
Hallo Habr! In jüngerer Zeit haben wir über einen offenen Datensatz geschrieben , der von einem Team von Data Science-Absolventen von NUST MISIS und Zavtra.Online (Universitätsabteilung von SkillFactory) als Teil des ersten Bildungsdatatons zusammengestellt wurde. Und heute präsentieren wir Ihnen bis zu 3 Datensätze von Teams, die auch das Finale erreicht haben.
Sie sind alle unterschiedlich: Einige haben den Musikmarkt erforscht, einige haben den Arbeitsmarkt von IT-Spezialisten erforscht und einige haben Hauskatzen untersucht. Jedes dieser Projekte ist in seinem eigenen Bereich relevant und kann verwendet werden, um im üblichen Arbeitsverlauf etwas zu verbessern. Ein Datensatz mit Katzen hilft beispielsweise Richtern bei Ausstellungen. Die Datensätze, die die Schüler sammeln mussten, mussten MVP (Tabelle, JSON oder Verzeichnisstruktur) sein, die Daten mussten bereinigt und analysiert werden. Mal sehen, was sie getan haben.
Datensatz 1: Gleiten Sie mit Data Surfers auf musikalischen Wellen
Ausrichten:
- Plotnikov Kirill - Projektmanager, Entwicklung, Dokumentation.
- Dmitry Tarasov - Entwicklung, Datenerfassung, Dokumentation.
- Shadrin Yaroslav - Entwicklung, Datenerfassung.
- Merzlikin Artyom - Produktmanager, Präsentation.
- Ksenia Kolesnichenko - vorläufige Datenanalyse.
Im Rahmen ihrer Teilnahme am Hackathon schlugen die Teammitglieder verschiedene interessante Ideen vor, aber wir beschlossen, uns auf das Sammeln von Daten über russische Musikkünstler und ihre besten Tracks von Spotify und MusicBrainz zu konzentrieren.
Spotify ist eine Musikplattform, die vor nicht allzu langer Zeit nach Russland gekommen ist, aber bereits aktiv an Popularität auf dem Markt gewinnt. Darüber hinaus bietet Spotify in Bezug auf die Datenanalyse eine sehr praktische API mit der Möglichkeit, eine große Datenmenge abzufragen, einschließlich ihrer eigenen Metriken, wie z. B. "Tanzbarkeit" - eine Punktzahl von 0 bis 1, die beschreibt, wie gut ein Track ist zum tanzen.
MusicBrainzIst eine musikalische Enzyklopädie, die die vollständigsten Informationen über bestehende und bestehende Musikgruppen enthält. Eine Art "musikalische Wikipedia". Wir brauchten Daten aus dieser Ressource, um eine Liste aller Künstler aus Russland zu erhalten.
Künstlerdaten sammeln
Wir haben eine ganze Tabelle mit 14363 eindeutigen Einträgen für verschiedene Künstler zusammengestellt. Um das Navigieren zu vereinfachen, finden Sie unter dem Spoiler eine Beschreibung der Tabellenfelder.
Beschreibung der Tabellenfelder
artist – ;
musicbrainz_id – Musicbrainz;
spotify_id – Spotify, ;
type – , Person, Group, Other, Orchestra, Choir Character;
followers – Spotify;
genres – ;
popularity – Spotify 0 100, .
musicbrainz_id – Musicbrainz;
spotify_id – Spotify, ;
type – , Person, Group, Other, Orchestra, Choir Character;
followers – Spotify;
genres – ;
popularity – Spotify 0 100, .

Beispiel für Record
Fields-Künstler, musicbrainz_id und type werden aus der Musicbrainz-Musikdatenbank abgerufen, da die Möglichkeit besteht, eine Liste der mit einem Land verknüpften Künstler abzurufen. Es gibt zwei Möglichkeiten, diese Daten abzurufen:
- Analysieren Sie den Abschnitt Künstler auf der Seite mit Informationen zu Russland.
- Daten über API abrufen. MusicBrainz API
Dokumentation MusicBrainz API
Dokumentation Suche
Beispiel GET Anfrage an musicbrainz.org
Im Laufe der Arbeit stellte sich heraus, dass die MusicBrainz-API auf eine Anfrage mit dem Parameter Area: Russia nicht ganz richtig reagiert und die Künstler, für die ein Bereich angegeben wurde, z. B. Izhevsk oder Moskva, vor uns verbirgt. Daher wurden die Daten von MusicBrainz vom Parser direkt von der Site übernommen. Unten finden Sie ein Beispiel für die Seite, von der aus die Daten analysiert wurden.
