
Wie kann sichergestellt werden, dass jeder Entwickler schnell eine Lösung für sein Problem finden und diese garantiert an die Produktion liefern kann? Die Bereitstellung der Anwendung ist einfach. Es ist schwieriger, es zu einem vollwertigen Produkt zu machen, damit ein Dutzend Teams es in hundert Fällen verwenden können. Und wenn es sich um ein Master-System für mehrere Terabyte handelt, steigt die Angst, die Hände schwitzen und die Basis platzt (vielleicht) aus allen Nähten.
Ich möchte einen Weg zur Bereitstellung ohne Ausfallzeiten und ohne Denial-of-Service teilen. Jenkins-Pipeline, keine Vermittler, 500 Instanzen in einer Produktionsumgebung in 60 Minuten. All dies ist in Open Source. Für Details lade ich Sie unter Katze ein.
Mein Name ist Roman Proskin. Ich erstelle und unterstütze Hochlastsysteme basierend auf Tarantool bei Mail.ru Group. Ich werde Ihnen erzählen, wie unser Team eine Tarantool-Anwendungsbereitstellung erstellt hat, die den Code in einer Produktionsumgebung ohne Ausfallzeiten oder Denial-of-Service aktualisiert. Ich werde die Probleme beschreiben, auf die wir im Prozess gestoßen sind, und welche Lösungen wir am Ende gewählt haben. Ich hoffe, dass unsere Erfahrung beim Aufbau Ihrer Bereitstellung hilfreich sein wird .
Das Bereitstellen einer Anwendung ist einfach. Tarantool verfügt über ein Cartridge-Cli-Dienstprogramm ( Github)). Damit wird die Clusteranwendung in wenigen Minuten irgendwo in Docker bereitgestellt. Es ist viel schwieriger, eine Lösung aus dem Knie in ein vollwertiges Produkt zu verwandeln. Es sollte problemlos Hunderte von Instanzen verarbeiten können. Gleichzeitig müssen Sie in Dutzenden von Teams mit unterschiedlichen Ausbildungsstufen gefragt sein.
Die Idee hinter unserer Bereitstellung ist sehr einfach:
- Sie nehmen zwei Eisenserver.
- Auf jedem starten Sie eine Instanz.
- Kombinieren Sie sie zu einem Satz Repliken.
- Sie aktualisieren nacheinander.
Aber wenn es um ein Mastersystem mit mehreren Terabyte Daten geht, steigt die Angst, die Hände schwitzen und die Basis platzt (vielleicht) aus allen Nähten.
Anfangsbedingungen einstellen
Das System hat eine strenge SLA: Es ist notwendig, eine Verfügbarkeit von 99% unter Berücksichtigung der geplanten Arbeiten sicherzustellen. Dies bedeutet, dass es insgesamt 87 Stunden pro Jahr gibt, in denen wir es uns leisten können, nicht auf Anfragen zu antworten . Es scheint, dass 87 Stunden viel sind, aber ...
Das Projekt ist für ein Datenvolumen von etwa 1,8 TB ausgelegt. Nur ein Neustart dauert 40 Minuten! Das Update selbst fügt, wenn die Änderungen manuell übernommen werden, weitere von oben hinzu. Wir führen drei Updates pro Woche durch: insgesamt 40 * 3 * 52/60 = 104 Stunden - SLA wird verletzt . Und dies sind nur geplante Arbeiten ohne Berücksichtigung von Unfällen, die mit Sicherheit auftreten werden.
Die Anwendung wurde für eine hohe Benutzerlast entwickelt, was bedeutet, dass sie die Stabilitätsanforderungen erfüllen musste. Um bei einem Knotenausfall keine Daten zu verlieren, haben wir uns entschlossen, unseren Cluster geografisch in zwei Rechenzentren aufzuteilen. Deshalb haben wir uns für einen Bereitstellungsmechanismus entschieden, der die SLA nicht verletzt. Lassen Sie die Instanzen nicht sofort, sondern stapelweise über Rechenzentren hinweg aktualisieren.
Die Last kann in das zweite Rechenzentrum übertragen werden. Anschließend steht der Cluster während des gesamten Updates für die Aufzeichnung zur Verfügung. Dies ist eine klassische Schulterbereitstellung und eine der Standardmethoden für die Notfallwiederherstellung .
Die Möglichkeit zur Aktualisierung über Rechenzentren hinweg ist eines der Schlüsselelemente einer Bereitstellung ohne Ausfallzeiten. Ich werde Ihnen am Ende des Artikels mehr über den Prozess erzählen, aber ich werde mich vorerst mit den Merkmalen unseres unmenschlichen Einsatzes und den Schwierigkeiten befassen, auf die wir gestoßen sind.
