Unsere Leser konnten nicht anders, als unser wachsendes Interesse an der Go-Sprache zu bemerken. Zusammen mit dem Buch aus dem vorherigen Beitrag haben wir viele interessante Dinge zu diesem Thema . Heute möchten wir Ihnen eine Übersetzung des Materials "für die Profis" anbieten, die interessante Aspekte der manuellen Speicherverwaltung in Go sowie die gleichzeitige Ausführung von Speicheroperationen in Go und C ++ demonstriert.
In der Sprache von Dgraph Labs wird Go seit seiner Gründung im Jahr 2015 verwendet. Nach fünf Jahren oder 200 000 Codezeilen auf dem Go können Sie gerne verkünden, dass es nicht falsch ist, Go zu verwenden. Diese Sprache inspiriert nicht nur als Werkzeug zum Erstellen neuer Systeme, sondern ermutigt sogar dazu, Skripte in Go zu schreiben, die traditionell in Bash oder Python geschrieben wurden. Es stellt sich heraus, dass Sie mit Go eine Basis aus sauberem, lesbarem und wartbarem Code erstellen können, die - was am wichtigsten ist - effizient und gleichzeitig einfach zu handhaben ist.
Es gibt jedoch ein Problem mit Go, das sich bereits in den frühen Phasen der Arbeit manifestiert: die Speicherverwaltung... Wir haben keine Beschwerden über den Go-Garbage-Collector erhalten, aber abgesehen davon, wie sehr er das Leben von Entwicklern vereinfacht, hat er dieselben Probleme wie andere Garbage-Collectors: Er kann einfach nicht mit der manuellen Speicherverwaltung in seiner Effizienz konkurrieren .
Das manuelle Verwalten des Speichers führt zu einer geringeren Speichernutzung und einer vorhersehbaren Speichernutzung und vermeidet verrückte Spitzen in der Speichernutzung, wenn ein großer neuer Speicherblock scharf zugewiesen wird. Alle oben genannten Probleme mit der automatischen Speicherverwaltung wurden bei der Verwendung von Speicher in Go festgestellt.
Sprachen wie Rust können teilweise Fuß fassen, weil sie eine sichere manuelle Speicherverwaltung bieten. Das ist willkommen.
Nach meiner Erfahrung ist das manuelle Zuweisen von Speicher und das Aufspüren potenzieller Speicherlecks einfacher als der Versuch, die Speichernutzung mit Garbage Collection-Tools zu optimieren. Die manuelle Speicherbereinigung lohnt sich bei der Erstellung von Datenbanken, die praktisch unbegrenzte Skalierbarkeit bieten.
Aus Liebe zu Go und der Notwendigkeit, die Speicherbereinigung mit dem Go GC zu vermeiden, mussten wir innovative Wege finden, um den Speicher in Go manuell zu verwalten. Natürlich müssen die meisten Go-Benutzer den Speicher niemals manuell verwalten. Wir empfehlen, dies zu vermeiden, es sei denn, Sie müssen dies wirklich tun. Und wenn Sie es brauchen - Sie müssen wissen , wie es zu tun .
Mit Cgo Speicher aufbauen
Dieser Abschnitt ist dem Cgo-Wiki-Artikel zum Konvertieren von C-Arrays in Go-Segmente nachempfunden. Wir könnten malloc verwenden, um Speicher in C zuzuweisen, und unsicher verwenden, um ihn an Go zu übergeben, ohne dass der Go-Garbage Collector eingreifen muss.
import "C"
import "unsafe"
...
var theCArray *C.YourType = C.getTheArray()
length := C.getTheArrayLength()
slice := (*[1 << 28]C.YourType)(unsafe.Pointer(theCArray))[:length:length]
Dies ist jedoch mit der unter golang.org/cmd/cgo angegebenen Einschränkung möglich.
: . Go nil C ( Go) C, , C Go. , C Go, Go . C, Go.
Daher werden wir anstelle von malloc das
calloc
etwas schwerere Gegenstück verwenden .
calloc
funktioniert genau so
malloc
, mit der Einschränkung, dass der Speicher auf Null zurückgesetzt wird, bevor er an den Anrufer zurückgegeben wird.
