In gewisser Weise ist dieser Artikel eine Fortsetzung unseres Artikels über die Größenbestimmung bei Habré . Aber hier sind Beispiele aus dem wirklichen Leben aufgetaucht. Wenn also eine Art Kontinuität erforderlich ist, beginnen Sie mit diesem Artikel und kehren Sie dann hierher zurück. Alle Details sind unter dem Schnitt.
Dieser Artikel basiert auf dem Benchmarking und der Dimensionierung Ihres Elasticsearch-Clusters für Protokolle und Metriken im Elastic-Blog. Wir haben es ein wenig modifiziert und die Beispiele mit Cloud-basiertem Elastic entfernt.
Hardwareressourcen für Elasticsearch-Cluster
Die Leistung eines Elasticsearch-Clusters hängt hauptsächlich davon ab, wie Sie ihn verwenden und was darunter läuft (im Sinne der Hardware). Die Hardware zeichnet sich durch Folgendes aus:
Gewölbe
Der Anbieter empfiehlt die Verwendung von SSDs, wo immer dies möglich ist. Dies ist jedoch möglicherweise nicht überall der Fall, sodass die Hot-Warm-Cold-Architektur und das Index Lifecycle Management (ILM) zu Ihren Diensten stehen.
Elasticsearch erfordert keinen redundanten Speicher (Sie können auf RAID 1/5/10 verzichten). Protokoll- oder Metrikspeicherszenarien verfügen normalerweise über mindestens ein Replikat für minimale Fehlertoleranz.
Erinnerung
Der Speicher auf dem Server ist unterteilt in:
JVM-Heap. Speichert Metadaten zu Clustern, Indizes, Segmenten, Segmenten und Dokumentfelddaten. Idealerweise sollten Sie dafür 50% des verfügbaren Arbeitsspeichers zuweisen.
Betriebssystem-Cache. Elasticsearch verwendet den verbleibenden verfügbaren Speicher zum Zwischenspeichern von Daten, wodurch die Leistung erheblich verbessert wird, indem das Lesen von Datenträgern bei Volltextsuchen, Dokumentwertaggregationen und Sortieren verhindert wird. Und vergessen Sie nicht, Swap (Swap-Datei) zu deaktivieren, um zu vermeiden, dass der Inhalt des RAM auf die Festplatte geleert und dann von dieser gelesen wird (dies ist langsam!).
Zentralprozessor
Elasticsearch-Knoten haben sogenannte. Thread-Pools und Thread-Warteschlangen, die die verfügbaren Computerressourcen verwenden. Die Anzahl und Leistung der CPU-Kerne bestimmen die durchschnittliche Geschwindigkeit und den Spitzendurchsatz von Datenoperationen in Elasticsearch. Meistens sind dies 8-16 Kerne.
Netzwerk
Netzwerkleistung - Sowohl Bandbreite als auch Latenz können die Kommunikation zwischen Elasticsearch-Knoten und die Kommunikation zwischen Elasticsearch-Clustern erheblich beeinträchtigen. Beachten Sie, dass standardmäßig jede Sekunde eine Knotenverfügbarkeitsprüfung durchgeführt wird. Wenn ein Knoten nicht innerhalb von 30 Sekunden pingt, wird er als nicht verfügbar markiert und vom Cluster heruntergefahren.
Dimensionierung eines Elasticsearch-Clusters nach Speichervolumen
Das Speichern von Protokollen und Metriken erfordert normalerweise viel Speicherplatz. Daher lohnt es sich, die Menge dieser Daten zu verwenden, um zunächst die Größe unseres Elasticsearch-Clusters zu bestimmen. Im Folgenden finden Sie einige Fragen zum Verständnis der Datenstruktur, die in einem Cluster verwaltet werden muss:
- Wie viele Rohdaten (GB) indizieren wir pro Tag?
- Wie viele Tage werden wir die Daten aufbewahren?
- Wie viele Tage sind in der heißen Zone?
- Wie viele Tage sind in der warmen Zone?
- Wie viele Replikate werden verwendet?
Es ist ratsam, 5% oder 10% darauf zu legen, damit immer 15% des gesamten Speicherplatzes auf Lager bleiben. Versuchen wir nun, diesen Fall zu zählen.
Gesamtdatengröße (GB) = Anzahl der Rohdaten pro Tag (GB) * Anzahl der Speichertage * (Anzahl der Replikate + 1).
Gesamtspeicher (GB) = Gesamtspeicher (GB) * (1 + 0,15 Speicherplatz + 0,1 zusätzlicher Speicher).
Gesamtzahl der Datenknoten = OKRVVERH (Gesamtdatengröße (GB) / Speichergröße pro Datenknoten / Verhältnis Speicher: Daten). Bei einer großen Installation ist es besser, einen weiteren Knoten auf Lager zu halten.
Elastic empfiehlt die folgenden Speicherverhältnisse: Daten für verschiedene Knotentypen: heiß → 1:30 (30 GB Speicherplatz pro Gigabyte Speicher), warm → 1: 160, kalt → 1: 500). OKRVVERKH - Surround auf die nächsthöhere Ganzzahl.
Beispiel für die Berechnung kleiner Cluster
Nehmen wir an, dass täglich ~ 1 GB Daten eintreffen, die 9 Monate lang gespeichert werden müssen.
Gesamtdaten (GB) = 1 GB x (9 Monate x 30 Tage) x 2 = 540 GB
Gesamtspeicher (GB) = 540 GB x (1 + 0,15 + 0,1) = 675 GB
Gesamtzahl der Datenknoten = 675 GB / 8 GB RAM / 30 = 3 Knoten.
