Wie wir parallele Universen für unsere (und Ihre) CI / CD-Pipeline in Octopod erstellt haben

Hallo Habr! Mein Name ist Denis und ich werde Ihnen sagen, wie es uns vorgeschlagen wurde, eine technische Lösung zur Optimierung des Entwicklungsprozesses und der Qualitätssicherung in unserem Typeable zu entwickeln. Es begann mit dem allgemeinen Gefühl, dass wir alles richtig machten, aber es wäre immer noch möglich, schneller und effizienter voranzukommen - neue Aufgaben anzunehmen, zu testen, weniger zu synchronisieren. All dies führte uns zu Diskussionen und Experimenten, die zu unserer Open-Source-Lösung führten, die ich im Folgenden beschreiben werde und die Ihnen jetzt zur Verfügung steht.
Lassen Sie uns jedoch nicht der Lok vorauslaufen, sondern von vorne beginnen und im Detail verstehen, wovon ich spreche. Stellen wir uns eine ziemlich normale Situation vor - ein Projekt mit einer dreistufigen Architektur (Speicher, Backend, Frontend). Es gibt einen Entwicklungsprozess und einen Qualitätssicherungsprozess, in denen mehrere Umgebungen (häufig als Konturen bezeichnet) zum Testen vorhanden sind:
- Die Produktion ist die Hauptarbeitsumgebung, in die Systembenutzer gehen.
- Pre-Production – - (, production, ; RC), production, production . Pre-production – , Production .
- Staging – , , , Production, .
Mit der Vorproduktion ist alles ganz klar: Release-Kandidaten gehen konsequent dorthin, die Release-Historie ist dieselbe wie in der Produktion . Es gibt Nuancen bei der Inszenierung :
- ORGANISATORISCH. Das Testen kritischer Teile kann eine Verzögerung beim Veröffentlichen neuer Änderungen erfordern. Änderungen können auf unvorhersehbare Weise interagieren. Das Verfolgen von Fehlern wird aufgrund der großen Aktivität auf dem Server schwierig. Manchmal gibt es Verwirrung darüber, welche Version implementiert ist. Es ist manchmal unklar, welche der akkumulierten Änderungen das Problem verursacht haben.
- . : production , «». staging , . . : , . , QA production , .
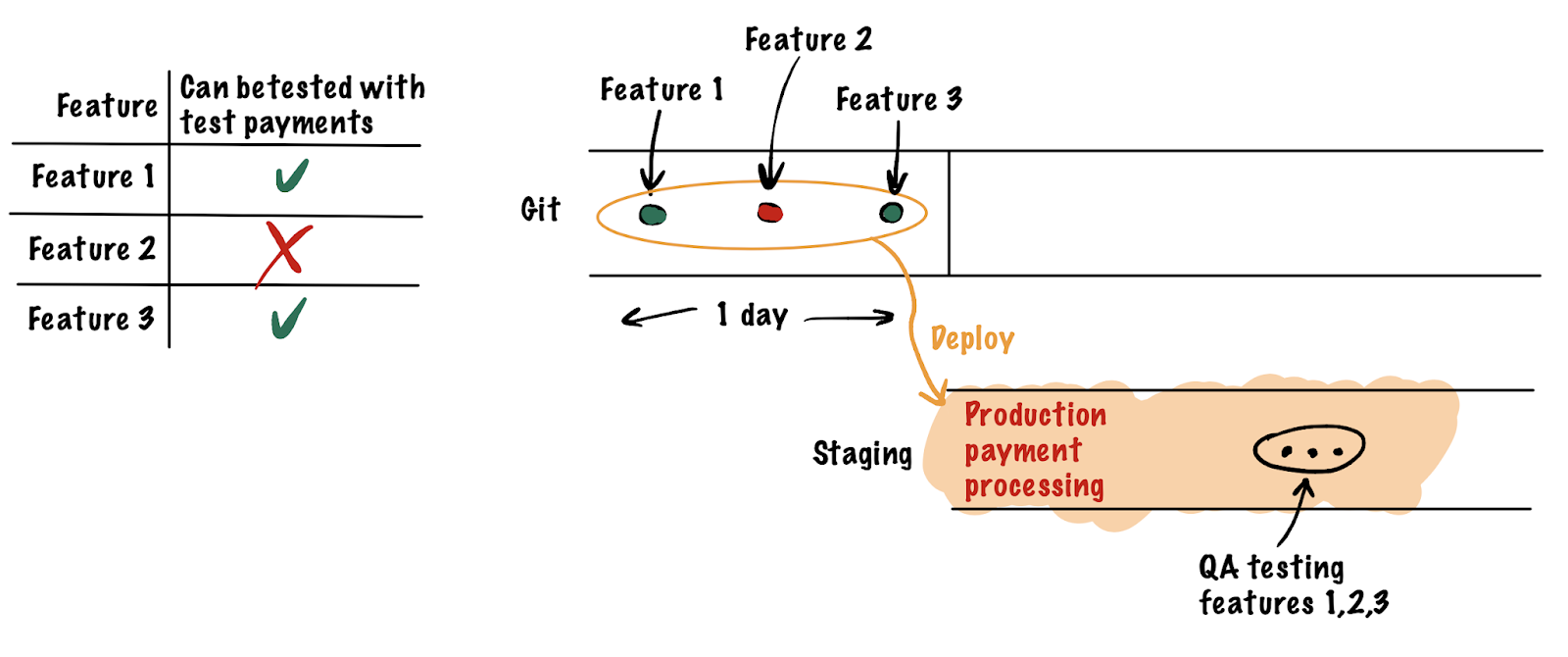
- .
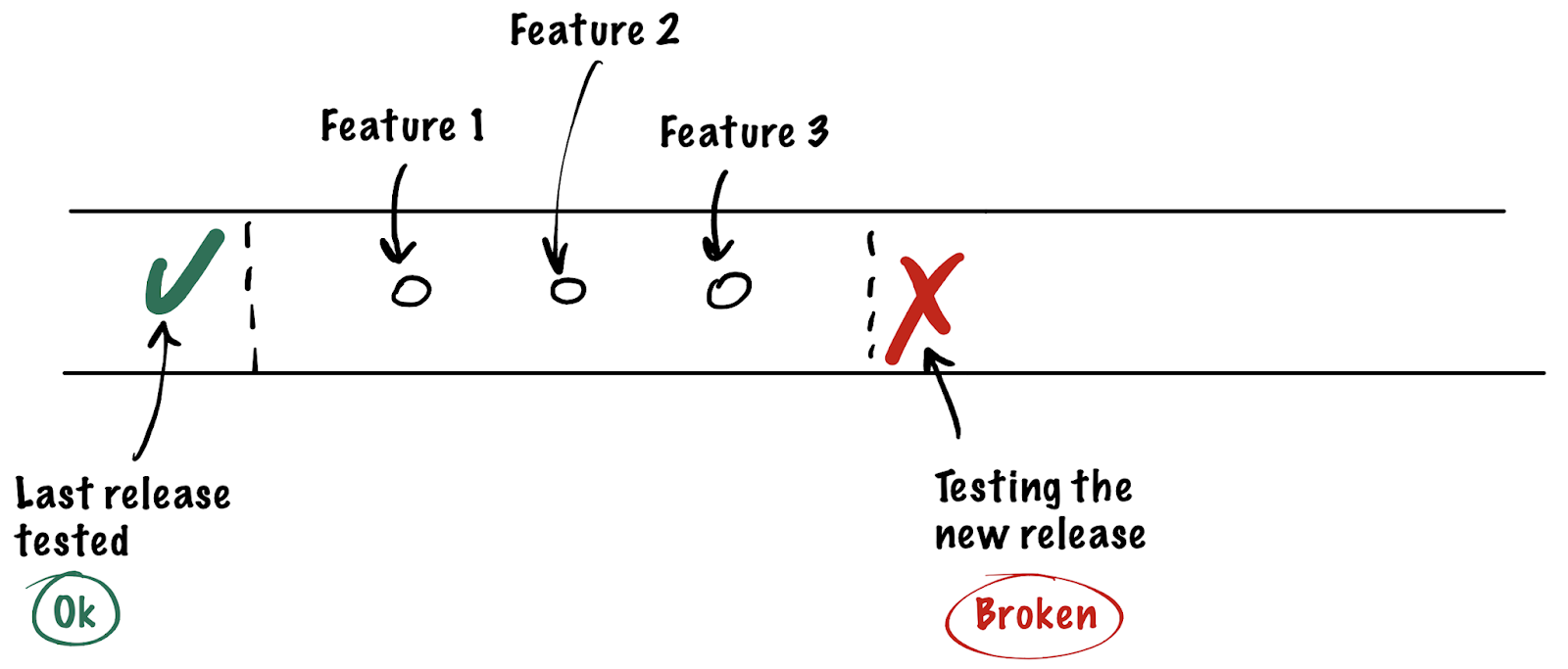
- . . -. , . , . , .