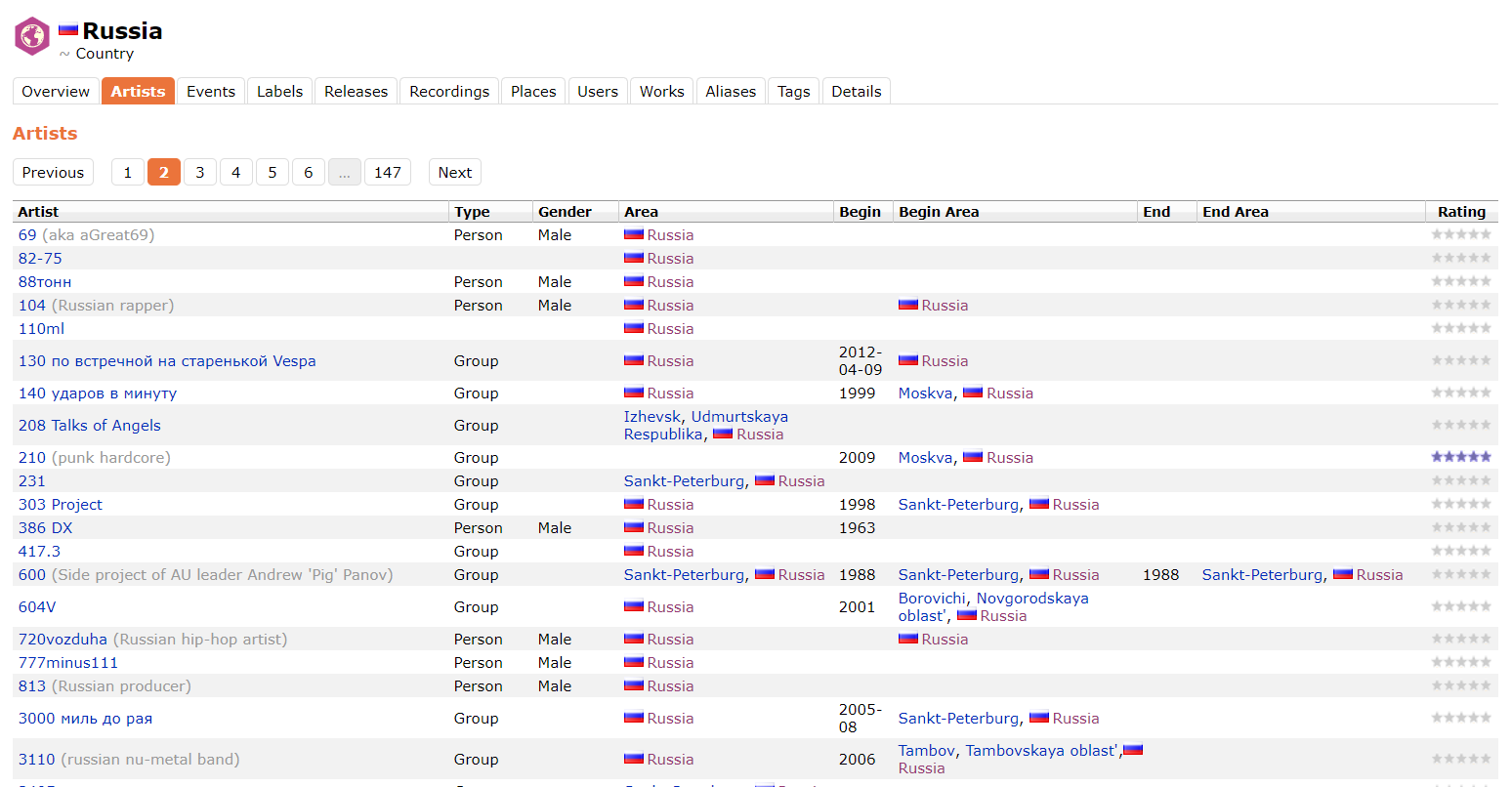
Die erhaltenen Daten über die Künstler von Musicbrainz.
Der Rest der Felder wird als Ergebnis von GET-Anforderungen an den Endpunkt erhalten . Geben Sie beim Senden einer Anforderung den Namen des Interpreten im Wert des Parameters q und den Künstler im Wert des Parameters type an.
