Unsere heutige Übersetzung handelt von Data Science. Ein Datenanalyst aus Dublin erklärte, er suche nach Wohnraum in einem Markt mit hoher Nachfrage und geringem Angebot.
Ich habe immer diejenigen Fachleute beneidet, die ihre beruflichen Fähigkeiten auf ihr tägliches Leben anwenden können . Nehmen Sie zum Beispiel einen Klempner, Zahnarzt oder Koch: Ihre Fähigkeiten sind nicht nur bei der Arbeit nützlich.
Für den Datenanalysten und Softwareentwickler sind diese Vorteile normalerweise weniger greifbar. Natürlich bin ich technisch versiert, aber bei der Arbeit beschäftige ich mich hauptsächlich mit der Wirtschaft, so dass es schwierig ist, interessante Anwendungsfälle für meine Fähigkeiten zur Lösung familiärer Probleme zu finden.
Als meine Frau und ich beschlossen, ein neues Zuhause in Dublin zu kaufen, sah ich sofort eine Gelegenheit, das Wissen zu nutzen!
Der Inhalt des Artikels:
- Hohe Nachfrage, geringes Angebot
- Auf der Suche nach Daten
- Von der Idee zum Werkzeug
- Grundinformationen
- Verbesserung der Datenqualität
- Google Data Studio
- Einige Implementierungsdetails (und dann weiter zum lustigen Teil)
- Geokodierungsadressen
- Berechnung der Zeit, zu der die Immobilie auf dem Markt ist
- Analyse
- Ergebnisse
- Fazit
Die folgenden Daten wurden nicht gelöscht, sondern mit diesem Skript generiert .
Hohe Nachfrage, geringes Angebot
Um zu verstehen, wie alles begann, können Sie meine persönlichen Erfahrungen mit dem Kauf von Immobilien in Dublin lesen. Ich muss zugeben, dass es nicht einfach war: Der Markt ist sehr gefragt (dank der hervorragenden Wirtschaftsleistung Irlands in den letzten Jahren), und Wohnraum ist extrem teuer. Laut einem Eurostat-Bericht hatte Irland im Jahr 2019 die höchsten Wohnkosten im Vergleich zur EU (77% über dem EU-Durchschnitt).

Was bedeutet dieses Diagramm?
1. Es gibt nur sehr wenige Häuser, die zu unserem Budget passen , und in Gebieten mit hoher Nachfrage gibt es noch weniger (mit mehr oder weniger normaler Verkehrsinfrastruktur).
2. Der Zustand des Sekundärgehäuses ist manchmal sehr schlecht, da es für die Eigentümer nicht rentabel ist, vor dem Verkauf in Reparaturen zu investieren. Häuser zum Verkauf haben oft niedrige Energieeffizienzklassen, schlechte Sanitär- und Elektrogeräte, was bedeutet, dass Käufer die Renovierungskosten zu einem bereits hohen Preis hinzufügen müssen.
3. Der Verkauf basiert auf einem Auktionssystem und in den meisten Fällen übersteigen die Gebote der Käufer den Startpreis. Soweit ich verstanden habe, gilt dies nicht für Neubauten, die jedoch erheblich über unserem Budget lagen. Daher haben wir dieses Segment überhaupt nicht berücksichtigt.
Ich denke, dass viele Menschen auf der ganzen Welt mit dieser Situation vertraut sind, da die Dinge in Großstädten höchstwahrscheinlich gleich sind.
Wie alle anderen bei unserer Immobiliensuche wollten wir das perfekte Zuhause in der perfekten Gegend zu einem erschwinglichen Preis finden. Mal sehen, wie uns die Datenanalyse dabei geholfen hat!
Auf der Suche nach Daten
In jedem Data Science-Projekt gibt es eine Datenerfassungsphase, und für diesen speziellen Fall habe ich nach einer Quelle gesucht, die Informationen zu allen auf dem Markt verfügbaren Wohnungen enthält. In Irland gibt es zwei Arten von Websites:
- Websites von Immobilienagenturen,
- Aggregatoren.
Beide Optionen sind sehr nützlich und erleichtern Verkäufern und Käufern das Leben erheblich. Leider bieten die Benutzeroberfläche und die vorgeschlagenen Filter nicht immer die effizienteste Möglichkeit, die erforderlichen Informationen zu extrahieren und verschiedene Eigenschaften zu vergleichen. Hier sind einige Fragen, die mit Suchmaschinen wie Google schwer zu beantworten sind:
1. Wie lange dauert es, bis Sie zur Arbeit kommen?
2. Wie viele Immobilien gibt es in dem einen oder anderen Gebiet? Es ist möglich, Stadtteile auf klassischen Websites zu vergleichen, diese erstrecken sich jedoch normalerweise über mehrere Quadratkilometer. Dies ist nicht detailliert genug, um beispielsweise zu verstehen, dass ein zu hoher Satz in einer bestimmten Straße auf einen Trick hinweist. Die meisten spezialisierten Websites haben Karten, aber sie sind nicht so informativ, wie wir es gerne hätten.
3. Welche Einrichtungen gibt es in der Nähe des Hauses?
4. Was ist der durchschnittliche Angebotspreis für eine Gruppe von Immobilien?
5. Wie lange ist die Immobilie schon im Verkauf? Selbst wenn diese Informationen verfügbar sind, sind sie nicht immer zuverlässig, da der Makler die Anzeige löschen und erneut platzieren könnte.
Die Neugestaltung der Benutzeroberfläche für die Benutzerfreundlichkeit und die Verbesserung der Datenqualität erleichterte die Suche nach einem Zuhause erheblich und ermöglichte es uns, einige sehr interessante Erkenntnisse zu gewinnen.
Von der Idee zum Werkzeug
Grundinformationen
Der erste Schritt bestand darin, einen Schaber zu schreiben, um grundlegende Informationen zu sammeln:
- Rohadresse der Immobilie,
- aktueller Verkäuferpreis,
- Link zu der Seite mit der Eigenschaft,
- Grundlegende Merkmale wie Anzahl der Zimmer, Anzahl der Badezimmer, Energieeffizienzklasse,
- Anzahl der Anzeigenansichten (falls verfügbar),
- Art der Immobilie (Haus, Wohnung, Neubau).
