
Es gibt bereits einige Veröffentlichungen zum Apple Matrix Coprozessor (AMX). Aber die meisten sind nicht allen klar. Ich werde versuchen, die Nuancen des Coprozessors in verständlicher Sprache zu erklären.
Warum spricht Apple nicht zu viel über diesen Coprozessor? Was ist daran so geheim? Und wenn Sie über die Neural Engine in SoC M1 gelesen haben, fällt es Ihnen möglicherweise schwer zu verstehen, was an AMX so ungewöhnlich ist.
Aber zuerst wollen wir uns an die grundlegenden Dinge erinnern ( wenn Sie genau wissen, was Matrizen sind, und ich bin sicher, dass es die meisten solcher Leser auf Habré gibt, können Sie den ersten Abschnitt überspringen, - ca. Übersetzung ).
Was ist eine Matrix?
Einfach ausgedrückt ist dies eine Tabelle mit Zahlen. Wenn Sie in Microsoft Excel gearbeitet haben, bedeutet dies, dass Sie sich mit der Ähnlichkeit von Matrizen befasst haben. Der Hauptunterschied zwischen Matrizen und gewöhnlichen Tabellen mit Zahlen liegt in den Operationen, die mit ihnen ausgeführt werden können, sowie in ihrem spezifischen Wesen. Die Matrix kann in vielen verschiedenen Formen betrachtet werden. Als Zeichenfolgen handelt es sich beispielsweise um einen Zeilenvektor. Oder als Spalte ist es logischerweise ein Spaltenvektor.

Wir können Matrizen addieren, subtrahieren, skalieren und multiplizieren. Addition ist die einfachste Operation. Sie fügen einfach jeden Artikel einzeln hinzu. Die Multiplikation ist etwas kniffliger. Hier ist ein einfaches Beispiel.
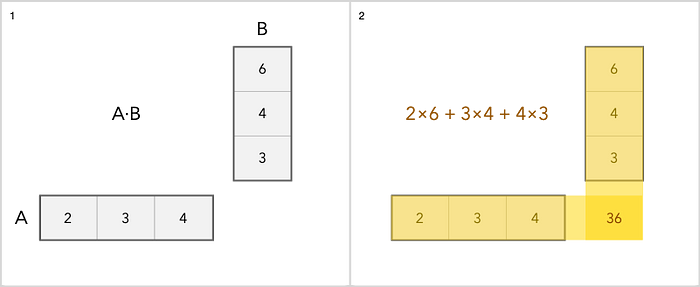
Wie bei anderen Operationen mit Matrizen können Sie hier darüber lesen .
Warum reden wir überhaupt über Matrizen?
Tatsache ist, dass sie häufig verwendet werden in:
• Bildverarbeitung.
• Maschinelles Lernen.
• Handschrift und Spracherkennung.
• Kompression.
• Arbeiten Sie mit Audio und Video.
Wenn es um maschinelles Lernen geht, erfordert diese Technologie leistungsstarke Prozessoren. Und nur ein paar Kerne zum Chip hinzuzufügen, ist keine Option. Jetzt werden die Kernel für bestimmte Aufgaben "geschärft".

