Tiefes neuronales Hochleistungsnetzwerk für tabellarische Daten TabNet
Einführung
Tiefe neuronale Netze (GNNs) sind zu einem der attraktivsten Werkzeuge für die Erstellung künstlicher Intelligenzsysteme (SRI) geworden, z. B. Spracherkennung, natürliche Kommunikation, Computer Vision [2-3] usw. Insbesondere aufgrund der automatischen Auswahl von GNS wichtig, definiert Merkmale, Verbindungen aus Daten. Neuronale Netzwerkarchitekturen (neokognitronisch, faltungsorientiert, tiefes Vertrauen usw.), Modelle und Algorithmen zum Lernen von GNS (Autoencoder, Boltzmann-Maschinen, kontrollierte wiederkehrende usw.) werden entwickelt. GNSs sind schwer zu trainieren, hauptsächlich aufgrund verschwindender Gradientenprobleme.
Der Artikel beschreibt die neue kanonische Architektur von GNS für Tabellendaten (TabNet), mit der ein "Entscheidungsbaum" angezeigt werden soll. Ziel ist es, die Vorteile hierarchischer Methoden (Interpretierbarkeit, Auswahl spärlicher Merkmale) und GNS-basierter Methoden (schrittweises und durchgängiges Lernen) zu erben. Insbesondere erfüllt TabNet zwei Hauptanforderungen: hohe Leistung und Interpretierbarkeit. Hohe Leistung reicht oft nicht aus - GNS muss baumartige Methoden interpretieren und ersetzen.
TabNet ist ein neuronales Netzwerk vollständig verbundener Schichten mit einem sequentiellen Aufmerksamkeitsmechanismus, der:
verwendet eine spärliche Auswahl von Objekten nach Instanzen, die aus dem Trainingsdatensatz erhalten wurden;
erstellt eine sequentielle mehrstufige Architektur, in der jeder Entscheidungsschritt zu dem Teil der Entscheidung beitragen kann, der auf den ausgewählten Funktionen basiert;
verbessert die Lernfähigkeit durch nichtlineare Transformationen ausgewählter Funktionen;
simuliert ein Ensemble mit genaueren Messungen und mehr Verbesserungsschritten.
Jede Schicht einer gegebenen Architektur (Fig. 1) ist ein Lösungsschritt, der einen Block mit vollständig verbundenen Schichten zum Transformieren von Eigenschaften enthält - einen Merkmalstransformator und einen Aufmerksamkeitsmechanismus zum Bestimmen der Wichtigkeit der ursprünglichen Eingangsmerkmale.

1. Konverter von Funktionen
1.1. Chargennormalisierung
- . . , (, ), , . (covariate shift).
. , — . ( ) , . , , , .
. , — , . , , ( , – ) . . - (batch normalization), 2015 [4].
- .
1. d: x = (x1, . . . , xd). k- x ( ):

2. . , . , , (

[−1, 1] ).
, :

γ, β .
3. , , -,


4. .
-:
, , ;
, ;
, ;
.
1.2. GLU
[5] Gated Linear Unit, , , LSTM-.
GLU
, , , . H = [h0 ,..., hN] w0, ... ,wN, P (wi |hi). f H hi = f(hi - 1 , wi - 1) , i ( , ).
f H = f * w , , , , , . . , , [5] , , .
. 2 . , D |V| x e, |V| - ( ), e - . w0, … , wN, E = [Dw0, … , DwN]. h0 , …hL

m, n – , , k - , X ∈ R N×m - hl ( , ),
, σ - ⊗ .
, hi . , . , k-1, , - , , k - .

X * W + b, σ(X * V + c). LSTM, X * W + b , . (GLU). E H = hL◦. . .◦h0 (E).
(GLU) , .
3.3 LSTM
LSTM (long short-term memory, – ) — , . LSTM , , [5].
LSTM . — , !
. , , tanh.
LSTM
LSTM .
LSTM , . , « ». h x 0 1 C. 1 « », 0 — « ».
. , . , . , .
, . . , « », , . tanh - C, . .
, .
C. , .
f, , . i*C. , , .
, .
, , . . , , . tanh ( [-1, 1]) .
, , , . , , ( ) .
TabNet

3.4. Split:
Feature Transformer , . , , Attentive Transformer , . (backpropagation) , «» , ( ). , . , Attentive Transformer . , "" , , .
SPLIT
: (. . 1) .
, , ( ), , .
. 3 . FC BN (GLU) , . √0.5 , , . . BN, , , BN BV mB. , , BN. , , . 3,
:
. softmax ( argmax ).
4.
. (), ( ) Softmax, , , : , - , — .
, , ht, t=1 …m, d , .
C d di−1 .
s — hi « ».
, s softmax. e=softmax(s)
softmax :
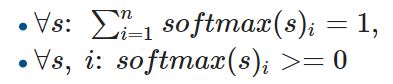
:

cc , hi ei.
. , , , , , . Softmax, Sparsemax. , , - , Softmax , . «» «» , - .
5. SPARSEMAX
, z z, . :

τ(z) S(z), p. softmax , , , softmax .
, . softmax , sparsemax :
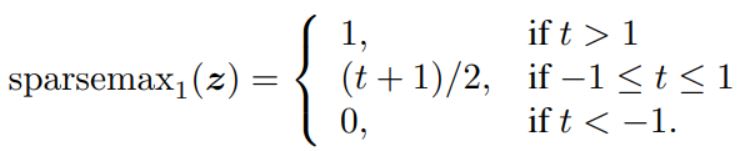
, :

, sparsemax , , :

|S(z)| - S(z).
, , , , Sparsemax.
,
6.
, , , , - . . , , . ( ), () , , , .
:
. , , , , . : M[i] · f. (. . 1) , , a[i − 1]:
Sparsemax [6] , .
,
h[i] - , . 4., FC, BN, P[i] - , , :

γ - : γ = 1, γ, . P[0] ,
- . ( ), P[0] , . :
ϵ - . λ, , .
, , . , , , - . , [5] , .
TabNet - . TabNet . , () , .
, , , .
.. // . : . 2017. .6, №3. .28–59. DOI: 10.14529/cmse170303
LeCun Y., Bengio Y., Hinton G. Deep Learning // Nature. 2015. Vol.521. Pp.436–444. DOI: 10.1038/nature14539.
Rav`ı D., Wong Ch., Deligianni F., et al. Deep Learning for Health Informatics // IEEE Journal of Biomedical and Health Informatics. 2017. Vol.21, No.1. PP.4–21. DOI: 10.1109/JBHI.2016.2636665.
Sergey Ioffe, Christian Szegedy. Batch Normalization: Accelerating Deep Network Training by Reducing Internal // Proceedings of The 32nd International Conference on Machine Learning (2015), pp.448-456.
Sercan O. Arik, Tomas Pfister. TabNet: Attentive Interpretable Tabular Learning // ICLR 2020 Conference Blind Submission 25 Sept 2019 (modified: 24 Dec 2019). URL:https://drive.google.com/file/d/1oLQRgKygAEVRRmqCZTPwno7gyTq22wbb/view?usp=sharing
Andre F. T. Martins and Ram´on Fern´andez Astudillo. 2016. From Softmax´ to Sparsemax: A Sparse Model of Attention and Multi-Label Classification. arXiv:1602.02068.