Die technologische Infrastruktur der M.Video-Eldorado Group ist heute weit mehr als eine gigantische Registrierkettenkette in mehr als 1000 Filialen im ganzen Land. Unter der Haube haben wir eine Online-Plattform, die Kundeninteraktion, maschinelles Lernen, intelligente Suchalgorithmen, Chat-Bots, ein Empfehlungssystem, die Automatisierung wichtiger Geschäftsprozesse und den elektronischen Dokumentenfluss bietet. Unter dem Schnitt gibt es eine detaillierte Geschichte darüber, was uns dazu gebracht hat, den Monolithen in Mikrodienste zu zerlegen.
Legenden der tiefen Antike
Damit dies alles wie am Schnürchen funktioniert, müssen wir die Entwicklung der Technologien verfolgen und umgehend auf Geschäftsanforderungen reagieren. Leider ist die Grundfunktionalität globaler ERP-Systeme bei weitem nicht immer in der Lage, schnell auf die aufkommenden Bedürfnisse interner Kunden zu reagieren. Dies wurde 2016 zu einem der Argumente für den Übergang zu einer Microservice-Architektur.
Das Unternehmen stand vor einer ziemlich schwierigen Aufgabe, eine einheitliche Geschäftslogik der Zusammenarbeit mit verschiedenen Werbemechanikern bei der Auftragserteilung von Kunden in allen Vertriebskanälen und Kontaktstellen (zu dieser Zeit: Website, mobile Anwendung, Kassen) umzusetzen und Terminals in Geschäften und Betreibern im Call Center).
Gleichzeitig verfügten wir innerhalb der IT-Landschaft über große monolithische Systeme wie die Oracle ATG E-Commerce-Plattform, SAP CRM und andere. Die Wiederholung der Logik in jedem von ihnen oder die Implementierung in einem und die Wiederverwendung der erforderlichen Funktionalität in einem anderen führte nach unseren Berechnungen zu jahrelanger Zeit und zig Millionen von Investitionen.
Aus diesem Grund haben wir ein kleines Team von Entwicklern und technisch kompetenten Mitarbeitern zusammengestellt, die uns zu diesem Zeitpunkt zur Verfügung standen, und darüber nachgedacht, wie wir einen separaten Service für unsere Anforderungen erstellen können. Bei der Ausarbeitung haben wir festgestellt, dass wir tatsächlich nicht ein, sondern drei oder vier Arbeitswerkzeuge benötigen. So kommen wir zum ersten Mal zum Konzept der Microservice-Architektur.
Wir haben uns für Java entschieden, da wir die nötige Erfahrung damit hatten. Wir haben Spring Version 3.2 gewählt. Als Ergebnis haben wir eine Art verteilten Mikromonolithen in drei oder vier Diensten erhalten, die eng miteinander verbunden sind. Trotz der Tatsache, dass sie unabhängig voneinander entwickelt wurden, konnte nur jeder zusammenarbeiten.
Es war jedoch ein großer Fortschritt bei der Entwicklung der eigenen Technologie. Wir wechselten von Java 6 zu Java 8, begannen Spring 3 zu beherrschen und wechselten reibungslos zu Spring 4. Natürlich war es ein gewisser Versuch.
Wir haben den Zeitrahmen für die Projektimplementierung erfolgreich von unklaren "Monaten für die Entwicklung" verkürzt und die erforderliche kanalübergreifende Geschäftslogik in fast zwei Monaten implementiert.
Technologische Entwicklung
In den Jahren 2017-18 haben wir mit einem globalen Refactoring des Mikromonolithen begonnen. Das Konzept der Entwicklung von Microservices wurde sowohl von IT-Spezialisten als auch von Unternehmen geschätzt. Der Fluss der Arbeitsaufgaben begann zu wachsen. Darüber hinaus haben wir weiterhin Funktionsblöcke, die von verschiedenen Verbrauchern benötigt werden, von der Unternehmens-IT-Landschaft isoliert und auf die Schienen von Microservices übertragen.
Wir haben versucht, mit der Zeit zu gehen und auf Java 9 umzusteigen, aber es war nicht von Erfolg gekrönt. Leider haben wir von dieser Übung keinen konkreten Nutzen gezogen, so dass wir auf Java 8 geblieben sind. Es
gab immer mehr Dienste, die zentral verwaltet und standardisiert mit ihnen arbeiten mussten. Hier haben wir zum ersten Mal die Containerisierung versucht. Docker-Container waren damals groß und schwer, jeweils mehrere hundert Megabyte.