Probleme
Wir übertragen den Verkehr über die Straße
Es gibt mehrere Rechenzentren, und Anfragen können an jedes von ihnen gehen. Eine Fahrt zu einem nahe gelegenen Rechenzentrum für Daten erhöht die Antwortzeit um 1-100 ms. Um Querverkehr zu vermeiden, haben wir unseren Rechenzentren Aktiv- und Standby- Tags zugewiesen . Der Balancer (Nginx) ist so konfiguriert, dass der Datenverkehr immer zum aktiven Rechenzentrum fließt. Wenn Tarantool im aktiven Rechenzentrum abstürzt oder nicht mehr verfügbar ist, wechselt es automatisch in die Reserve.
Jede Benutzeranforderung ist wichtig, daher müssen Sie sicherstellen, dass die Verbindungen aufrechterhalten werden. Zu diesem Zweck haben wir ein separates Ansible-Playbook geschrieben, das den Datenverkehr zwischen Rechenzentren umschaltet. Das Umschalten erfolgt über eine Direktive
backup
in der Beschreibung
upstream
für den Server. Die Upstreams werden durch das Limit ausgewählt, das aktiv wird. Der Rest ist vorgeschrieben
backup
: nginx lässt nur dann Verkehr auf sie, wenn nicht alle aktiven verfügbar sind. Beim Ändern der Konfiguration werden offene Verbindungen nicht geschlossen, und neue Anforderungen werden an Router gesendet, die nicht neu gestartet werden müssen.
Was kann getan werden, wenn die Infrastruktur keinen externen Load Balancer hat? Schreiben Sie Ihren eigenen Mini-Balancer in Java, der die Verfügbarkeit von Tarantool-Instanzen überwacht. Dieses separate Subsystem erfordert jedoch auch eine eigene Bereitstellung. Eine andere Möglichkeit besteht darin, einen Schaltmechanismus innerhalb der Router aufzubauen. Eines bleibt unverändert: Der HTTP-Verkehr muss kontrolliert werden.
Wir haben es mit Nginx gelöst, aber die Probleme endeten nicht dort. Das Umschalten muss auch für Master in Replikatsätzen erfolgen. Wie bereits erwähnt, müssen die Daten in der Nähe der Router aufbewahrt werden, um unnötige Netzwerkauslösungen zu vermeiden. Wenn der aktuelle Master (dh eine Speicherinstanz mit Schreibzugriff) abstürzt, funktioniert der Failover-Mechanismus nicht sofort. Während der Cluster eine allgemeine Entscheidung über die Nichtverfügbarkeit der Instanz trifft, sind alle Anforderungen für das betroffene Datenelement fehlerhaft. Um dieses Problem zu lösen, mussten wir auch ein Playbook kompilieren, in dem wir GraphQL-Abfragen an die Cluster-API verwendeten.
Mechanismen zum Ändern von Assistenten und zum Wechseln des Benutzerverkehrs sind die letzten Schlüsselelemente einer Bereitstellung ohne Ausfallzeiten. Ein kontrollierter Load Balancer vermeidet den Verlust von Verbindungen und Fehler bei der Verarbeitung von Benutzeranforderungen sowie den Wechsel von Mastern - Fehler beim Datenzugriff. Zusammen mit dem Update auf den Schultern dieser drei Säulen wird eine fehlertolerante Bereitstellung erzielt, die wir weiter automatisiert haben.
Vermächtnis bekämpfen
Der Kunde hatte bereits einen vorgefertigten Rollout-Mechanismus: Rollen, die Instanzen Schritt für Schritt bereitstellten und konfigurierten. Dann kamen wir mit der magischen Ansible-Patrone ( Github)) das wird alle Probleme lösen. Wir haben nicht nur berücksichtigt, dass die Ansible-Patrone selbst ein Monolith ist - eine große Rolle, deren verschiedene Stufen durch Etiketten und getrennte Aufgaben getrennt sind. Um es vollständig nutzen zu können, musste der Prozess der Bereitstellung des Artefakts geändert, die Verzeichnisstruktur auf den Zielcomputern überarbeitet, der Orchestrator geändert und vieles mehr werden. Ich habe einen Monat damit verbracht, die Bereitstellung mit einer Ansible-Kassette zu verfeinern. Die monolithische Rolle passte einfach nicht in die fertigen Spielbücher. In dieser Form hat es nicht geklappt, und ich wurde von einer gerechten Frage eines Kollegen gestoppt: "Brauchen wir es?"