Zu Beginn haben wir in ihrer einfachsten Form die Funktionen Calloc und Free implementiert, die Go-Bytesegmente für Go via Cgo zuweisen und freigeben. Um diese Funktionen zu testen, wurde ein kontinuierlicher Speichernutzungstest entwickelt und getestet. ... Dieser Test wiederholte in Form einer Endlosschleife einen Speicherzuweisungs- / Freigabezyklus, in dem zuerst Speicherfragmente mit zufälliger Größe zugewiesen wurden, bis der insgesamt zugewiesene Speicher 16 GB erreichte, und dann wurden diese Fragmente allmählich freigegeben, bis nur 1 GB Speicher zugewiesen wurde .
Das entsprechende C-Programm funktionierte wie erwartet. Wir haben
htop
gesehen, wie die dem Prozess zugewiesene Speichermenge (RSS) zuerst 16 GB erreicht, dann auf 1 GB sinkt, dann wieder auf 16 GB ansteigt und so weiter. Ein Go-Programm, das nach jeder Schleife immer mehr Speicher verwendet
Calloc
und
Free
verwendet (siehe Abbildung unten).
Es wurde vermutet, dass dies auf eine Speicherfragmentierung zurückzuführen ist, da die
C.calloc
Standardaufrufe keine "Thread-Erkennung" aufweisen . Um dies zu vermeiden, wurde beschlossen, es zu versuchen
jemalloc
.
jemalloc
jemalloc
Ist eine generische Implementierungmalloc
, die sich darauf konzentriert, Fragmentierung zu verhindern und skalierbare Parallelität aufrechtzuerhalten.jemalloc
wurde erstmals 2005 in FreeBSD als Allokator verwendetlibc
und hat seitdem aufgrund seines vorhersehbaren Verhaltens in vielen Anwendungen Verwendung gefunden. - jemalloc.net
Wir haben unsere APIs auf
jemalloc
Aufrufe
calloc
und umgestellt
free
. Darüber hinaus hat diese Option perfekt funktioniert: Sie
jemalloc
unterstützt Streams nativ ohne Speicherfragmentierung. Der Speichertest, bei dem die Speicherzuweisungs- und Freigabezyklen getestet wurden, blieb bis auf den geringen Aufwand für die Durchführung des Tests im Rahmen des Zumutbaren.
Um zu verdeutlichen, dass wir jemalloc verwenden und Namenskonflikte vermeiden, fügen wir bei der Installation ein Präfix hinzu,
je_
damit unsere APIs jetzt
je_calloc
und
je_free
nicht
calloc
und aufrufen
free
.
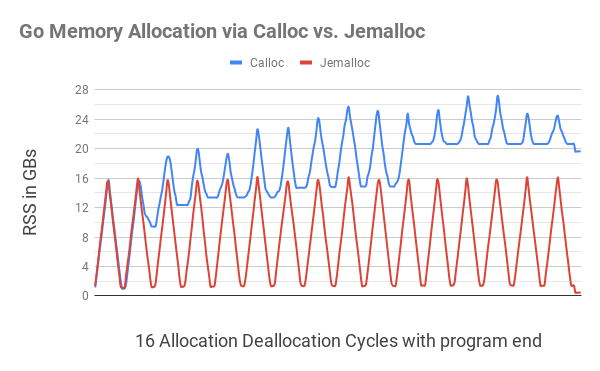
Diese Abbildung zeigt, dass das Zuweisen von Go-Speicher mit
C.calloc
führt zu einer schwerwiegenden Speicherfragmentierung, die dazu führt, dass das Programm bis zum 11. Zyklus bis zu 20 GB Speicher belegt. Der äquivalente Code
jemalloc
ergab keine merkliche Fragmentierung und passte in jeden Zyklus nahe 1 GB.
Näher am Ende des Programms (eine kleine Welligkeit am rechten Rand)
C.calloc
verbrauchtedas Programm nach der
jemalloc
Freigabe desgesamten zugewiesenen Speichers immer noch etwas weniger als 20 GB Speicher, während es nur 400 MB Speicher kostete.
Um jemalloc zu installieren, laden Sie es von hier herunter und führen Sie die folgenden Befehle aus:
./configure --with-jemalloc-prefix='je_' --with-malloc-conf='background_thread:true,metadata_thp:auto' make sudo make install
Der gesamte Code
Calloc
sieht ungefähr so aus:
ptr := C.je_calloc(C.size_t(n), 1)
if ptr == nil {
// NB: throw panic, ,
// . , – , Go,
// .
throw("out of memory")
}
uptr := unsafe.Pointer(ptr)
atomic.AddInt64(&numBytes, int64(n))
// C Go, .
return (*[MaxArrayLen]byte)(uptr)[:n:n]
Dieser Code ist im Ristretto- Paket enthalten . Ein Assembly-Tag wurde hinzugefügt, damit der resultierende Code zum Zuweisen von Byte-Chunks zu jemalloc wechseln kann
jemalloc
. Um die Bereitstellungsvorgänge weiter zu vereinfachen, wurde die Bibliothek statisch mit
jemalloc
der resultierenden Go-Binärdatei verknüpft , indem die entsprechenden LDFLAGS-Flags gesetzt wurden.
