
Doppelte Behandlung ist eines der schmerzhaftesten Themen in der Arbeit eines Analytikers. Auf unserer Plattform versuchen wir, diesen Prozess so weit wie möglich zu automatisieren, um die Belastung der NSI-Experten zu verringern und die Produktivität der Kollegen bei der Datenverarbeitung zu steigern. Heute werden wir uns am Beispiel eines der gängigsten und grundlegendsten Nachschlagewerke - dem Verzeichnis der Gegenparteien - ansehen, wie die Plattform dazu beiträgt, einen einzigen goldenen Rekord zu bilden.
Betrachten wir eines der typischen Szenarien. Angenommen, ein großer B2B-Händler empfängt Waren von verschiedenen Lieferanten und verkauft sie an Kunden - juristische Personen. Personen. Wenn in der Praxis bei der Wartung durch den Lieferanten alles mehr oder weniger gut ist, erfordert die Bearbeitung des Kundenstamms manchmal ein ganzes engagiertes Expertenteam. Dies liegt an der Tatsache, dass Unternehmen normalerweise mehrere Systemquellen für Kundendaten verwenden: ERP, CRM, Open Source usw. Die Arbeit ist besonders schwierig, wenn es mehrere Abteilungen im Unternehmen gibt, von denen jede ihren eigenen Kundenstamm unterhält das gleiche Gebiet ... In diesem Fall wird ein Teil der Kundendaten bei der Umverteilung einer Basis dupliziert und überschneidet sich implizit zwischen verschiedenen Kundenbasis. In einem ERP-System ist eine ernsthafte Verarbeitung doppelter Datensätze erforderlich, um einen sogenannten Stammsatz zu erhalten.mit denen Sie in Zukunft arbeiten können. Die Unidata-Plattform verfügt über einen speziellen Mechanismus zum Suchen und Verarbeiten doppelter Datensätze, der solche Aufgaben erfolgreich bewältigt.
Lass uns anfangen
Die Plattform basiert auf dem Metamodell der verwendeten Domain. Domain ist ein strukturierter Satz von Registern und Verzeichnissen. ihre Attribute und die Beziehungen zwischen ihnen, die zusammen die Datenstruktur der Domäne beschreiben. Wir werden später über das Metamodell selbst sprechen, aber jetzt werden wir sehen, wie die Plattform es Ihnen ermöglicht, mit doppelten Datensätzen in einem vorhandenen Datenmodell zu arbeiten. In unserem Beispiel gibt es ein Register von "Gegenparteien", in dem die Hauptattribute lauten: Name der Gegenpartei (normalerweise kurz und vollständig), TIN, KPP, rechtliche und tatsächliche Adressen, Adresse der Registrierung der juristischen Person usw.
Die Plattform verwendet einen Konsolidierungsmechanismus, um Duplikate zu verarbeiten. Das Wesentliche bei der Konsolidierung ist, dass wir bestimmte Regeln für das Auffinden von Duplikaten festlegen, Datenquellen definieren und für jede Datenquelle spezielle Gewichte festlegen, die für das Vertrauensniveau der vom Quellsystem empfangenen Informationen und der von gefundenen Duplikate verantwortlich sind Das System wird zu einem einzigen Referenzdatensatz zusammengeführt. In diesem Fall verschwinden doppelte Datensätze aus den Suchergebnissen, bleiben jedoch im Verlauf des Referenzdatensatzes. Alle Einstellungen werden in der Plattformadministratoroberfläche vorgenommen und erfordern keine Programmierung. Wenn das Zusammenführen von Datensätzen fehlerhaft erfolgt, besteht immer die Möglichkeit, das Zusammenführen rückgängig zu machen. Somit wird der größte Teil der Arbeit mit Duplikaten vom System selbst übernommen, der Benutzer kann nur diesen Prozess steuern.Betrachten wir die Anwendung des Konsolidierungsmechanismus auf die Fälle des angegebenen Beispiels.
Angenommen, die Unidata-Plattform wurde in den Integrationsbus des Unternehmens eingeführt, der Daten zu Gegenparteien aus dem CRM-System, dem ERP-System und dem mobilen Verkaufssystem empfängt. Die Plattform entfernt Duplikate, bereichert und harmonisiert die Daten und überträgt dann die Referenzdatensätze an die empfangenden Systeme.