Wir haben nicht aufgegeben - wir haben die Cluster-Konfiguration von einem einzigen Stück getrennt, nämlich:
- Kombinieren von Speicherinstanzen zu Replikatsätzen;
- Bootstrap Vshard (Cluster Data Sharding-Mechanismus);
- Einrichten eines Failovers (automatisches Umschalten der Master im Falle eines Sturzes).
Dies sind die letzten Phasen der Bereitstellung, in denen alle Instanzen ausgeführt werden. Leider mussten alle anderen Schritte so belassen werden, wie sie sind.
Orchestrator auswählen
Code auf Servern ist nutzlos, wenn er nicht ausgeführt werden kann. Wir benötigen ein Dienstprogramm zum Starten und Stoppen von Tarantool-Instanzen. Die Ansible-Kassette enthält Aufgaben zum Erstellen von Systemctl-Servicedateien und zum Arbeiten mit RPM-Paketen. Die Besonderheit unserer Aufgabe war jedoch das Vorhandensein eines geschlossenen Kreislaufs beim Kunden und das Fehlen von Sudo-Privilegien. Dies bedeutet, dass wir systemctl nicht verwenden konnten.
Bald fanden wir einen Orchestrator, der keine permanenten Root-Rechte benötigt - Supervisord... Ich musste es zuerst auf allen Servern installieren und auch lokale Probleme mit dem Zugriff auf die Socket-Datei lösen. Eine neue ansible Rolle scheint mit Supervisord zu funktionieren: Sie enthält Aufgaben zum Erstellen von Konfigurationsdateien, Aktualisieren der Konfiguration, Starten und Stoppen von Instanzen. Das war genug, um es in Produktion zu bringen.
Aus Versuchsgründen haben wir die Möglichkeit hinzugefügt, die Anwendung mit Supervisord in einer Ansible-Kassette auszuführen. Diese Methode erwies sich als weniger flexibel und wartet noch auf den Abschluss in einem separaten Zweig.
Ladezeiten reduzieren
Unabhängig davon, welchen Orchestrator wir verwenden, können wir keine Stunde auf den Start der Instanz warten. Die Schwelle beträgt 20 Minuten. Wenn die Instanz länger als dieser Schwellenwert nicht verfügbar ist, wird ein automatischer Absturz ausgelöst und im Abrechnungssystem aufgezeichnet. Häufige Unfälle beeinträchtigen die Schlüsselleistung von Teams und können Pläne für die Entwicklung des Systems untergraben. Ich möchte die Prämie wegen des banal notwendigen Einsatzes überhaupt nicht verlieren. Auf jeden Fall müssen Sie innerhalb von 20 Minuten halten.
Fakt: Die Downloadzeit hängt direkt von der Datenmenge ab. Je mehr Sie von den Protokollen in den Arbeitsspeicher erhöhen müssen, desto länger startet die Instanz nach dem Update. Sie müssen auch berücksichtigen, dass Speicherinstanzen auf demselben Computer um Ressourcen konkurrieren: Tarantool verwendet alle Prozessorkerne, um Indizes zu erstellen.
Basierend auf unseren Beobachtungen sollte die Größe
memtx_memory
pro Instanz 40 GB nicht überschreiten. Dieser Wert ist optimal, damit die Wiederherstellung weniger als 20 Minuten dauert. Die Anzahl der Instanzen auf einem Server wird separat berechnet und hängt eng mit der Projektinfrastruktur zusammen.
Wir verbinden Überwachung
Jedes System muss überwacht werden, und Tarantool ist keine Ausnahme. Unsere Überwachung erschien nicht sofort. Ein ganzer Block wurde aufgewendet, um den erforderlichen Zugriff, die Genehmigung und die Einrichtung der Umgebung zu erhalten.
In dem Verfahren der Anwendung der Entwicklung und Schreiben von Spielbücher, modifizierten wir leicht die Metriken Modul ( github ). Jetzt können Sie die Metriken durch den Namen der Instanz teilen, von der sie geflogen sind - globale Beschriftungen. Durch die Integration in Überwachungssysteme hat sich für Clusteranwendungen eine ganze Rolle herausgebildet . Die neue Art von Quantilmetriken ergab sich auch aus der Verallgemeinerung der Anforderungen an unser System.
Jetzt sehen wir die aktuelle Anzahl der Anforderungen an das System, die Größe des verwendeten Speichers, die Replikationsverzögerung und viele andere wichtige Metriken. Darüber hinaus werden sie mit Benachrichtigungen in Chats konfiguriert. Die kritischsten Probleme fallen in das allgemeine System der Autounfälle und haben eine klare SLA zur Beseitigung.