Beispiel für die Berechnung eines großen Clusters
Sie erhalten 100 GB pro Tag und speichern diese Daten 30 Tage in der heißen Zone und 12 Monate in der warmen Zone. Sie haben 64 GB Speicher pro Knoten, von denen 30 GB für den JVM-Heap und der Rest für den Betriebssystem-Cache zugewiesen sind. Das empfohlene Verhältnis von Speicher: Daten für die heiße Zone beträgt 1:30, für die warme Zone 1: 160.
Wenn Sie also 100 GB pro Tag erhalten und diese Daten 30 Tage lang speichern müssen, erhalten Sie:
Gesamtmenge von Daten (GB) in der Hot Zone = (100 GB x 30 Tage * 2) = 6000 GB
Gesamtspeicher der Hot Zone (GB) = 6000 GB x (1 + 0,15 + 0,1) = 7500 GB Gesamtdatenknoten der
Hot Zone = OKRVUPH ( 7500 / 64/30) + 1 = 5 Knoten Gesamtdaten
(GB) in der warmen Zone= (100 GB x 365 Tage * 2) = 73.000 GB
Gesamtspeicher (GB) in der Warmzone = 73.000 GB x (1 + 0,15 + 0,1) = 91.250 GB
Gesamtzahl der Datenknoten in der Warmzone = OKRVVERKH (91 250 / 64/160) + 1 = 10 Knoten
Somit haben wir 5 Knoten für die heiße Zone und 10 Knoten für die warme Frucht. Für die kalte Zone ähnliche Berechnungen, aber das Speicherverhältnis: Die Daten werden bereits 1: 500 sein.
Leistungstests
Sobald die Größe des Clusters bestimmt wurde, muss bestätigt werden, dass die Mathematik im wirklichen Leben funktioniert.
Dieser Test verwendet dasselbe Tool wie die Elasticsearch-Ingenieure Rally . Es ist einfach bereitzustellen und auszuführen und vollständig anpassbar, sodass mehrere Szenarien (Tracks) getestet werden können.
Um die Analyse der Ergebnisse zu vereinfachen, ist der Test in zwei Abschnitte unterteilt: Indizierung und Suchanfragen. Bei den Tests werden Daten aus Metricbeat- Tracks und Webserver-Protokollen verwendet .
Indizierung
Das Testen beantwortet die folgenden Fragen:
- Was ist der maximale Durchsatz für die Indizierung von Clustern?
- Wie viele Daten können pro Tag indiziert werden?
- Ist der Cluster größer oder kleiner als die entsprechende Größe?
Dieser Test verwendet einen 3-Knoten-Cluster mit der folgenden Konfiguration für jeden Knoten:
- 8 vCPU;
- Festplatte;
- 32 GB / 16 Heap.
Indizierungstest Nr. 1
Der für den Test verwendete Datensatz besteht aus Metricbeat-Daten mit den folgenden Merkmalen:
- 1.079.600 Dokumente;
- Datenvolumen: 1,2 GB;
- Durchschnittliche Dokumentgröße: 1,17 KB.
Als nächstes werden mehrere Tests durchgeführt, um die optimale Paketgröße und die optimale Anzahl von Threads zu bestimmen.
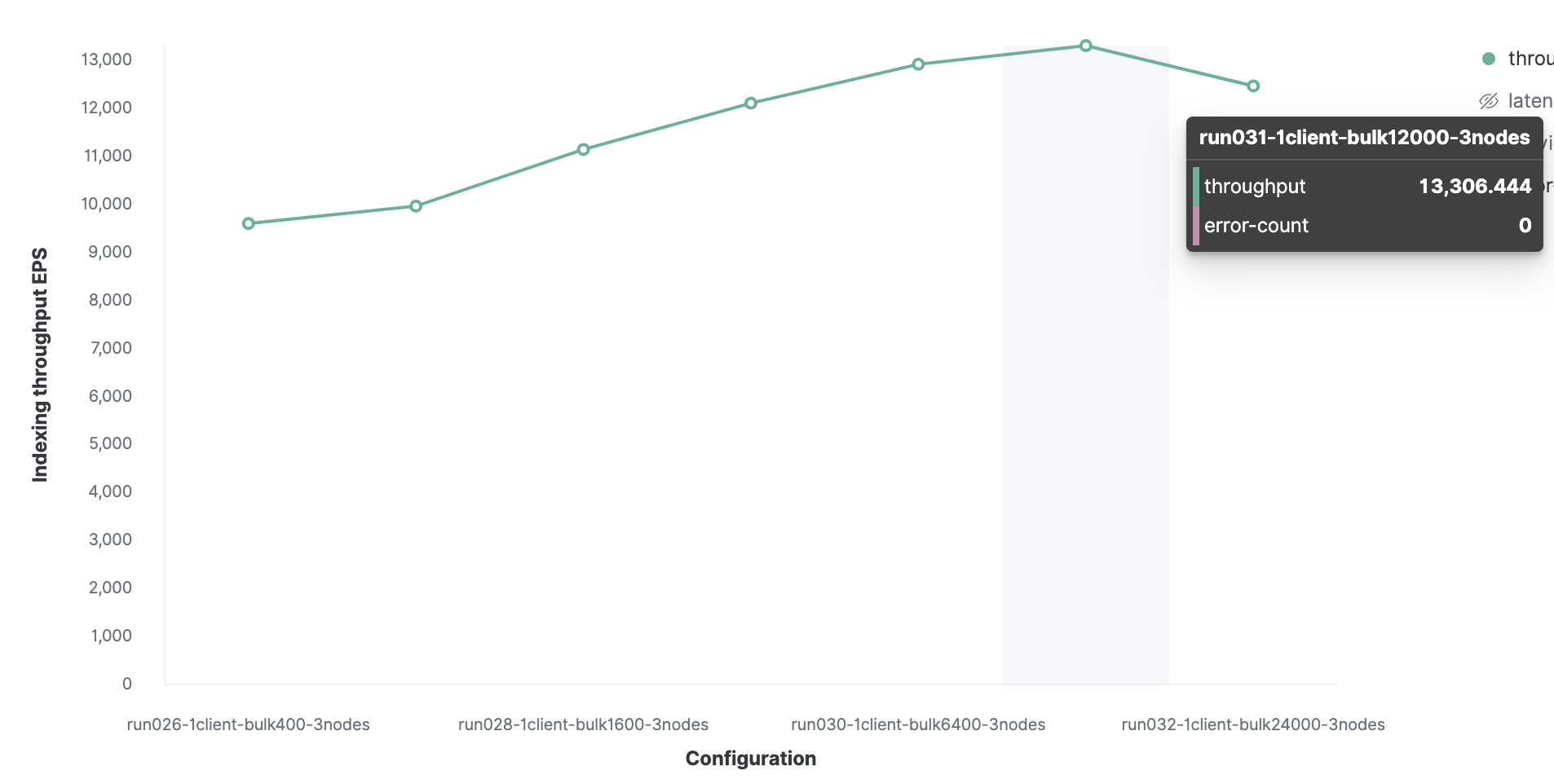
Alles beginnt mit 1 Rallye-Client, um die optimale Paketgröße zu finden. Zunächst werden 100 Dokumente geladen, bei doppelten Starts verdoppelt sich ihre Anzahl. Das Ergebnis ist eine optimale Stapelgröße von 12.000 Dokumenten (das sind ungefähr 13,7 MB). Wenn die Paketgröße weiter zunimmt, beginnt die Leistung zu sinken.