Später mussten wir Probleme mit dem Ausgleich von Verkehr und Auslastung der Dienste lösen. Wir haben Consul für externe Kunden und Eureka für interne Kunden als Lösungen ausgewählt. Wir haben verschiedene Tools der dienstübergreifenden Kommunikation gRPC, RMI ausprobiert. Wir haben fast ein Jahr so gelebt, und es schien uns, als hätten wir gelernt, wie man erfolgreich Microservices erstellt und eine Microservice-Architektur aufbaut.
Schnall dich an, wir ertrinken!
Im Jahr 2019 hat die Anzahl unserer Microservices deutlich zugenommen und die Marke von 100+ überschritten. Wir haben nach Möglichkeit neue Lösungen für die dienststellenübergreifende Kommunikation angewendet und versucht, ereignisbasierte Ansätze zu implementieren.
In der Zwischenzeit wurden die Probleme der Orchestrierung und des Abhängigkeitsmanagements immer akuter. Die größte Änderung, die uns bereits Anfang 2019 berührt hat, betraf jedoch die Änderung der Unternehmensrichtlinien in Bezug auf die Verwendung von Java.
Wir hatten die Wahl, was wir als nächstes tun sollten: Bleiben Sie bei Oracle und zahlen Sie ihnen viel Geld, investieren Sie in unseren eigenen Build von Open JDK oder versuchen Sie, echte Alternativen zu finden.
Wir haben uns für die dritte Option entschieden und zusammen mit BellSoft, einem der fünf weltweit führenden Unternehmen, das an der Entwicklung des OpenJDK-Projekts beteiligt ist, nach einer Reihe von Besprechungen und Diskussionen einen Plan für den Übergang und die Pilotierung der neuen Java-Version erstellt Der Prozess war schwierig, aber bei allen Tests hatten wir keine ernsthaften und unlösbaren Probleme.
Der nächste Schritt für uns war die Implementierung des Container-Managements für Kubernetes. Dank dessen schien es uns seit einiger Zeit, dass alles in Ordnung ist und wir ernsthafte Erfolge erzielt haben. Aber dann tauchten die nächsten Probleme mit der Infrastruktur auf. Sie konnte den ständigen Lastanstieg einfach nicht bewältigen.
Wir hatten einfach keine Zeit zum Skalieren. Die Notwendigkeit der nächsten grundlegenden technischen Transformationen wurde offensichtlich. Also haben wir uns mit Cloud-Technologien befasst und uns bemüht, sie selbst auszuprobieren.
Erhebe dich über die Wolken
Der Beginn des Jahres 2020 versprach uns einen großen Schritt in der Entwicklung unserer internen Technologien, dem Verständnis und der Verbesserung unserer Microservice-Architektur. Vor uns war ein großer Schritt in die Wolken. Leider mussten die Pläne, wie sie sagen, genau im Laufe des Stücks korrigiert werden.
Aufgrund der COVID-19-Pandemie mussten wir im gesamten Unternehmen nach neuen Tools suchen, um den sich aufgrund der Pandemie ändernden Anforderungen unserer Kunden gerecht zu werden, anstatt die Möglichkeiten von Cloud-Diensten schrittweise zu migrieren und zu erkunden. Wir haben tatsächlich die nächsten Microservices geschrieben, gleichzeitig neue Technologien eingeführt und sind immer noch auf die Cloud-Infrastruktur umgestiegen.
Für uns ist die Größe von Containern aus zwei einfachen Gründen kritisch geworden: Es ist Geld für die verbrauchte Cloud-Computing-Leistung und die Zeit, die der Entwickler und damit das gesamte Unternehmen damit verbringt, Container anzuheben, zu synchronisieren und zu konfigurieren, Autotests durchzuführen, und so weiter. Und hier haben wir den Vorteil und die Nützlichkeit unserer kompakten Container mit der Liberica JDK-Laufzeit voll gespürt.
Trotz des Höhepunkts der Pandemie haben wir in wenigen Monaten zwei Dutzend Microservices implementiert und erfolgreich in Betrieb genommen, die vollständig auf der Cloud-Infrastruktur basieren.
Ende 2020 haben wir uns auf Prozesssachen konzentriert: Wir haben viel Zeit und Mühe investiert, um einen Produktansatz zu entwickeln, Microservices zu entwickeln, separate Teams mit eigenen Metriken und KPIs für verschiedene Bereiche von Geschäftsbereichen auszuwählen und zu bilden .