Ein wenig über die Werkzeuge. Eine detaillierte Beschreibung, wo, was und wie man sie bekommt, wird in etcd gesammelt , von wo der Telegraf- Agent seine Anweisungen erhält. JSON-formatierte Metriken werden in InfluxDB gespeichert . Wir haben Grafana als Visualizer verwendet , für den wir sogar ein Vorlagen- Dashboard geschrieben haben . Und schließlich werden Warnungen durch konfiguriert kapacitor .
Dies ist natürlich bei weitem nicht die einzige Option für die Implementierung der Überwachung. Sie können Prometheus verwenden , und Metriken wissen nur, wie Werte im erforderlichen Format angegeben werden. Für Warnungen kann zabbix beispielsweise auch nützlich sein .
Mein Kollege erzählte mir mehr über das Einrichten der Überwachung für Tarantool im Artikel " Überwachen von Tarantool: Protokolle, Metriken und deren Verarbeitung ".
Protokollierung einrichten
Sie können sich nicht auf die Überwachung beschränken. Um ein vollständiges Bild davon zu erhalten, was mit dem System geschieht, sollten alle Diagnosen erfasst werden, einschließlich Protokolle. Je höher die Protokollierungsstufe, desto mehr Debugging-Informationen und desto größer die Protokolldateien.
Der Speicherplatz ist nicht unendlich. Unsere Anwendung kann bei Spitzenlast bis zu 1 TB Protokolle pro Tag generieren. In einer solchen Situation können Sie Festplatten hinzufügen, aber früher oder später wird entweder freier Speicherplatz oder das Projektbudget knapp. Sie möchten aber auch keine spurlosen Debugging-Informationen verlieren! Was zu tun ist?
In einer der Bereitstellungsphasen haben wir die Logrotate- Einstellung hinzugefügt : Halten Sie ein paar 100-MB-Dateien roh und komprimieren Sie ein paar mehr. Im normalen Betrieb reicht dies aus, um innerhalb von 24 Stunden ein lokales Problem zu finden. Protokolle werden in einem streng definierten Verzeichnis im JSON-Format gespeichert. Auf allen Servern wird der Filebeat- Daemon ausgeführt , der Anwendungsprotokolle sammelt und zur Langzeitspeicherung an ElasticSearch sendet . Dieser Ansatz bewahrt Sie vor Festplattenüberlauffehlern und ermöglicht es Ihnen, die Systemleistung bei langfristigen Problemen zu analysieren. Und dieser Ansatz passt gut in die Bereitstellung.
Wir skalieren die Lösung
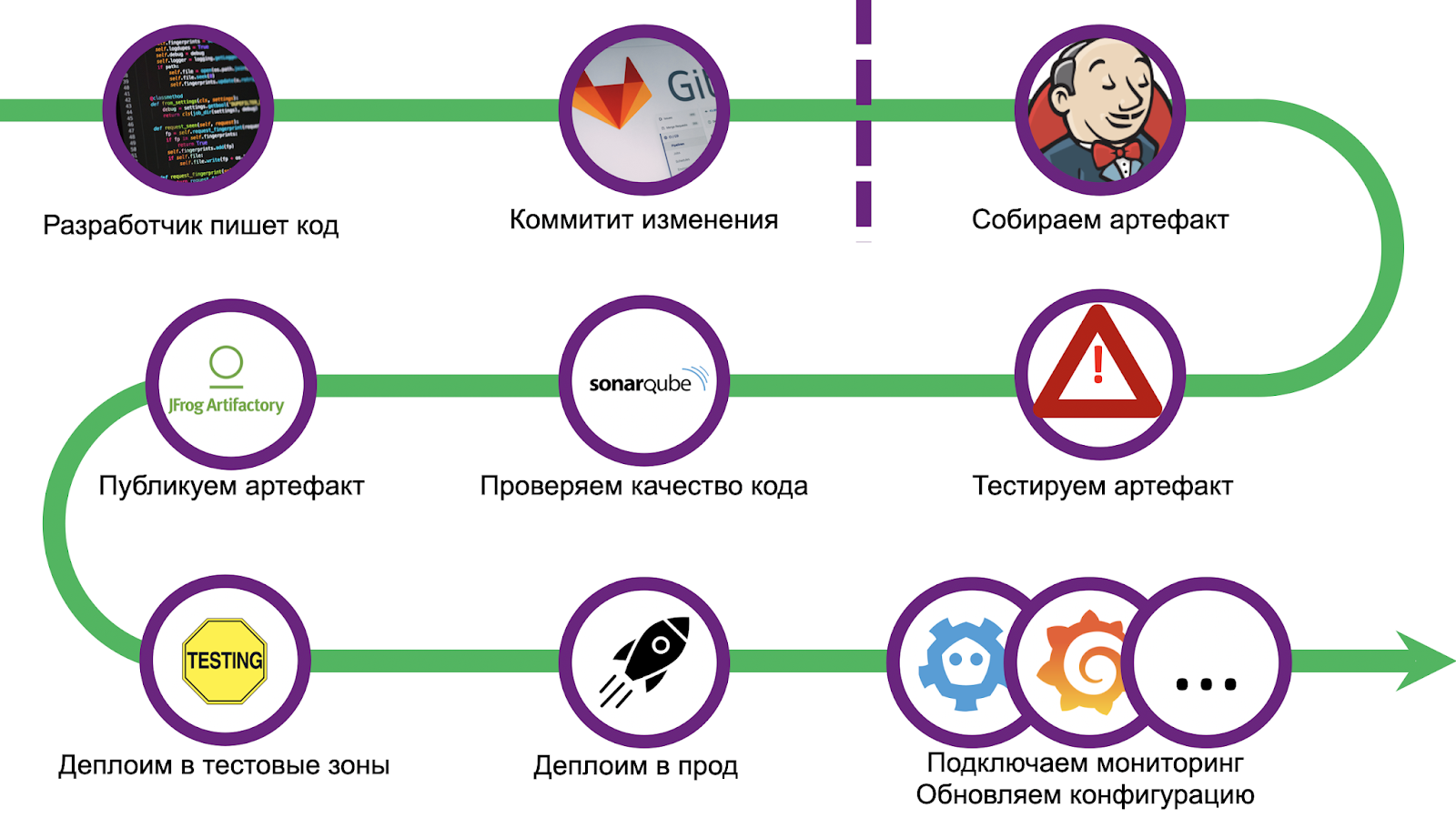