- . - , , , , . , , , . , . production , time-to-production time-to-market .
Jeder dieser Punkte wird auf die eine oder andere Weise gelöst, aber all dies führte zu der Frage, ob es möglich sein wird, unser Leben zu vereinfachen, wenn wir uns vom Konzept eines Staging-Standes zu ihrer dynamischen Zahl entfernen. Ähnlich wie wir CI-Prüfungen für jeden Zweig in Git haben, können wir QA-Checkout-Stände für jeden Zweig erhalten. Das einzige, was uns von einem solchen Schritt abhält, ist der Mangel an Infrastruktur und Werkzeugen. Um eine Funktion zu akzeptieren, wird grob gesagt eine separate Bereitstellung mit einem dedizierten Domänennamen erstellt. Die Qualitätssicherung testet sie, akzeptiert sie oder gibt sie zur Überarbeitung zurück. Etwas wie das:

Mit diesem Ansatz wird das Problem verschiedener Umgebungen auf natürliche Weise gelöst:

Bezeichnenderweise wurden die Meinungen im Team nach der Diskussion in "Lass es uns versuchen, ich will besser als jetzt" und "Es scheint so normal, ich sehe keine monströsen Probleme" unterteilt, aber wir werden später darauf zurückkommen.
Unser Weg zur Lösung
Das erste, was wir versuchten, war ein Prototyp, der von unseren DevOps erstellt wurde: eine Kombination aus Docker-Compose (Orchestrierung), Rundeck (Management) und Portainer (Introspektion), mit der wir die allgemeine Richtung des Denkens und der Herangehensweise testen konnten. Es gab Probleme mit der Bequemlichkeit:
- Jede Änderung erforderte Zugriff auf den Code und das Rundeck, die die Entwickler hatten, aber nicht hatten, zum Beispiel die QS-Ingenieure.
- Dies wurde auf einer großen Maschine ausgelöst, die bald unzureichend wurde, und für den nächsten Schritt wurden bereits Kubernetes oder ähnliches benötigt.
- Portainer gab keine Informationen über den Status einer bestimmten Inszenierung, sondern über eine Reihe von Containern.
- Ich musste die Datei ständig mit der Beschreibung der Stufen zusammenführen, die alten Stände mussten gelöscht werden.
Trotz aller Nachteile und mit einigen Unannehmlichkeiten bei der Bedienung kam der Ansatz ins Spiel und begann, Zeit und Mühe des Projektteams zu sparen. Die Hypothese wurde getestet, und wir beschlossen, alles gleich zu machen, aber auf eine klopfende Art und Weise. Um das Ziel der Optimierung des Entwicklungsprozesses zu erreichen, haben wir die Anforderungen für einen neuen gesammelt und verstanden, was wir wollten:
- Verwenden Sie Kubernetes, um auf eine beliebige Anzahl von Staging-Umgebungen zu skalieren, und verfügen Sie über einen Standardsatz von Tools für moderne DevOps.
- Eine Lösung, die sich leicht in die Infrastruktur integrieren lässt, die bereits Kubernetes verwendet.
- , Product QA-. , . – .
- , CI/CD , . , Github Actions CI.
- , DevOps .
- , , / - .
- Vollständige Informationen und eine Liste von Aktionen sollten Superbenutzern in der Person von DevOps-Ingenieuren und Teamleitern zur Verfügung stehen.
Und wir haben angefangen, Octopod zu entwickeln . Der Name war eine Verwirrung mehrerer Gedanken über K8S, mit denen wir alles im Projekt orchestriert haben: Viele Projekte in diesem Ökosystem spiegeln die Meeresästhetik und -themen wider, und wir stellten uns eine Art Tintenfisch vor, der viele Unterwasserbehälter mit Tentakeln orchestriert. Außerdem ist der Pod eine der Gründungseinheiten in Kubernetes.
