
Die Probleme, die maschinelles Lernen heute löst, sind oft komplex und umfassen eine große Anzahl von Merkmalen (Merkmalen). Aufgrund der Komplexität und Vielfalt der Anfangsdaten ermöglicht die Verwendung einfacher Modelle für maschinelles Lernen häufig nicht die Erzielung der erforderlichen Ergebnisse. Daher werden in realen Geschäftsfällen komplexe, nichtlineare Modelle verwendet. Solche Modelle haben einen erheblichen Nachteil: Aufgrund ihrer Komplexität ist es fast unmöglich, die Logik zu erkennen, mit der das Modell diese bestimmte Klasse der Kontobetrieb zugewiesen hat. Die Interpretierbarkeit des Modells ist besonders wichtig, wenn die Ergebnisse seiner Arbeit dem Kunden präsentiert werden müssen - er wird höchstwahrscheinlich wissen wollen, anhand welcher Kriterien Entscheidungen für sein Unternehmen getroffen werden.
, sklearn, xgboost, lightGBM (). , . , , ? ? , . SHAP. SHAP . , .
. , . 213 , .
kaggle .
:
%%time
# LOAD TRAIN
X_train=pd.read_csv('train_transaction.csv',index_col='TransactionID', dtype=dtypes, usecols=cols+['isFraud'])
train_id= pd.read_csv('train_identity.csv',index_col='TransactionID', dtype=dtypes)
X_train = X_train.merge(train_id, how='left', left_index=True, right_index=True)
# LOAD TEST
X_test=pd.read_csv('test_transaction.csv',index_col='TransactionID', dtype=dtypes, usecols=cols)
test_id = pd.read_csv('test_identity.csv',index_col='TransactionID', dtype=dtypes)
fix = {o:n for o, n in zip(test_id.columns, train_id.columns)}
test_id.rename(columns=fix, inplace=True)
X_test = X_test.merge(test_id, how='left', left_index=True, right_index=True)
# TARGET
y_train = X_train['isFraud'].copy()
del train_id, test_id, X_train['isFraud']; x = gc.collect()
# PRINT STATUS
print('Train shape',X_train.shape,'test shape',X_test.shape)
X_train.head()

, , , , .
, () , , . , , , .
.
:
if BUILD95:
feature_imp=pd.DataFrame(sorted(zip(clf.feature_importances_,cols)), columns=['Value','Feature'])
plt.figure(figsize=(20, 10))
sns.barplot(x="Value", y="Feature", data=feature_imp.sort_values(by="Value", ascending=False).iloc[:50])
plt.title('XGB95 Most Important Features')
plt.tight_layout()
plt.show()
del clf, h; x=gc.collect()

, , . : ? . , , . , , SHAP. , , : 20 . 50 .
:
import shap
shap.initjs()
shap_test = shap.TreeExplainer(h).shap_values(X_train.loc[idxT,cols])
shap.summary_plot(shap_test, X_train.loc[idxT,cols],
max_display=25, auto_size_plot=True)
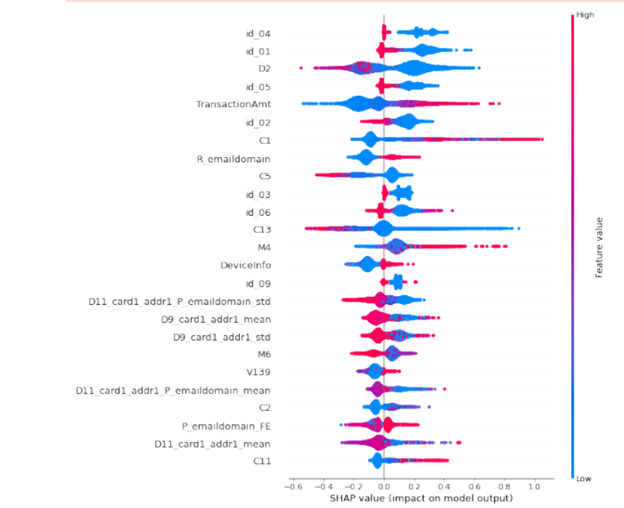
, . 2 . «0», «1». , . , . , , , : , , . , email.
Basierend auf den erhaltenen Daten ist es möglich, das Modell aufzuhellen, dh nur die Parameter zu belassen, die einen signifikanten Einfluss auf die Vorhersageergebnisse unseres Modells haben. Darüber hinaus wird es möglich, die Bedeutung von Funktionen für bestimmte Untergruppen von Daten zu bewerten, z. B. Kunden aus verschiedenen Regionen, Transaktionen zu verschiedenen Tageszeiten usw. Darüber hinaus kann dieses Tool zur Analyse von Einzelfällen verwendet werden, z Beispiel, um "Ausreißer" und Extremwerte zu analysieren. SHAP kann auch beim Auffinden fallender Zonen bei der Klassifizierung negativer Phänomene helfen. Dieses Tool macht in Kombination mit anderen Ansätzen die Modelle leichter, qualitativ besser und die Ergebnisse interpretierbar.