Sammeln von Daten über beliebte Titel
Die Tabelle enthält 44473 Datensätze der beliebtesten Titel russischer Künstler, die in der obigen Tabelle aufgeführt sind. Unter dem Spoiler befindet sich eine Beschreibung der Tabellenfelder.
Beschreibung der Tabellenfelder
artist – ;
artist_spotify_id – Spotify ( , spotify_id );
name – ;
spotify_id – Spotify;
duration_ms – ;
explicit – , true false;
popularity – Spotify *;
album_type – , album, single compilation;
album_name – ;
album_spotify_id – Spotify;
release_date – ;
album_popularity – Spotify.
artist_spotify_id – Spotify ( , spotify_id );
name – ;
spotify_id – Spotify;
duration_ms – ;
explicit – , true false;
popularity – Spotify *;
album_type – , album, single compilation;
album_name – ;
album_spotify_id – Spotify;
release_date – ;
album_popularity – Spotify.
Audiofunktionen
key – , , 0 = C, 1 = C♯/D♭, 2 = D ..;
mode – , – 1, – 0;
time_signature – ;
acousticness – 0,0 1,0 , ;
danceability – , 0,0 1,0;
energy – 0,0 1,0;
instrumentalness – , , 0,0 1.0;
liveness – , 0,0 1,0;
loudness – , -60 0 ;
speechiness – , 0,0 1,0;
valence – «», , 0,0 1,0;
tempo – .
mode – , – 1, – 0;
time_signature – ;
acousticness – 0,0 1,0 , ;
danceability – , 0,0 1,0;
energy – 0,0 1,0;
instrumentalness – , , 0,0 1.0;
liveness – , 0,0 1,0;
loudness – , -60 0 ;
speechiness – , 0,0 1,0;
valence – «», , 0,0 1,0;
tempo – .
Weitere Informationen zu den einzelnen Parametern finden Sie hier .

Ein Beispiel für einen Datensatz Die
Felder name, spotify_id, duration_ms, explizit, popularität, album_type, album_name, album_spotify_id, release_date werden mithilfe einer GET-Anforderung
https://api.spotify.com/v1//v1/artists/{id}/top-tracks
unter Angabe der ID der Spotify-ID des zuvor erhaltenen Künstlers und im Wert abgerufen des Marktparameters geben wir RU an. Dokumentation .
Das Feld album_popularity kann abgerufen werden, indem eine GET-Anforderung für gestellt wird
https://api.spotify.com/v1/albums/{id}
, wobei die zuvor erhaltene album_spotify_id als Wert für den Parameter id angegeben wird. Dokumentation .
Als Ergebnis erhalten wir die Datenüber die besten Tracks von Spotify-Künstlern. Jetzt besteht die Herausforderung darin, die Audiofunktionen zu erhalten. Dies kann auf zwei Arten erfolgen:
- Um Daten zu einer Spur abzurufen, müssen Sie eine GET-Anfrage stellen
https://api.spotify.com/v1/audio-features/{id}
und die Spotify-ID als Wert des ID-Parameters angeben. Dokumentation .
- Um Daten über mehrere Spuren gleichzeitig abzurufen, sollten Sie eine GET-Anforderung an senden
https://api.spotify.com/v1/audio-features
und die durch Kommas getrennte Spotify-ID dieser Spuren als Wert für den Parameter ids übergeben. Dokumentation .
Alle Skripte befinden sich im Repository unter diesem Link .
Nach dem Sammeln der Daten haben wir eine vorläufige Analyse durchgeführt, die unten dargestellt wird.
