
Wir bei ForePaaS experimentieren seit einiger Zeit mit DevOps - zuerst als Team und jetzt im gesamten Unternehmen. Der Grund ist einfach: Die Organisation wächst. Bisher hatten wir nur ein Team für alle Gelegenheiten. Sie befasste sich mit Produktarchitektur, Design und Sicherheit und reagierte schnell auf jedes Problem. Jetzt sind wir nach Spezialisierung in mehrere Teams unterteilt: Front-End, Back-End, Entwicklung, Betrieb ...
Wir haben erkannt, dass unsere vorherigen Methoden nicht so effektiv sind und wir etwas ändern müssen, während wir die Geschwindigkeit beibehalten, ohne Qualität und Laster zu beeinträchtigen umgekehrt.
Früher haben wir die Team-Entwickler angerufen, die tatsächlich Ops durchgeführt haben und auch für die Entwicklung im Backend verantwortlich waren. Einmal pro Woche teilten andere Entwickler dem DevOps-Team mit, welche neuen Services in der Produktion bereitgestellt werden müssen. Dies führte manchmal zu Problemen. Einerseits verstand das DevOps-Team nicht wirklich, was mit den Entwicklern geschah, andererseits fühlten sich die Entwickler nicht für ihre Dienste verantwortlich.
Vor kurzem haben die Mitarbeiter von DevOps versucht, diese Verantwortung bei den Entwicklern zu wecken - für die Verfügbarkeit, Zuverlässigkeit und Qualität des Service-Codes. Zunächst mussten wir die Entwickler beruhigen, die von der Last, die auf sie gefallen war, alarmiert waren. Sie benötigten mehr Informationen, um aufkommende Probleme zu diagnostizieren, und so beschlossen wir, die Systemüberwachung zu implementieren.
In diesem Artikel werden wir darüber sprechen, was Überwachung ist und womit sie gegessen wird, etwas über die sogenannten vier goldenen Signale lernen und diskutieren, wie Metriken und Drilldowns verwendet werden, um aktuelle Probleme zu untersuchen.
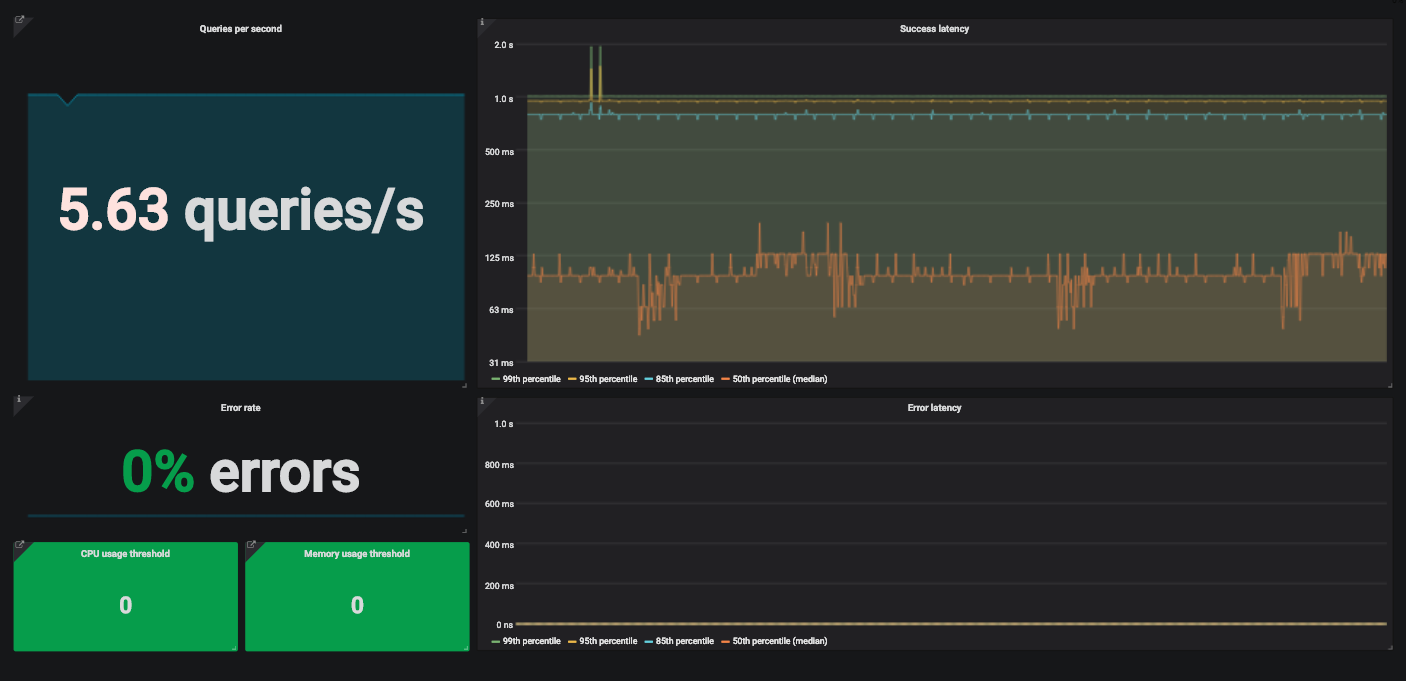
Ein Beispiel für ein Grafana-Dashboard mit vier goldenen Signalen zur Überwachung eines Dienstes.
Was ist Überwachung?
Überwachung ist die Erstellung, Erfassung, Aggregation und Verwendung von Metriken, die Einblick in den Zustand eines Systems geben.