Zerlegen von Go-Strukturen in Bytesegmente
Wir haben jetzt eine Möglichkeit, ein Bytesegment zuzuweisen und freizugeben, und dann werden wir diese verwenden, um unsere Strukturen in Go auszurichten. Sie können mit dem einfachsten Beispiel beginnen (vollständiger Code).
type node struct {
val int
next *node
}
var nodeSz = int(unsafe.Sizeof(node{}))
func newNode(val int) *node {
b := z.Calloc(nodeSz)
n := (*node)(unsafe.Pointer(&b[0]))
n.val = val
return n
}
func freeNode(n *node) {
buf := (*[z.MaxArrayLen]byte)(unsafe.Pointer(n))[:nodeSz:nodeSz]
z.Free(buf)
}
Im obigen Beispiel haben wir die Go-Struktur für den in C zugewiesenen Speicher mit erstellt
newNode
. Wir haben eine entsprechende Funktion erstellt
freeNode
, mit der wir Speicher freigeben können, sobald wir mit der Struktur fertig sind. Die Struktur in der Sprache Go enthält den einfachsten Datentyp
int
und einen Zeiger auf die nächste Knotenstruktur. All dies kann im Programm festgelegt werden, und dann kann auf diese Entitäten zugegriffen werden. Wir haben 2M-Knotenobjekte ausgewählt und daraus eine verknüpfte Liste erstellt, um zu demonstrieren, dass jemalloc wie erwartet funktioniert.
Mit der Standardspeicherzuordnung von Go können Sie sehen, dass 31 MiB des Heaps einer verknüpften Liste mit 2 Millionen Objekten zugeordnet sind, aber nichts durch zugewiesen wird
jemalloc
.
$ go run . Allocated memory: 0 Objects: 2000001 node: 0 ... node: 2000000 After freeing. Allocated memory: 0 HeapAlloc: 31 MiB
Unter Verwendung des Assembly-Tags sehen
jemalloc
wir, dass 30 MiB Speicherbyte durch zugewiesen werden
jemalloc
, und nachdem die verknüpfte Liste freigegeben wurde, fällt dieser Wert auf Null. Go weist nur 399 KiB aus dem Speicher zu, was wahrscheinlich auf den Aufwand beim Ausführen des Programms zurückzuführen ist.
$ go run -tags=jemalloc . Allocated memory: 30 MiB Objects: 2000001 node: 0 ... node: 2000000 After freeing. Allocated memory: 0 HeapAlloc: 399 KiB
Amortisation der Calloc-Kosten mit Allocator
Der obige Code leistet hervorragende Arbeit bei der Speicherzuweisung in Go. Dies erfolgt jedoch auf Kosten einer Leistungsverschlechterung . Nachdem
time
wir beide Kopien mit gefahren haben , sehen wir, dass das
jemalloc
Programm in 1,15 Sekunden kopiert wurde . Da machte
jemalloc
sie 5 mal langsamer, mit über 5,29.
$ time go run . go run . 1.15s user 0.25s system 162% cpu 0.861 total $ time go run -tags=jemalloc . go run -tags=jemalloc . 5.29s user 0.36s system 108% cpu 5.200 total
Diese Verlangsamung kann auf die Tatsache zurückgeführt werden, dass für jede Speicherzuweisung Cgo-Aufrufe getätigt wurden und jeder Cgo-Aufruf einen gewissen Overhead verursacht. Um dies zu bewältigen, wurde die Allocator- Bibliothek geschrieben , die ebenfalls im ristretto / z- Paket enthalten ist . Diese Bibliothek weist einem Speicher größere Speichersegmente zu, von denen jedes viele kleine Objekte aufnehmen kann, wodurch teure Cgo-Aufrufe überflüssig werden .