Auf dem technischen Stack ist Octopod Haskell, Rust, FRP, Compilation nach JS, Nix. Aber im Allgemeinen geht es in der Geschichte nicht darum, deshalb werde ich nicht näher darauf eingehen.
Das neue Modell wurde in unserem Unternehmen als Multi-Staging bekannt. Das gleichzeitige Betreiben mehrerer Staging-Umgebungen ist vergleichbar mit dem Reisen über parallele Universen und Dimensionen in Science-Fiction (und nicht so sehr). Darin ähneln sich die Universen mit Ausnahme eines kleinen Details: Irgendwo haben verschiedene Seiten den Krieg gewonnen, irgendwo hat eine Kulturrevolution stattgefunden, irgendwo ein technologischer Durchbruch. Die Prämisse mag klein sein, aber zu welchen Änderungen kann sie führen! In unseren Prozessen ist diese Voraussetzung der Inhalt jedes einzelnen Feature-Zweigs.
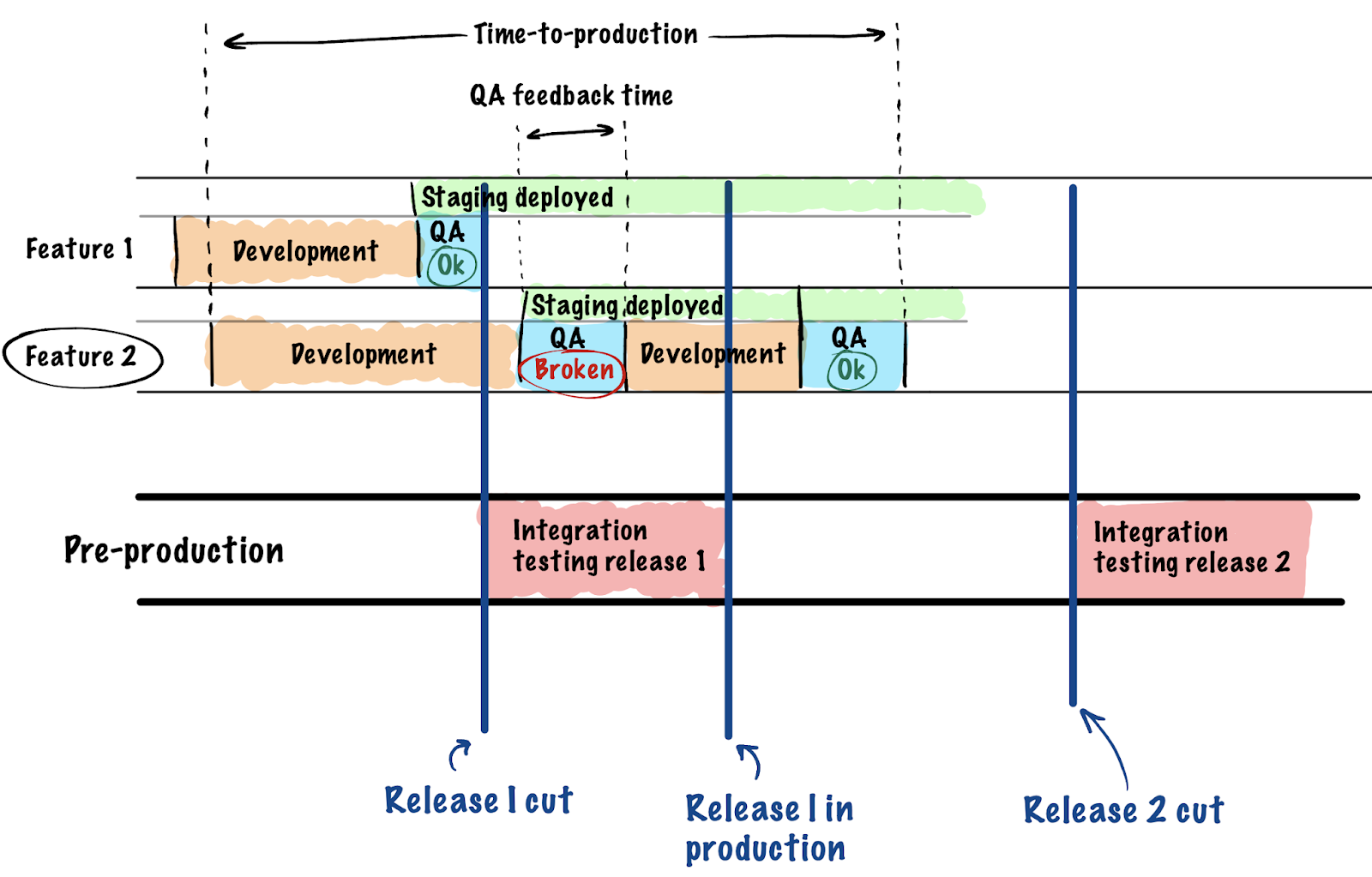
Unsere Implementierung erfolgte in mehreren Phasen und begann mit einem Projekt. Dies umfasst das Anpassen der Projekt-Orchestrierung von DevOps-Seite und das Reorganisieren des Test- und Kommunikationsprozesses vom Projektmanager.