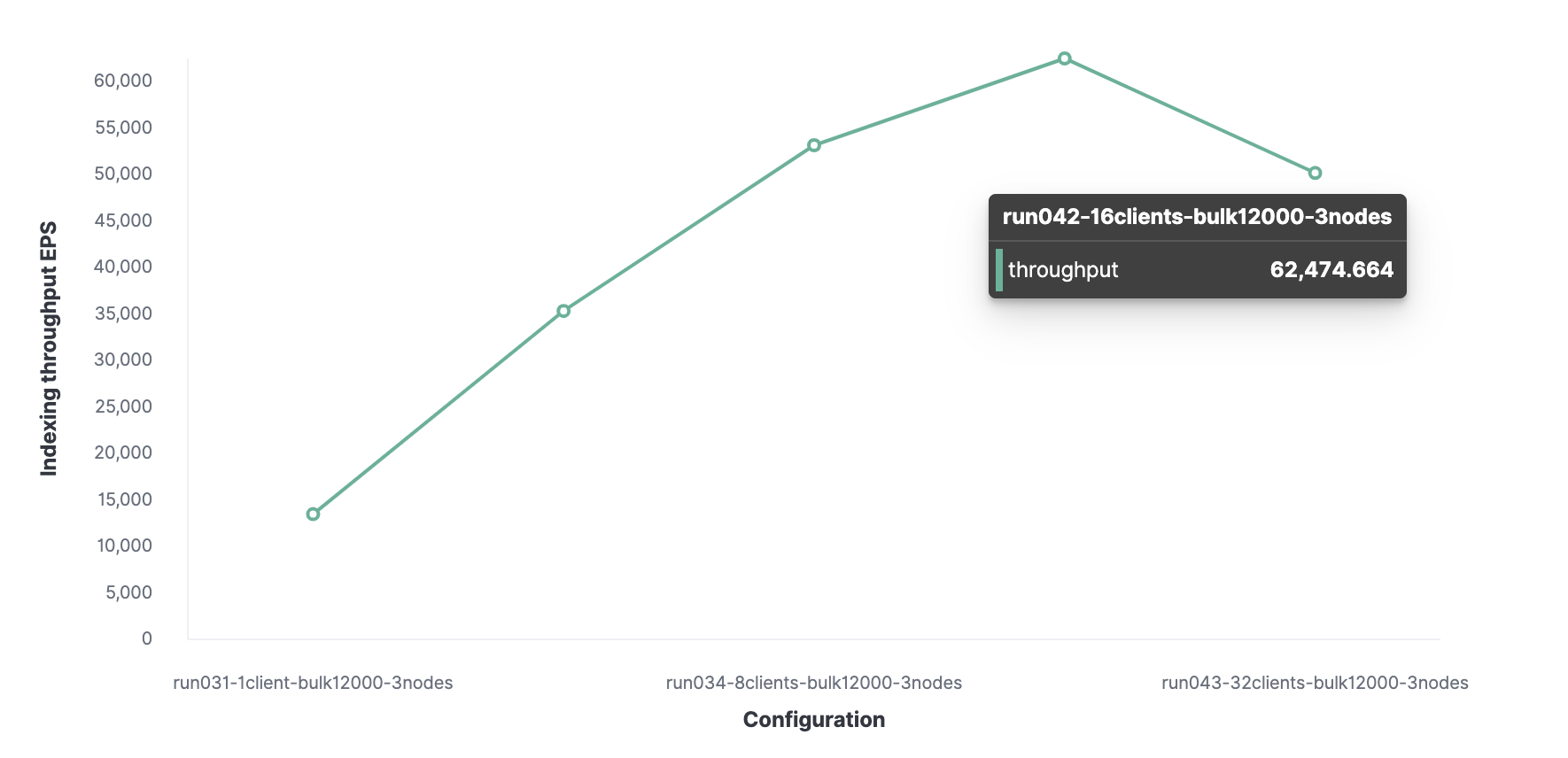
Unter Verwendung einer ähnlichen Methode ist 16 die optimale Anzahl von Clients, um 62.000 indizierte Ereignisse pro Sekunde zu erreichen.