Der Allocator beginnt mit einem Puffer und erstellt, sobald er aufgebraucht ist, einen neuen Puffer, der doppelt so groß ist wie der erste. Es führt eine interne Liste aller zugewiesenen Puffer. Wenn der Benutzer mit den Daten fertig ist, können wir Release aufrufen, um alle diese Puffer auf einen Schlag freizugeben. Hinweis: Allocator verschiebt den Speicher überhaupt nicht. Dies stellt sicher, dass alle Zeiger, die wir auf die Struktur haben, weiterhin funktionieren.
Obwohl eine solche Speicherverwaltung plump und im Vergleich erscheinen , wie zu bedienen
tcmalloc
und
jemalloc
ist dieser Ansatz viel einfacher. Sobald Sie Speicher zugewiesen haben, können Sie nicht nur eine Struktur freigeben. Sie können nur den gesamten vom Allocator verwendeten Speicher auf einmal freigeben.
Was Allocator wirklich gut kann, ist, Millionen von Strukturen billig zuzuweisen und sie dann freizugeben, wenn die Arbeit erledigt ist, ohne dass ein Haufen Go involviert sein muss, um die Arbeit zu erledigen . Das Ausführen des obigen Programms mit dem neuen Allocator-Build-Tag wird noch schneller ausgeführt als die Go-Speicherversion.
$ time go run -tags="jemalloc,allocator" . go run -tags="jemalloc,allocator" . 1.09s user 0.29s system 143% cpu 0.956 total
In Go 1.14 und höher
-race
ermöglicht das Flag Ausrichtungsprüfungen von Strukturen im Speicher. Allocator verfügt über eine Methode
AllocateAligned
, die Speicher zurückgibt, und der Zeiger muss korrekt ausgerichtet sein, um diese Prüfungen zu bestehen. Wenn die Struktur groß ist, kann etwas Speicher verloren gehen, aber die CPU-Anweisungen beginnen aufgrund der korrekten Abgrenzung von Wörtern effizienter zu arbeiten.
Es gab ein weiteres Problem mit der Speicherverwaltung. Es kommt also vor, dass Speicher an einem Ort zugewiesen und an einem völlig anderen Ort freigegeben wird. Die gesamte Kommunikation zwischen diesen beiden Punkten kann über Strukturen erfolgen, und sie können nur durch Übertragung eines bestimmten Objekts unterschieden werden
Allocator
. Um dies zu bewältigen, weisen wir jedem Objekt eine eindeutige ID zu.
Allocator
welche diese Objekte in der Referenz speichern
uint64
. Jedes neue Objekt
Allocator
wird im globalen Wörterbuch unter Bezugnahme auf sich selbst gespeichert. Allokatorobjekte können dann unter Verwendung dieser Referenz abgerufen und freigegeben werden, wenn die Daten nicht mehr benötigt werden.
Ordnen Sie Links kompetent an
NICHT referenzieren Zugewiesenen Speicher aus manuell zugewiesenem Speicher entfernen.
Wenn Sie eine Struktur wie oben gezeigt von Hand zuweisen, ist es wichtig sicherzustellen, dass in dieser Struktur keine Verweise auf den von Go zugewiesenen Speicher vorhanden sind. Lassen Sie uns die obige Struktur ein wenig modifizieren:
type node struct {
val int
next *node
buf []byte
}
Verwenden Sie die
root := newNode(val)
oben definierte Funktion , um einen Knoten manuell auszuwählen. Wenn wir dann installieren
root.next = &node{val: val}
und somit alle anderen Knoten in der verknüpften Liste über den Go-Speicher zuweisen, erhalten wir unweigerlich den folgenden Sharding-Fehler:
$ go run -race -tags="jemalloc" . Allocated memory: 16 B Objects: 2000001 unexpected fault address 0x1cccb0 fatal error: fault [signal SIGSEGV: segmentation violation code=0x1 addr=0x1cccb0 pc=0x55a48b]
Der von Go zugewiesene Speicher unterliegt der Speicherbereinigung, da keine gültige Go-Struktur darauf verweist. Die Referenzen stammen nur aus dem in C zugewiesenen Speicher, und der Go-Heap enthält keine geeigneten Referenzen, was den obigen Fehler hervorruft. Wenn Sie also eine Struktur erstellen und manuell Speicher dafür zuweisen, ist es wichtig sicherzustellen, dass alle rekursiv zugänglichen Felder auch manuell zugewiesen werden.
