Hallo, alle miteinander. Wir betreten die Zielgerade: Heute ist der letzte Artikel darüber, was Data Science für die Vorhersage von COVID-19 bieten kann.
Der erste Artikel ist hier . Der zweite ist hier .
Heute sprechen wir mit Alexander Zhelubenkov über seine Entscheidungen, die Ausbreitung von COVID-19 vorherzusagen.
Unsere Bedingungen sind wie folgt:
Gegeben : Kolossale datenwissenschaftliche Fähigkeiten, drei talentierte Spezialisten.
Finden : Möglichkeiten, die Ausbreitung von COVID-19 in einer Woche vorherzusagen.
Und hier ist die Entscheidung von Alexander Zhelubenkov
- Alexander, hallo. Erzählen Sie uns zunächst ein wenig über sich und Ihren Job.
- Ich arbeite bei Lamoda als Leiter der Gruppe Datenanalyse und maschinelles Lernen. Wir beschäftigen uns mit einer Suchmaschine und Algorithmen zur Einstufung von Produkten im Katalog. Data Science interessierte mich, als ich an der Moskauer Staatlichen Universität an der Fakultät für Computermathematik und Kybernetik studierte.
- Kenntnisse und Fähigkeiten haben sich als nützlich erwiesen. Sie haben ein Qualitätsmodell erstellt: Einfach genug, um nicht überpasst zu werden. Wie haben Sie das geschafft?
- Das Problem der Vorhersage von Zeitreihen ist gut untersucht, und es ist verständlich, welche Ansätze darauf angewendet werden können. In unserer Aufgabe sind die Stichproben im Vergleich zum maschinellen Lernen recht klein - mehrere tausend Beobachtungen in den Trainingsdaten und nur 560 Vorhersagen müssen für jede Woche gemacht werden (Prognose für 80 Regionen für jeden Tag der nächsten Woche). In solchen Fällen werden gröbere Modelle verwendet, die in der Praxis gut funktionieren. Tatsächlich endete ich mit einer ordentlichen Grundlinie.
Als Modell habe ich die Gradientenverstärkung bei Bäumen verwendet. Möglicherweise stellen Sie fest, dass die Standardmodelle aus Holz nicht wissen, wie Trends vorhergesagt werden können. Wenn wir jedoch zu inkrementellen Zielen wechseln, können Sie den Trend vorhersagen. Es stellt sich heraus, dass Sie dem Modell beibringen müssen, um vorherzusagen, um wie viel sich die Anzahl der Fälle im Vergleich zum aktuellen Tag in den nächsten X Tagen erhöhen wird, wobei X von 1 auf 7 der Prognosehorizont ist.
Ein weiteres Merkmal war, dass die Qualität der Vorhersagen des Modells auf einer logarithmischen Skala bewertet wurde, dh die Strafe bestand nicht darin, wie sehr Sie sich geirrt hatten, sondern darin, wie oft sich die Vorhersagen des Modells als ungenau herausstellten. Dies hatte folgenden Effekt: Die endgültige Qualität der Prognosen für alle Regionen wurde stark von der Genauigkeit der Prognosen in kleinen Regionen beeinflusst.
Zeitpläne für jede Region waren bekannt: die Anzahl der Fälle an jedem der Tage in der Vergangenheit und buchstäblich einige qualitative Merkmale wie die Bevölkerung und der Anteil der Stadtbewohner. Im Grunde ist das alles. Es ist schwierig, solche Daten neu zu trainieren, wenn es normal ist, die Validierung durchzuführen und festzustellen, wo es sich lohnt, im Boosting-Training anzuhalten.
- Welche Gradientenverstärkungsbibliothek haben Sie verwendet?
- Ich bin auf die altmodische Weise - XGBoost. Ich kenne LightGBM und CatBoost, aber für eine solche Aufgabe scheint mir die Wahl nicht so wichtig zu sein.
- Okay. Aber immer noch das Ziel. Was hast du für das Ziel genommen? Ist dies der Logarithmus der Beziehung von zwei Tagen oder der Logarithmus des Absolutwerts?
- Als Ziel habe ich den Unterschied in den Logarithmen der Anzahl der Fälle genommen. Wenn es heute beispielsweise 100 Fälle gab und morgen 200, dann müssen Sie bei der Vorhersage eines Tages im Voraus lernen, den Logarithmus des zweifachen Wachstums vorherzusagen.