Um ein System zu überwachen, benötigen wir Informationen zu seinen Software- und Hardwarekomponenten. Solche Informationen können durch Metriken erhalten werden, die unter Verwendung eines speziellen Programms oder einer Code-Instrumentierung gesammelt werden.
Instrumentation ändert Ihren Code, damit Sie seine Leistung messen können. Wir fügen Code hinzu, der die Funktionalität des Produkts selbst nicht beeinträchtigt, sondern lediglich Metriken berechnet und bereitstellt. Angenommen, wir möchten die Latenz einer Anforderung messen. Fügen Sie einen Code hinzu, der berechnet, wie lange es dauert, bis der Dienst die empfangene Anforderung verarbeitet.
Die auf diese Weise erstellte Metrik muss noch gesammelt und mit anderen kombiniert werden. Dies erfolgt normalerweise mit Metricbeat für die Erfassung und Logstash für die Indizierung von Metriken in Elasticsearch . Dann können diese Metriken für Ihre eigenen Zwecke verwendet werden. In der Regel wird dieser Stapel durch Kibana ergänzt , das in Elasticsearch indizierte Daten rendert.
Warum überwachen?
Sie müssen das System aus verschiedenen Gründen überwachen. Beispielsweise überwachen wir den aktuellen Status des Systems und seine Variationen, um Warnungen zu generieren und Dashboards zu füllen. Wenn wir eine Warnung erhalten, suchen wir im Dashboard nach den Gründen für den Fehler. Manchmal wird die Überwachung verwendet, um zwei Versionen eines Dienstes zu vergleichen oder langfristige Trends zu analysieren.
Was ist zu überwachen?
Site Reliability Engineering enthält ein hilfreiches Kapitel zur Überwachung verteilter Systeme, in dem der Ansatz von Google zur Verfolgung der vier goldenen Signale beschrieben wird.

B. Beyer, C. Jones, N. Murphy & J. Petoff (2016) Site Reliability Engineering. Wie Google Produktionssysteme betreibt. O'Reilly. Kostenlose Online-Version: https://landing.google.com/sre/sre-book/toc/index.html
- — . . — , .
- — . API . , .
- . (, 500- ) . — , .
- , , . ? . . , , .