Wenn die obige Struktur beispielsweise ein Bytesegment verwendet, haben wir dieses Segment mithilfe eines Allokators zugewiesen und auch das Mischen des Go-Speichers mit dem C-Speicher vermieden.
b := allocator.AllocateAligned(nodeSz)
n := (*node)(unsafe.Pointer(&b[0]))
n.val = -1
n.buf = allocator.Allocate(16) // 16
rand.Read(n.buf)
Umgang mit Gigabyte dediziertem Speicher
Allocator
Gut für die manuelle Auswahl von Millionen von Strukturen. Es gibt aber auch Fälle, in denen Sie Milliarden kleiner Objekte erstellen und sortieren müssen. Um dies in Go auch mit Hilfe zu tun
Allocator
, müssen Sie Code wie folgt schreiben:
var nodes []*node
for i := 0; i < 1e9; i++ {
b := allocator.AllocateAligned(nodeSz)
n := (*node)(unsafe.Pointer(&b[0]))
n.val = rand.Int63()
nodes = append(nodes, n)
}
sort.Slice(nodes, func(i, j int) bool {
return nodes[i].val < nodes[j].val
})
// .
Alle diese 1B-Knoten werden manuell zugewiesen
Allocator
, was teuer ist. Sie müssen auch Geld für jedes Speichersegment in Go ausgeben, was an sich ziemlich teuer ist, da wir 8 GB Speicher benötigen (8 Bytes pro Knotenzeiger).
Um diesen praktischen Situationen gerecht zu werden, wurde eine
z.Buffer
Speicherzuordnungsdatei erstellt, mit der Linux Speicherseiten nach Bedarf des Systems austauschen und leeren kann. Es implementiert
io.Writer
und erlaubt uns, uns nicht darauf zu verlassen
bytes.Buffer
.
Noch wichtiger ist, dass es
z.Buffer
eine neue Möglichkeit bietet, kleinere Datensegmente hervorzuheben. Wenn Sie anrufen
SliceAllocate(n)
,
z.Buffer
(n)
zeichnet die Länge des auszuwählenden Segments auf und wählt dann dieses Segment aus. Dies
z.Buffer
erleichtert das Verstehen von Segmentgrenzen und das korrekte Durchlaufen von Segmenten mit
SliceIterate
.
Daten variabler Länge sortieren
Zum Sortieren haben wir zunächst versucht, Segmentversätze abzurufen
z.Buffer
, zum Vergleich auf Segmente zu verweisen, aber nur die Versätze zu sortieren. Nachdem der Offset empfangen wurde,
z.Buffer
kann er ihn lesen, die Segmentlänge ermitteln und dieses Segment zurückgeben. Auf diese Weise können Sie die Segmente in sortierter Form zurückgeben, ohne auf Speicherwechsel zurückgreifen zu müssen. So innovativ dieser Mechanismus auch ist, dieser Druck setzt den Speicher erheblich unter Druck, da wir immer noch eine Speicherstrafe von 8 GB zahlen müssen, um die interessierenden Offsets auf den Go-Speicher zu übertragen.
Der wichtigste Faktor, der unsere Arbeit einschränkte, war, dass die Größen nicht für alle Segmente gleich waren. Darüber hinaus konnten wir auf diese Segmente nur in sequentieller Reihenfolge und nicht in umgekehrter oder zufälliger Reihenfolge zugreifen, da wir Offsets nicht im Voraus berechnen und speichern konnten. Bei den meisten Algorithmen zum Sortieren wird davon ausgegangen, dass alle Werte dieselbe Größe haben, in beliebiger Reihenfolge aufgerufen werden können und nichts den Austausch verhindert.
sort.Slice
in Go funktioniert ähnlich und war daher schlecht geeignet für
z.Buffer
.
Angesichts dieser Einschränkungen wurde der Schluss gezogen, dass der Merge-Sortieralgorithmus für die jeweilige Aufgabe am besten geeignet ist. Mit der Zusammenführungssortierung können Sie in einem Puffer arbeiten und Operationen in sequentieller Reihenfolge ausführen, wobei der zusätzliche Speicheraufwand nur halb so groß wie der Puffer ist. Es stellte sich heraus, dass es nicht nur billiger ist als das Verschieben der Einrückung in den Speicher, sondern auch die Vorhersagbarkeit in Bezug auf den Speicheraufwand (die Hälfte der Puffergröße) erheblich verbessert. Besser noch, der für die Zusammenführungssortierung erforderliche Overhead wird selbst dem Speicher zugeordnet.