Dies sind in der Tat alle Daten, die ich im Internet finden konnte. Für eine tiefere Analyse musste ich diesen Datensatz verbessern.
Verbesserung der Datenqualität
Bei der Auswahl eines Hauses ist mein Hauptargument für den Kauf ein bequemer Weg zur Arbeit. Für mich sind es nicht mehr als 50 Minuten für die gesamte Reise von Tür zu Tür. Für diese Berechnungen habe ich mich für die Google Cloud-Plattform entschieden:
1. Mit der Geokodierungs-API habe ich die Breiten- und Längengradkoordinaten anhand der Adresse der Eigenschaft ermittelt.
2. Mit der Directions-API habe ich die Zeit berechnet, die erforderlich ist, um von zu Hause zur Arbeit zu Fuß und mit öffentlichen Verkehrsmitteln zu gelangen. Hinweis: Radfahren ist etwa dreimal schneller als Gehen.
3. Verwenden von API-Sitzen (Places API)Ich habe Informationen über die Annehmlichkeiten rund um jede Unterkunft erhalten. Insbesondere interessierten wir uns für Apotheken, Supermärkte und Restaurants. Hinweis: Die Places-APIs sind sehr teuer: Bei einer Datenbank mit 4.000 Eigenschaften müssten Sie 12.000 Abfragen ausführen, um Informationen zu drei Arten von Annehmlichkeiten zu erhalten. Daher habe ich diese Daten aus dem endgültigen Dashboard ausgeschlossen.
Neben der geografischen Lage interessierte mich eine weitere Frage: Wie lange ist die Immobilie schon auf dem Markt? Wenn die Immobilie nicht zu lange verkauft wurde, ist dies ein Weckruf: Vielleicht stimmt etwas mit der Gegend oder dem Haus selbst nicht, oder der Preis ist zu hoch.
Umgekehrt ist zu beachten, dass die Eigentümer dem ersten erhaltenen Angebot nicht zustimmen, wenn die Immobilie gerade zum Verkauf angeboten wurde. Leider sind diese Informationen ziemlich leicht zu verbergen. Mithilfe des grundlegenden maschinellen Lernens habe ich diesen Aspekt anhand der Anzahl der Anzeigenansichten und einiger anderer Metriken geschätzt.
Schließlich habe ich den Datensatz mit einigen Servicefeldern verbessert, um das Filtern zu vereinfachen (z. B. durch Hinzufügen einer Spalte mit einer Preisspanne).
Google Data Studio
Mit einem verbesserten Datensatz, der für mich in Ordnung war, wollte ich ein leistungsstarkes Dashboard erstellen . Ich habe Google Data Studio als Datenvisualisierungstool für diese Aufgabe ausgewählt. Dieser Dienst hat einige Nachteile (seine Funktionen sind sehr, sehr begrenzt), aber es gibt auch Vorteile: Er ist kostenlos, hat eine Webversion und kann Daten aus Google Sheets lesen. Unten sehen Sie ein Diagramm, das den gesamten Workflow beschreibt.

Einige Implementierungsdetails
Um ehrlich zu sein, war die Implementierung ziemlich unkompliziert und es gibt hier nichts Neues oder Besonderes: nur eine Reihe von Skripten zum Sammeln von Daten und einige grundlegende Pandas-Transformationen. Es sei jedoch darauf hingewiesen, dass die Interaktion mit der Google-API und die Berechnung der Zeit, in der die Immobilie auf dem Markt war, zu beachten sind.
Die folgenden Daten wurden nicht gelöscht, sondern mit diesem Skript generiert .
Werfen wir einen Blick auf die Rohdaten.
Wie erwartet enthält die Datei die folgenden Spalten:
id
: Anzeigen-ID._address
: Adresse der Immobilie._d_code
: . D<>. <> , (, ), — ._link
: , ._price
: .type
: (, , )._bedrooms
: ()._bathrooms
: ._ber_code
: , : «», ._views
: ( )._latest_update
: ( ).days_listed
: — , ,_last_update
.
Es geht darum, all dies auf die Karte zu bringen und die Leistung geolokalisierter Daten zu nutzen. Schauen wir uns dazu an, wie Sie mithilfe der Google-API Längen- und Breitengrade ermitteln.
Dazu benötigen Sie ein Konto bei Google Cloud Platform. Anschließend können Sie dem Lernprogramm unter dem Link folgen, um einen API-Schlüssel abzurufen und die entsprechende API zu aktivieren. Wie ich bereits geschrieben habe, habe ich für dieses Projekt die Geokodierungs-API, die Richtungs-API und die Orts-API verwendet (daher müssen Sie diese spezifischen APIs beim Erstellen des API-Schlüssels aktivieren). Unten finden Sie ein Code-Snippet für die Interaktion mit Google Cloud Platform.