?
Nehmen Sie zum Beispiel den Technologie-Stack. Wir wählen normalerweise gängige Standardwerkzeuge anstelle von kundenspezifischen Lösungen. Außer wenn uns die verfügbare Funktionalität nicht ausreicht. Wir stellen die meisten Dienste in Kubernetes-Umgebungen bereit und instrumentieren den Code, um Metriken für jeden benutzerdefinierten Dienst abzurufen. Um diese Metriken zu sammeln und für Prometheus vorzubereiten, verwenden wir eine der Prometheus-Clientbibliotheken . Es gibt Client-Bibliotheken für fast alle gängigen Sprachen. In der Dokumentation finden Sie alles, was Sie zum Schreiben Ihrer eigenen Bibliothek benötigen.
Wenn es sich um einen Open Source-Dienst eines Drittanbieters handelt, nehmen wir normalerweise die von der Community vorgeschlagenen Exporteure. Exporteure sind der Code, der Metriken vom Service sammelt und für Prometheus formatiert. Sie werden normalerweise mit Diensten verwendet, die keine Prometheus-Metriken generieren.
Wir senden Metriken über die Pipeline und speichern sie in Prometheus als Zeitreihen. Darüber hinaus verwenden wir Kube-State-Metriken in Kubernetes, um Metriken zu sammeln und an Prometheus zu senden. Wir können dann Dashboards und Warnungen in Grafana mithilfe von Prometheus-Anforderungen erstellen . Wir werden hier nicht auf technische Details eingehen, sondern selbst mit diesen Tools experimentieren. Sie haben eine detaillierte Dokumentation, die Sie leicht herausfinden können.
Schauen wir uns beispielsweise eine einfache API an, die Datenverkehr empfängt und die empfangenen Anforderungen mithilfe anderer Dienste verarbeitet.
Verzögern
Die Latenz ist die Zeit, die zum Verarbeiten einer Anforderung benötigt wird. Wir messen die Latenz separat für erfolgreiche Anfragen und für Fehler. Wir wollen nicht, dass diese Statistiken verwechselt werden.
Die Gesamtlatenz wird normalerweise berücksichtigt, dies ist jedoch nicht immer eine gute Wahl. Es ist besser, die Latenzverteilung zu verfolgen, da sie den Verfügbarkeitsanforderungen besser entspricht. Der Anteil der Anforderungen, die schneller als ein bestimmter Schwellenwert verarbeitet werden, ist ein allgemeiner Service Level Indicator (SLI). Hier ist ein Beispiel für ein Service Level Objective (SLO) für dieses SLI:
"Innerhalb von 24 Stunden sollten 99% der Anfragen in weniger als 1 Sekunde bearbeitet werden."
Die visuellste Art, Latenzmetriken darzustellen, ist ein Zeitreihendiagramm. Wir legen Kennzahlen in Eimer und Exporteure sammeln sie jede Minute. Auf diese Weise können n-Quantile für Servicelatenzen berechnet werden.
Wenn 0 <n <1 ist und der Graph q Werte enthält, ist das n-Quantil dieses Graphen gleich einem Wert, der n * q von q Werten nicht überschreitet. Das heißt, das mittlere 0,5-Quantil eines Graphen mit x Datensätzen entspricht einem Wert, der die Hälfte der x Datensätze nicht überschreitet.