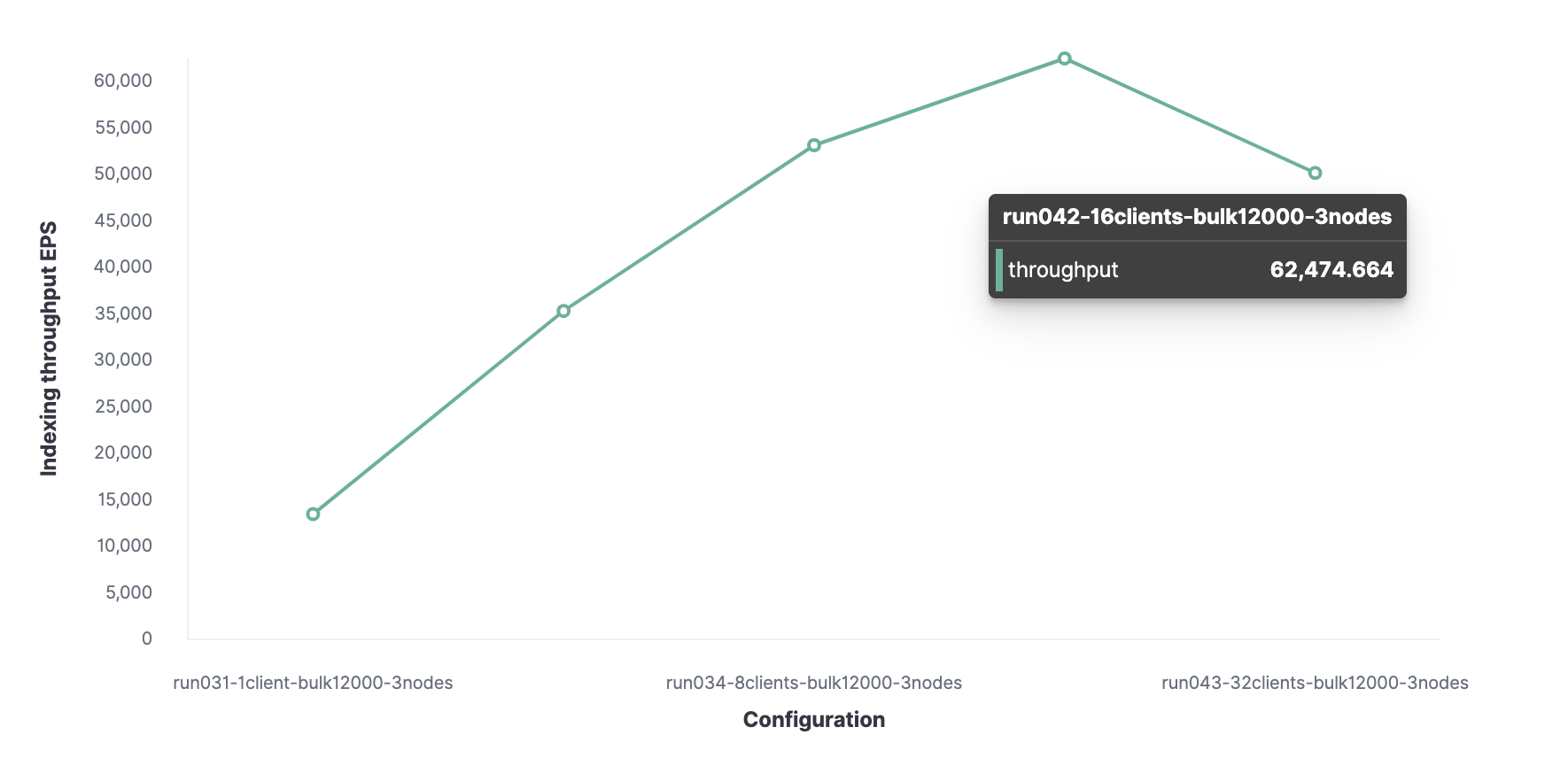
Insgesamt kann der Cluster maximal 62.000 Ereignisse pro Sekunde verarbeiten, ohne die Leistung zu beeinträchtigen. Um diese Anzahl zu erhöhen, müssen Sie einen neuen Knoten hinzufügen.
Unten ist der gleiche Test mit einem Paket von 12.000 Ereignissen, aber zum Vergleich werden die Bandbreitendaten für 1 Knoten, 2 und 3 Knoten angegeben.