Der Weg war lang und dornig, wir haben eine anständige Anzahl von Zapfen. Um Fehler nicht zu wiederholen, haben wir die Bereitstellung standardisiert und das CI / CD-Bundle Gitlab + Jenkins verwendet. Das Skalieren verursachte auch eine Reihe von Problemen. Das Debuggen der Lösung dauerte mehr als einen Monat. Aber wir haben es geschafft und jetzt sind wir bereit, unsere Erfahrungen mit Ihnen zu teilen. Lass uns durch die Stufen gehen.
Wie kann sichergestellt werden, dass jeder Entwickler schnell eine Lösung für sein Problem finden und diese garantiert an die Produktion liefern kann? Nimm Jenkinsfile von ihm weg! Es ist notwendig, kühne Grenzen zu skizzieren, die über die Unmöglichkeit der Bereitstellung hinausgehen, und den Entwickler auf diesen Weg zu lenken.
Wir haben einen vollwertigen Musterantrag gestellt, der auf die gleiche Weise eingeführt wurde und einen erschöpfenden Ausgangspunkt darstellt. Mit dem Kunden sind wir jedoch noch weiter gegangen: Wir haben ein Dienstprogramm zum automatischen Erstellen einer Vorlage geschrieben, mit der ein Git-Repository und Jenkins-Aufgaben eingerichtet werden. Der Entwickler benötigt weniger als eine Stunde für alles, und das Projekt wird in Produktion sein.
Die Pipeline beginnt mit einer Standard-Codeprüfung und einer Umgebungseinrichtung. Zusätzlich legen wir Inventar für die spätere Bereitstellung in mehreren Funktionstestzonen und Produkten an. Dann kommt die Unit-Test-Phase.
Das Standard-Tarantool-Test-Framework luatest ( github). Sie können sowohl Unit- als auch Integrationstests darin schreiben. Es gibt Zusatzmodule zum Ausführen und Konfigurieren der Tarantool-Kassette . Auch in neueren Versionen können Sie die Abdeckung aktivieren . Wir beginnen es mit einem einfachen Befehl:
.rocks/bin/luatest --coverage
Am Ende der Tests werden die gesammelten Statistiken an SonarQube gesendet - eine Software zur Bewertung der Qualität und Sicherheit des Codes. Im Inneren haben wir das Quality Gate bereits konfiguriert. Jeder Code in der Anwendung, unabhängig von der Sprache (Lua, Python, SQL usw.), wird validiert. Es gibt jedoch keinen integrierten Handler für Lua. Um die Abdeckung im generischen Format darzustellen, haben wir Plugins installiert, die vor Beginn der Tests installiert werden.
