
Wenn wir über CI & CD sprechen, gehen wir häufig tiefer in die grundlegenden Tools zur Automatisierung von Build, Test und Anwendungsbereitstellung ein - wobei wir uns auf die Tools konzentrieren, aber vergessen, die Prozesse abzudecken, die beim Schneiden und Stabilisieren von Releases auftreten. Es sind jedoch nicht alle vorgefertigten Tools gleichermaßen nützlich, und einige benutzerdefinierte Prozesse passen nicht in ihre Abdeckung. Sie müssen die Prozesse untersuchen und Wege finden, sie zu automatisieren, um sie zu optimieren.
In unserem Unternehmen verwenden QS-Ingenieure Zephyr, um den Fortschritt der Regression zu verfolgen, da wir manuelle und explorative Tests nicht durch Autotests ersetzen können. Trotzdem werden Autotests hier und in großen Mengen häufig verfolgt, sodass ich in der Lage sein möchte, einige automatisierte Banalprüfungen wegzulassen und Tester produktivere und nützlichere Arbeiten ausführen zu lassen.
Wir haben Nachtläufe, in denen volle Testsuiten verfolgt werden. Aber zu Beginn der Beherrschung von Zephyr mussten unsere Tester während der Regression xcresult oder sogar eine frühere plist oder junit xml herunterladen und dann die Entsprechungen von grünen und roten Tests in Marshmallows mit ihren Händen notieren. Dies ist eine eher routinemäßige Operation, und es dauert viel Zeit, um 500-600 Tests von Hand zu bestehen. Sie wollen solche Dinge einer seelenlosen Maschine ausliefern. So wurde ZERG geboren.
Zerg wird geboren
Zephyr Enterprise Report Generator ist ein kleines Dienstprogramm, das zunächst nur wusste, wie man im Testbericht nach Übereinstimmungen sucht und deren aktuellen Status an Zephyr sendet. Später erhielt das Dienstprogramm neue Funktionen, aber heute konzentrieren wir uns darauf, Berichte zu finden und zu senden.
In Zephyr werden wir gebeten, mit Versionen, Schleifen und Ausführungen von Testfällen zu arbeiten. Jede Version enthält eine beliebige Anzahl von Zyklen, und jeder Zyklus enthält Falldurchläufe. Solche Durchgänge enthalten Informationen über die Aufgabe (Zephyr lässt sich perfekt in Jira integrieren und der Testfall ist tatsächlich eine Aufgabe in Jira), den Autor, den Status des Falls sowie darüber, wer mit diesem Fall befasst ist, und andere notwendige Details .
Um das oben beschriebene Problem zu automatisieren, ist es wichtig zu verstehen, wie der Status des Falls festgelegt wird.
Arbeiten mit Code
Aber wie korrelieren Sie den Code-Test und den Marshmallow-Test? Hier haben wir einen ziemlich einfachen und unkomplizierten Ansatz gewählt: Für jeden Test fügen wir im Kommentarbereich Links zu Aufgaben in jira hinzu.
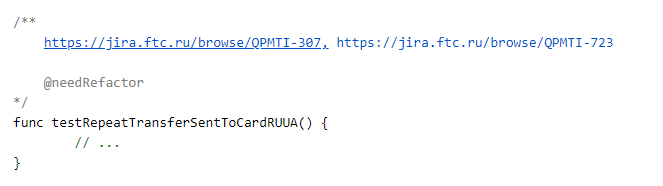
Zusätzliche Parameter können auch in die Kommentare eingefügt werden, aber dazu später mehr.
Ein Test im Code kann also mehrere Aufgaben abdecken. Die umgekehrte Logik funktioniert aber auch. Für eine Aufgabe können mehrere Tests in Code geschrieben werden. Ihr Status wird bei der Erstellung des Berichts berücksichtigt.
Wir müssen den Quellcode durchgehen, alle Testklassen und Tests extrahieren, Aufgaben mit Methoden verknüpfen und dies mit dem Test-Passing-Bericht (xcresult oder junit) korrelieren.
Sie können auf verschiedene Arten mit dem Code selbst arbeiten:
- Lesen Sie einfach Dateien und
rufen
Sie Informationen über reguläre Ausdrücke ab. - Verwenden Sie SourceKit. Auch wenn Sie SourceKit verwenden, können wir nicht auf reguläre Ausdrücke verzichten, um Aufgaben-IDs aus Links in Kommentaren zu extrahieren.
Zu diesem Zeitpunkt sind wir nicht an Details interessiert, daher werden wir uns mit einem Protokoll von ihnen abgrenzen:

Wir müssen Tests erhalten. Dazu beschreiben wir die Strukturen:
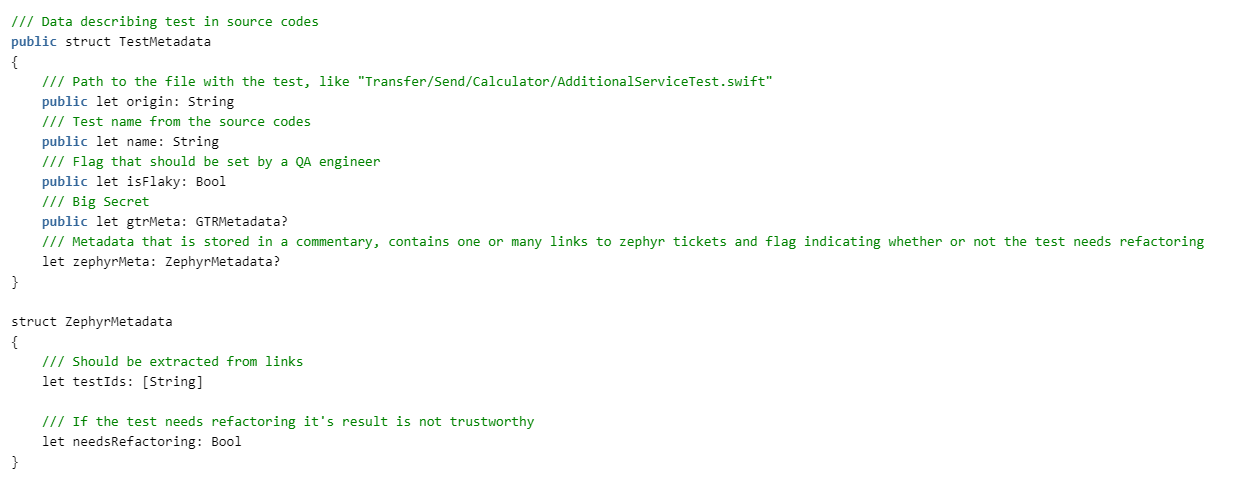
Dann müssen wir den Bericht über das Bestehen von Tests lesen. ZERG wurde vor dem Wechsel zu xcresult geboren und kann daher plist und junit analysieren. Wir sind immer noch nicht an den Details in diesem Artikel interessiert, sie werden im Code angehängt. Deshalb werden wir die Protokolle abschotten

Sie müssen lediglich die Tests im Code mit den Testergebnissen aus den Berichten verknüpfen.
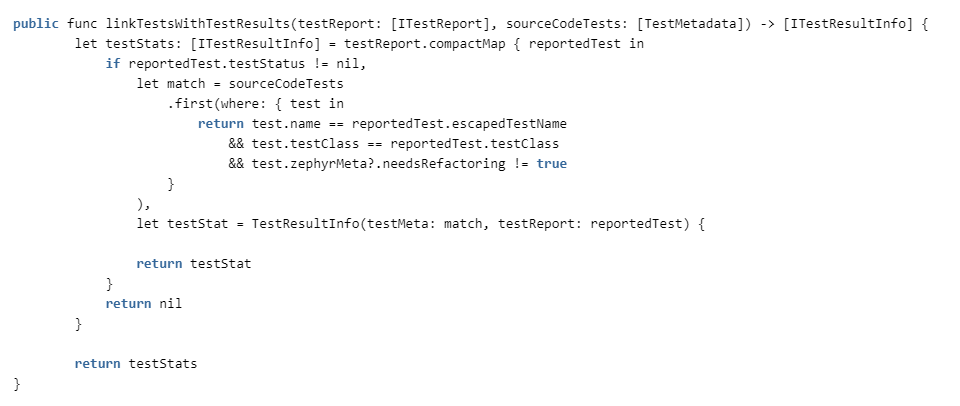
Wir überprüfen die Entsprechung anhand des Klassennamens und des Testnamens (verschiedene Klassen haben möglicherweise Methoden mit demselben Namen) und ob für den Test ein Refactoring erforderlich ist. Wenn Sie es brauchen, halten wir es für unzuverlässig und werfen es aus der Statistik.
Wir arbeiten mit Marshmallows
Nachdem wir die Testberichte gelesen haben, müssen wir sie in den Zephyr-Kontext übersetzen. Dazu müssen Sie eine Liste der Projektversionen abrufen, die mit der Version der Anwendung korrelieren (damit dies funktioniert, muss die Version im Marshmallow mit der Version in der Info.plist Ihrer Anwendung übereinstimmen B. 2.56), Loops und Pässe herunterladen. Und dann korrelieren Sie die Pässe mit unseren vorhandenen Berichten.
Dazu müssen wir die folgenden Methoden in ZephyrAPI implementieren: Die
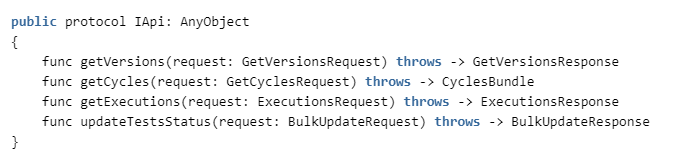
Spezifikation finden Sie hier: getzephyr.docs.apiary.io , und die Client-Implementierung befindet sich in unserem Repository.
Der allgemeine Algorithmus ist ziemlich einfach:
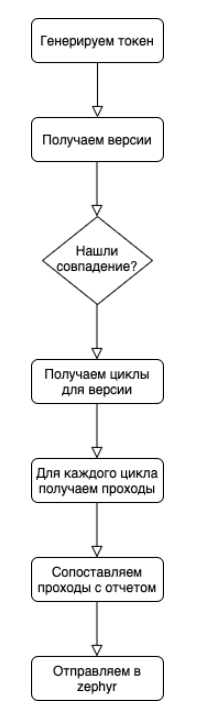
In der Phase des Abgleichs von Durchläufen mit Berichten muss ein subtiler Punkt berücksichtigt werden: In der Zephyr-API ist es am bequemsten, die Ausführungsaktualisierung stapelweise zu senden, wobei der allgemeine Status und eine Liste der Durchlauf-IDs übertragen werden . Wir müssen unsere Ticketberichte erweitern und das nm-Verhältnis berücksichtigen. Für einen Fall in Marshmallow kann der Code mehrere Tests enthalten. Ein Test im Code kann mehrere Fälle abdecken. Wenn für einen Fall n Tests im Code enthalten sind und einer davon rot ist, ist der allgemeine Status für einen solchen Fall rot. Wenn einer dieser Tests jedoch m Fälle abdeckt und grün ist, sollte der Rest der Fälle dies tun nicht rot werden.
Deshalb arbeiten wir mit Mengen und suchen nach dem Schnittpunkt von Rot und Grün. Alles, was in den Schnittpunkt fällt, subtrahieren wir von den grünen Ergebnissen und senden die bearbeiteten Informationen an Zephyr.