# The Google Maps library
import googlemaps
# Date time for easy computations between dates
from datetime import datetime
# JSON handling
import json
# Pandas
import pandas as pd
# Regular expressions
import re
# TQDM for fancy loading bars
from tqdm import tqdm
import time
import random
# !!! Define the main access point to the Google APIs.
# !!! This object will contain all the functions needed
geolocator = googlemaps.Client(key="<YOUR API KEY>")
WORK_LAT_LNG = (<LATITUDE>, <LONGITUDE>)
# You can set this parameter to decide the time from which
# Google needs to calculate the directions
# Different times affect public transport
DEPARTURE_TIME = datetime.now
# Load the source data
data = pd.read_csv("/path/to/raw/data/data.csv")
# Define the columns that we want in the geocoded dataframe
geo_columns = [
"_link",
"lat",
"lng",
"_time_to_work_seconds_transit",
"_time_to_work_seconds_walking"
]
# Create an array where we'll store the geocoded data
geo_data = []
# For each element of the raw dataframe, start the geocoding
for index,
in tqdm(data.iterrows()):
# Google Geo coding
_location = ""
_location_json = ""
try:
# Try to retrieve the base location,
# i.e. the Latitude and Longitude given the address
_location = geolocator.geocode(row._address)
_location_json = json.dumps(_location[0])
except:
pass
_time_to_work_seconds_transit = 0
_directions_json = ""
_lat_lon = {"lat": 0, "lng": 0}
try:
# Given the work latitude and longitude, plus the property latitude and longitude,
# retrieve the distance with PUBLIC TRANSPORT (`mode=transit`)
_lat_lon = _location[0]["geometry"]["location"]
_directions = geolocator.directions(WORK_LAT_LNG,
(_lat_lon["lat"], _lat_lon["lng"]), mode="transit")
_time_to_work_seconds_transit = _directions[0]["legs"][0]["duration"]["value"]
_directions_json = json.dumps(_directions[0])
except:
pass
_time_to_work_seconds_walking = 0
try:
# Given the work latitude and longitude, plus the property latitude and longitude,
# retrieve the WALKING distance (`mode=walking`)
_lat_lon = _location[0]["geometry"]["location"]
_directions = geolocator.directions(WORK_LAT_LNG, (_lat_lon["lat"], _lat_lon["lng"]), mode="walking")
_time_to_work_seconds_walking = _directions[0]["legs"][0]["duration"]["value"]
except:
pass
# This block retrieves the number of SUPERMARKETS arount the property
'''
_supermarket_nr = 0
_supermarket = ""
try:
# _supermarket = geolocator.places_nearby((_lat_lon["lat"],_lat_lon["lng"]), radius=750, type="supermarket")
_supermarket_nr = len(_supermarket["results"])
except:
pass
'''
# This block retrieves the number of PHARMACIES arount the property
'''
_pharmacy_nr = 0
_pharmacy = ""
try:
# _pharmacy = geolocator.places_nearby((_lat_lon["lat"],_lat_lon["lng"]), radius=750, type="pharmacy")
_pharmacy_nr = len(_pharmacy["results"])
except:
pass
'''
# This block retrieves the number of RESTAURANTS arount the property
'''
_restaurant_nr = 0
_restaurant = ""
try:
# _restaurant = geolocator.places_nearby((_lat_lon["lat"],_lat_lon["lng"]), radius=750, type="restaurant")
_restaurant_nr = len(_restaurant["results"])
except:
pass
'''
geo_data.append([row._link, _lat_lon["lat"], _lat_lon["lng"], _time_to_work_seconds_transit,
_time_to_work_seconds_walking])
geo_data_df = pd.DataFrame(geo_data)
geo_data_df.columns = geo_columns
geo_data_df.to_csv("geo_data_houses.csv", index=False)
Berechnung der Zeit, zu der die Immobilie auf dem Markt ist
Schauen wir uns die Daten genauer an :
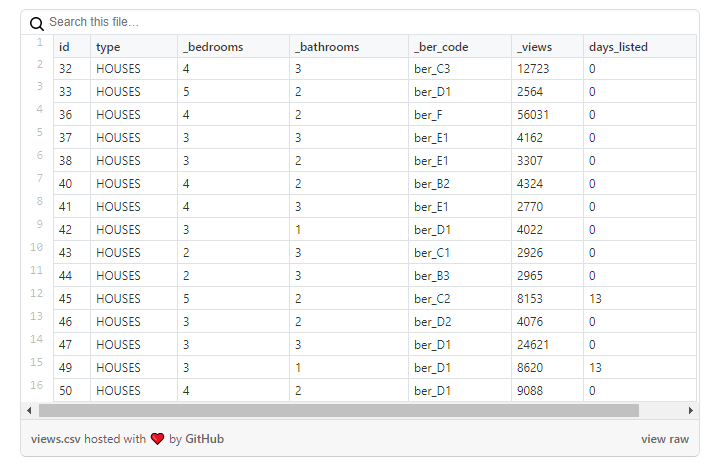
Wie Sie in diesem Beispiel sehen können, spiegelt sich die Anzahl der Ansichten von Immobilien nicht in der Anzahl der Tage wider, an denen die Anzeige aktiv war: Beispielsweise hat ein Haus mit der ID = 47 ~ 25 tausend Aufrufe, aber es erschien an diesem Tag, als ich Daten lud.
Dieses Problem ist jedoch nicht für alle Eigenschaften gleich. Im folgenden Beispiel ist die Anzahl der Aufrufe vergleichbarer mit der Anzahl der Tage, an denen die Anzeige aktiv war:

Wie können wir die obigen Informationen verwenden? Leicht! Wir können den zweiten Datensatz als Trainingssatz für das Modell verwenden, den wir dann auf den ersten Datensatz anwenden können.
Ich habe zwei Ansätze getestet:
1. Nehmen Sie einen "vergleichbaren" Datensatz und berechnen Sie die durchschnittliche Anzahl der Ansichten pro Tag. Wenden Sie diesen Wert dann auf den ersten Datensatz an. Dieser Ansatz ist nicht ohne gesunden Menschenverstand, hat jedoch das folgende Problem: Alle Immobilien werden zu einer Gruppe zusammengefasst, und es ist wahrscheinlich, dass eine Anzeige für den Verkauf eines Hauses im Wert von 10 Millionen Euro weniger Aufrufe pro Tag erhält, da eine solche Das Budget steht einer engen Gruppe von Personen zur Verfügung.
2. Trainieren Sie das Random Forest-Modell für den zweiten Datensatz und wenden Sie es dann auf den ersten Datensatz an.
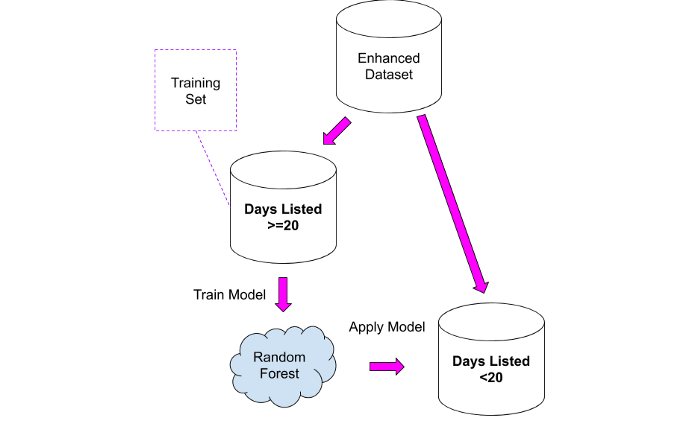
Die Ergebnisse sollten sehr sorgfältig betrachtet werden, wobei zu berücksichtigen ist, dass die neue Spalte nur ungefähre Werte enthält: Ich habe sie als Ausgangspunkt verwendet, um Eigenschaften, bei denen etwas seltsam erschien, genauer zu analysieren.