tarantoolctl rocks install luacov 0.13.0-1 # coverage
tarantoolctl rocks install luacov-reporters 0.1.0-1 #
Eine einfache Konsolenversion kann folgendermaßen angezeigt werden:
.rocks/bin/luacov -r summary . && cat ./luacov.report.out
Der Bericht für SonarQube wird mit dem folgenden Befehl generiert:
.rocks/bin/luacov -r sonar
Nach der Abdeckung kommt die Linterphase. Wir verwenden Luacheck ( Github ), das auch eines der Tarantool-Plugins ist.
tarantoolctl rocks install luacheck 0.26.0-1
Linter-Ergebnisse werden auch an SonarQube gesendet:
.rocks/bin/luacheck --config .luacheckrc --formatter sonar *.lua
Codeabdeckungsstatistiken und Linters werden zusammen gezählt. Um das Quality Gate zu passieren, müssen alle Bedingungen erfüllt sein:
- Die Codeabdeckung durch Tests muss mindestens 80% betragen.
- Änderungen sollten keine neuen Gerüche einführen;
- Die Gesamtzahl der kritischen Probleme beträgt 0.
- Die Gesamtzahl der nicht kritischen Bestände beträgt weniger als 5.
Nachdem Sie das Quality Gate passiert haben, müssen Sie das Artefakt backen. Da wir beschlossen haben, dass alle Anwendungen Tarantool Cartridge verwenden, verwenden wir Cartridge-Cli ( Github ) zum Erstellen . Dies ist ein kleines Dienstprogramm zum lokalen Ausführen (tatsächlich Entwickeln) von Cluster-Tarantool-Anwendungen. Sie weiß auch, wie Docker-Images und -Archive mit Anwendungscode sowohl lokal als auch in Docker erstellt werden (z. B. wenn Sie ein Artefakt für eine andere Architektur erstellen müssen). Die Montage
tar.gz
wird mit dem folgenden Befehl ausgeführt:
cartridge pack tgz --name <nme> --version <vrsion>
Das resultierende Archiv wird dann in ein beliebiges Repository hochgeladen, z. B. in Artifactory oder Mail.ru Cloud Storage .
Bereitstellung ohne Ausfallzeiten
Der letzte Schritt der Pipeline ist die Bereitstellung selbst. Abhängig vom Status der Änderungen wird das Rollen in verschiedene Testzonen durchgeführt. Für jedes Niesen wird eine Zone zugewiesen: Jeder Push in das Repository startet die gesamte Pipeline. Es gibt auch mehr funktionellen Bereiche , in denen Sie die Interaktion mit externen Systemen, für diesen Test können Sie eine erstellen müssen merge Anfrage im Hauptzweig des Repository. In der Produktion wird das Rollen jedoch erst gestartet, nachdem die Änderungen akzeptiert und die Zusammenführungsschaltfläche gedrückt wurden.