Sägen des Monolithen in Microservices am Beispiel des Auftragsberechnungsdienstes
Um Ihre Geduld nicht zu testen, möchte ich konkrete Beispiele und Logik für die Arbeit mit einer Microservice-Infrastruktur demonstrieren. Nehmen wir eine typische Auftragsberechnung in einer Standard-IT-Umgebung.
Wir standen vor einer ganzen Reihe von Herausforderungen. Unsere Stammdaten befanden sich tief in den Systemen im Backoffice. Jedes IT-System ist ein klassischer Monolith: Datenbank, Anwendungsserver. Die Integration von Mastersystemen mit anderen Teilnehmern der IT-Landschaft erfolgte als "Punkt-zu-Punkt", dh jedes IT-System integrierte sich auf seine Weise und jedes Mal neu.
Es gab hauptsächlich zwei Arten von Integrationen: Replikation auf Datenbankebene, Dateiübertragung. Die Berechnungslogik wurde in jedem IT-System separat wiederholt, und zwar in verschiedenen Entwicklungssprachen. Es gibt keine Möglichkeit, auch nur den Code eines benachbarten Teams wiederzuverwenden.
Aufgrund unterschiedlicher Roadmaps und Ressourcenkosten verschiedener IT-Systeme war es äußerst kostspielig und nahezu unmöglich, die Berechnungslogik in allen Systemen gleichzeitig zu synchronisieren.
Darüber hinaus war es für uns bei der Bearbeitung von Kundenbeschwerden äußerst schwierig festzustellen, warum der richtige Preis oder der eine oder andere Rabatt nicht gewährt wurde.
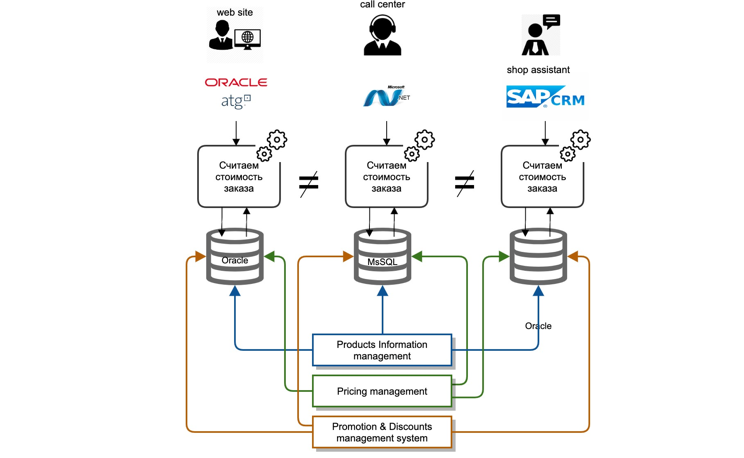
Was haben wir getan? Wir haben den Kontext analysiert und ermittelt, der für die korrekte Berechnung des Bestellwerts erforderlich ist. Als Nächstes haben wir Geschäftsbereiche ausgewählt und diese intern in separate Microservices unterteilt. So haben wir beispielsweise Daten zu Waren hervorgehoben, die bei der Berechnung der Kosten einer Bestellung berücksichtigt werden mussten.
Wir haben einen Service zum Online-Importieren von Daten aus Mastersystemen mithilfe von Warteschlangen (Kafka) implementiert. Zusätzlich zu den Daten haben wir atomare Mikrodienste implementiert, die mit Produktkategorien und deren Attributen (Produkte-Attribut-Service, Produkt-Kategorien-Service) arbeiten. Dasselbe haben wir mit Domains im Zusammenhang mit Preis und Werbung gemacht.
Separat haben wir die Logik und das Verfahren zur Berechnung der Auftragspreise in eine separate Bestellberechnungsmaschine verschoben und eine einzige einheitliche Logik zur Berechnung von Preisen und Kosten unter Verwendung von Rabattgeldern und Werbekarten implementiert.
Wir haben außerdem eine standardisierte REST-API für alle Kunden implementiert, die die Logik der Auftragsabwicklung implementieren. Für die dienstübergreifende Kommunikation haben wir das gRPC-Protokoll mit einer Beschreibung auf protobuf3 ausgewählt.
Daher sieht ein Standard-Microservice heute ungefähr so aus: Es handelt sich um eine Spring-Boot-Anwendung, die mit GitLab CI in einem Docker-Container gesammelt und im Kubernetes-Cluster bereitgestellt wird.