Fall 1. Passende TIN und KPP
Der einfachste Weg, doppelte Gegenparteien zu finden, besteht darin, sie nach TIN und KPP zu vergleichen. In den meisten Fällen reicht sogar eine TIN aus. Um eine solche Regel für die Suche nach doppelten Datensätzen zu implementieren, reicht es aus, eine genaue Übereinstimmungsregel für die Attribute INN und KPP einzurichten.
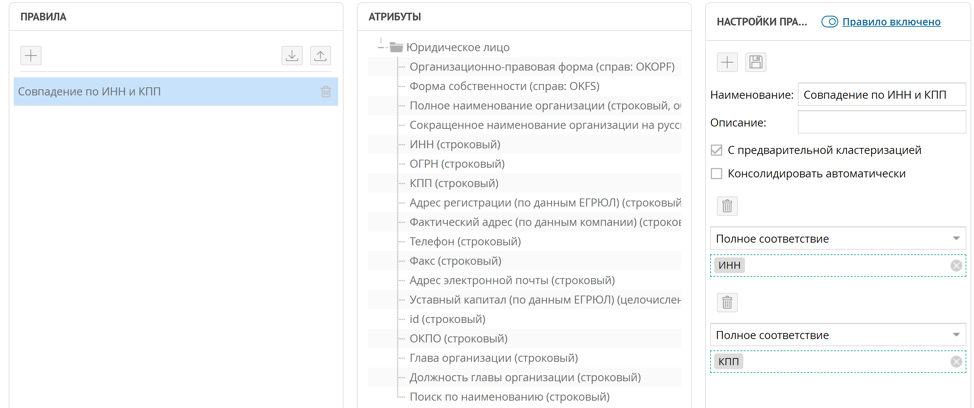
Gemäß dieser Regel wird beim Eintreffen eines neuen Datensatzes auf der Plattform die konfigurierte doppelte Suchregel automatisch gestartet, wenn die Regel auf "Pre-Clustering" eingestellt ist. Alle durch Zufall von INN und KPP gefundenen Tupel von Datensätzen werden in doppelten Clustern gesammelt. Im Fenster für doppelte Cluster können Sie mit Unidata einen Stammsatz aus doppelten Datensätzen erstellen.
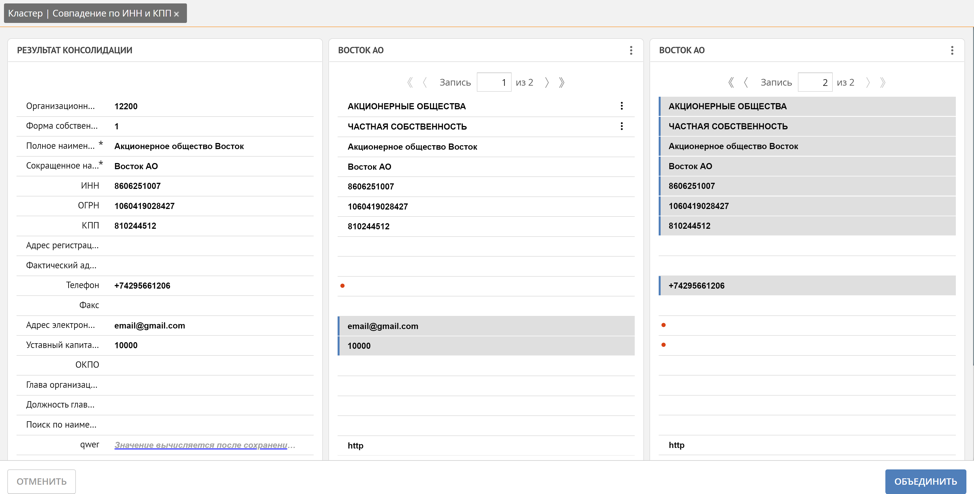
Hier kann der Benutzer manuell verfolgen, welcher Datensatz automatisch zu einer Referenz wird, und ihn gegebenenfalls korrigieren, indem er die Werte der Attribute der doppelten Datensätze, die in den Referenzdatensatz aufgenommen werden sollen, manuell markiert oder den gesamten Datensatz markiert. Darüber hinaus unterstützt Unidata einen Mechanismus zum Anreichern fehlender Werte basierend auf ähnlichen Datensätzen. Zum Beispiel wurden Telefon, Post und Aktienkapital automatisch aus 2 verschiedenen doppelten Aufzeichnungen erhalten.