Ich möchte Sie an die Schlüsselelemente unserer Bereitstellung ohne Ausfallzeiten erinnern:
- Update für Rechenzentren;
- Master in Replikatsätzen wechseln;
- Einrichten des Balancers für ein aktives Rechenzentrum.
Beim Upgrade müssen Sie die Kompatibilität von Versionen und Datenschema überwachen. Das Update wird beendet, wenn bei einem der Schritte ein Fehler auftritt.
Das Update kann wie folgt schematisch dargestellt werden:
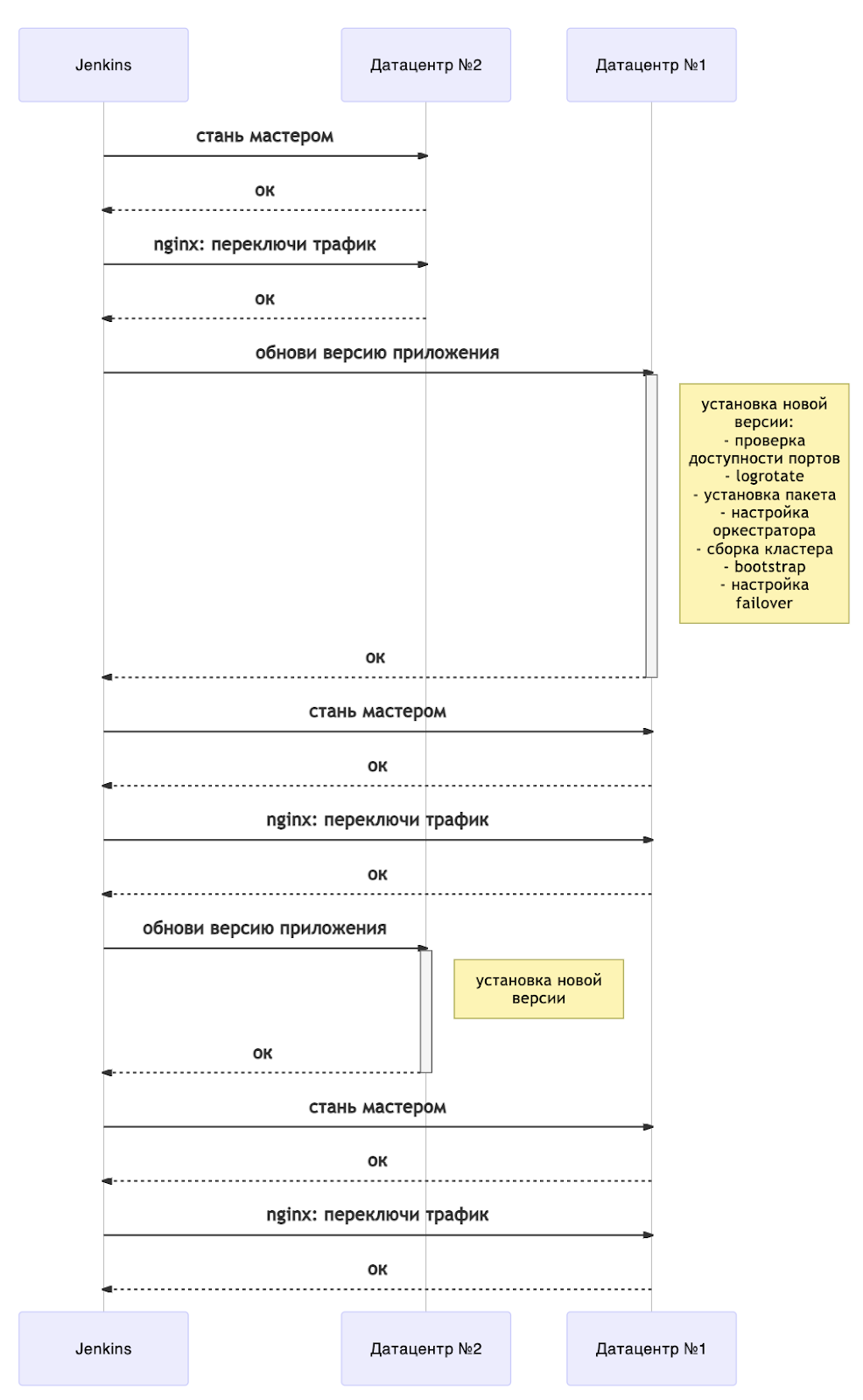
Jetzt wird jedes Update von einem Neustart des Servers begleitet. Um zu verstehen, wann Sie mit der Bereitstellung fortfahren können, haben wir ein separates Playbook, in dem Sie auf den Status der Instanzen warten. Tarantool Cartridge verfügt über eine Statusmaschine, und wir warten auf den Status RolesConfigured. Dies bedeutet, dass die Instanz vollständig konfiguriert ist (und für uns bereit ist, Anforderungen anzunehmen). Wenn die Anwendung zum ersten Mal bereitgestellt wird, müssen Sie auf den Status Nicht konfiguriert warten .
Insgesamt zeigt das Diagramm eine Übersicht über eine Bereitstellung ohne Ausfallzeiten. Es ist leicht auf mehrere Rechenzentren skalierbar. Abhängig von Ihren Anforderungen können Sie alle Backup-Arme sofort nach dem Wechsel der Master (dh zusammen mit dem Rechenzentrum Nr. 1) oder einzeln aktualisieren.
Natürlich konnten wir nicht anders, als unsere Entwicklungen auf Open Source zu bringen. Bisher sind sie in meiner Ansible-Cartridge-Gabel ( opomuc / ansible-cartridge ) verfügbar , es ist jedoch geplant, diese in den Hauptzweig des Haupt-Repositorys zu verschieben.
Ein Beispiel finden Sie hier ( Beispiel ). Damit es ordnungsgemäß funktioniert, muss der Server
supervisord
für den Benutzer konfiguriert sein
tarantool
. Die Konfigurationsbefehle finden Sie hier . Das Archiv mit der Anwendung muss auch eine Binärdatei enthalten
tarantool
.
