicherbänke hinzufügen, aber irgendwann wird die Gesamtbandbreite für das physische Design zu komplex. Angesichts praktischer körperlicher Einschränkungen waren wir gezwungen, in andere Richtungen zu denken.
Das Telefonnetz ist für uns zu einer Inspirationsquelle geworden. Vor langer Zeit erkannte Charles Close, dass skalierbare Switches durch den Aufbau von Netzwerken kleinerer Switches hergestellt werden können. Wie sich herausstellte, sind alle wunderbaren Eigenschaften, die wir brauchen, im Clos-Netzwerk vorhanden:

Abbildung 8 - Netzwerk schließen.
Netzwerkeigenschaften schließen:
- Die Kraft wächst mit der Größe.
- Hat keinen einzigen Fehlerpunkt.
- Erhält eine ausreichende Redundanz für die Fehlertoleranz.
- Bewältigt Überlastungen, indem die Last auf die Struktur verteilt wird.
Wir implementieren Ein- und Ausgänge immer zusammen, daher falten wir dieses Bild normalerweise entlang der gepunkteten Linie. Dies führt zu einem gefalteten Clos-Netzwerk, und dies verwenden wir heute in Routern mit mehreren Fällen: Einige Fälle haben eine Netzwerkkarte und eine Schicht von Switches, in anderen - zusätzliche Schichten von Switches.

Abbildung 9 - Collapsed Clos-Netzwerk
Leider hat auch diese Architektur ihre eigenen Probleme. Das Format der zwischen Switches verwendeten Zellen ist proprietär und gehört dem Chiphersteller, was zu einer Abhängigkeit von Chipsätzen führt. Die Abhängigkeit von einem Chip-Anbieter ist nicht viel besser als die Abhängigkeit von einem einzelnen Router-Anbieter. Die Probleme sind dieselben: Preisgestaltung und Verfügbarkeit von Geräten an eine einzige Quelle zu binden. Hardware-Upgrades sind eine Herausforderung, da der neue Zellen-Switch gleichzeitig ältere Verbindungen und Zellenformate unterstützen muss, um die Interoperabilität sowie alle Verbindungsraten und Zellenformate neuer Geräte aufrechtzuerhalten.
Jede Zelle muss adressiert sein, um die Ausgangs-NIC anzugeben, an die sie Informationen senden muss. Eine solche Adressierung ist endlich, wodurch eine Skalierbarkeitsgrenze entsteht. Die Steuerung und Verwaltung in Routern mit mehreren Fällen ist immer noch vollständig proprietär, was zu einem weiteren Problem eines einzelnen Anbieters im Software-Stack führt.
Glücklicherweise können wir diese Probleme lösen, indem wir unsere Architekturphilosophie ändern. In den letzten fünfzig Jahren haben wir uns bemüht, Router zu skalieren. Wir haben aus der Erfahrung mit dem Aufbau großer Wolken gelernt, dass die Scale-Out-Philosophie oft erfolgreicher ist.
Die Scale-Out-Architektur verwendet eine Divide-and-Conquer-Strategie, anstatt einen riesigen, extrem schnellen Einzelserver zu erstellen. Ein Rack mit kleinen Servern kann den gleichen Job erledigen und ist gleichzeitig zuverlässiger, flexibler und kostengünstiger.
Dieser Ansatz gilt auch für Router. Ist es möglich, mehrere kleine Router in einer Clos-Topologie auszurichten, um ähnliche architektonische Vorteile zu erzielen und gleichzeitig Probleme im Zusammenhang mit dem Netz zu vermeiden? Wie sich herausstellte, ist dies nicht besonders schwierig:

Abbildung 10 - Ersetzen von Zellen-Switches durch Paket-Switches unter Beibehaltung der Clos-Topologie zur einfacheren Skalierung.
Durch Ersetzen der Zellen-Switches durch Paket-Switches und Beibehalten der Clos-Topologie bieten wir eine einfache Skalierbarkeit.
Die Skalierung ist in zwei Dimensionen möglich: entweder Hinzufügen neuer Ingress-Router und Paket-Switches parallel zu vorhandenen Layern oder Hinzufügen zusätzlicher Switch-Layer. Da einzelne Router heutzutage ziemlich standardisiert sind, vermeiden wir die Abhängigkeit von einem einzelnen Anbieter. Alle Verbindungen verwenden Standard-Ethernet, sodass keine Kompatibilitätsprobleme auftreten.
Upgrades sind unkompliziert und unkompliziert: Wenn der Switch mehr Kanäle benötigt, können Sie ihn einfach durch einen größeren Switch ersetzen. Wenn Sie einen separaten Kanal aktualisieren müssen und beide Enden des Kanals über diese Funktion verfügen, müssen Sie nur die Optik aktualisieren. Unterschiedliche Übertragungsraten unterschiedlicher Verbindungen innerhalb einer Fabric sind kein Problem, da jeder Router als Raten-Mapper fungiert.
Diese Architektur ist bereits in der Welt der Rechenzentren beliebt und wird je nach Anzahl der Switch-Schichten als Leaf-Spine- oder Super-Spine-Architektur bezeichnet. Es hat sich als äußerst zuverlässig, stabil und flexibel erwiesen.
Aus Sicht der Übertragungsebene ist klar, dass dies eine praktikable Alternative zur Architektur ist. Es bleiben Probleme mit der Steuerebene und der Steuerebene. Das Skalieren der Steuerebene erfordert eine Verbesserung der Skalierung unserer Steuerprotokolle um eine Größenordnung. Wir versuchen, dies zu implementieren, indem wir die Abstraktionsmechanismen verbessern, indem wir eine Proxy-Darstellung der Architektur erstellen, die die gesamte Topologie als einen einzelnen Knoten beschreibt.
Ebenso arbeiten wir an der Entwicklung von Abstraktionen der Steuerebene, mit denen wir die gesamte Clos-Struktur als einen einzigen Router steuern können. Diese Arbeit wird als offener Standard durchgeführt, daher ist keine der beteiligten Technologien proprietär.
Im Laufe von fünfzig Jahren haben sich Router-Architekturen sprunghaft weiterentwickelt, und bei der Suche nach Kompromissen zwischen verschiedenen Technologien wurden viele Fehler gemacht. Offensichtlich ist unsere Entwicklung noch nicht abgeschlossen. In jeder Iteration haben wir die Probleme der vorherigen Generation angegangen und neue Herausforderungen entdeckt.
Wenn wir unsere bisherigen und aktuellen Erfahrungen sorgfältig studieren, können wir hoffentlich zu einer flexibleren und zuverlässigeren Architektur übergehen und zukünftige Verbesserungen erzielen, ohne die Hardware vollständig zu ersetzen.