Wie bereits erwähnt, bestimmt die Plattform beim Bilden eines Clusters von Duplikaten automatisch, wie der Referenzdatensatz gebildet wird. Dies ist auf die zuvor erwähnten Vertrauensgewichte der Quellsysteme zurückzuführen. Je höher das Gewicht des Systems ist, aus dem der Datensatz stammt, desto wichtiger sind die Werte seiner Attribute für den Referenzdatensatz. Es gibt jedoch häufig Situationen, in denen die Werte bestimmter Attribute für ein bestimmtes Quellsystem Vorrang vor allen anderen haben sollten. Beispielsweise vertrauen wir die tatsächliche Lieferadresse des Kunden vor allem dem Agenten an, der direkt auf dem Gebiet des Kunden verhandelt und kennt die Adresse genau, was in unserem Beispiel mobiles Verkaufssystem bedeutet. Um solche Probleme zu lösen, kann die Plattform Gewichte nicht nur für Datenquellen, sondern auch für Datensatzattribute im Kontext jeder Datenquelle festlegen.Mit dieser Kombination von Gewichten können Sie die Regeln zum Generieren eines Referenzdatensatzes flexibel konfigurieren.

Fall 2. Fuzzy-Korrespondenz mit dem Namen der juristischen Person
Obwohl die TIN ein obligatorisches Attribut ist, nehmen wir an, dass die Informationen über den Kunden seit langer Zeit nicht mehr aktualisiert wurden. Er hat seine organisatorische und rechtliche Form geändert. In diesem Fall kommt bereits ein Eintrag mit einer anderen TIN auf die Plattform und die TIN-Übereinstimmung funktioniert nicht. In diesem Fall können Sie auf der Plattform eine Fuzzy-Match-Regel anhand des Werts der Attribute bilden, in diesem Fall anhand des Namens der juristischen Person.

Die Fuzzy-Suche verfügt nicht über ein vorläufiges Clustering, da dieser Vorgang sehr ressourcenintensiv ist. Dies bedeutet, dass diese Regel nicht sofort funktioniert, wenn ein neuer Datensatz hinzugefügt wird. Um Fuzzy-Suchregeln zu starten, wird eine spezielle Operation zum Suchen von Duplikaten verwendet, die vom Administrator oder vom System nach einem Zeitplan manuell gestartet wird. Nachdem die Duplikate gefunden wurden, können die gebildeten Cluster in einem speziellen Abschnitt der Datenoperatorschnittstelle angezeigt werden.
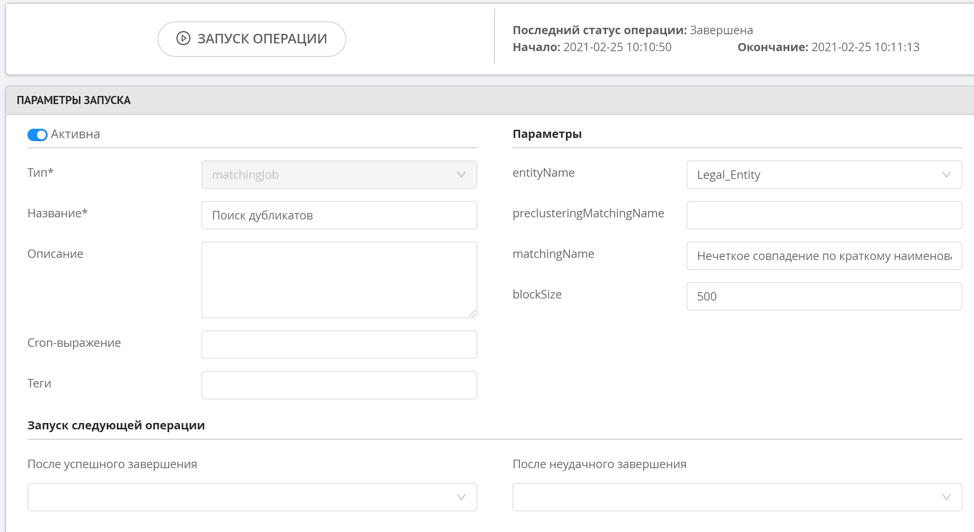

Die Fuzzy-Duplikatsuche funktioniert so, dass wir ähnliche Zeichenfolgenwerte ermitteln, die sich um 1-2 Zeichen unterscheiden oder nicht mehr als zwei Permutationen (Levenshtein-Abstand) erfordern. Es besteht auch die Möglichkeit, nach n-Gramm zu suchen. Mit diesem Ansatz können Sie ähnliche Datensätze mit hoher Genauigkeit finden, ohne Ressourcen zu laden, um alle möglichen Zeichenfolgenmanipulationen zu berechnen, wenn sich die Zeichenfolgen stark voneinander unterscheiden.