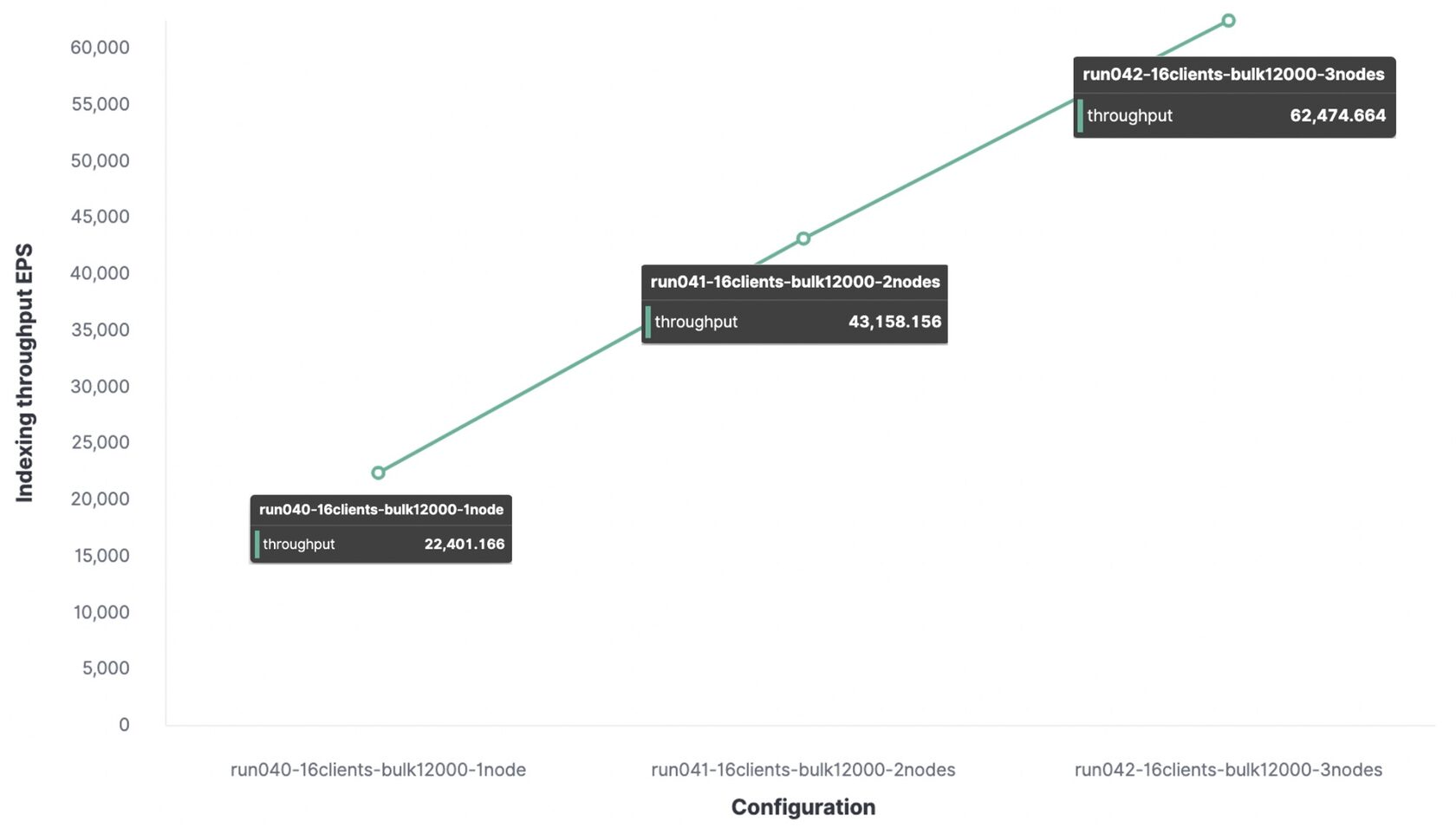
In einer Testumgebung beträgt der maximale Indizierungsdurchsatz:
- Mit 1 Knoten und 1 Shard wurden 22.000 Ereignisse pro Sekunde indiziert.
- Mit 2 Knoten und 2 Shards wurden 43.000 Ereignisse pro Sekunde indiziert.
- Mit 3 Knoten und 3 Shards wurden 62.000 Ereignisse pro Sekunde indiziert.
Jede zusätzliche Indexanforderung wird in die Warteschlange gestellt, und wenn sie voll ist, antwortet der Knoten, indem er die Indexanforderung ablehnt.
Bitte beachten Sie, dass das Dataset die Clusterleistung beeinflusst. Daher ist es wichtig, Rallye-Strecken mit Ihren eigenen Daten auszuführen.
