Hallo, alle miteinander. Wir setzen diese Artikelserie darüber fort, was Data Science für die Vorhersage von COVID-19 bieten kann. Der erste Artikel ist hier . Heute werden wir über die zweite Klasse von Modellen zur Vorhersage der Dynamik der Ausbreitung von COVID-19 sprechen. Sie basieren auf Annahmen über eine Zunahme der Inzidenz und beschreiben mittel- und langfristig die Situation. Wir sprechen mit Nikolay Kobalo, Senior Data Engineer bei CFT.
Erinnern wir uns, welche Bedingungen wir haben:
Gegeben: Kolossale datenwissenschaftliche Fähigkeiten, drei talentierte Spezialisten.
Finden: Möglichkeiten, die Ausbreitung von COVID-19 in einer Woche vorherzusagen.
Fahren wir mit der zweiten Lösung fort.
- Kolya, hallo. Sagen Sie uns, mit welchem Modell Sie dieses Problem gelöst haben.
- Ich habe eines der Modelle genommen, das meiner Meinung nach am besten zu diesem Anlass passt. Das Modell wird in Form einer Differentialgleichung dargestellt und besteht aus vier Funktionen:
1. Die Anzahl der Personen, die für eine Infektion mit dieser Infektion anfällig sind;
2. Die Anzahl der Träger, dh Personen, die bereits infiziert sind, aber noch nichts davon wissen;
3. Die Anzahl der Kranken, die andere infizieren;
4. Die Anzahl der wiederhergestellten.
Wie Sie sehen können, berücksichtigt dieses Modell nicht die Mortalität durch Covid. Sie können die Details des Modells auf meinem Github sehen: https://github.com/rerf2010rerf/COVID-19-forecast/blob/master/public.ipynb
Das Modell heißt SEIR und gehört zu einer Familie von Kompartimentmodellen, die die Ausbreitung einer Epidemie beschreiben. Modelle dieser Familie ermöglichen die Beschreibung verschiedener Arten von Infektionen. Zum Beispiel diejenigen, für die Immunität entwickelt wurde (oder im Gegenteil nicht entwickelt wird). Oder diejenigen, die eine Inkubationszeit haben (oder nicht haben). Im Fall von COVID-19 verwendete ich ein Modell mit einer Inkubationszeit und der Immunität, die bei kranken Menschen erzeugt wurde.
Alle polygamen Modelle sind Systeme von Differentialgleichungen erster Ordnung. Für SEIR sehen sie folgendermaßen aus:

Hier:
S (t) - (anfällig) - die Anzahl der Personen, die anfällig für Infektionen sind.
E (t) - (exponiert) - die Anzahl der Träger, d.h. infizierte Menschen, bei denen sich die Krankheit aufgrund der Inkubationszeit noch nicht manifestiert hat.
Ich (t) - (ansteckend) - infiziert.
R (t) - (wiederhergestellt) - wiederhergestellt.
N = S + E + I + R - Populationsgröße. Es bleibt konstant, d.h. Es wird angenommen, dass niemand an der Krankheit stirbt.
μ ist die natürliche Sterblichkeitsrate.
α ist der Kehrwert der Inkubationszeit der Krankheit.
γ ist der Kehrwert der durchschnittlichen Erholungszeit.
β ist der Intensitätskoeffizient der Kontakte, die zur Infektion führen.
Der Lebenszyklus einer Person im SEIR-Modell sieht folgendermaßen aus:

Eine gesunde, aber noch nicht kranke Person (anfällig) kann von einer infizierten (infektiösen) Person infiziert werden. Die Wahrscheinlichkeit, dass eine gesunde Person infiziert wird, wird durch den β-Parameter beschrieben.
Eine infizierte Person befindet sich in einem Zustand eines Infektionsträgers (exponiert). Träger sind Menschen, bei denen sich die Krankheit noch nicht manifestiert hat, dh sie haben eine Inkubationszeit. Träger können niemanden infizieren. Der Übergang von krankheitsanfälligen Personen in den Zustand der Träger wird durch die ersten beiden Gleichungen des Modells beschrieben (unter Verwendung des Ausdrucks β (I / N)).
Nach 1 / α Tagen (Inkubationszeit) nach der Infektion tritt der Träger in den infizierten Zustand (infektiös) ein.
