Der Artikel richtet sich an Anfänger wie mich.
Start
Schauen wir uns zunächst das Problem an. Ich habe eine wenig bekannte Nachrichtenseite über Israel besucht, da ich selbst in diesem Land lebe und Nachrichten ohne Werbung und ohne interessante Nachrichten lesen möchte. Und so gibt es eine Site, auf der Nachrichten veröffentlicht werden: Es gibt Nachrichten, die rot markiert sind, und es gibt gewöhnliche. Die gewöhnlichen sind nichts Interessantes, und die rot markierten sind genau der Saft. Betrachten Sie unsere Website.
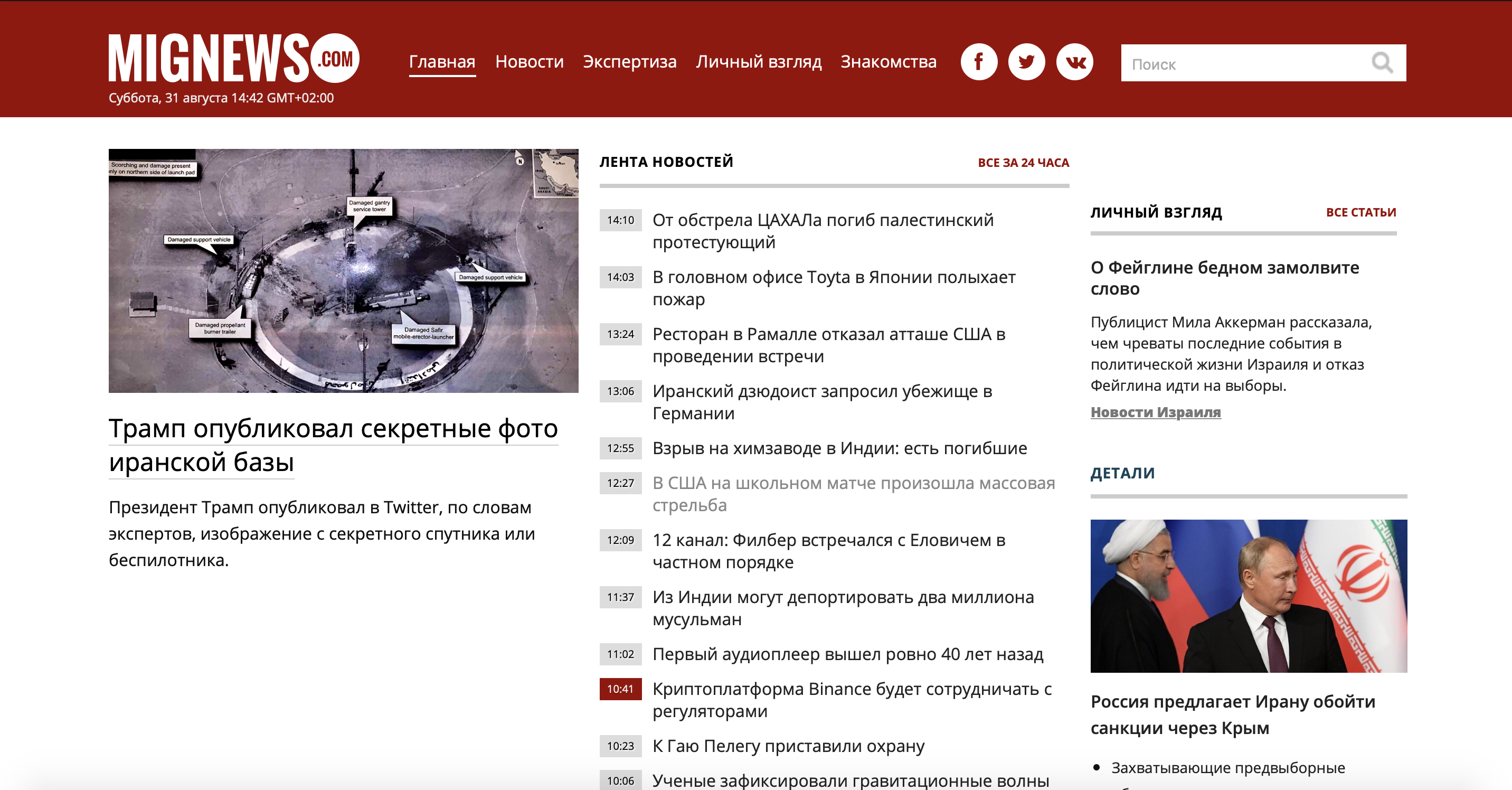
Wie Sie sehen können, ist die Website groß genug und es gibt viele unnötige Informationen, aber wir müssen nur den Nachrichtencontainer verwenden. Verwenden wir die mobile Version der Website
, um uns Zeit und Mühe zu sparen.

Wie Sie sehen können, hat uns der Server einen schönen Nachrichtencontainer (der übrigens mehr ist als auf der Hauptseite, was zu unseren Gunsten ist) ohne Werbung und Müll zur Verfügung gestellt.
Schauen wir uns den Quellcode an, um zu verstehen, womit wir es zu tun haben.