Indizierungstest Nr. 2
Für den nächsten Schritt werden die Protokolldatenspuren des HTTP-Servers mit der folgenden Konfiguration verwendet:
- 247 249 096 Dokumente;
- Datenvolumen: 31,1 GB;
- Durchschnittliche Dokumentgröße: 0,8 KB.
Die optimale Paketgröße beträgt 16.000 Dokumente.
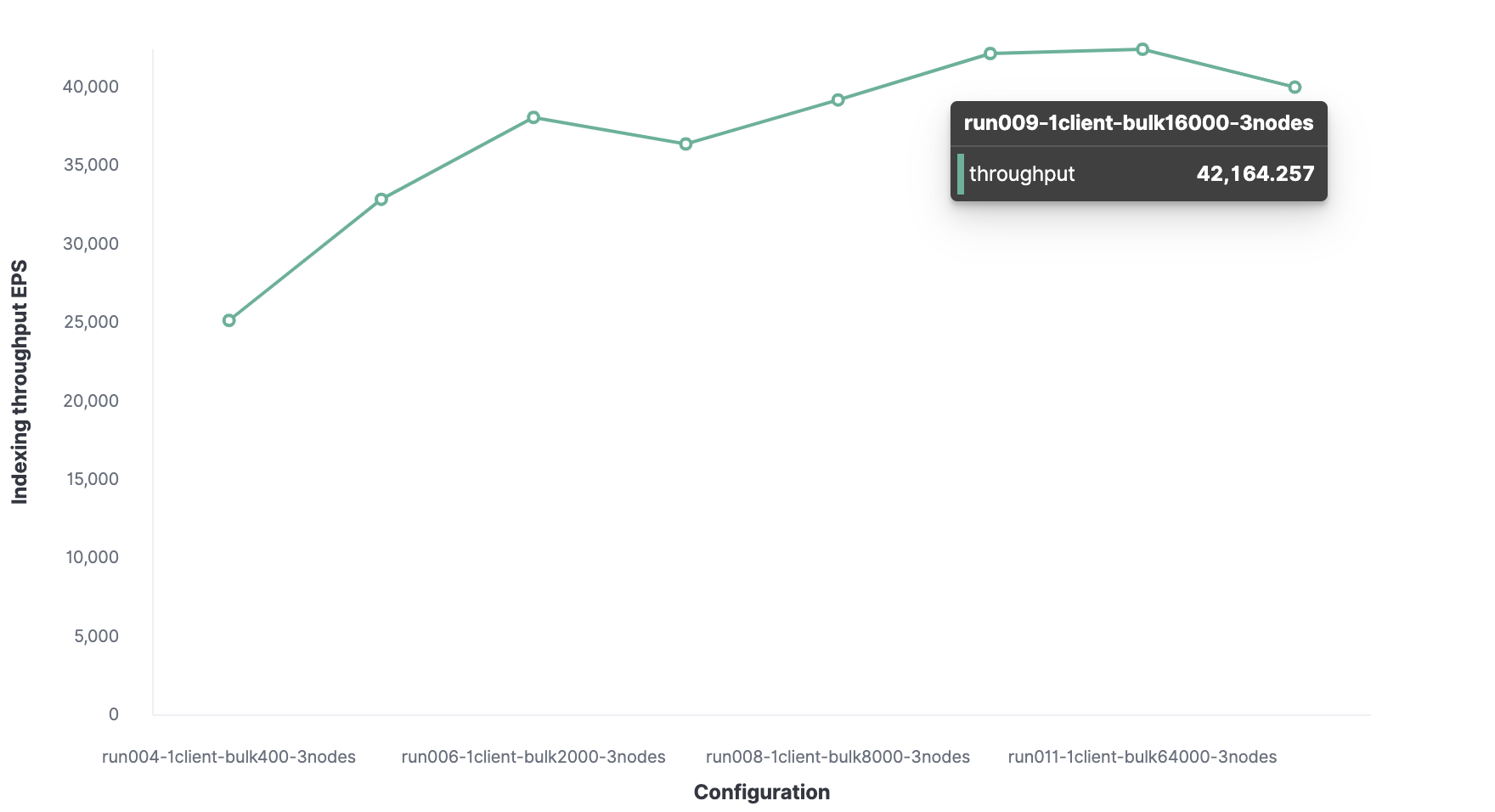
Die optimale Anzahl von Clients beträgt 32.
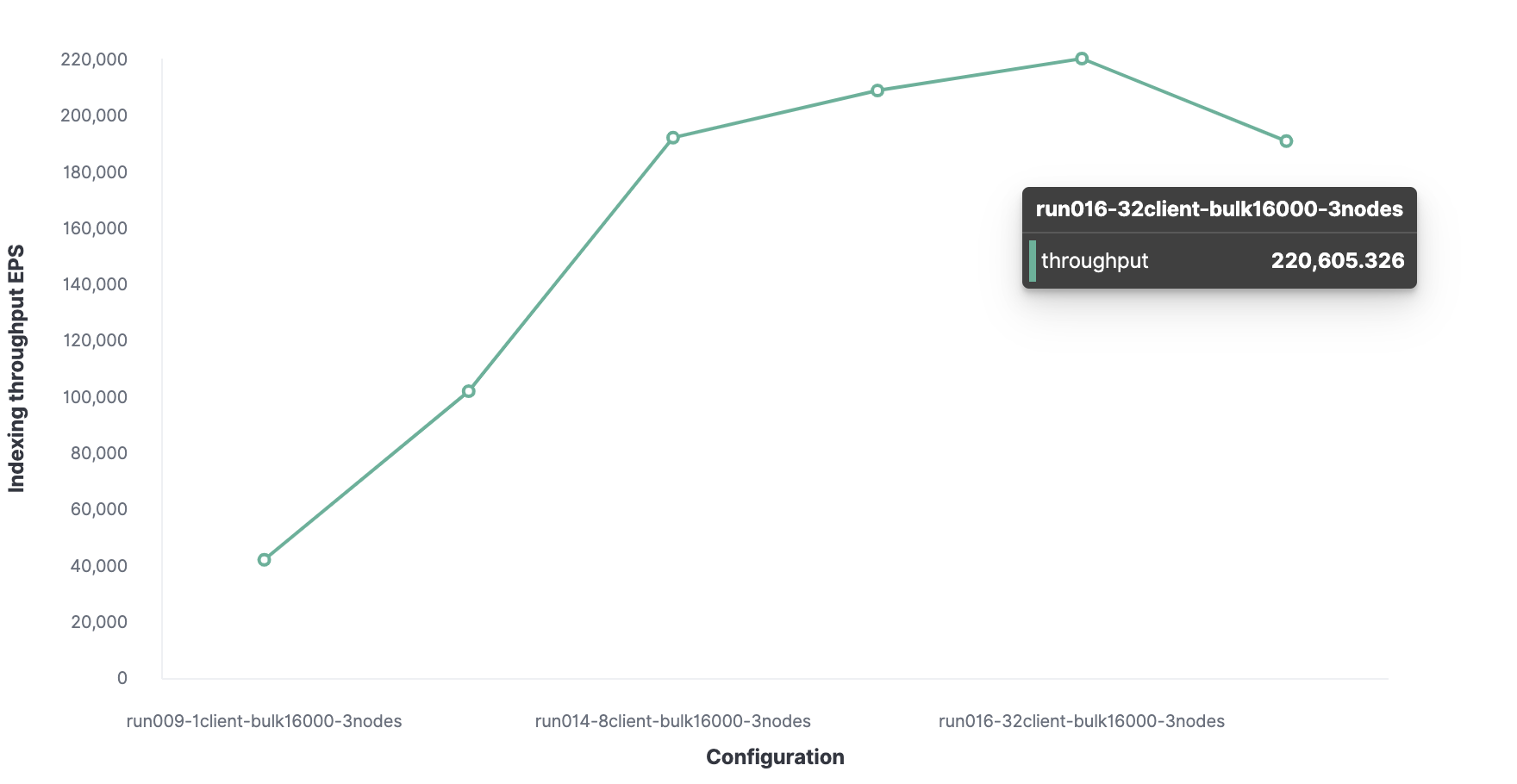
Dementsprechend beträgt der maximale Indizierungsdurchsatz in Elasticsearch 220.000 Ereignisse pro Sekunde.
