Das Schreiben von Programmen vollständig in Assemblersprache ist jedoch nicht nur lang, trostlos und schwierig, sondern auch etwas albern - da zu diesem Zweck Abstraktionen auf hoher Ebene erfunden wurden, um die Entwicklungszeit zu verkürzen und den Programmierprozess zu vereinfachen. Daher werden meistens separat genommene, gut optimierte Funktionen in Assemblersprache geschrieben, die dann aus höheren Sprachen wie C ++ und C # aufgerufen werden.
Auf dieser Grundlage wird Visual Studio die bequemste Programmierumgebung sein, die bereits MASM enthält. Sie können es über das Kontextmenü des Projekts Build Dependencies - Build Customizations ... mit einem C / C ++ - Projekt verbinden, indem Sie das Kontrollkästchen neben masm aktivieren. Die Assembler-Programme selbst befinden sich in Dateien mit dem .asm Erweiterung (in deren Eigenschaften der Elementtyp auf Microsoft Macro Assembler festgelegt werden muss). Dies ermöglicht nicht nur das Kompilieren und Aufrufen von Assembler-Programmen ohne unnötige Gesten, sondern auch das Durchführen eines End-to-End-Debuggens, das direkt aus c ++ oder c # (einschließlich des Haltepunkts in der Assembler-Liste) in die Assembler-Quelle "durchfällt". sowie Verfolgen des Status der Register zusammen mit den üblichen Variablen im Überwachungsfenster.
Satzstellung markieren
Visual Studio verfügt nicht über eine integrierte Syntaxhervorhebung für Assembler und andere Errungenschaften der modernen IDE-Struktur. Es kann jedoch mit Erweiterungen von Drittanbietern bereitgestellt werden.
AsmHighlighter ist historisch gesehen das erste mit minimaler Funktionalität und unvollständigem Befehlssatz - nicht nur AVX fehlt, sondern auch einige der Standard-Befehle, insbesondere fsqrt. Diese Tatsache veranlasste mich, meine eigene Erweiterung zu schreiben -
ASM Advanced Editor . Zusätzlich zum Hervorheben und Reduzieren von Codeabschnitten (unter Verwendung der Kommentare "; [", "; [+" und ";]") werden Hinweise an Register gebunden, die beim Herunterfahren des Codes (auch über Kommentare) angezeigt werden. Es sieht aus wie das:
;rdx=
oder so:
mov rcx, 8;=
Hinweise für Befehle sind ebenfalls vorhanden, jedoch in experimenteller Form - es stellte sich heraus, dass das vollständige Ausfüllen länger dauert als das Schreiben der Erweiterung selbst.
Es stellte sich auch plötzlich heraus, dass die üblichen Schaltflächen zum Kommentieren / Kommentieren des markierten Abschnitts des Codes nicht mehr funktionierten. Daher musste ich eine andere Erweiterung schreiben, in der diese Funktionalität an derselben Schaltfläche aufgehängt war, und die Notwendigkeit für diese oder jene Aktion wird automatisch ausgewählt.
Asm Alter- tauchte etwas später auf. Darin ging der Autor den anderen Weg und konzentrierte seine Bemühungen auf die integrierte Befehlsreferenz und die automatische Vervollständigung, einschließlich der Verfolgung von Tags. Dort ist auch eine Code-Faltung vorhanden (gemäß "#region / #end region"), aber es scheint noch keine Bindung von Kommentaren an Register zu geben.
32 vs. 64
Seit dem Erscheinen der 64-Bit-Plattform ist es zur Norm geworden, zwei Versionen von Anwendungen zu schreiben. Es ist Zeit, damit aufzuhören! Wie viel Vermächtnis können Sie ziehen. Gleiches gilt für Erweiterungen - Sie können einen Prozessor ohne SSE2 nur in einem Museum finden - außerdem funktionieren 64-Bit-Anwendungen ohne SSE2 nicht. Es wird kein Programmiervergnügen geben, wenn Sie 4 Varianten optimierter Funktionen für jede Plattform schreiben.