Wie Sie sehen können, liegt jede Nachricht separat im 'a'-Tag und hat die' Lenta'-Klasse. Wenn wir das 'a'-Tag öffnen, werden wir feststellen, dass sich darin ein' span'-Tag befindet, das die Klasse 'time2' oder 'time2 time3' sowie die Veröffentlichungszeit enthält. Nach dem Schließen des Tags sehen wir der Nachrichtentext selbst.
Was unterscheidet wichtige Nachrichten von unwichtigen Nachrichten? Dieselbe Klasse 'time2' oder 'time2 time3'. Nachrichten mit der Aufschrift "time2 time3" sind unsere roten Nachrichten. Da das Wesentliche der Aufgabe klar ist, können wir mit dem Üben fortfahren.
Trainieren
Um mit Parsern zu arbeiten, haben sich kluge Leute die "BeautifulSoup4" -Bibliothek ausgedacht, die viel mehr coole und nützliche Funktionen bietet, aber beim nächsten Mal mehr dazu. Wir benötigen auch die Anforderungsbibliothek, mit der wir verschiedene http-Anforderungen senden können. Wir werden sie herunterladen.
(Stellen Sie sicher, dass Sie die neueste Pip-Version haben)
pip install beautifulsoup4
pip install requests
Gehen Sie zum Code-Editor und importieren Sie unsere Bibliotheken:
from bs4 import BeautifulSoup
import requests
Speichern wir zunächst unsere URL in einer Variablen:
url = 'http://mignews.com/mobile'
Senden wir nun eine GET () -Anforderung an die Site und speichern die empfangenen Daten in der Variablen 'page':
page = requests.get(url)
Lassen Sie uns die Verbindung überprüfen:
print(page.status_code)
Der Code hat uns den Statuscode '200' zurückgegeben, was bedeutet, dass wir erfolgreich verbunden sind und alles in Ordnung ist.
Lassen Sie uns nun zwei Listen erstellen (ich werde später erklären, wofür sie sind):
new_news = [] news = []
Es ist Zeit, BeautifulSoup4 zu verwenden und unsere Seite zu füttern. Geben Sie in Anführungszeichen an, wie es uns helfen wird, 'html.parcer':
soup = BeautifulSoup(page.text, "html.parser")
Wenn Sie ihn bitten zu zeigen, was er dort gespeichert hat:
print(soup)
Wir werden den gesamten HTML-Code unserer Seite herausholen.
Verwenden wir nun die Suchfunktion in BeautifulSoup4:
news = soup.findAll('a', class_='lenta')
Schauen wir uns das, was wir hier geschrieben haben, genauer an.
Speichern Sie in der zuvor erstellten 'Nachrichten'-Liste (zu der ich versprochen habe zurückzukehren) alles mit dem' a'-Tag und der 'Nachrichten'-Klasse. Wenn wir darum bitten, alles, was gefunden wurde, an die Konsole auszugeben, werden uns alle Nachrichten auf der Seite angezeigt:

Wie Sie sehen können, werden neben dem Nachrichtentext die Tags 'a', 'span', die Klassen lenta 'und' time2 'und auch' time2 time3 'im Allgemeinen alles, was er nach unseren Wünschen gefunden hat.
Lass uns weitermachen:
for i in range(len(news)):
if news[i].find('span', class_='time2 time3') is not None:
new_news.append(news[i].text)
Hier durchlaufen wir in einer for-Schleife unsere gesamte Liste von Nachrichten. Wenn wir in den Nachrichten unter dem Index [i] das Tag 'span' und die Klasse 'time2 time3' finden, speichern wir den Text aus diesen Nachrichten in der neuen Liste 'new_news'.
Beachten Sie, dass wir '.text' verwenden, um die Zeilen in unserer Liste aus dem 'bs4.element.ResultSet' neu zu formatieren, das BeautifulSoup für seine Suche in einfachen Text verwendet.
Seien Sie vorsichtig, wenn ich mich lange Zeit mit diesem Problem befasst habe, weil ich die Funktionsweise von Datenformaten missverstanden habe und nicht weiß, wie man Debugging verwendet. Somit können wir diese Daten jetzt in einer neuen Liste speichern und alle Methoden der Listen verwenden, da dies nun gewöhnlicher Text ist und im Allgemeinen damit machen, was wir wollen.
Lassen Sie uns unsere Daten anzeigen:
for i in range(len(new_news)):
print(new_news[i])
Folgendes bekommen wir:

Wir bekommen Postzeit und nur interessante Neuigkeiten.
Anschließend können Sie einen Bot im Warenkorb erstellen und diese Nachrichten dort hochladen oder ein Widget mit aktuellen Nachrichten auf Ihrem Desktop erstellen. Im Allgemeinen können Sie eine bequeme Möglichkeit finden, um sich über die Neuigkeiten zu informieren.
Hoffentlich hilft dieser Artikel Neulingen zu verstehen, was mit Parsern gemacht werden kann, und hilft ihnen dabei, ein wenig voranzukommen.
Vielen Dank für Ihre Aufmerksamkeit, ich war froh, meine Erfahrungen zu teilen.