Die Reihenfolge der Befehle zum Starten der Schulterbereitstellung:
# ( )
ansible-playbook -i hosts.yml playbook.yml \
-b --become-user tarantool \
--extra-vars 'base_dir=/data/tarantool' \
--extra-vars 'cartridge_package_path=./getting-started-app-1.0.0-0.tar.gz' \
--extra-vars 'app_version=1.0.0' \
--tags supervisor
# 1.2.0
# dc2
ansible-playbook -i hosts.yml master.yml \
-b --become-user tarantool \
--extra-vars 'base_dir=/data/tarantool' \
--extra-vars 'cartridge_package_path=./getting-started-app-1.2.0-0.tar.gz' \
--limit dc2
# — dc1
ansible-playbook -i hosts.yml playbook.yml \
-b --become-user tarantool \
--extra-vars 'base_dir=/data/tarantool' \
--extra-vars 'cartridge_package_path=./getting-started-app-1.2.0-0.tar.gz' \
--extra-vars 'app_version=1.2.0' \
--tags supervisor \
--limit dc1
# dc1
ansible-playbook -i hosts.yml master.yml \
-b --become-user tarantool \
--extra-vars 'base_dir=/data/tarantool' \
--extra-vars 'cartridge_package_path=./getting-started-app-1.2.0-0.tar.gz' \
--limit dc1
# — dc2
ansible-playbook -i hosts.yml playbook.yml \
-b --become-user tarantool \
--extra-vars 'base_dir=/data/tarantool' \
--extra-vars 'cartridge_package_path=./getting-started-app-1.2.0-0.tar.gz' \
--extra-vars 'app_version=1.2.0' \
--tags supervisor \
--limit dc2
# , dc1
ansible-playbook -i hosts.yml master.yml \
-b --become-user tarantool \
--extra-vars 'base_dir=/data/tarantool' \
--extra-vars 'cartridge_package_path=./getting-started-app-1.2.0-0.tar.gz' \
--limit dc1
Der Parameter
base_dir
gibt den Pfad zum "Home" -Verzeichnis des Projekts an. Nach dem Rollout werden Unterverzeichnisse erstellt:
<base_dir>/run
- für Steuerbuchsen und PID-Dateien;<base_dir>/data
- für .snap- und .xlog-Dateien sowie für die Konfiguration der Tarantool-Kassette;<base_dir>/conf
- für Anwendungseinstellungen und bestimmte Instanzen;<base_dir>/releases
- für die Versionierung und den Quellcode;<base_dir>/instances
- für Links zur aktuellen Version für jede Instanz der Anwendung.
Der Parameter
cartridge_package_path
spricht für sich selbst, aber es gibt eine Besonderheit:
- Wenn der Pfad mit
http://
oder beginnthttps://
, wird das Artefakt aus dem Netzwerk vorinstalliert (z. B. aus dem daneben angehobenen Artefakt). - In anderen Fällen wird die Datei lokal durchsucht
Der Parameter
app_version
wird für die Versionierung im Ordner verwendet
<base_dir>/releases
. Der Standardwert ist
latest
.
Das Tag
supervisor
bedeutet, dass es als Orchestrator verwendet wird
supervisord
.
Es gibt viele Optionen zum Starten einer Bereitstellung, aber die zuverlässigste ist die gute alte
Makefile
. Der bedingte Befehl
make deploy
kann in jede CI \ CD aufgenommen werden und alles funktioniert genau gleich.
Ergebnis
Das ist alles! Wir haben jetzt eine vorgefertigte Pipeline auf Jenkins, wir haben Zwischenhändler losgeworden, und die Geschwindigkeit der Lieferung von Änderungen ist verrückt geworden. Die Anzahl der Benutzer wächst, in der Produktionsumgebung werden bereits 500 Instanzen ausschließlich mit unserer Lösung bereitgestellt. Wir haben Raum zum Wachsen.
Obwohl der Bereitstellungsprozess selbst alles andere als ideal ist, bietet er eine solide Grundlage für die Weiterentwicklung der DevOps-Prozesse. Sie können unsere Implementierung sicher übernehmen, um das System schnell an die Produktion zu liefern und keine Angst vor häufigen Änderungen zu haben.
Und es wird für uns auch eine Lehre sein, dass es unmöglich ist, einen Monolithen mitzubringen und auf seine weit verbreitete Verwendung zu hoffen: Wir brauchen eine Zerlegung der Spielbücher, die Zuweisung von Rollen für jede Phase der Installation und eine flexible Art der Inventarisierung. Eines Tages werden unsere Entwicklungen in Master aufgenommen und alles wird noch besser!
Links
- Eine Schritt-für-Schritt-Anleitung für Ansible-Kassetten:
- Sie können über Tarantool Cartridge lesen hier .
- Informationen zur Bereitstellung auf Kubernetes:
- Tarantool-Überwachung: Protokolle, Metriken und deren Verarbeitung .
- Wenden Sie sich an den Telegramm-Chat, um Hilfe zu erhalten .