Suche
Der Suchdurchsatz wird basierend auf 20 Clients und 1000 Vorgängen pro Sekunde geschätzt. Für die Suche werden drei Tests durchgeführt.
Suchtest Nr. 1
Vergleicht die Servicezeit (bzw. das 90. Perzentil) für eine Reihe von Abfragen.
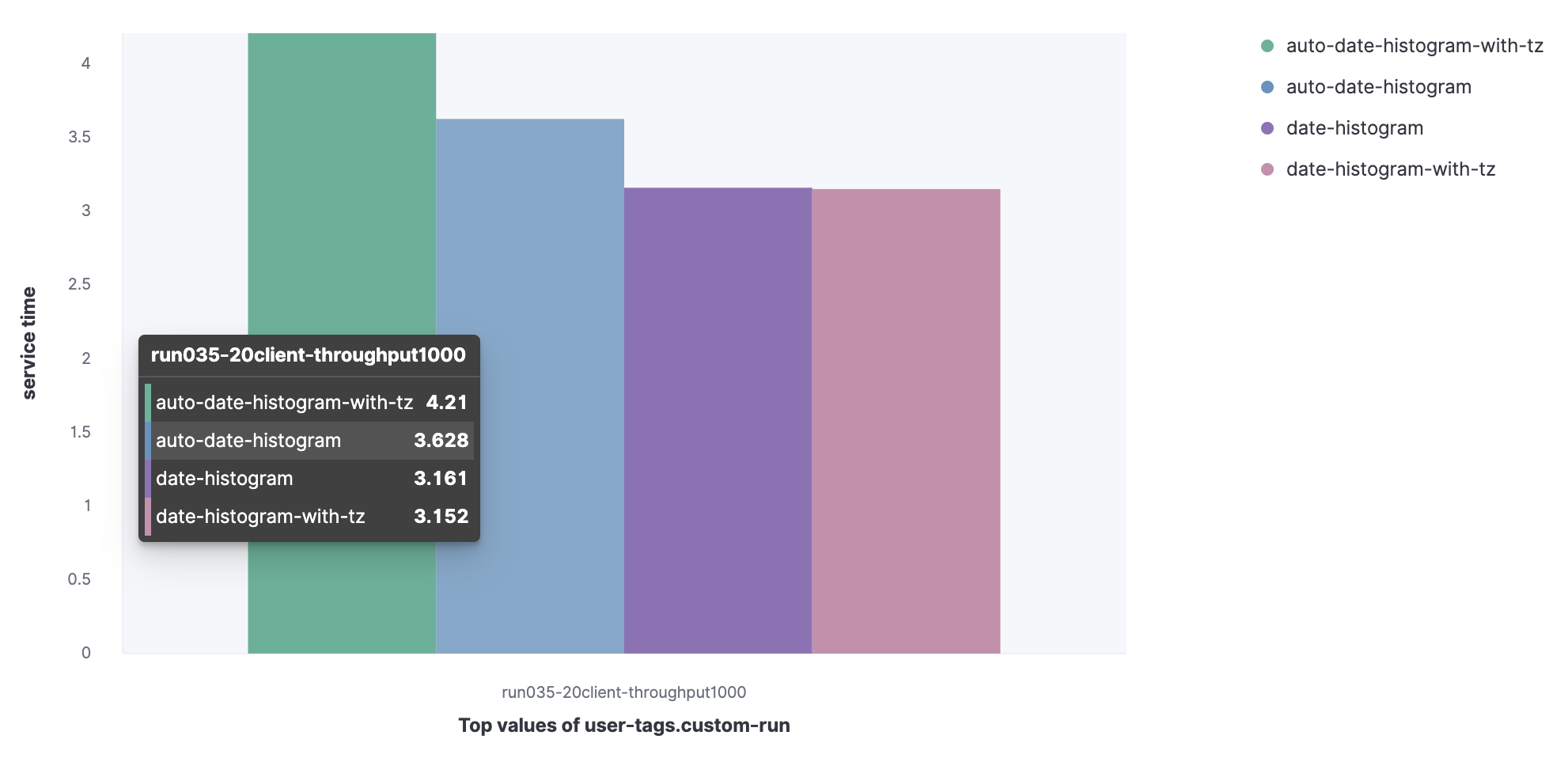
Datensatz von Metricbeat:
- Aggregiertes Datumshistogramm mit automatischem Intervall (Auto-Date-Historgram);
- Aggregiertes Datumshistogramm mit Zeitzone mit automatischem Intervall (automatisches Datumshistogramm mit tz);
- Aggregiertes Datumshistogramm (Datumshistogramm);
- Aggregiertes Datumshistogramm mit Zeitzone (Datumshistogramm mit tz).
Sie können sehen, dass die Anforderung für das automatische Datumshistogramm mit tz die längste Servicezeit im Cluster aufweist.