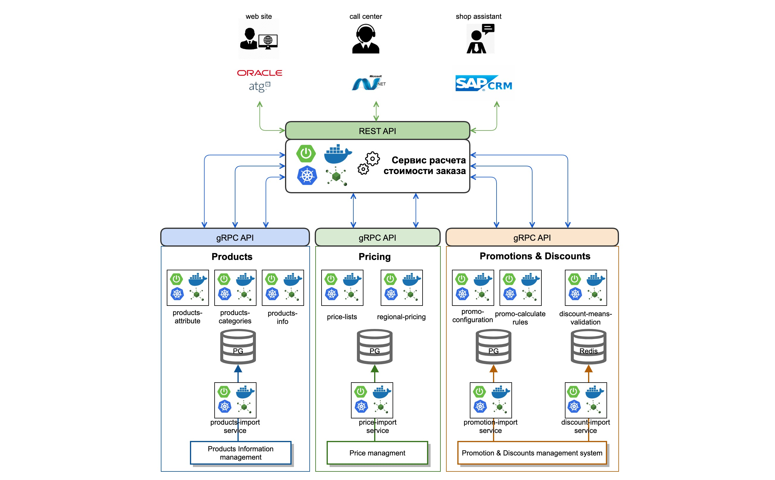
Was ist das Endergebnis?
Auf dem Weg unserer technischen Entwicklung haben wir zunächst den Ansatz für die Entwicklung der Services selbst und die Bildung von Teams überarbeitet. Wir haben uns auf einen Produktansatz konzentriert und Teams rekrutiert, die auf den maximalen Prinzipien der Autonomie basieren.
Gleichzeitig, damit die Teams bestimmten Geschäftsbereichen und -bereichen entsprechen und dementsprechend zusammen mit den Leitern der Geschäftsfunktionen an der Entwicklung eines bestimmten Geschäftsbereichs teilnehmen können.
In Bezug auf die technische Entwicklung haben wir die asynchrone Konnektivität mit Kafka, einschließlich Kafka-Streams, als eines der dienststellenübergreifenden Kommunikationstools ausgewählt. Dadurch konnten die Teams praktisch unabhängig von anderen werden. Wir nutzen und praktizieren auch aktiv reaktive Entwicklungspraktiken, zum Beispiel das Reaktorprojekt. Wir wollen immer noch das Projekt Loom ausprobieren.
Um die Entwicklung zu beschleunigen, konzentrierten wir uns auf die Entwicklung mehrerer technischer und organisatorischer Faktoren, die es uns ermöglichten, das Timing maßgeblich zu beeinflussen.
Der technologische Aspekt ist der Übergang zu Cloud-Technologien, der die optimale Automatisierungsgeschwindigkeit der CI \ CD-Prozesse sicherstellte. Die Geschwindigkeit und Dauer der vollständigen Regression und Bereitstellung eines bestimmten Mikrodienstes ist hier entscheidend.
Beispielsweise dauert eine CI \ CD-Pipeline (für alle Arten von Unit-Tests, Verträgen und Integrationen) für eine funktionierende produktive Geschäftsanwendung (und dies sind ungefähr 12-15 miteinander verbundene Mikrodienste) ungefähr 31 Minuten, was 7-8 entspricht Minuten weniger als Indikatoren Anfang 2020.
So verbringen wir etwa 17-18% weniger Zeit damit, auf das Ergebnis zu warten. Diese Einsparungen ermöglichen es uns, andere Lebensmittelaufgaben zu erledigen. Dies liegt hauptsächlich daran, dass wir kompakte Container auf Basis von Alpine Linux verwenden, die von Stunde zu Stunde schneller und leichter werden.
Wir sind in Bezug auf die Entwicklung von Mikroservices im Allgemeinen effizienter geworden. Dies wirkt sich positiv auf das Benutzererlebnis unserer Kunden aus. Geschwindigkeit ist jetzt eine der Schlüsselkennzahlen unserer Online-Produkte (Website und mobile Apps), und Liberica JDK ermöglicht es uns auch, diesen Gewinn zu erzielen, den wir in Bezug auf die Leistung in eine positive Erfahrung für unsere Kunden umwandeln.
Darüber hinaus konnten wir durch den richtigen Ansatz für die Entwicklung von Microservices die Zeit für die Markteinführung unseres Produkts erheblich verkürzen. Wir haben gelernt, wie einzelne Services mit verschiedenen Strategien für den Einsatz von A \ B, Konservenfabrik und anderen nach Bedarf in die Produktion gebracht werden können. Dies ermöglicht es, schnell Feedback zur Arbeit von Microservices zu erhalten.