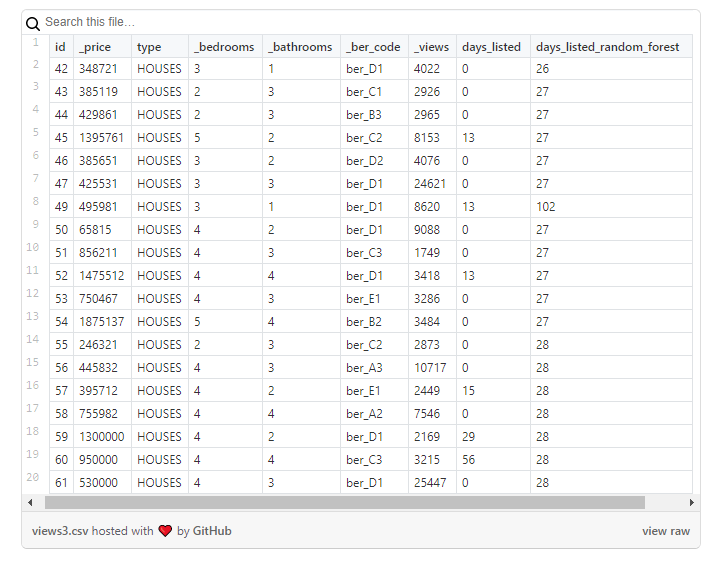
Analyse
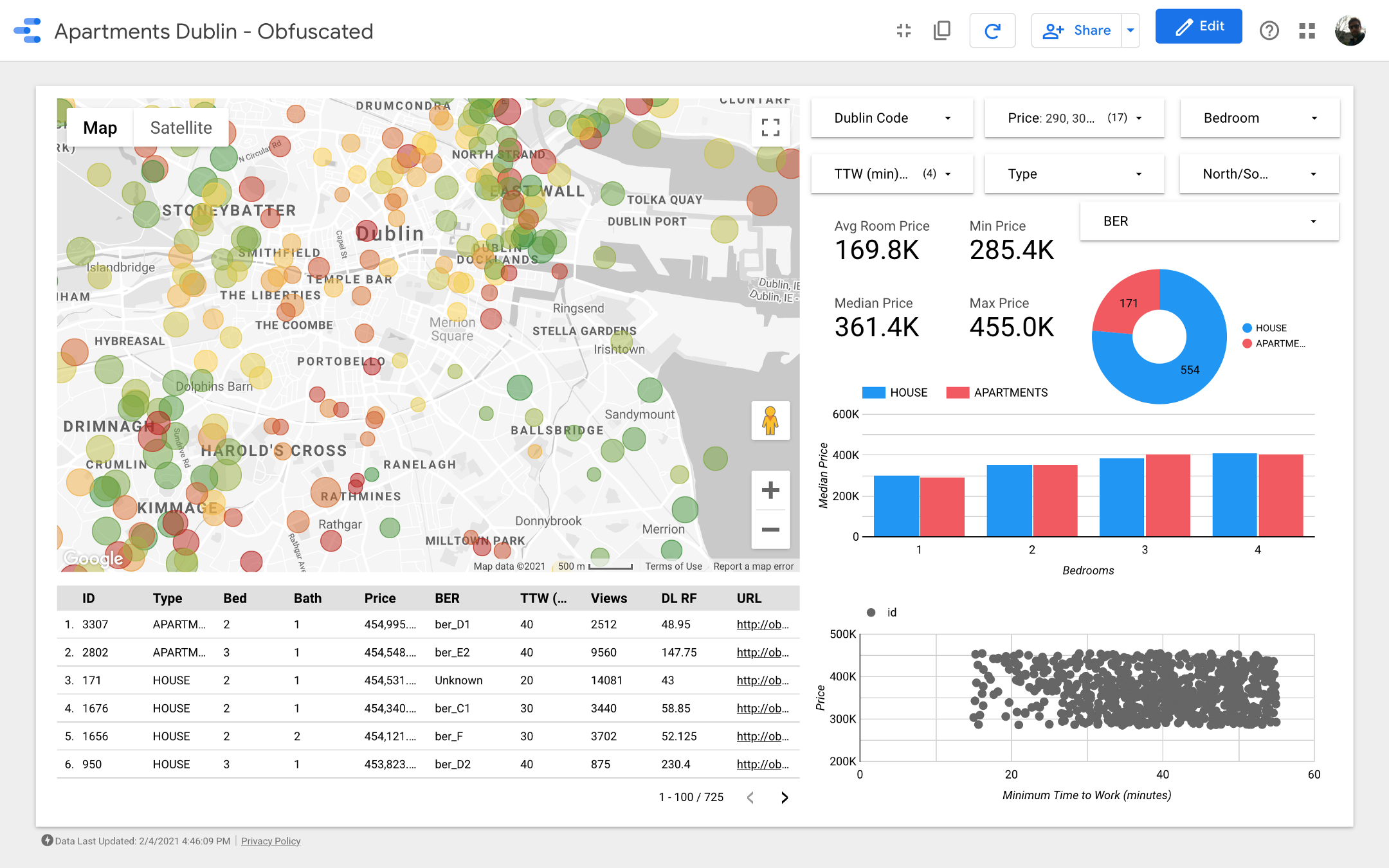
Meine Damen und Herren, ich präsentiere Ihnen das letzte Dashboard . Wenn Sie sich damit beschäftigen möchten, folgen Sie dem Link .