Der Vorteil der 64-Bit-Plattform liegt überhaupt nicht in den "breiten" Registern - sondern in der Tatsache, dass sich die Anzahl dieser Register verdoppelt hat - jeweils 16 Stück, sowohl für allgemeine Zwecke als auch für XMM / YMM. Dies vereinfacht nicht nur die Programmierung, sondern reduziert auch den Speicherzugriff erheblich.
FPU
Wenn es früher nirgendwo ohne FPU gab, tk. Funktionen mit reellen Zahlen ließen das Ergebnis oben auf dem Stapel, dann findet auf einer 64-Bit-Plattform der Austausch ohne seine Teilnahme unter Verwendung der xmm-Register der SSE2-Erweiterung statt. Intel empfiehlt in seinen Richtlinien außerdem aktiv, FPUs zugunsten von SSE2 zu streichen. Es gibt jedoch eine Einschränkung: Mit der FPU können Sie Berechnungen mit einer Genauigkeit von 80 Bit durchführen - was in einigen Fällen kritisch sein kann. Daher ist die FPU-Unterstützung nirgendwo hingegangen, und es lohnt sich definitiv nicht, sie als veraltete Technologie zu betrachten. Zum Beispiel kann die Berechnung der Hypotenuse "frontal" durchgeführt werden, ohne dass ein Überlauf befürchtet wird.
nämlich
fld x fmul st(0), st(0) fld y fmul st(0), st(0) faddp st(1), st(0) fsqrt fstp hypot
Die Hauptschwierigkeit bei der Programmierung der FPU ist ihre Stapelorganisation. Zur Vereinfachung wurde ein kleines Dienstprogramm geschrieben , das automatisch Kommentare mit dem aktuellen Status des Stapels generiert (es war geplant, ähnliche Funktionen direkt zur Haupterweiterung für die Syntaxhervorhebung hinzuzufügen - aber wir sind nie dazu gekommen).
Optimierungsbeispiel: Hartley-Transformation
Moderne C ++ - Compiler sind intelligent genug, um Code für einfache Aufgaben wie das Summieren von Zahlen in einem Array oder das Drehen von Vektoren automatisch zu vektorisieren und die entsprechenden Muster im Code zu erkennen. Daher funktioniert es nicht, einen signifikanten Leistungsgewinn für primitive Aufgaben zu erzielen. Im Gegenteil, es kann sich herausstellen, dass Ihr superoptimiertes Programm langsamer ausgeführt wird als vom Compiler generiert. Aber Sie sollten auch daraus keine weitreichenden Schlussfolgerungen ziehen - sobald die Algorithmen etwas komplizierter und für die Optimierung nicht mehr offensichtlich sind, verschwindet die Magie der Optimierung von Compilern. Durch manuelle Optimierung im Jahr 2021 ist es immer noch möglich, die Leistung um das Zehnfache zu steigern.
Als Aufgabe nehmen wir den Algorithmus (langsam) Hartley verwandelt :
der Code
static void ht_csharp(double[] data, double[] result)
{
int n = data.Length;
double phi = 2.0 * Math.PI / n;
for (int i = 0; i < n; ++i)
{
double sum = 0.0;
for (int j = 0; j < n; ++j)
{
double w = phi * i * j;
sum += data[j] * (Math.Cos(w) + Math.Sin(w));
}
result[i] = sum / Math.Sqrt(n);
}
}
Es ist auch ziemlich trivial für die automatische Vektorisierung (wir werden später sehen), aber es gibt etwas mehr Raum für Optimierung. Nun, unsere optimierte Version wird folgendermaßen aussehen:
Code (Kommentare entfernt)
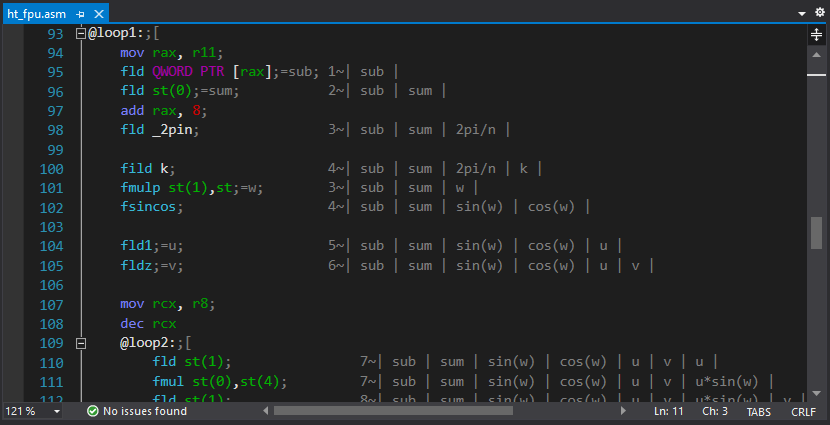
ht_asm PROC local sqrtn:REAL10 local _2pin:REAL10 local k:DWORD local n:DWORD and r8, 0ffffffffh mov n, r8d mov r11, rcx xor rcx, rcx mov r9, r8 dec r9 shr r9, 1 mov r10, r8 sub r10, 2 shl r10, 3 finit fld _2pi fild n fdivp st(1), st fstp _2pin fld1 fild n fsqrt fdivp st(1), st ; mov rax, r11 mov rcx, r8 fldz @loop0: fadd QWORD PTR [rax] add rax, 8 loop @loop0 fmul st, st(1) fstp QWORD PTR [rdx] fstp sqrtn add rdx, 8 mov k, 1 @loop1: mov rax, r11 fld QWORD PTR [rax] fld st(0) add rax, 8 fld _2pin fild k fmulp st(1),st fsincos fld1;=u fldz;=v mov rcx, r8 dec rcx @loop2: fld st(1) fmul st(0),st(4) fld st(1) fmul st,st(4) faddp st(1),st fxch st(1) fmul st, st(4) fxch st(2) fmul st,st(3) fsubrp st(2),st fld st(0) fadd st, st(2) fmul QWORD PTR [rax] faddp st(5), st fld st(0) fsubr st, st(2) fmul QWORD PTR [rax] faddp st(6), st add rax, 8 loop @loop2 fcompp fcompp fld sqrtn fmul st(1), st fxch st(1) fstp QWORD PTR [rdx] fmulp st(1), st fstp QWORD PTR [rdx+r10] add rdx,8 sub r10, 16 inc k dec r9 jnz @loop1 test r10, r10 jnz @exit mov rax, r11 fldz mov rcx, r8 shr rcx, 1 @loop3:;[ fadd QWORD PTR [rax] fsub QWORD PTR [rax+8] add rax, 16 loop @loop3;] fld sqrtn fmulp st(1), st fstp QWORD PTR [rdx] @exit: ret ht_asm ENDP
Bitte beachten Sie: Es gibt kein Abrollen der Schleife, kein SSE / AVX, keine Cosinustabellen, keine Komplexitätsreduzierung aufgrund des "schnellen" Transformationsalgorithmus. Die einzige explizite Optimierung ist die iterative Sinus / Cosinus-Berechnung in der inneren Schleife des Algorithmus direkt in den FPU-Registern.
Da es sich neben der Geschwindigkeit auch um eine integrale Transformation handelt, sind wir auch an der Genauigkeit der Berechnung und der Höhe der akkumulierten Fehler interessiert. In diesem Fall ist es sehr einfach, es zu berechnen - indem wir zwei Transformationen hintereinander durchführen, sollten wir (theoretisch) die Anfangsdaten erhalten. In der Praxis unterscheiden sie sich geringfügig, und es ist möglich, den Fehler durch die Standardabweichung des erhaltenen Ergebnisses vom analytischen Ergebnis zu berechnen.
Die Ergebnisse der automatischen Optimierung eines c ++ - Programms können auch stark von den Einstellungen der Compilerparameter und der Auswahl eines gültigen erweiterten Befehlssatzes (SSE / AVX / etc) abhängen. Es gibt jedoch zwei Nuancen:
- Moderne Compiler neigen dazu, alles zu berechnen, was in der Kompilierungsphase möglich ist. Daher ist es im kompilierten Code durchaus möglich, anstelle des Algorithmus einen vorberechneten Wert zu sehen, der dem Compiler bei der Messung der Leistung einen Vorteil von 100500 verschafft mal. Um dies zu vermeiden, verwenden meine Messungen die externe Funktion zero (), die die Eingabeparameter mehrdeutig macht.