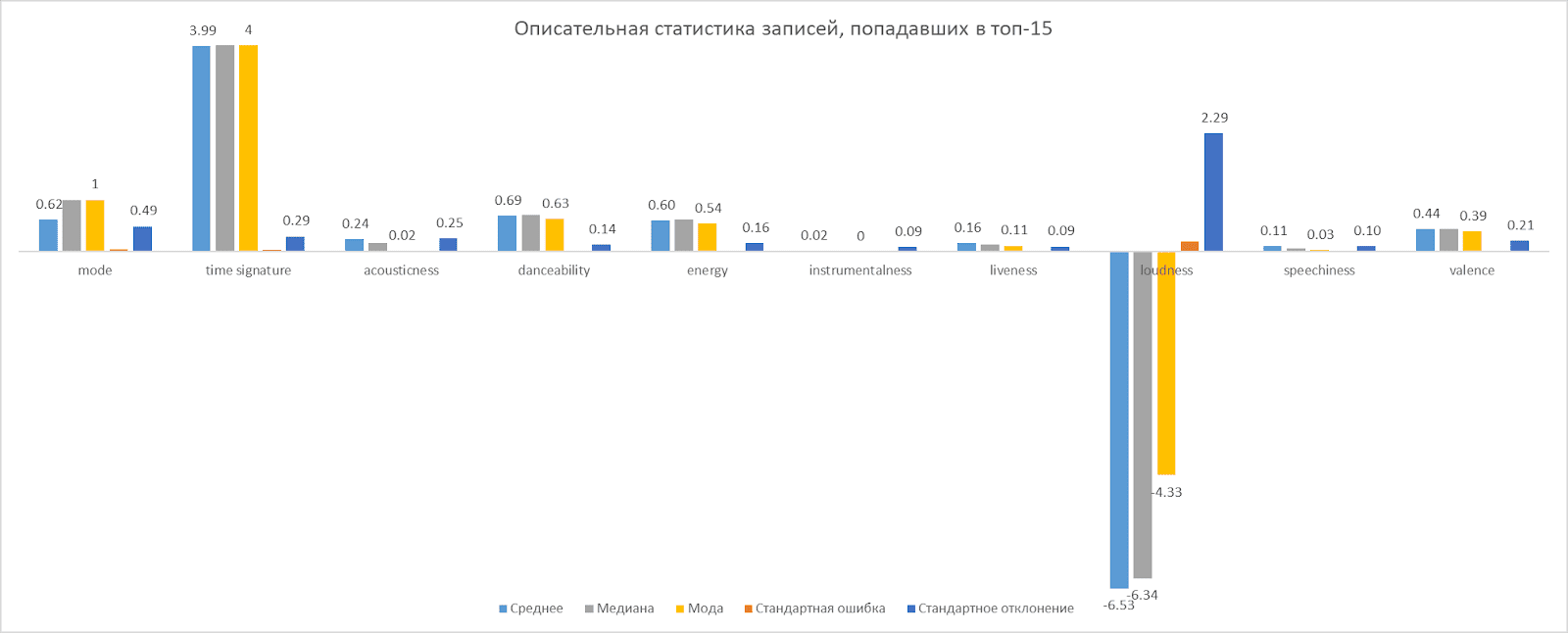
Ergebnis
Infolgedessen konnten wir Daten zu 14363 Künstlern und 44473 Tracks sammeln. Durch die Kombination von Daten aus MusicBrainz und Spotify haben wir den bislang vollständigsten Datensatz aller auf der Spotify-Plattform vertretenen russischen Musikkünstler erhalten.
Mit einem solchen Datensatz können B2B- und B2C-Produkte im Musikbereich erstellt werden. Zum Beispiel Systeme zur Empfehlung von Darstellern an Veranstalter, deren Konzerte organisiert werden können, oder Systeme, die jungen Darstellern helfen, Titel zu schreiben, die mit größerer Wahrscheinlichkeit populär werden. Durch regelmäßiges Auffüllen des Datensatzes mit neuen Daten können Sie auch verschiedene Trends in der Musikindustrie analysieren, z. B. die Bildung und das Wachstum der Popularität bestimmter Trends in der Musik, oder einzelne Interpreten analysieren. Der Datensatz selbst kann auf GitHub angezeigt werden .
Datensatz 2: Wir erforschen den Arbeitsmarkt und identifizieren Schlüsselkompetenzen mit "Hedgehog is clear".
Ausrichten:
- Andrey Pshenichny - Sammeln und Verarbeiten von Daten, Schreiben einer analytischen Notiz zum Datensatz.
- Pavel Kondratenok - Produktmanager, Datenerfassung und Beschreibung seines Prozesses, GitHub.
- Svetlana Shcherbakova - Datenerfassung und -verarbeitung.
- Evseeva Oksana - Vorbereitung der Abschlusspräsentation des Projekts.
- Elfimova Anna - Projektmanagerin.
Für unseren Datensatz haben wir die Idee gewählt, für Oktober 2020 Daten zu offenen Stellen in Russland aus dem IT- und Telekommunikationsbereich von der Website hh.ru zu sammeln.