Hinweis: Leider funktioniert das Google Maps-Modul nicht, wenn es in einen Artikel eingebettet ist. Daher musste ich Screenshots verwenden.
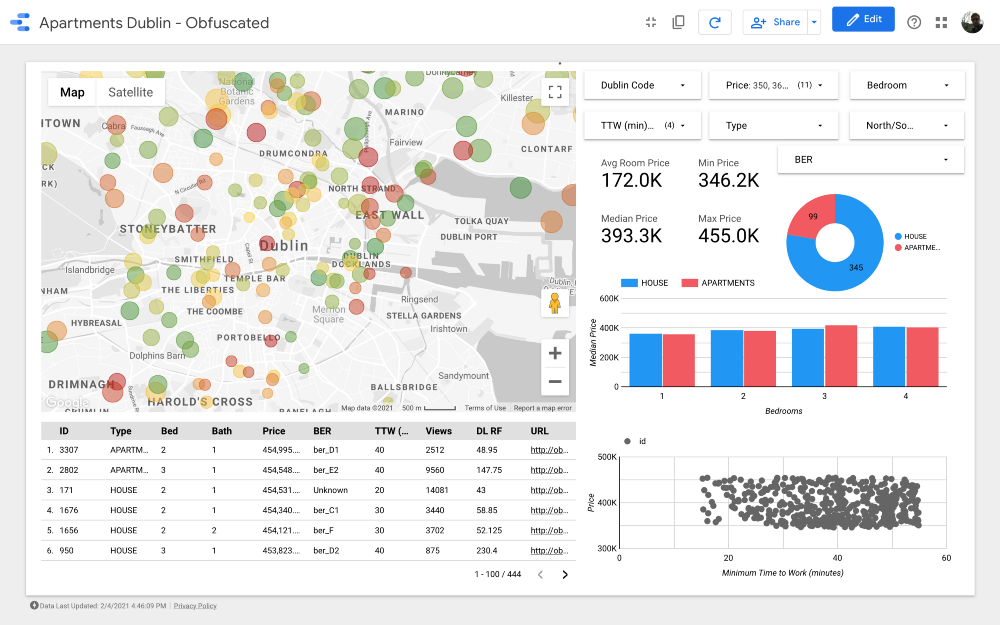
https://datastudio.google.com/s/qKDxt8i2ezE Die
Karte ist der wichtigste Teil des Dashboards. Die Farbe der Blasen hängt vom Preis des Hauses / der Wohnung ab, und die Färbung berücksichtigt nur die verfügbaren Eigenschaften (entsprechend den Filtereinstellungen in der oberen rechten Ecke). Die Größe der Blasen gibt die Entfernung zur Arbeit an: Je kleiner sie ist, desto kürzer ist die Straße.
In Diagrammen können Sie analysieren, wie sich der Angebotspreis in Abhängigkeit von bestimmten Merkmalen (z. B. der Art des Gebäudes oder der Anzahl der Räume) ändert, und das Streudiagramm vergleicht die Entfernung zur Arbeit und den Angebotspreis.
Schließlich die Rohdatentabelle (
DL RF
steht für Days Listed Random Forest und zeigt die Anzahl der Tage an, an denen die Anzeige aktiv war, das Random Forest-Modell).
Ergebnisse
Lassen Sie uns in die Analyse eintauchen und sehen, welche Schlussfolgerungen wir aus dem Dashboard ziehen können.
Der Datensatz enthält ungefähr 4.000 Häuser und Wohnungen: Natürlich können wir nicht alle anzeigen. Daher besteht unsere Aufgabe darin , eine Teilmenge von Datensätzen zu identifizieren, die eine oder mehrere Immobilien enthalten, die wir kaufen möchten.
Zunächst müssen wir die Suchkriterien klären. Angenommen, wir suchen nach einer Immobilie, die die folgenden Merkmale erfüllt:
1. Art der Immobilie: Haus.
2. Anzahl der Zimmer (Schlafzimmer): 3.
3. Entfernung zur Arbeit: weniger als 60 Minuten.
4. Energieeffizienzklasse: A, B, C oder D.
5. Preis: von 250 bis 540 Tausend Euro.
Wenden wir alle Filter außer dem Preis an und schauen wir uns die Karte an (filtern Sie nur diejenigen heraus, die teurer als 1 Million und weniger als 200 Tausend Euro sind).
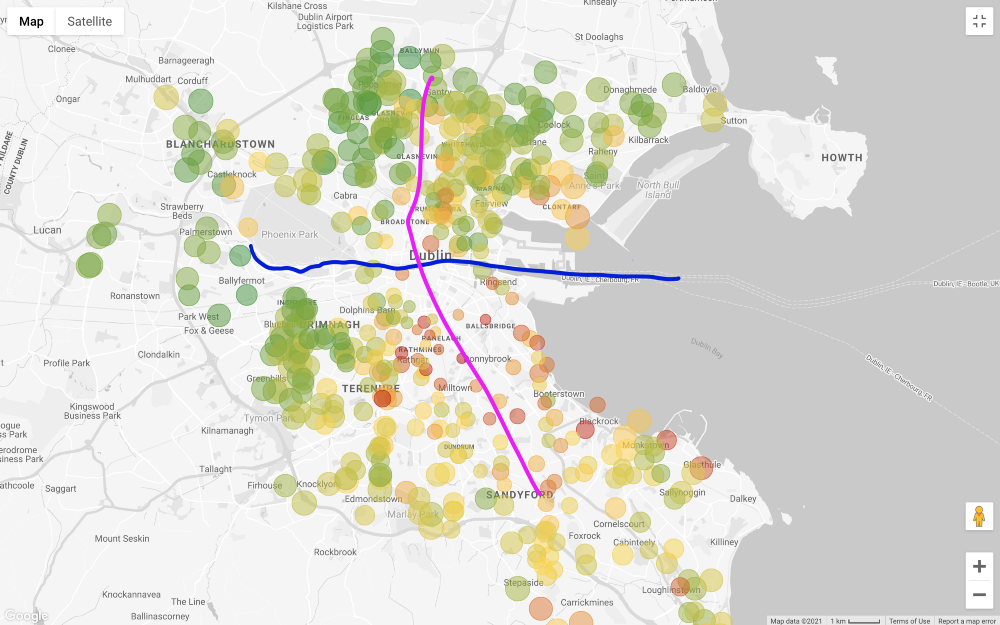
Im Allgemeinen ist der Preis für Immobilien im Süden von Liffey viel höher als im Norden, mit wenigen Ausnahmen im Südwesten der Stadt. Sogar die "äußeren Gebiete" im Norden, dh im Nordosten und Nordwesten, scheinen billiger zu sein als im Norden des Stadtzentrums. Ein Grund für diese Preisgestaltung ist, dass die Hauptstraßenbahnlinie (LUAS) von Dublin die Stadt in einer geraden Linie von Nord nach Süd durchquert (es gibt eine andere Linie, die von West nach Ost verläuft, aber nicht durch alle Geschäftsviertel führt).