Nach 1 / γ Tagen (Erholungszeit) tritt die infizierte Person in den wiederhergestellten Zustand ein. Die erholte Person entwickelt Immunität und kann sich diese Infektion nicht mehr zuziehen.
Das Modell berücksichtigt auch die natürliche Sterblichkeit der Bevölkerung in der Bevölkerung. Die Mortalität im SEIR-Modell wird durch die Fertilität ausgeglichen, sodass sich die Gesamtbevölkerung nicht ändert. Gleichzeitig wird die Zahl der geborgenen Menschen in der Bevölkerung sinken, da Neugeborene keine Immunität haben werden. Dementsprechend nimmt die Zahl der Menschen, die sich in der Bevölkerung erholt haben, im Laufe der Zeit ab. Die Sterblichkeitsrate wird durch den Parameter μ beschrieben.
- Sie haben Koeffizienten im Modell. Haben Sie irgendwelche Annahmen getroffen?
- Eine meiner Annahmen war, dass die natürliche Sterblichkeit in der Bevölkerung vernachlässigt werden kann, d. H. μ = 0. Diese Annahme scheint gültig zu sein, da wir die Ausbreitung der Infektion über einen kurzen Zeitraum von nur wenigen Monaten vorhersagen wollen.
Darüber hinaus geht das gewählte Modell davon aus, dass diejenigen, die sich erholt haben, immun gegen Infektionen werden, dh sie können nicht erneut infiziert werden.
- Und das ist übrigens so?
- Es scheint ja. Es wurden bereits mehrere Neuinfektionen registriert, die jedoch meistens nicht auftreten. Daher können wir sagen, dass es so ist.
- Und was ist Ihr „Kontaktintensitätsfaktor“?
„Hier meine ich die Intensität, mit der Menschen miteinander in Kontakt kommen und sich infizieren. Grob gesagt ist dies die Wahrscheinlichkeit, dass, wenn sich zwei Menschen treffen, bei denen einer infiziert ist und der andere nicht, der zweite irgendwann krank wird.
- Wie viel ist das? Nah an einem?
- Nein, ich habe diesen Parameter entsprechend den Daten ausgewählt. Dies hängt vom Grad der Selbstisolation ab. Wenn beispielsweise ein großer Teil der Bevölkerung nicht mit anderen Menschen in Kontakt kommt, wird der Koeffizient niedriger, und wenn die Bevölkerung aktiv miteinander kommuniziert, wächst er.
- Okay. Haben Sie auch eine Erholungszeit? Sowohl Alpha als auch Gamma?
- Ich habe das Alpha gleich 1 / 5.1 genommen, dies war ein bekannter Parameter für COVID-19 (der inverse Parameter zur Inkubationszeit in Tagen). Und ich habe den Farbumfang entsprechend den Daten ausgewählt. Dies ist "Genesungszeit". Die „Intensität der Kontakte“ basiert übrigens auch auf den Daten.
- Gut. Können Sie uns andererseits sagen, welche Annahmen die Modelle treffen? Was bedeutet jede Gleichung?
- Die erste Gleichung beschreibt die Änderung der Anzahl der anfälligen Infektionen. Insbesondere besagt der dritte Begriff, dass die Anzahl der anfälligen Personen umso schneller abnimmt, je intensiver die Kontakte zwischen dem Infizierten und dem Anfälligen sind. Wenn jemand infiziert war und dann infiziert wurde, ist er nicht mehr in dieser Nummer enthalten. Zu Beginn der Epidemie entspricht dies der Anzahl der Menschen in der Bevölkerung.
Dann wird die Anzahl der Träger denjenigen entnommen, die für eine Infektion anfällig sind, dh eine Person kommuniziert mit einer infizierten Person, wird infiziert und wird ein Träger der Infektion. Dies ist in der zweiten Gleichung beschrieben. Es heißt, dass die Wachstumsrate der Träger umso größer ist, je intensiver die Kontakte zwischen dem Anfälligen und dem Infizierten sind und im Gegenteil, je weniger, desto weniger Träger sind im Moment übrig.
Die dritte Gleichung besagt, dass die Wachstumsrate der Infizierten umso größer ist, je mehr Träger es jetzt gibt (die sich in infizierte verwandeln) und je weniger, desto mehr Infizierte gibt es bereits.