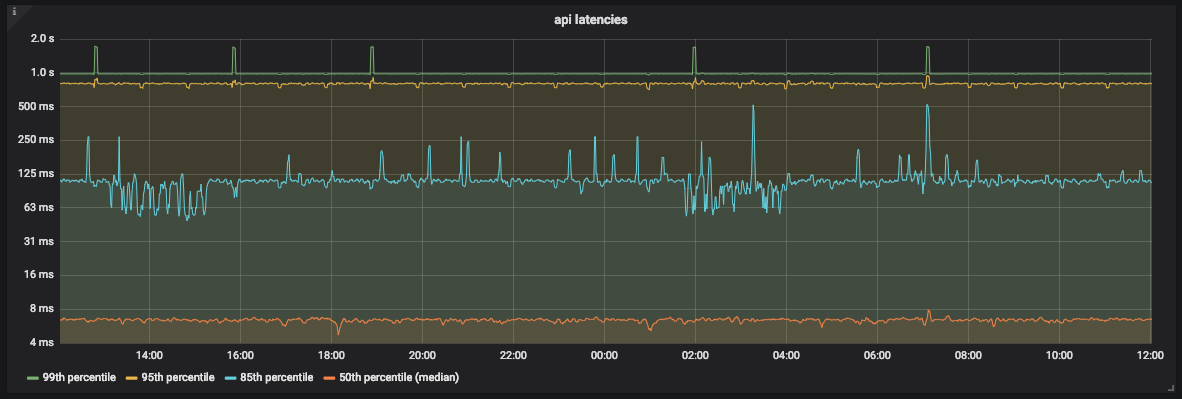
API-Latenzdiagramm
Wie Sie im Diagramm sehen können, verarbeitet die API 99% der Anforderungen meistens in weniger als 1 Sekunde. Es gibt jedoch auch Peaks um 2 Sekunden, die nicht unserem SLO entsprechen.
Da wir Prometheus verwenden, müssen wir bei der Auswahl der Schaufelgröße sehr vorsichtig sein. Prometheus ermöglicht lineare und exponentielle Schaufelgrößen. Es spielt keine Rolle, für welche wir uns entscheiden, solange Schätzfehler berücksichtigt werden .
Prometheus liefert keinen genauen Wert für das Quantil. Es bestimmt, in welchem Bucket sich das Quantil befindet, verwendet dann eine lineare Interpolation und berechnet einen ungefähren Wert.
Der Verkehr
Um den Datenverkehr für eine API zu messen, müssen Sie zählen, wie viele Anforderungen pro Sekunde empfangen werden. Da wir einmal pro Minute Metriken erfassen, erhalten wir für eine bestimmte Sekunde nicht den genauen Wert. Wir können jedoch die durchschnittliche Anzahl von Anfragen pro Sekunde mithilfe der Raten- und Zornfunktionen in Prometheus berechnen .
Um diese Informationen anzuzeigen, verwenden wir das Grafana SingleStat-Bedienfeld. Es zeigt die aktuellen durchschnittlichen Anforderungen pro Sekunde und Trends an.

Ein Beispiel für ein Grafana SingleStat-Panel mit der Anzahl der Anforderungen, die unsere API pro Sekunde empfängt.
Wenn sich die Anzahl der Anforderungen pro Sekunde plötzlich ändert, wird dies angezeigt . Wenn sich der Verkehr in wenigen Minuten halbiert, werden wir verstehen, dass es ein Problem gibt.
Fehler
Es ist einfach, den Prozentsatz offensichtlicher Fehler zu berechnen. Teilen Sie die HTTP 500-Antworten durch die Gesamtzahl der Anforderungen. Wie beim Verkehr verwenden wir hier einen Durchschnitt.
Das Intervall muss das gleiche sein wie für den Verkehr. Dies erleichtert das Verfolgen von fehlerhaftem Datenverkehr auf einem Panel.
Angenommen, die Fehlerrate beträgt in den letzten fünf Minuten 10% und die API verarbeitet 200 Anforderungen pro Sekunde. Es ist leicht zu berechnen, dass durchschnittlich 20 Fehler pro Sekunde aufgetreten sind.
Sättigung
Um die Sättigung zu überwachen, müssen Sie Servicelimits definieren. Für unsere API haben wir zunächst die Ressourcen sowohl des Prozessors als auch des Speichers gemessen, da wir nicht wussten, welche Auswirkungen mehr haben. Kubernetes und Kube-State-Metriken stellen diese Metriken für Container bereit.