Fähigkeitsdatenerfassung
Die wichtigste Metrik für alle Benutzerkategorien sind Schlüsselkompetenzen. Bei der Analyse sind wir jedoch auf Schwierigkeiten gestoßen: Beim Ausfüllen von Stellenangeboten wählen die Personalabteilungen Schlüsselqualifikationen aus der Liste aus und können sie auch manuell eingeben. Daher wurde eine große Anzahl doppelter und falscher Fähigkeiten in unseren Datensatz aufgenommen (z. B.) fanden wir den Namen der Schlüsselfertigkeit "0.4 Kb"). Es gibt noch eine weitere Schwierigkeit, die Probleme bei der Analyse des resultierenden Datensatzes verursacht hat: Nur etwa die Hälfte der offenen Stellen enthält Daten zu Gehältern, aber wir können Durchschnittsgehaltsindikatoren aus einer anderen Ressource verwenden (z. B. aus den Ressourcen My Circle oder Habr.Career).
Wir haben mit der Datenerfassung und eingehenden Analyse begonnen. Als Nächstes haben wir die Daten abgetastet, dh Features (Features oder mit anderen Worten Prädiktoren) und Objekte ausgewählt, wobei ihre Relevanz für die Zwecke von Data Mining, Qualität und technische Einschränkungen (Volumen und Typ) berücksichtigt wurden.
Hier hat uns die Analyse der Häufigkeit der Erwähnung von Fähigkeiten in den Tags der erforderlichen Fähigkeiten in der Stellenbeschreibung geholfen, welche Merkmale der Vakanz die vorgeschlagene Belohnung beeinflussen. Gleichzeitig wurden 8915 Schlüsselkompetenzen identifiziert. Unten finden Sie eine Tabelle mit den 10 wichtigsten Fähigkeiten und wie oft sie erwähnt werden.
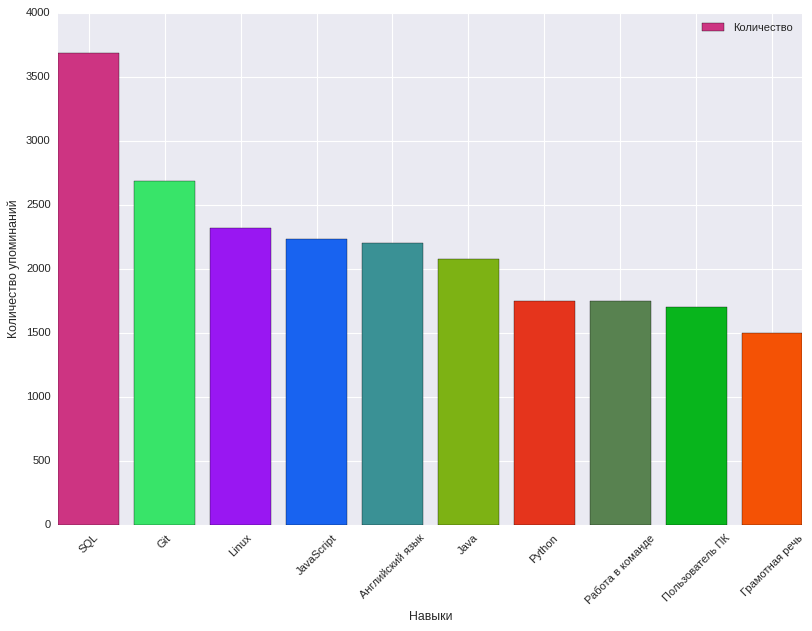
Die häufigsten Schlüsselkompetenzen bei IT-Stellenangeboten, Telecom
Data, wurden mithilfe ihrer API von der hh.ru-Website abgerufen. Den Code zum Hochladen von Daten finden Sie hier . Wir haben die Funktionen, die wir für den Datensatz benötigen, manuell ausgewählt. Die Struktur und Art der gesammelten Daten können der Beschreibung der Dokumentation für den Datensatz entnommen werden.
Nach diesen Manipulationen haben wir einen Datensatz mit einer Größe von 34.513 Zeilen erhalten. Unten sehen Sie ein Beispiel der gesammelten Daten und den Link .