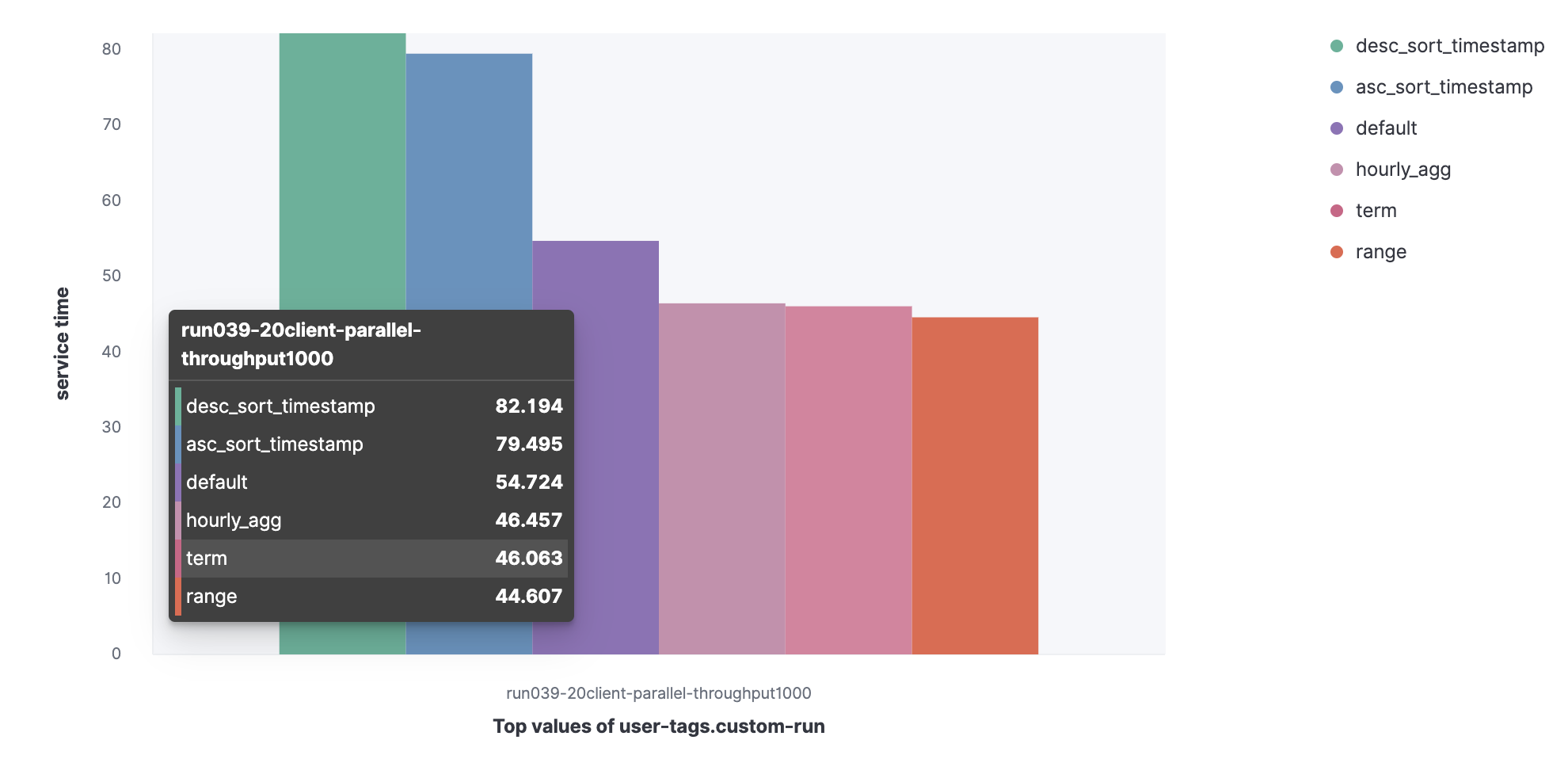
Datensatz aus dem HTTP-Serverprotokoll:
- Standard;
- Begriff;
- Reichweite;
- Hourly_agg;
- Desc_sort_timestamp;
- Asc_sort_timestamp.
Sie können sehen, dass die Anforderungen desc_sort_timestamp und desc_sort_timestamp eine längere Lebensdauer haben.

Suchtest Nr. 2 Schauen
wir uns nun parallele Abfragen an. Mal sehen, wie sich die Servicezeit für das 90. Perzentil erhöht, wenn Abfragen parallel ausgeführt werden. Suchtest
Nr. 3
Berücksichtigen Sie die Indizierungsgeschwindigkeit und die Servicezeit von Suchanfragen bei paralleler Indizierung.
Führen Sie eine parallele Indizierungs- und Suchaufgabe aus, um die Indizierungsgeschwindigkeit und die Abfragedienstzeit anzuzeigen.

Lassen Sie uns sehen, wie sich die Abfragedienstzeit für das 90. Perzentil erhöht hat, wenn Suchvorgänge parallel zu Indizierungsvorgängen durchgeführt werden.

Insgesamt 32 Clients für die Indizierung und 20 Benutzer für die Suche:
- Der Indexdurchsatz beträgt 173.000 Ereignisse pro Sekunde, was weniger als 220.000 entspricht, die in früheren Experimenten erhalten wurden.
- Die Suchbandbreite beträgt 1000 Ereignisse pro Sekunde.
Rally ist ein leistungsstarkes Benchmarking-Tool, das Sie jedoch nur mit Daten verwenden sollten, die in Zukunft auch in die Produktion eingehen werden.
Ein paar Anzeigen:
Wir haben einen Schulungskurs zu den Grundlagen der Arbeit mit Elastic Stack entwickelt , der an die spezifischen Bedürfnisse des Kunden angepasst ist. Detailliertes Schulungsprogramm auf Anfrage.
Wir laden Sie ein, sich für den Elastischen Tag in Russland und die GUS 2021 anzumelden , der am 3. März von 10 bis 13 Uhr online stattfindet.
Lesen Sie unsere anderen Artikel:
- Dimensionierung Elasticsearch
- Wie Elastic Stack-Lizenzen (Elasticsearch) lizenziert und unterschiedlich sind
- Grundlegendes zum maschinellen Lernen im elastischen Stapel (auch bekannt als Elasticsearch, auch bekannt als ELK)
- Elastic under the lock: Aktiviert Sicherheitsoptionen für den Elasticsearch-Cluster für den Zugriff von innen und außen
Wenn Sie an Administrations- und Supportdiensten für Ihre Elasticsearch-Installation interessiert sind, können Sie eine Anfrage im Feedback-Formular auf einer speziellen Seite hinterlassen .
Abonnieren Sie unsere Facebook-Gruppe und unseren Youtube-Kanal .