In zwei Monaten haben wir einige neue Services für das Einkaufserlebnis entwickelt und implementiert. Wir sprechen über die sogenannte schnelle Lieferung von Waren innerhalb von 2 Stunden (wir verwenden verschiedene Taxi- und Lieferaggregatoren) und die Erteilung unserer Bestellungen an den unerwartetsten Orten (in Pyaterochka-Geschäften oder russischen Postämtern, selbst auf großen Parkplätzen) Geschäftszentren).
Dank unserer Microservices haben einige Kunden der M.Video-Eldorado-Gruppe die Möglichkeit, ein Taxi mit ihren Waren direkt vom Geschäft nach Hause zu nehmen.
Kreative Pläne
Unsere Pläne für 2021 beinhalten die aktive Entwicklung der Cloud-Infrastruktur und den vollständigen Übergang zum Konzept der Infrastruktur als Code ("Infrastruktur als Code").
Wir planen, der Entwicklung transparenter Lösungen für die Steuerung und Interaktion von Mikrodiensten in Form einer Service Mesh-Lösung auf der Basis von Istio und Admiral große Aufmerksamkeit zu widmen. Wir haben noch viel Arbeit vor uns, um den gesamten Observability-Stack zu optimieren und zu verbessern, die Anforderungsverfolgung und die Nachrichtenprotokollierung zu überwachen.
Wir planen auch, serverlose Technologien zu verwenden, einschließlich des Wunsches, es in Java zu versuchen. Darüber hinaus gibt es eine weit entfernte, aber nicht unrealistische Idee, eine Multi-Cloud-Infrastruktur und ein Ökosystem aufzubauen.
Wenn Sie daran interessiert sind, unseren Technologie-Stack mit Ihren Händen zu berühren, zögern Sie nicht, es gibt genug Arbeit für alle. Die Registrierung der Freiwilligen erfolgt rund um die Uhr: hier . Gern geschehen .
Vorteile, Life Hacks, persönliche Erfahrung

Dmitry Chuiko, Senior Performance Architect bei BellSoft, über die Geheimnisse winziger Docker-Container für Java-Microservices:
─ . , . Docker-. , : , .
Linux , . JDK. , , .
1.
CentOS CentOS slim. ? Debian. Alpine musl. BellSoft Alpine Linux, — Linux. Liberica JDK 11.0.10 + 11.0.10 Linux.
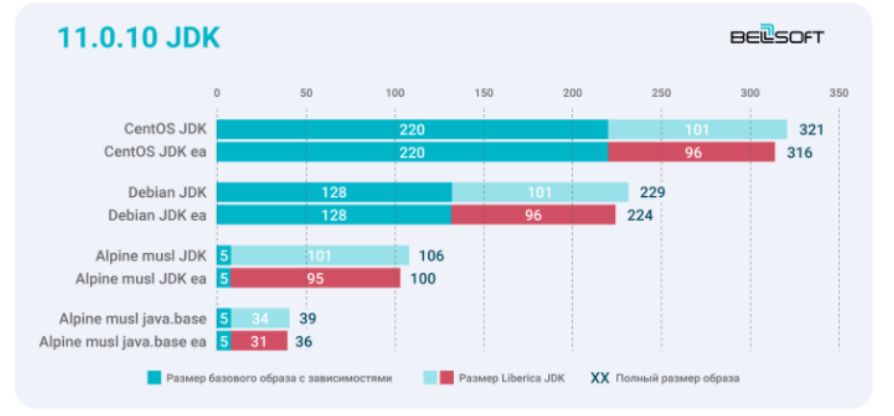
Liberica EA 3–6 14,7 % Alpine musl java.base. 7,6 %. Docker-, JRE java.base. Liberica JRE EA — 16 %.
Liberica Lite . , , — . - Java SE JVM, Standart, JIT- (C1, C2, Graal JIT Compiler), (Serial, Parallel, CMS, G1, Shenandoah, ZGC) serviceability, .
2. JDK
— jdeps JLINK. . Java (JDeps). - Java, . . JAR, , . JDeps JDK, Java-. , , .

jdeps , java.base. jlink. , BellSoft Docker- java.base. DockerHub, .
docker run –rm bellsoft/liberica – openjdk -demos- asciiduke.
CLI-like java.base. Liberica JDK Lite Alpine Linux musl 40,4 .
.
Enjoy!