Beispieldaten gesammelt
Ergebnis
Das Ergebnis ist ein Datensatz, mit dem Sie herausfinden können, welche Fähigkeiten bei IT-Spezialisten in verschiedenen Bereichen am gefragtesten sind, und der für Arbeitssuchende (sowohl Anfänger als auch erfahrene), Arbeitgeber, Personalfachleute, Bildungseinrichtungen und Organisatoren nützlich sein kann von Konferenzen. Bei der Datenerfassung gab es auch Schwierigkeiten: Es gibt zu viele Anzeichen und sie sind in einer niedrig formalisierten Sprache verfasst (Beschreibung der Fähigkeiten des Bewerbers), die Hälfte der offenen Stellen hat keine offenen Daten zu Gehältern. Der Datensatz selbst kann auf GitHub angezeigt werden .
Datensatz 3: Genießen Sie die Vielfalt der Katzen mit Team AA
Ausrichten:
- Evgeny Ivanov - Web Scraping Entwicklung.
- Sergey Gurylev - Produktmanager, Beschreibung des Entwicklungsprozesses, GitHub.
- Yulia Cherganova - Vorbereitung der Projektpräsentation, Datenanalyse.
- Elena Tereshchenko - Datenaufbereitung, Datenanalyse.
- Yuri Kotelenko - Projektmanager, Dokumentation, Projektpräsentation.
Ein Datensatz für Katzen? Warum nicht, dachten wir. Unser Catset enthält Beispielbilder von Katzen verschiedener Rassen.
Katzendaten sammeln
Ursprünglich haben wir catfishes.ru ausgewählt , um Daten zu sammeln . Es bietet alle Vorteile, die wir benötigen: Es ist eine kostenlose Quelle mit einer einfachen HTML-Struktur und qualitativ hochwertigen Bildern. Trotz der Vorteile dieser Website hatte sie einen erheblichen Nachteil - eine kleine Anzahl von Fotos im Allgemeinen (etwa 500 für alle Rassen) und eine kleine Anzahl von Bildern jeder Rasse. Deshalb haben wir uns für eine andere Seite entschieden - lapkins.ru .

Aufgrund der etwas komplexeren HTML-Struktur war das Scraping der zweiten Site etwas schwieriger als das der ersten, aber die HTML-Struktur war leicht herauszufinden. Infolgedessen konnten wir bereits 2600 Fotos aller Rassen vom zweiten Standort sammeln.
Wir mussten nicht einmal die Daten filtern, da die Fotos der Katzen auf der Website von guter Qualität sind und den Rassen entsprechen.
Um Bilder von der Website zu sammeln, haben wir einen Web-Scraper geschrieben. Die Seite enthält eine Seite lapkins.ru/cat mit einer Liste aller Rassen. Nach dem Parsen dieser Seite haben wir die Namen aller Rassen und Links zu der Seite für jede Rasse erhalten. Nachdem wir jeden der Felsen iterativ durchlaufen hatten, erhielten wir alle Bilder und legten sie in die entsprechenden Ordner. Der Scraper-Code wurde in Python mithilfe der folgenden Bibliotheken implementiert:
- urllib : Funktionen zum Arbeiten mit URLs;
- html : Funktionen zur Verarbeitung von XML und HTML;
- Shutil : Funktionen auf hoher Ebene für die Verarbeitung von Dateien, Dateigruppen und Ordnern;
- Betriebssystem : Funktionen zum Arbeiten mit dem Betriebssystem.
Wir haben XPath verwendet, um mit Tags zu arbeiten.