Die Anzahl der Transistoren im Prozessor ist begrenzt, so dass auch die Anzahl der Aufgaben / Module, die dem Chip hinzugefügt werden können, begrenzt ist. Im Allgemeinen können Sie dem Prozessor einfach weitere Kerne hinzufügen, dies beschleunigt jedoch nur Standardberechnungen, die bereits schnell sind. Daher entschied sich Apple für einen anderen Weg und hob Module für Bildverarbeitung, Videodecodierung und maschinelles Lernen hervor. Diese Module sind Coprozessoren und Beschleuniger.
Was ist der Unterschied zwischen dem Apple Matrix Coprozessor und der Neural Engine?
Wenn Sie an der Neural Engine interessiert waren, wissen Sie wahrscheinlich, dass sie auch Matrixoperationen für die Arbeit mit Problemen des maschinellen Lernens ausführt. Aber wenn ja, warum brauchten Sie dann auch den Matrix-Coprozessor? Vielleicht ist es das gleiche? Verwechsle ich etwas? Lassen Sie mich die Situation klären und Ihnen den Unterschied erklären und erklären, warum beide Technologien benötigt werden.
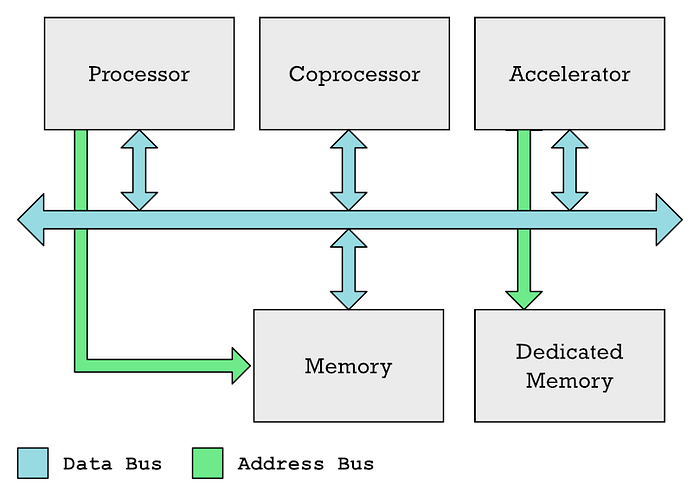
Die Hauptverarbeitungseinheit (CPU), Coprozessoren und Beschleuniger können normalerweise über einen gemeinsamen Datenbus kommunizieren. Die CPU steuert normalerweise den Zugriff auf den Speicher, während ein Beschleuniger wie eine GPU häufig über einen eigenen dedizierten Speicher verfügt.
Ich gebe zu, dass ich in meinen vorherigen Artikeln die Begriffe "Coprozessor" und "Beschleuniger" synonym verwendet habe, obwohl sie nicht dasselbe sind. GPU und Neural Engine sind also verschiedene Arten von Beschleunigern.
In beiden Fällen verfügen Sie über spezielle Speicherbereiche, die die CPU mit den zu verarbeitenden Daten füllen muss, sowie über einen weiteren Speicherbereich, den die CPU mit einer Liste von Anweisungen füllt, die der Beschleuniger ausführen muss. Der Prozessor benötigt Zeit, um diese Aufgaben auszuführen. Sie müssen dies alles koordinieren, die Daten eingeben und dann auf den Empfang der Ergebnisse warten.
Und ein solcher Mechanismus eignet sich für große Aufgaben, aber für kleine Aufgaben ist dies übertrieben.

Dies ist der Vorteil von Coprozessoren gegenüber Beschleunigern. Coprozessoren sitzen und beobachten den Fluss von Maschinencode-Anweisungen, die vom Speicher (oder insbesondere vom Cache) zur CPU kommen. Der Coprozessor ist gezwungen, auf die spezifischen Anweisungen zu reagieren, die er verarbeiten musste. In der Zwischenzeit ignoriert die CPU diese Anweisungen meistens oder erleichtert die Handhabung durch den Coprozessor.
Der Vorteil ist, dass die vom Coprozessor ausgeführten Anweisungen im regulären Code enthalten sein können. Bei der GPU ist alles anders - Shader-Programme werden in separaten Speicherpuffern abgelegt, die dann explizit auf die GPU übertragen werden müssen. Sie können hierfür keinen regulären Code verwenden. Und deshalb eignet sich AMX hervorragend für einfache Matrixverarbeitungsaufgaben.
Der Trick dabei ist, dass Sie Anweisungen in der Befehlssatzarchitektur (ISA) Ihres Mikroprozessors definieren müssen. Bei Verwendung eines Coprozessors besteht daher eine engere Integration mit dem Prozessor als bei Verwendung eines Beschleunigers.
Die Entwickler von ARM haben sich übrigens lange dagegen gewehrt, ISA benutzerdefinierte Anweisungen hinzuzufügen. Dies ist einer der Vorteile von RISC-V. Im Jahr 2019 gaben die Entwickler jedoch Folgendes auf: „Die neuen Anweisungen werden mit den Standard-ARM-Anweisungen kombiniert. Um eine Softwarefragmentierung zu vermeiden und eine konsistente Softwareentwicklungsumgebung aufrechtzuerhalten, erwartet ARM, dass Clients benutzerdefinierte Anweisungen hauptsächlich bei Bibliotheksaufrufen verwenden. "
Dies könnte eine gute Erklärung für die fehlende Beschreibung der AMX-Anweisungen in der offiziellen Dokumentation sein. ARM erwartet lediglich, dass Apple Anweisungen in die vom Kunden bereitgestellten Bibliotheken aufnimmt (in diesem Fall Apple).
Was ist der Unterschied zwischen einem Matrix-Coprozessor und einem Vektor-SIMD?
Im Allgemeinen ist es nicht so schwierig, einen Matrix-Coprozessor mit der Vektor-SIMD-Technologie zu verwechseln, die in den meisten modernen Prozessoren, einschließlich ARM, zu finden ist. SIMD steht für Single Instruction Multiple Data.