Bitte beachten Sie, dass ich diese Überlegungen nur auf der Grundlage einer Sichtprüfung mache. Für einen gründlicheren Ansatz muss die Korrelation zwischen dem Preis eines Hauses und seiner Entfernung zu öffentlichen Verkehrsmitteln getestet werden. Wir sind jedoch nicht daran interessiert, diesen Zusammenhang nachzuweisen.
Die Situation wird noch interessanter, wenn Sie die Filterpreise in Übereinstimmung mit unserem Budget einstellen (vergessen Sie nicht, dass auf der Karte oben das Haus mit 3 Schlafzimmern angezeigt wird und Sie in weniger als 60 Minuten zur Arbeit kommen und auf der Karte unten hinzugefügt nur nach Preis filtern):
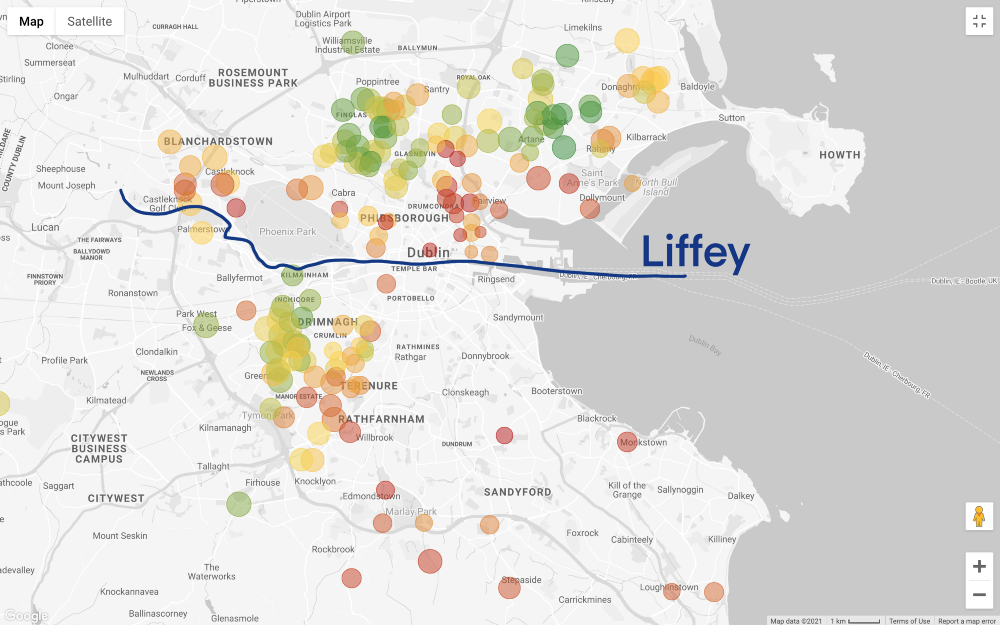
Machen Sie einen Schritt zurück. Wir haben eine allgemeine Vorstellung von den Bereichen, die wir uns leisten können, aber jetzt liegt das Schwierigste vor uns - die Suche nach Kompromissen! Wollen wir eine Budgetoption finden? Oder betrachten wir das beste Haus, das unsere hart verdienten Ersparnisse kaufen können? Leider kann die Datenanalyse diese Fragen nicht beantworten. Dies ist eine geschäftliche (und sehr persönliche) Entscheidung.
Angenommen, wir haben die zweite Option gewählt: Wir priorisieren die Qualität des Hauses oder der Fläche gegenüber dem niedrigeren Preis.
In diesem Fall müssen wir die folgenden Optionen in Betracht ziehen:
1. Gebiete mit einer geringen Konzentration von Vorschlägen - Ein isoliertes Haus auf der Karte weist möglicherweise darauf hin, dass es in der Gegend nicht viele Angebote gibt, was bedeutet, dass die Eigentümer es nicht eilig haben trenne dich von ihrem Zuhause in einer so guten Gegend ...
2. Ein Haus in einer Ansammlung teurer Immobilien - Wenn alle anderen Immobilien in der Nähe eines bestimmten Hauses teuer sind, kann dies bedeuten, dass das Gebiet sehr gefragt ist. Dies ist nur eine zusätzliche Anmerkung, aber wir könnten dieses Phänomen mithilfe der räumlichen Autokorrelation quantifizieren (z. B. durch Berechnung von Morans I ).
Auch wenn die erste Option attraktiv erscheint, sollte berücksichtigt werden, dass der im Vergleich zu anderen Angeboten in der gleichen Gegend sehr niedrige Immobilienpreis einen Haken im Haus selbst bedeuten kann (z. B. kleine Zimmer oder sehr hohe Renovierungskosten) ). Aus diesem Grund werden wir unsere Analyse fortsetzen und uns auf die zweite Option konzentrieren, die meiner Meinung nach angesichts unseres Ziels die vielversprechendste ist.
Schauen wir uns die Vorschläge in diesem Bereich genauer an:

Wir haben unsere Optionen bereits von 4.000 auf weniger als 200 reduziert, und jetzt müssen wir die Punkte besser aufteilen und die Cluster vergleichen.