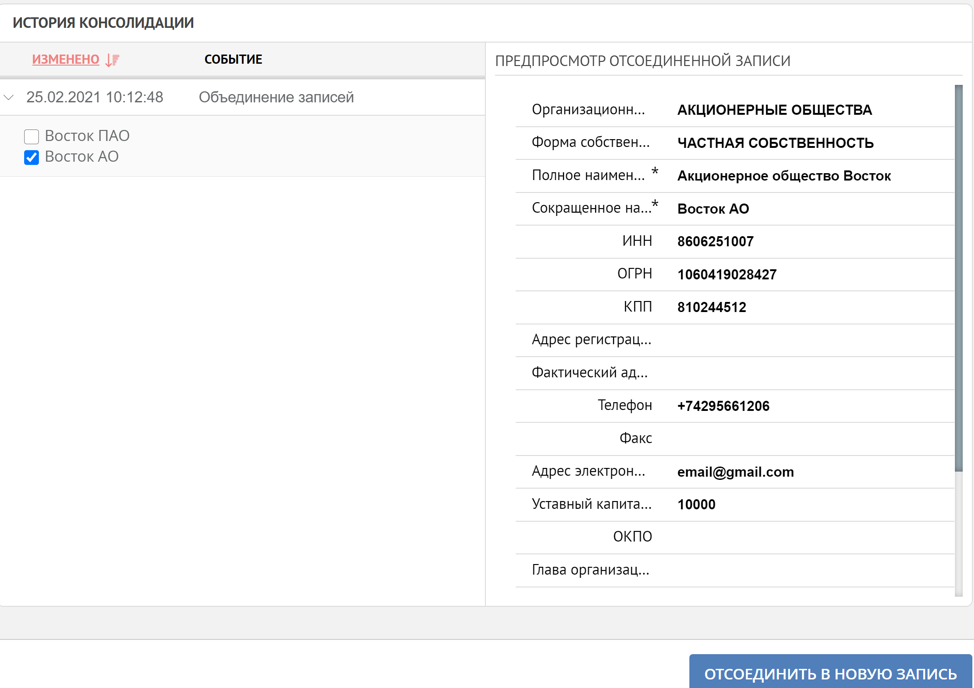
So haben wir in einfachen typischen Fällen die Prinzipien der Plattform bei der Arbeit mit doppelten Datensätzen demonstriert. Die doppelte Verarbeitung kann entweder vollständig unter Benutzerkontrolle oder automatisch durchgeführt werden. Wenn die Datenkonsolidierung versehentlich erfolgt ist, hat das System, wie eingangs erwähnt, immer die Möglichkeit, den Verlauf der Bildung des Referenzdatensatzes anzuzeigen und gegebenenfalls den umgekehrten Vorgang zu starten.
Wir hören hier nicht auf, wir erforschen neue Algorithmen und Ansätze bei der Arbeit mit Duplikaten, wir bemühen uns, die maximale Datenqualität in einer Vielzahl von Unternehmenssystemen sicherzustellen.