Im Allgemeinen ist bekannt, dass die Ausbreitung des Virus in den ersten Wochen exponentiell zunimmt. Das heißt, wenn wir Inkremente auf einer logarithmischen Skala als Ziele verwenden, ist es tatsächlich möglich, jeden Tag eine Konstante multipliziert mit dem Prognosehorizont vorherzusagen. Gradient Boosting ist ein vielseitiges Modell und kommt mit solchen Aufgaben gut zurecht.
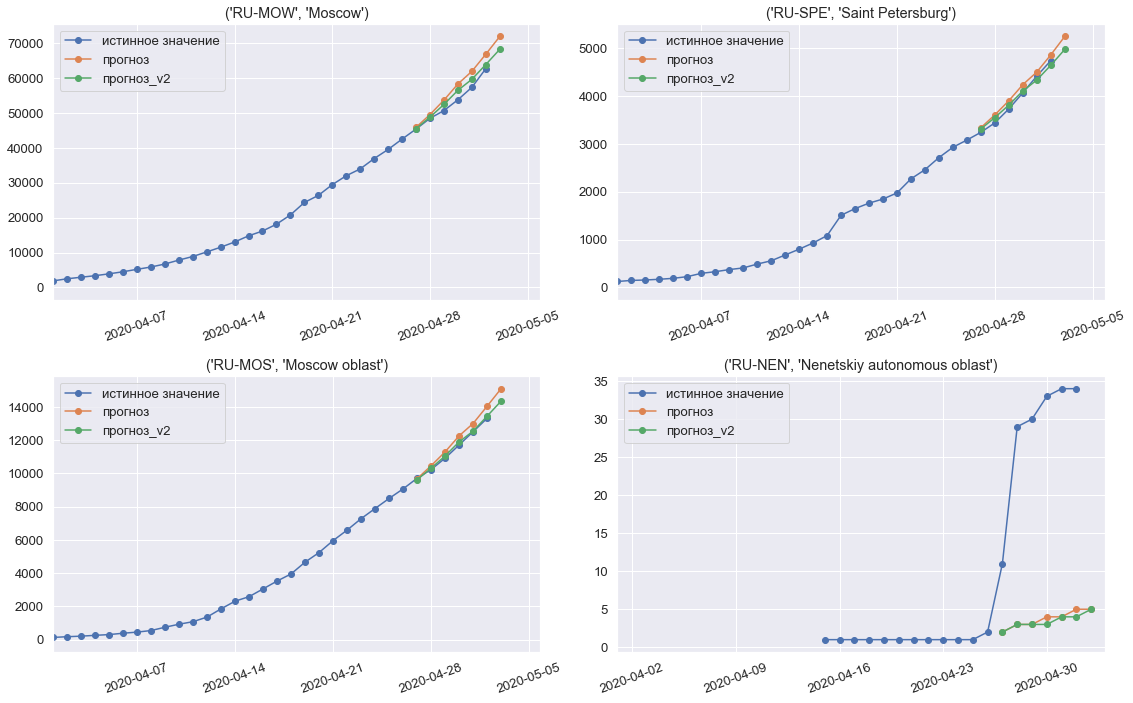
Modellvorhersagen für die dritte, letzte Woche des Wettbewerbs
- Welche Trainingsstichprobe haben Sie genommen?
- Um Regionen vorherzusagen, habe ich Informationen zur Verteilung nach Ländern genommen. Es scheint, dass dies geholfen hat, da sich irgendwo bereits das starke Wachstum verlangsamte und die Länder begannen, das Plateau zu betreten. In den Regionen Russlands habe ich die Anfangszeit unterbrochen, als es einige Einzelfälle gab. Für das Training habe ich Daten vom Februar verwendet.
- Wie werden Sie validiert?
- Wie bei Zeitreihen zeitlich validiert und üblich. Ich habe die letzten zwei Wochen für den Test verwendet. Wenn wir die letzte Woche vorhersagen, verwenden wir für das Training alle Daten davor. Wenn wir das vorletzte vorhersagen, verwenden wir alle Daten ohne die letzten zwei Wochen.
- Hast du etwas anderes benutzt? Einige Tage, 10. oder 20. Tag, also von dort?
- Die wichtigsten Faktoren, die wichtig waren, waren unterschiedliche Statistiken: Durchschnittswerte, Median, Anstieg in den letzten N Tagen. Für jede Region kann sie separat berechnet werden. Sie können dieselben Faktoren auch separat addieren und nur für alle Regionen gleichzeitig berechnen.