Mit SIMD können Sie die Systemleistung steigern, wenn Sie denselben Vorgang für mehrere Elemente ausführen müssen, was eng mit Matrizen zusammenhängt. Im Allgemeinen werden SIMD-Anweisungen, einschließlich ARM Neon- oder Intel x86 SSE- oder AVX-Anweisungen, häufig verwendet, um die Matrixmultiplikation zu beschleunigen.
Die SIMD-Vektor-Engine ist jedoch Teil des Mikroprozessorkerns, ebenso wie ALU (Arithmetic Logic Unit) und FPU (Floating Point Unit) Teil der CPU sind. Nun, bereits der Befehlsdecoder im Mikroprozessor "entscheidet", welcher Funktionsblock aktiviert werden soll.

Der Coprozessor ist jedoch ein separates physikalisches Modul und nicht Teil des Mikroprozessorkerns. Früher war beispielsweise der 8087 von Intel ein separater Chip, der Gleitkommaoperationen beschleunigen sollte.

Es mag seltsam sein, dass jemand ein so komplexes System mit einem separaten Chip entwickelt, der die Daten verarbeitet, die vom Speicher zum Prozessor gelangen, um einen Gleitkommabefehl zu erkennen.
Aber die Truhe öffnet sich einfach. Tatsache ist, dass der ursprüngliche 8086-Prozessor nur 29.000 Transistoren hatte. Der 8087 hatte bereits 45.000 davon. Letztendlich ermöglichten die Technologien die Integration von FPUs in den Hauptchip, wodurch Coprozessoren beseitigt wurden.
Aber warum AMX nicht Teil des M1 Firestorm-Kerns ist, ist nicht ganz klar. Vielleicht hat Apple gerade beschlossen, nicht standardmäßige ARM-Elemente außerhalb des Hauptprozessors zu verschieben.
Aber warum wird über AMX nicht viel gesprochen?
Wenn AMX nicht in der offiziellen Dokumentation beschrieben ist, wie können wir es überhaupt herausfinden? Vielen Dank an Entwickler Dougall Johnson, der ein wunderbares Reverse Engineering des M1 durchgeführt und den Coprozessor entdeckt hat. Seine Arbeit wird hier beschrieben . Wie sich herausstellte, hat Apple spezielle Bibliotheken und / oder Frameworks wie Accelerate für mathematische Operationen im Zusammenhang mit Matrizen erstellt . All dies umfasst die folgenden Elemente:
• vImage - Bildverarbeitung auf höherer Ebene, z. B. Konvertieren zwischen Formaten, Bearbeiten von Bildern.
• BLASIst eine Art Industriestandard für lineare Algebra (was wir Mathematik nennen, die sich mit Matrizen und Vektoren befasst).
• BNNS - wird verwendet, um neuronale Netze zu betreiben und zu trainieren.
• vDSP - digitale Signalverarbeitung. Fourier-Transformationen, Faltung. Dies sind mathematische Operationen, die ausgeführt werden, wenn ein Bild oder ein Signal verarbeitet wird, das Ton enthält.
• LAPACK - Übergeordnete lineare Algebra-Funktionen, z. B. das Lösen linearer Gleichungen.
Johnson verstand, dass diese Bibliotheken den AMX-Coprozessor verwenden würden, um die Berechnungen zu beschleunigen. Daher entwickelte er eine spezielle Software zur Analyse und Überwachung von Bibliotheksaktionen. Letztendlich konnte er undokumentierte AMX-Maschinencode-Anweisungen finden.
Und Apple dokumentiert dies alles nicht, weil ARM LTD. versucht nicht zu viele Informationen zu bewerben. Tatsache ist, dass wenn benutzerdefinierte Funktionen wirklich weit verbreitet sind, dies zu einer Fragmentierung des ARM-Ökosystems führen kann, wie oben erläutert.
Apple hat die Möglichkeit, ohne dies wirklich zu bewerben, später bei Bedarf die Funktionsweise von Systemen zu ändern - beispielsweise AMX-Anweisungen zu löschen oder hinzuzufügen. Für Entwickler reicht die Accelerate-Plattform aus, den Rest erledigt das System selbst. Dementsprechend kann Apple sowohl Hardware als auch Software dafür steuern.
Vorteile des Apple Matrix Coprozessors
Hier gibt es viel, ein hervorragender Überblick über die Fähigkeiten des Elements wurde von Nod Labs erstellt, das sich auf maschinelles Lernen, Intelligenz und Wahrnehmung spezialisiert hat. Insbesondere führten sie vergleichende Leistungstests zwischen AMX2 und NEON durch.
Wie sich herausstellte, führt AMX die Operationen aus, die erforderlich sind, um Operationen mit Matrizen doppelt so schnell auszuführen. Dies bedeutet natürlich nicht, dass AMX das Beste ist, sondern für maschinelles Lernen und Hochleistungsrechnen - ja.
Unter dem Strich ist der Coprozessor von Apple eine beeindruckende Technologie, die Apple ARM einen Vorsprung beim maschinellen Lernen und beim Hochleistungsrechnen verschafft.