Hierbei ist auch zu beachten, dass wir innerhalb des Teams vereinbart haben, dass zerg den Status des Passes nicht ändert, wenn:
1. der aktuelle Status blockiert oder fehlgeschlagen ist (wir haben früher den Status für fehlgeschlagen geändert, aber jetzt haben wir aufgegeben üben, weil wir möchten, dass Tester während der Regression auf rote Autotests achten).
2. Wenn der aktuelle Status bestanden ist und von einer Person festgelegt wurde, nicht von zerg.
3. Wenn der Test als blinkend markiert ist.
Zephyr API-Interessen
Wenn wir Schleifen anfordern, erhalten wir json, das auf den ersten Blick nicht für die Deserialisierung systematisiert werden kann. Die Sache ist, dass eine Anforderung, Schleifen für eine Version abzurufen, obwohl sie ein Array von Schleifen zurückgeben sollte, tatsächlich ein Objekt zurückgibt, wobei jedes Feld eindeutig ist und als Schleifenkennung bezeichnet wird, die im Wert liegt. Um dies zu handhaben, verwenden wir einfache Hacks:

Testübergabe-Status kommen in einer der Anforderungen neben dem Anforderungsobjekt. Sie können jedoch vorab in enum verschoben werden:

Wenn Sie Schleifen anfordern, müssen Sie die Versions- und Ganzzahlkennung des Projekts an die Anforderungsparameter übergeben. Bei der Anforderung von Durchläufen für die Schleife muss jedoch dieselbe Projektkennung in einem Zeichenfolgenformat übergeben werden.

Anstelle einer Schlussfolgerung
Wenn es viel Routinearbeit gibt, kann höchstwahrscheinlich etwas automatisiert werden. Einer dieser Fälle ist die Synchronisierung des Durchlaufs von Autotests mit dem Testmanagementsystem.
Daher haben wir jede Nacht einen vollständigen Testlauf, und während der Regression wird der Bericht an die QS-Ingenieure gesendet. Dies reduziert die Regressionszeit und gibt Zeit für Erkundungstests.
Wenn Sie den Android-Quellparser korrekt implementieren, kann er mit demselben Erfolg für die zweite Plattform angewendet werden.
Unser Zerg kann nicht nur Tests vergleichen, sondern auch die anfänglichen Auswirkungen analysieren, aber mehr dazu, vielleicht beim nächsten Mal.