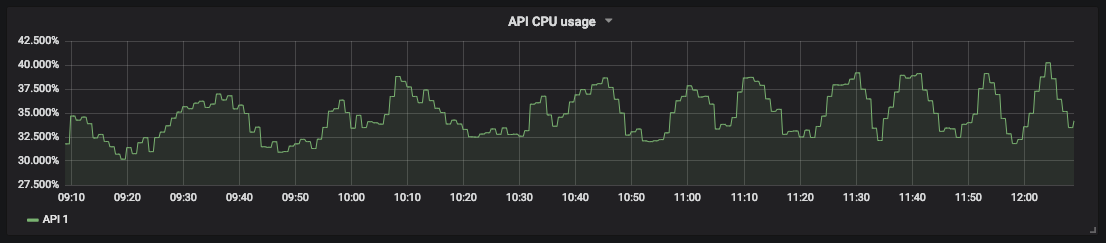
Ein Diagramm der CPU-Auslastung für unsere API-
Sättigungsmessung ermöglicht es Ihnen, Ausfallzeiten vorherzusagen und Ressourcen zu planen. Beispielsweise können Sie für die Datenbankspeicherung den freien Speicherplatz messen und messen, wie schnell er gefüllt wird, um zu verstehen, wann Maßnahmen ergriffen werden müssen.
Detaillierte Dashboards zur Überwachung verteilter Dienste
Werfen wir einen Blick auf einen anderen Dienst. Zum Beispiel eine verteilte API, die als Proxy für andere Dienste fungiert. Diese API verfügt über mehrere Instanzen in verschiedenen Regionen und mehrere Endpunkte. Jeder von ihnen hängt von seinen eigenen Diensten ab. Es wird bald ziemlich schwierig, Diagramme mit Dutzenden von Zeilen zu lesen. Wir müssen in der Lage sein, das gesamte System zu überwachen und bei Bedarf einzelne Fehler zu erkennen.
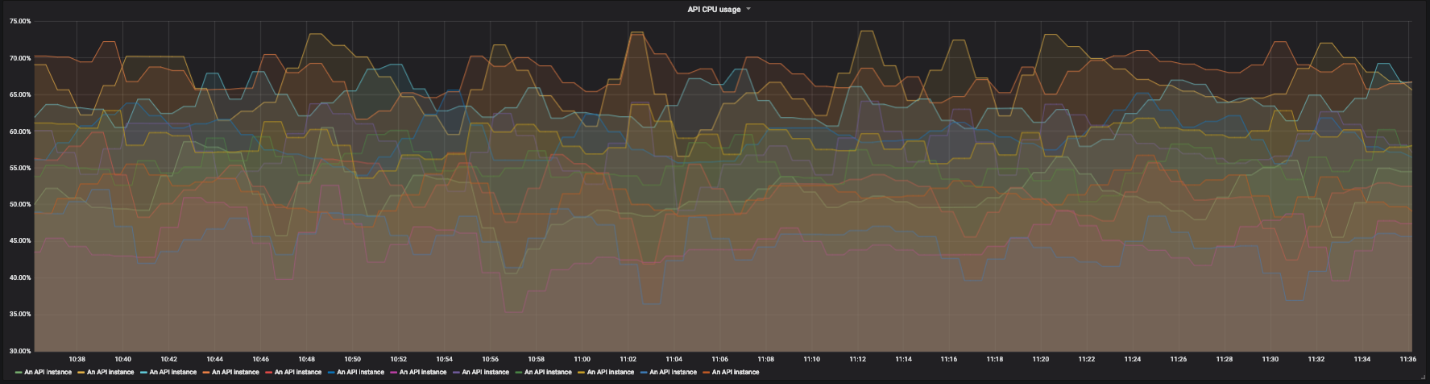
CPU-Auslastungsdiagramm für 12 Instanzen unserer API
Hierfür verwenden wir Drilldown-Dashboards. Auf jedem Bildschirm eines Panels sehen wir eine globale Ansicht des Systems und können auf einzelne Elemente klicken, um die Details zu untersuchen. Für die Sättigung verwenden wir keine Grafiken, sondern nur farbige Rechtecke, die die Verwendung von Prozessor- und Speicherressourcen anzeigen. Wenn die Ressourcennutzung den angegebenen Schwellenwert überschreitet, wird das Rechteck orange.