Es gibt noch einen sehr positiven Effekt bei der Verwendung der Zusammenführungssortierung. Die Offset-Sortierung muss die Offsets im Speicher behalten, während wir sie durchlaufen und den Puffer verarbeiten, was nur den Druck auf den Speicher erhöht. Bei der Zusammenführungssortierung wird der gesamte zusätzliche Speicher, der benötigt wird, zum Zeitpunkt des Beginns der Aufzählung freigegeben, was bedeutet, dass wir mehr Speicher haben, um den Puffer zu verarbeiten.
z.Buffer unterstützt auch die Speicherzuweisung durch
Calloc
sowie die automatische Speicherzuordnung nach Überschreiten eines vom Benutzer festgelegten Grenzwerts. Daher funktioniert das Tool gut mit Daten jeder Größe.
buffer := z.NewBuffer(256<<20) // 256MB Calloc.
buffer.AutoMmapAfter(1<<30) // mmap 1GB.
for i := 0; i < 1e9; i++ {
b := buffer.SliceAllocate(nodeSz)
n := (*node)(unsafe.Pointer(&b[0]))
n.val = rand.Int63()
}
buffer.SortSlice(func(left, right []byte) bool {
nl := (*node)(unsafe.Pointer(&left[0]))
nr := (*node)(unsafe.Pointer(&right[0]))
return nl.val < nr.val
})
// .
buffer.SliceIterate(func(b []byte) error {
n := (*node)(unsafe.Pointer(&b[0]))
_ = n.val
return nil
})
Speicherlecks abfangen
Diese gesamte Diskussion wäre unvollständig, ohne das Thema Speicherlecks anzusprechen. Wenn wir den Speicher manuell zuweisen, sind Speicherlecks in all den Fällen unvermeidlich, in denen wir vergessen, Speicher freizugeben. Wie kannst du sie fangen?
Wir haben lange Zeit eine einfache Lösung verwendet - wir haben einen Atomzähler verwendet, der die Anzahl der bei solchen Aufrufen zugewiesenen Bytes verfolgt. In diesem Fall können Sie schnell herausfinden, wie viel Speicher wir manuell im Programm zugewiesen haben
z.NumAllocBytes()
. Wenn wir am Ende des Speichertests noch zusätzlichen Speicher hatten, bedeutete dies ein Leck.
Als wir ein Leck gefunden haben, haben wir zuerst versucht, den jemalloc-Speicherprofiler zu verwenden. Aber es wurde schnell klar, dass dies nicht half - er sah nicht den gesamten Anrufstapel, als er gegen die Cgo-Grenze stieß. Alles, was der Profiler sieht, ist die Speicherzuweisung und die Freigabe erfolgt aus denselben Aufrufen
z.Calloc
und
z.Free
.
Dank der Go-Laufzeit konnten wir schnell ein einfaches System erstellen, um Anrufer zu fangen
z.Calloc
und sie Anrufen zuzuordnen
z.Free
. Dieses System erfordert Mutex-Sperren, daher haben wir beschlossen, es nicht standardmäßig zu aktivieren. Stattdessen haben wir das Build-Flag verwendet
leak
um Debug-Meldungen für Lecks in Entwickler-Assemblys zu aktivieren. Somit werden Lecks automatisch erkannt und genau dort an der Konsole angezeigt, wo sie entstanden sind.
// .
pc, _, l, ok := runtime.Caller(1)
if ok {
dallocsMu.Lock()
dallocs[uptr] = &dalloc{
pc: pc,
no: l,
sz: n,
}
dallocsMu.Unlock()
}
// , , .
// ,
// , .
$ go test -v -tags="jemalloc leak" -run=TestCalloc
...
LEAK: 128 at func: github.com/dgraph-io/ristretto/z.TestCalloc 91
Ausgabe
Mit Hilfe der beschriebenen Techniken wird ein goldener Mittelwert erreicht. Wir können Speicher in kritischen Codepfaden manuell zuweisen, die stark vom verfügbaren Speicher abhängen. Gleichzeitig können wir die automatische Speicherbereinigung auf weniger kritische Weise nutzen. Selbst wenn Sie nicht sehr gut mit Cgo oder jemalloc umgehen können, können Sie diese Techniken mit relativ großen Speicherblöcken in Go verwenden - der Effekt ist vergleichbar.
Alle oben genannten Bibliotheken sind unter der Apache 2.0-Lizenz im Ristretto / z- Paket verfügbar . Der Speichertest und der Demo-Code befinden sich im Contrib- Ordner .