Infolge einer Reihe von Iterationen wurden einige Funktionen von Octopod selbst entfernt oder bis zur Unkenntlichkeit geändert. In der ersten Version hatten wir beispielsweise eine Seite mit einem Bereitstellungsprotokoll für jeden Schaltkreis, aber hier ist das Pech: Nicht jedes Team akzeptiert, dass Anmeldeinformationen über diese Protokolle an alle an der Entwicklung beteiligten Mitarbeiter weitergeleitet werden können. Aus diesem Grund haben wir uns entschlossen, diese Funktionalität zu entfernen , und sie dann in einer anderen Form zurückgegeben. Jetzt ist sie anpassbar (und daher optional) und wird durch die Integration in das kubernetes-Dashboard implementiert .
Es gibt noch andere Punkte: Mit dem neuen Ansatz verwenden wir mehr Rechenressourcen, Festplatten und Domänennamen, um die Infrastruktur zu unterstützen, was die Frage der Kostenoptimierung aufwirft. Wenn Sie dies mit DevOps-Feinheiten kombinieren, wird das Material in einem separaten Beitrag oder sogar in zwei eingetippt, sodass ich hier nicht weiter darauf eingehen werde.
Parallel zur Lösung neu auftretender Probleme bei einem Projekt haben wir begonnen, diese Lösung in ein anderes zu integrieren, als wir das Interesse eines anderen Teams sahen. Dadurch konnten wir sicherstellen, dass unsere Lösung anpassbar und flexibel genug für die Anforderungen verschiedener Projekte war. Derzeit ist Octopod in unserem Land seit drei Monaten weit verbreitet.
Ergebend
Infolgedessen werden das System und die Prozesse in mehreren Projekten implementiert, es besteht Interesse von einem weiteren. Interessanterweise würden auch diejenigen Kollegen, die jetzt keine Probleme mit dem alten System sahen, nicht mehr darauf zurückgreifen wollen. Es stellte sich heraus, dass wir für einige Probleme gelöst haben, von denen sie nicht einmal wussten!
Die schwierigste war wie üblich die erste Implementierung - die meisten technischen Probleme und Probleme waren damit verbunden. Das Feedback der Benutzer ermöglichte es, besser zu verstehen, was überhaupt verbessert werden muss. In den neuesten Versionen sieht die Benutzeroberfläche und die Arbeit mit Octopod folgendermaßen aus:
Für uns ist Octopod eine Antwort auf eine Verfahrensfrage geworden, und ich würde den aktuellen Stand als eindeutigen Erfolg bezeichnen - Flexibilität und Bequemlichkeit haben deutlich zugenommen. Es gibt immer noch keine vollständig gelösten Probleme: Wir ziehen die Autorisierung von Octopod selbst im Cluster für mehrere Projekte nach Atlassian oauth, und dieser Prozess wird verzögert. Dies ist jedoch nichts weiter als eine Frage der Zeit, technisch ist das Problem bereits in erster Näherung gelöst.
Open Source
Wir hoffen, dass Octopod nicht nur für uns nützlich sein wird. Wir freuen uns über Vorschläge, Pull-Anfragen und Informationen darüber, wie Sie ähnliche Prozesse optimieren. Wenn das Projekt für das Publikum von Interesse ist, werden wir mit uns über die Merkmale der Orchestrierung und des Betriebs schreiben.
Der gesamte Quellcode mit Konfigurationsbeispielen und Dokumentation ist im Repository von Github verfügbar .