Die Automatisierung der Clustersuche wird dieser Analyse nicht viel hinzufügen, aber wir wenden den DBSCAN- Algorithmus trotzdem an.... Wir verwenden DBSCAN, da einige der Gruppen möglicherweise nicht globular sind (z. B. funktioniert k-means in dieser Datenbank nicht ordnungsgemäß). Theoretisch müssen wir die geografische Entfernung zwischen den Punkten berechnen, aber wir werden das euklidische System verwenden, da es eine gute Annäherung gibt:
import pandas as pd
from sklearn.cluster import DBSCAN
data = pd.read_csv("data.csv")
data["labels"] = DBSCAN(eps=0.01, min_samples=3).fit(data[["lat","lng"]].values).labels_
print(data["labels"].unique())
data.to_csv("out.csv")

Der Algorithmus zeigte ein ziemlich gutes Ergebnis, aber ich würde die Cluster wie folgt überarbeiten (unter Berücksichtigung des Wissens über die Geschäftsviertel von Dublin):

Wir lehnen Gebiete mit niedrigeren Preisen ab, da wir der maximalen Wohnqualität und einer bequemen Arbeitsstraße Priorität einräumen Unser Budget, sodass die Cluster 2, 3, 4, 6 und 9 ausgeschlossen werden können. Beachten Sie, dass sich die Cluster 2, 3 und 4 in einigen der budgetfreundlichsten Gebiete im Norden Dublins befinden (wahrscheinlich aufgrund einer weniger entwickelten öffentlichen Verkehrsinfrastruktur). Cluster 11 bietet teure Optionen, die weit von der Arbeit entfernt sind, sodass wir sie auch ausschließen können.
Mit Blick auf die teureren Cluster ist Nummer 7 eine der besten in Bezug auf die Entfernung zur Arbeit. Das Drumcondra , eine wunderschöne Wohngegend im Norden von Dublin; Trotz der Tatsache, dass es relativ zur Straßenbahnlinie nicht sehr günstig gelegen ist, fahren Buslinien entlang; In Cluster 8 sind die Immobilienpreise und die Entfernung zur Arbeit dieselben wie in Drumkondra. Ein weiterer Cluster, der analysiert werden sollte, ist Nummer 10: Er scheint sich in einem Gebiet mit geringerem Angebot zu befinden, was bedeutet, dass die Menschen hier wahrscheinlich selten Wohnungen verkaufen, und das Gebiet ist auch für öffentliche Verkehrswege recht günstig gelegen. Verkehr (vorausgesetzt, alle Gebiete haben das gleiche Bevölkerungsdichte).
Schließlich die Cluster 1 und 5 neben dem Phoenix Park, dem größten eingezäunten öffentlichen Park .
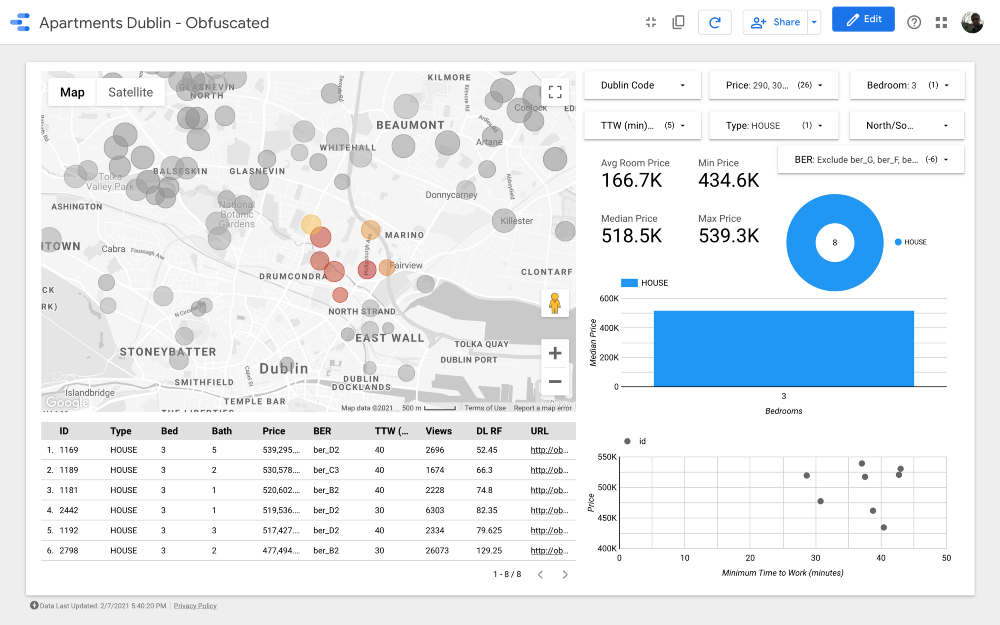
Cluster 7

Cluster 8
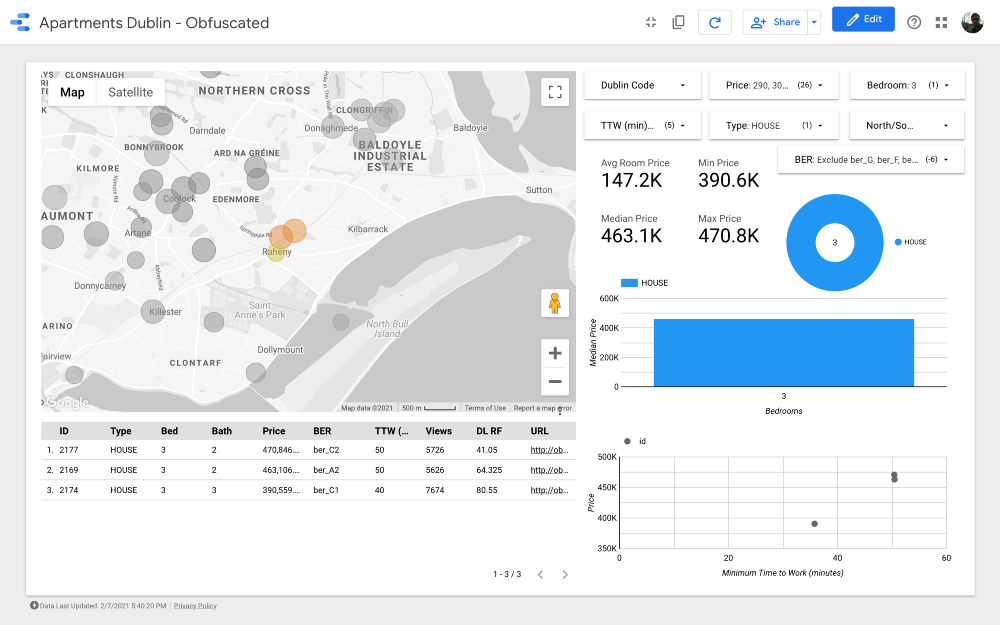
Cluster 10
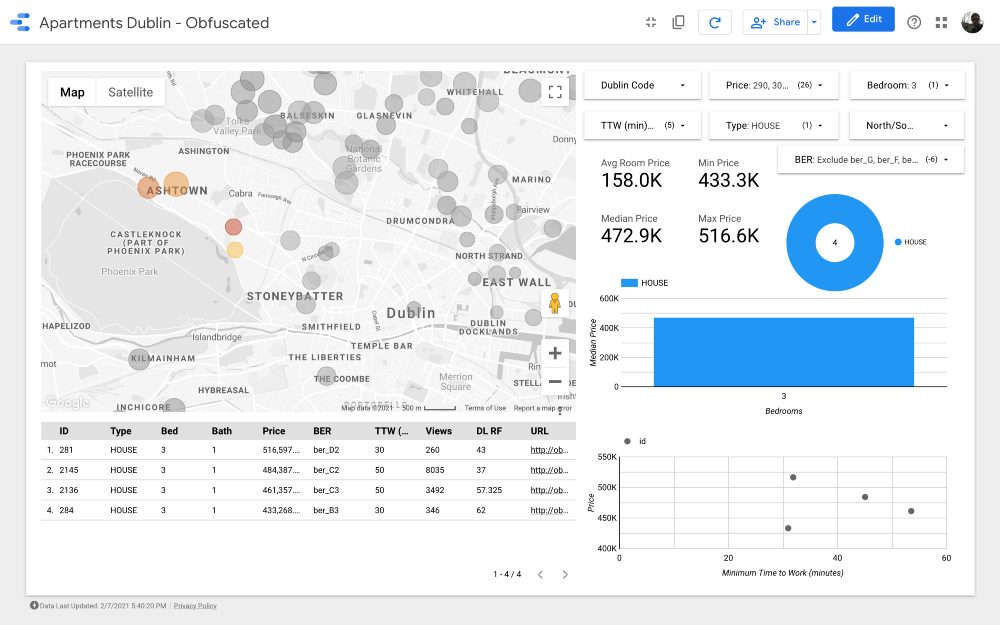
Cluster 1

Cluster 5
Großartig! Wir haben 26 sehenswerte Immobilien gefunden. Jetzt können wir jedes Angebot sorgfältig analysieren und letztendlich eine Besichtigung mit einem Makler vereinbaren!