- Frage zur Validierung. Suchen Sie mehr nach Stabilität oder Genauigkeit? Was war das Kriterium?
- Ich habe mir die durchschnittliche Qualität des Modells angesehen, die in den letzten zwei Wochen zur Validierung ausgewählt wurde. Beim Hinzufügen einiger Faktoren haben wir ein derartiges Bild erhalten, dass bei einer festen Boosting-Konfiguration und nur beim Variieren des Random-Seed-Parameters die Qualität der Vorhersagen stark springen kann - das heißt, es wurde eine große Varianz erhalten. Um nicht umzuschulen und ein stabileres Modell zu erhalten, habe ich im endgültigen Modell letztendlich keine derart zweifelhaften Faktoren verwendet.
- Woran erinnerst du dich? Überrascht? Eine Funktion, die funktioniert hat, oder eine Art Boosting-Trick?
- Ich habe zwei Lektionen gelernt. Als ich mich entschied, zwei Modelle zu mischen: linear und verstärkend, und gleichzeitig für jede Region, wurden die Koeffizienten, mit denen diese beiden Modelle aufgenommen wurden (sie erwiesen sich als unterschiedlich), einfach in der letzten Woche festgelegt - das heißt für sieben Tage. Tatsächlich habe ich 7 Tage lang 1-2 Koeffizienten für jede Region festgelegt. Aber die Entdeckung war folgende: Die Prognose erwies sich als viel schlechter als wenn ich diese Einstellungen nicht vorgenommen hätte. In einigen Regionen wurde das Modell stark umgeschult, und infolgedessen erwiesen sich die darin enthaltenen Prognosen als schlecht. In der dritten Phase des Wettbewerbs habe ich beschlossen, dies nicht zu tun.
Und der zweite Punkt: Es scheint, dass die Anzahl der Tage von Anfang an als Merkmal nützlich sein sollte: von der ersten kranken Person, von der zehnten kranken Person. Ich habe versucht, sie hinzuzufügen, aber bei der Validierung hat sich die Situation verschlechtert. Ich habe es so erklärt: Die Verteilung der Werte in Stichproben verschiebt sich mit der Zeit. Wenn Sie am 20. Tag nach Beginn der Ausbreitung des Virus studieren, wird die Vorhersage der Verteilung der Werte dieser Funktion sieben Tage dauern, und möglicherweise können solche Faktoren nicht verwendet werden Vorteil.
- Sie sagten, dass der Anteil der Stadtbevölkerung eine Rolle spielt. Und was noch?
- Ja, der Anteil der städtischen Bevölkerung sowohl für Länder als auch für Regionen Russlands wurde immer verwendet. Dieser Faktor hat die Qualität der Prognosen durchweg geringfügig verbessert. Daher habe ich außer der Zeitreihe selbst nichts anderes in das endgültige Modell aufgenommen. Versucht, Sonstiges hinzuzufügen, hat aber nicht funktioniert.
- Was ist Ihre Meinung: SARIMA ist das letzte Jahrhundert?
- Modelle des autoregressiven - gleitenden Durchschnitts - sind schwieriger einzurichten, und es ist teurer, zusätzliche Faktoren hinzuzufügen, obwohl ich sicher bin, dass mit (S) ARIMA (X) -Modellen gute Vorhersagen getroffen werden können. aber nicht so gut wie beim Boosten.
- Und für einen längeren Zeitraum als eine Woche können Sie Vorhersagen treffen. Was denken Sie?
- Es wäre interessant. Die Organisatoren hatten zunächst die Idee, langfristige Prognosen zu sammeln. Der Monat scheint ein Wendepunkt zu sein, an dem Sie immer noch die Ansätze ausprobieren können, die ich gemacht habe.
- Was glaubst du wird als nächstes passieren?
- Wir müssen das Modell neu bauen, schauen Sie. Meine Lösung finden Sie übrigens hier:
github.com/Topspin26/sberbank-covid19-challenge Die
neuesten Nachrichten zu COVID Data Science aus der internationalen Gemeinschaft finden Sie unter https://www.kaggle.com/tags/covid19 . Und natürlich laden wir Sie zum # coronavirus-Kanal unter opendatascience.slack.com ein (eingeladen von ods.ai ).