Was ist los mit dem TargetEncoder aus der Bibliothek category_encoders?
Dieser Artikel ist eine Fortsetzung des vorherigen Artikels , in dem erläutert wurde, wie die objektive probabilistische Codierung tatsächlich funktioniert. In diesem Artikel werden wir sehen, in welchen Fällen die Standardlösung der Bibliothek category_encoders ein falsches Ergebnis liefert, und außerdem werden wir die Theorie und das Codebeispiel für eine korrekte objektiv-probabilistische Codierung mit mehreren Klassen untersuchen. Gehen!
1. Wann ist TargetEncoder falsch?
Schauen Sie sich diese Daten an. Farbe ist ein Merkmal, und ein Ziel ist ... ein Ziel. Unser Ziel ist es, die Farbe basierend auf dem Ziel zu codieren.

Lassen Sie uns hierfür die übliche objektiv-probabilistische Codierung durchführen.
import category_encoders as ce
ce.TargetEncoder(smoothing=0).fit_transform(df.Color,df.Target)
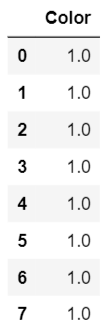
Hmm ... sieht nicht gut aus, oder? Alle Farben wurden auf 1 geändert. Warum? Dies liegt daran, dass der TargetEncoder den Durchschnitt aller Zielwerte für jede Farbe und nicht die Wahrscheinlichkeit ermittelt.
Während TargetEncoder ordnungsgemäß funktioniert, wenn Sie ein binäres Ziel mit 0 und 1 haben, schlägt dies in zwei Fällen fehl:
Wenn das Ziel binär ist, aber nicht 0/1 (zumindest zum Beispiel 1 und 2).
Wenn das Ziel eine Mehrfachklasse wie im obigen Beispiel ist.
Also, was tun?
Theorie
, n . , . n , . n-1 , , . - , , .
.
.
1: - .
enc=ce.OneHotEncoder().fit(df.Target.astype(str)) y_onehot=enc.transform(df.Target.astype(str)) y_onehot
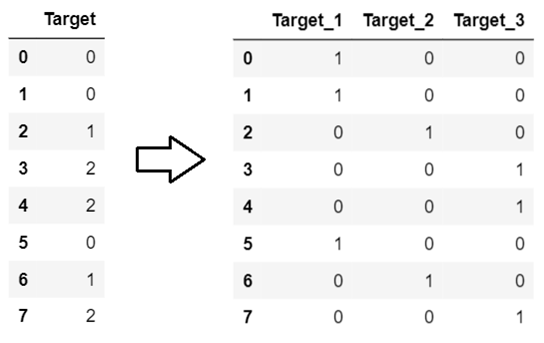
, Target_1 0 Target. 1 Target 0, 0 . Target_2 1 Target.
2: , .
class_names = y_onehot.columns
for class_ in class_names:
enc = ce.TargetEncoder(smoothing = 0)
print(enc.fit_transform(X,y_onehot[class_]))
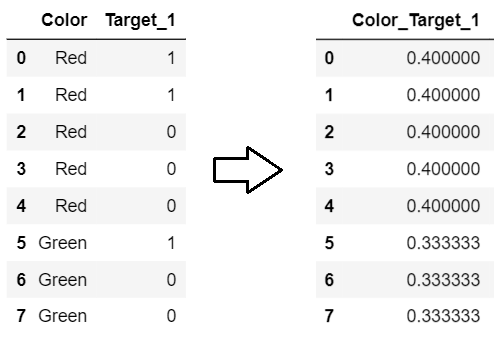
0
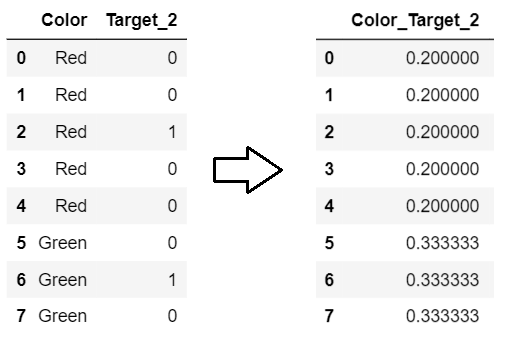
1

2
3: , , 1 2 .
!
, :

, Color_Target. , , . , , , Color_Target_3 ( - ) .
, ?!
Unten finden Sie eine Funktion, die eine Datentabelle und ein Zielbezeichnungsobjekt vom Typ Serie als Eingabe verwendet. Die df-Funktion kann sowohl numerische als auch kategoriale Variablen enthalten.
def target_encode_multiclass(X,y): #X,y are pandas df and series
y=y.astype(str) #convert to string to onehot encode
enc=ce.OneHotEncoder().fit(y)
y_onehot=enc.transform(y)
class_names=y_onehot.columns #names of onehot encoded columns
X_obj=X.select_dtypes('object') #separate categorical columns
X=X.select_dtypes(exclude='object')
for class_ in class_names:
enc=ce.TargetEncoder()
enc.fit(X_obj,y_onehot[class_]) #convert all categorical
temp=enc.transform(X_obj) #columns for class_
temp.columns=[str(x)+'_'+str(class_) for x in temp.columns]
X=pd.concat([X,temp],axis=1) #add to original dataset
return X
Zusammenfassung
In diesem Artikel habe ich in der Bibliothek category_encoder gezeigt, was mit dem TargetEncoder nicht stimmt, erklärt, was der ursprüngliche Artikel über das Targeting von Variablen mehrerer Klassen sagt, alles anhand eines Beispiels demonstriert und einen funktionierenden modularen Code bereitgestellt, den Sie in Ihren einbinden können Anwendung.