Fazit
Wir begannen unsere Suche, wussten praktisch nichts über Dublin und bekamen am Ende ein gutes Verständnis dafür, welche Bereiche der Stadt beim Kauf eines Hauses besonders gefragt sind.
Beachten Sie, wir haben uns nicht einmal die Bilder dieser Häuser angesehen und nichts darüber gelesen! Allein durch das Betrachten eines gut organisierten Dashboards kamen wir zu einigen nützlichen Schlussfolgerungen, zu denen wir am Anfang nicht hätten kommen können!
Diese Daten sind nicht mehr nützlich, und einige Integrationen können durchgeführt werden, um die Analyse zu verbessern. Einige Gedanken:
1. Wir haben den Ausstattungsdatensatz (den wir mit der Places-API zusammengestellt haben) nicht in die Studie integriert. Mit einem größeren Budget für Cloud-Services können wir diese Informationen problemlos zum Dashboard hinzufügen.
2. In Irland werden viele interessante Daten auf der Website des statistischen Amtes veröffentlicht : So finden Sie beispielsweise Informationen zur Anzahl der Anrufe bei jeder Polizeistation nach Quartal und Art der Straftat. So konnten wir herausfinden, in welchen Bereichen am meisten gestohlen wird. Da es möglich ist, Volkszählungsdaten für jedes Wahllokal zu erhalten, könnten wir auch die Kriminalitätsrate pro Kopf berechnen. Bitte beachten Sie, dass wir für solche erweiterten Funktionen ein geeignetes geografisches Informationssystem (z. B. QGIS ) oder eine Datenbank benötigen , die geografische Daten verarbeiten kann (z . B. PostGIS ).
3. Irland verfügt über eine Datenbank mit früheren Immobilienpreisen, die als Wohnimmobilienregister bezeichnet wird . Ihre Website enthält Informationen zu allen seit dem 1. Januar 2010 in Irland gekauften Wohnimmobilien, einschließlich Verkaufsdatum, Preis und Adresse. Durch den Vergleich der aktuellen Immobilienpreise mit früheren Immobilienpreisen können Sie sehen, wie sich die Nachfrage im Laufe der Zeit verändert hat.
4. Die Preise für die Hausversicherung hängen in hohem Maße vom Standort des Hauses ab. Mit einigem Aufwand könnten wir die Websites der Versicherungsunternehmen verschrotten, um ihr "Risikofaktormodell" in unser Dashboard zu integrieren.
In einem Markt wie Dublin kann es eine entmutigende Aufgabe sein, ein neues Zuhause zu finden, insbesondere für jemanden, der gerade in die Stadt gezogen ist und es nicht sehr gut kennt.
Dank dieses Tools haben meine Frau und ich uns (und dem Makler) Zeit gespart: Wir haben 4 Mal zugesehen, 3 Verkäufern ihren Preis angeboten, und einer von ihnen hat unser Angebot angenommen.