Die vierte Gleichung beschreibt die Wachstumsrate derjenigen, die sich erholt haben. Je größer, desto infizierter (wer kann sich erholen) und je weniger, desto mehr erholt sich bereits.
- Klingt nach einer Beschreibung der Entwicklung der Situation.
- Tatsächlich gibt es verschiedene Modelle. Dies ist das SEIR-Modell, und es gibt SIR, bei denen keine Anfälligkeit für Infektionen besteht. Es gibt Modelle mit mehr Parametern. Es gibt ein Modell, das die Sterblichkeit aufgrund einer Infektion vorsieht, aber ich habe es nicht verwendet.
- Wo haben Sie dieses Modell gefunden?
- Gegoogelt. Es gibt einen Artikel auf Wikipedia. Zusätzliche Artikel gefunden.
- Sie haben auch die Grafiken präsentiert.
- Diese Grafik ist ein Beispiel. Es basiert nicht auf realen Daten. Es zeigt nur, wie sich das Modell verhält. Sie sagt voraus, dass alle irgendwann krank werden und gesund werden.

- Okay, du hast alles genommen und was dann?
- Ich habe die Daten genommen, die nach Ländern verfügbar sind. Er nahm an, dass die Sterblichkeitsrate Null ist. Die Unterschiede wurden in Form von endlichen Differenzen umgeschrieben:

Als Operator für endliche Differenzen in dieser Lösung wird eine zweiseitige Differenz verwendet.
Die Anzahl der wiederhergestellten Personen R pro Tag ist in den Anfangsdaten enthalten, und die Anzahl der infizierten I entspricht der Anzahl der bestätigten Fälle abzüglich der Anzahl der wiederhergestellten Personen. Aus der letzten Gleichung können wir also γ durch Optimierung der MALE-Zielfunktion (ΔR-γI) ermitteln.
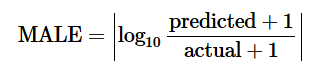
Um zu verfolgen, wie sich Quarantänemaßnahmen auf die Entwicklung der Epidemie auswirken, habe ich meine Aufgabe ein wenig kompliziert und den β-Koeffizienten durch die β (t) -Funktion ersetzt. Schließlich sollte mit der Einführung der Quarantäne im Land die Infektionsrate sinken. was bedeutet, dass in unserem Fall β nicht konstant ist. Da wir bereits alle Anfangsbedingungen zur Lösung des Unterschieds haben, können wir die Optimierung verwenden, um die Funktion β (t) zu finden.
- Dies ist ein Tag des Unterschieds?
- Tag abzüglich des Vortages. Ich habe die Daten eingesteckt und die unbekannten Koeffizienten berechnet.
- Beta und Gamma?
- Ich habe Alpha 5.1 Tage genommen. Dementsprechend war es notwendig, Beta und Gamma zu finden - die Intensität der Kontakte und die Zeit der Genesung.
- Und was ist mit dir passiert?
- Es gibt Grafiken. Jede Region und jedes Land erwies sich als unterschiedlich. Ich habe mich für jedes Land einzeln entschieden. Auf der linken Seite befindet sich eine grafische Darstellung der Daten (schwarz - es war echt, rot - infiziert und wiederhergestellt, vom Modell vorhergesagt). Infiziert + genesen - es stellt sich heraus, E + R. Rechts ist das Beta-Koeffizientendiagramm. Beta soll übrigens zeitabhängig sein. Hier fällt der größte Sprung in β mit der Zeit der Quarantäne am 30. März zusammen.
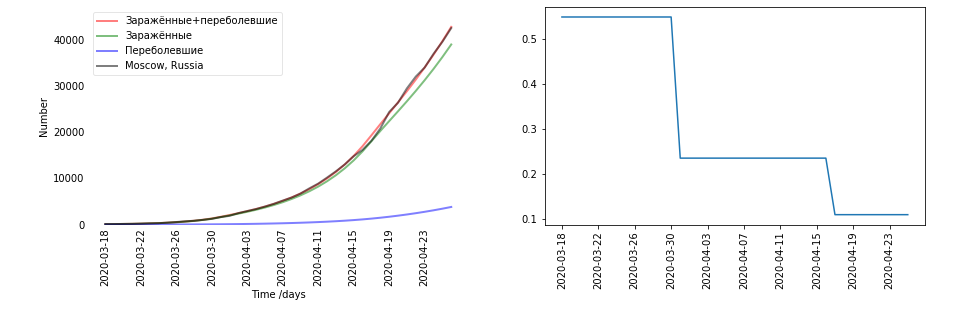
- Und Sie haben es nach den Daten gezählt oder angenommen?