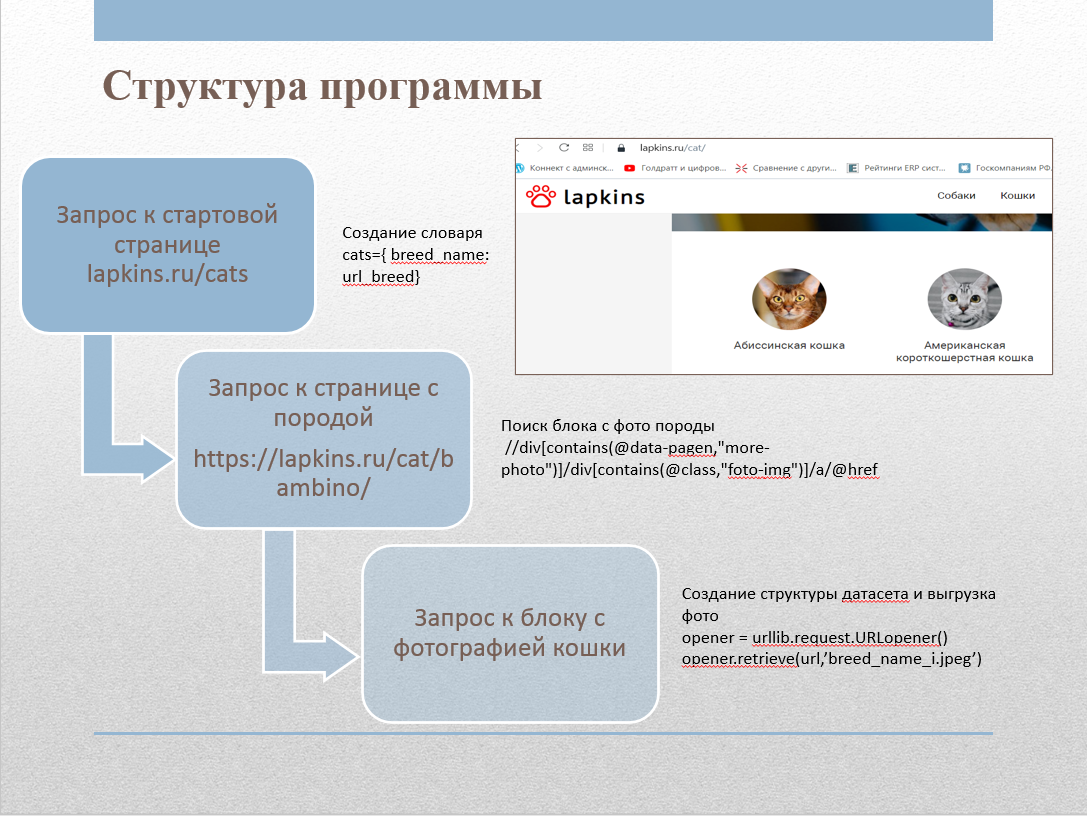
Das Verzeichnis Cats_lapkins enthält Ordner, deren Namen den Namen von Katzenrassen entsprechen. Das Repository enthält 64 Verzeichnisse für jede Rasse. Insgesamt enthält der Datensatz 2600 Bilder. Alle Bilder sind im JPG-Format. Dateinamenformat: Zum Beispiel "Abessinierkatze 2.jpg", zuerst der Name der Rasse, dann die Nummer - die Seriennummer der Probe.

Ergebnis
Ein solcher Datensatz kann beispielsweise verwendet werden, um Modelle zu trainieren, die Hauskatzen nach Rasse klassifizieren. Die gesammelten Daten können für folgende Zwecke verwendet werden: Bestimmung der Merkmale der Pflege einer Katze, Auswahl einer geeigneten Diät für Katzen bestimmter Rassen sowie Optimierung der primären Identifizierung der Rasse auf Ausstellungen und bei der Beurteilung. Cotoset kann auch von Unternehmen verwendet werden - Tierkliniken und Futtermittelherstellern. Das Cotoset selbst ist auf GitHub frei verfügbar .
Nachwort
Basierend auf den Ergebnissen der Daten erhielten unsere Studenten den ersten Fall in ihrem Portfolio für Datenwissenschaftler und Feedback zu Arbeiten von Mentoren von Unternehmen wie Huawei, Kaspersky Lab, Align Technology, Auriga, Intellivision, Wrike und Merlin AI. Dataton war auch insofern nützlich, als er sofort die Profil-Hard- und Soft-Skills pumpte, die zukünftige Datenwissenschaftler benötigen, wenn sie bereits in echten Teams arbeiten werden. Es ist auch eine gute Gelegenheit für den gegenseitigen "Wissensaustausch", da jeder Schüler einen anderen Hintergrund und dementsprechend seine eigene Sicht auf das Problem und seine mögliche Lösung hat. Wir können mit Zuversicht sagen, dass ohne eine solche praktische Arbeit, ähnlich wie bei einigen bereits bestehenden Geschäftsaufgaben, die Ausbildung von Spezialisten in der modernen Welt einfach undenkbar ist.
Weitere Informationen zu unserem Masterstudiengang finden Sie auf der Website data.misis.ru und im Telegrammkanal .
Nun, und natürlich kein einziger Master-Abschluss! Wenn Sie mehr über Data Science , maschinelles Lernen und Deep Learning erfahren möchten - schauen Sie sich unsere entsprechenden Kurse an, es wird schwierig, aber aufregend. Der HABR-Gutscheincode hilft Ihnen dabei, neue Dinge zu lernen, indem er 10% zum Rabatt auf das Banner hinzufügt.

Andere Berufe und Kurse