- « AVX» — , AVX. . – , AVX .
Der interessanteste Optimierungsparameter ist das Gleitkommamodell, das präzise | strenge | schnelle Werte annimmt. Im Fall von Fast kann der Compiler nach eigenem Ermessen mathematische Transformationen durchführen (einschließlich iterativer Berechnungen) - tatsächlich findet nur in diesem Modus eine automatische Vektorisierung statt.
Also, Visual Studio 2019-Compiler, AVX2-Zielframework, Gleitkommamodell = Präzise. Um es noch interessanter zu machen, wird es von einem c # -Projekt auf einem Array von 10.000 Elementen gemessen:
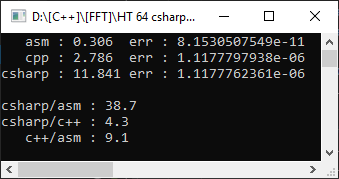
C # erwies sich erwartungsgemäß als langsamer als C ++, und die Assembler-Funktion erwies sich als neunmal schneller! Es ist jedoch zu früh, um sich zu freuen - setzen wir Floating Point Model = Fast:

Wie Sie sehen können, hat dies dazu beigetragen, den Code erheblich zu beschleunigen, und die Verzögerung bei der manuellen Optimierung betrug nur das 1,8-fache. Was sich aber nicht geändert hat, ist der Fehler. Dass die andere Option einen Fehler von 4 signifikanten Stellen ergab - und dies ist bei mathematischen Berechnungen wichtig.
In diesem Fall erwies sich unsere Version als schneller und genauer. Dies ist jedoch nicht immer der Fall - und wenn wir die FPU zum Speichern der Ergebnisse auswählen, verlieren wir unweigerlich die Möglichkeit der Optimierung durch Vektorisierung. Außerdem verbietet niemand die Kombination von FPU und SSE2 in Fällen, in denen dies sinnvoll ist (insbesondere habe ich diesen Ansatz bei der Implementierung der Doppel-Doppel-Arithmetik verwendet , da ich während der Multiplikation eine 10-fache Beschleunigung erhalten habe).
Die weitere Optimierung der Hartley-Transformation liegt in einer anderen Ebene und erfordert (für eine beliebige Größe) den Bluestein-Algorithmus, der auch für die Genauigkeit von Zwischenberechnungen entscheidend ist. Nun, dieses Projekt kann auf GitHub heruntergeladen werden , und als Bonus gibt es auch einige Funktionen zum Summieren / Skalieren von Arrays für FPU / SSE2 / AVX (für Bildungszwecke).
Was zu lesen
Literatur zum Monteur in loser Schüttung. Es gibt jedoch mehrere wichtige Quellen:
1. Offizielle Dokumentation von Intel . Nichts überflüssiges, die Wahrscheinlichkeit von Tippfehlern ist minimal (die in der gedruckten Literatur allgegenwärtig sind).
2. Online-Verzeichnis , entnommen aus der offiziellen Dokumentation.
3. Standort von Agner Fogh , einem anerkannten Optimierungsexperten. Enthält auch Beispiele für optimierten C ++ - Code unter Verwendung von Intrinsics.
4. EINFACH FPU .
5.40 Grundübungen in der Assembler-Programmierung .
6. Alles, was Sie wissen müssen, um mit der Programmierung für 64-Bit-Versionen von Windows zu beginnen .
Anhang: Warum nicht einfach Intrinsics verwenden?
Versteckter Text
, , , - — , SIMD- . — .
:
:
- . DOS , – .
- . – .
- . , , (FPU). . , //etc.
- - – , , . , , .
- , C++ , - SIMD-. 32- XMM8 XMM0 / XMM7 – . — , , , . – , C++.
- , . , – Microsoft , C++.