- Dies wird bereits anhand der Daten berechnet. Dies ist genau das Ergebnis des Trainings in Moskau.
- Haben Sie die Zeitschwellen selbst festgelegt?
- Ich dachte, dass die Funktion eine solche zweistufige Form hat. Und optimiert. Ich passe nur die Daten an und finde die optimalen Funktionen, die am besten passen. Ich habe auch versucht, Funktionen mit einer anderen Anzahl von Sprossen zu verwenden, aber die zweistufigen zeigten bessere Ergebnisse.
- Werfen wir einen Blick auf die Länder, zum Beispiel Italien. Nun, hier haben Sie ein anderes Bild ...

- In Italien hat die Quarantäne anscheinend besser funktioniert. Und es gibt mehr Menschen, die krank waren. Das Modell bestätigte, dass die Quarantäne am 9. März eingeführt wurde.
- Was haben Sie für die endgültige Prognose ausgewählt?
- Für die endgültige Prognose habe ich eine konstante Intensität der Kontakte gewählt und ein Modell mit den letzten beiden Punkten erstellt. Das heißt, wir kennen die gesamte Vorgeschichte, aber wir nehmen nur die letzten Punkte.
- Dies ist für die Vorhersage für die Woche?
- Ja. Und was vorher passiert ist, war zu sehen, wie sich das Modell verhält. Und dann habe ich mir schon angeschaut, welche Funktion besser zu übernehmen ist und wie viele Punkte zu studieren sind.
- Wenn Sie bis jetzt prognostizieren wollten, hätten Sie wahrscheinlich eine andere Entscheidung erhalten. Haben Sie etwas, das zeigt, wie sich die Situation weiterentwickeln kann?
- Ja. Aber dort ist es nicht sehr interessant. Sie sagte voraus, dass alle in Moskau bis September krank sein würden.
- Bei einem der Meetups sagten Sie, dass laut Ihrer Prognose der Höhepunkt im Juli gewesen sein sollte. Tatsächlich passierte alles etwas früher. Was hat das Modell Ihrer Meinung nach nicht berücksichtigt?
- Wahrscheinlich Beta. Vielleicht hat sich die Quarantäne verschärft. Es ist möglich, dass die Intensität der Kontakte aufgrund der Tatsache abgenommen hat, dass Menschen krank waren und sich nicht infizieren und nicht infizieren. Beta sollte irgendwie davon abhängen. Und hier wird es nicht berücksichtigt.
- Nun, das heißt, Sie sagen, wir können alles mit einer Beta regulieren?
- Nach bekannten Daten - ja, wir können mit Beta und Gamma anpassen.
- Prognostiziert Ihr Modell die nächste Welle?
- Nein, alles ist stabil: es wächst, es wächst, es wächst und jeder wird krank. Obwohl es auch einen Faktor der Saisonalität gibt. Zum Beispiel Herbstperioden (wenn die Grippe usw. das Immunsystem geschwächt ist). Das Modell berücksichtigt dies jedoch nicht.
- Was sind die Vor- und Nachteile Ihres Modells?
- Zum Zeitpunkt der Modellzusammenstellung waren nur wenige Daten bekannt. Jetzt sind sowohl die Erholungszeit als auch die Inkubationszeit bereits bekannt (damals war 5.1, jetzt wird es genauer gemessen). Von den Profis: Es zeigt den Prozess selbst, wie es geht. Und wenn wir das Beispiel anderer Länder, zum Beispiel Italien, Deutschland, genauer untersuchen, wie diese Betas beeinflusst wurden, wäre es uns möglich, dieses Modell zu verfeinern und eine genauere Langzeitprognose zu erstellen.
, data science – .
, , . - – , , , , .
, , . .Er hat das coolste Modell gemacht;)