CPU- und Speicherauslastungsindikatoren für API-
Instanzen Klicken Sie auf das Rechteck, gehen Sie zu Details und sehen Sie mehrere farbige Rechtecke, die verschiedene API-Instanzen darstellen.

CPU-Auslastungsindikatoren für API-Instanzen
Wenn nur eine Instanz ein Problem hat, können wir auf das Rechteck klicken und weitere Details erfahren. Hier sehen wir die Region der Instanz, empfangene Anfragen und so weiter.

Eine detaillierte Ansicht des Status einer API-Instanz. Von links nach rechts, von oben nach unten: Anbieterregion, Hostname der Instanz, Datum des letzten Neustarts, Anforderungen pro Sekunde, CPU-Auslastung, Speicherauslastung, Gesamtanforderungen pro Pfad und Gesamtfehlerprozentsatz pro Pfad.
Wir machen dasselbe mit dem Prozentsatz der Fehler - wir klicken und betrachten den Prozentsatz der Fehler für jeden Endpunkt der API, um zu verstehen, wo das Problem liegt - in der API selbst oder in den Diensten, mit denen es verbunden ist.
Wir haben dasselbe für erfolgreiche Verzögerungen und Fehler bei Anfragen getan, obwohl es hier Nuancen gibt. Das Hauptziel ist es, sicherzustellen, dass der Service weltweit in Ordnung ist. Das Problem ist, dass die API viele verschiedene Endpunkte hat, von denen jeder von mehreren Diensten abhängt. Jeder Endpunkt hat seine eigenen Verzögerungen und Verkehr.
Das Einrichten separater SLOs (und SLAs) für jeden Service-Endpunkt ist mühsam. Einige Endpunkte haben eine höhere nominelle Latenz als andere. In diesem Fall kann ein Refactoring erforderlich sein. Wenn separate SLOs erforderlich sind, müssen Sie den gesamten Dienst in kleinere Dienste aufteilen. Vielleicht werden wir sehen, dass die Abdeckung unseres Dienstes zu groß war.
Wir haben beschlossen, die Gesamtlatenz am besten zu überwachen. Die Granularität ermöglicht es einfach, das Problem zu untersuchen, wenn die Latenzabweichungen so groß sind, dass sie Aufmerksamkeit erregen.
Fazit
Wir verwenden diese Methoden bereits seit einiger Zeit zur Überwachung von Systemen und haben festgestellt, dass sich die Zeit, die zum Auffinden von Problemen benötigt wird, und die mittlere Zeit bis zur Wiederherstellung (MTTR) verringert haben. Durch die Detaillierung können wir die tatsächliche Ursache eines globalen Problems finden, und für uns hat sich diese Fähigkeit stark verändert.
Andere Entwicklungsteams haben ebenfalls begonnen, diese Methoden zu verwenden und sehen nur Vorteile darin. Jetzt sind sie nicht nur für den Betrieb ihrer Dienste verantwortlich. Sie gehen noch weiter und können bestimmen, wie sich Änderungen am Code auf das Verhalten von Diensten auswirken.
Die vier goldenen Signale lösen nicht alle Probleme, sind aber bei den häufigsten sehr hilfreich. Mit fast keinem Aufwand konnten wir die Überwachung erheblich verbessern und die MTTR reduzieren. Fügen Sie so viele Metriken wie nötig hinzu, solange sich vier goldene Signale darunter befinden.