
Mit 12 Problemen ist es an der Zeit, den Namen und das Design ein wenig zu ändern, aber Sie warten immer noch auf Recherchen, Demos, offene Modelle und Datensätze. Lernen Sie die neue Version des Machine Learning Toolkit kennen.
DALL E.
Barrierefreiheit: Projektseite / Zugriff auf geschlossene API über Warteliste
OpenAI präsentierte sein neues DALL-E-Transformator-Sprachmodell mit 12 Milliarden Parametern, das auf Bild-Text-Paaren trainiert wurde. Das Modell basiert auf GPT-3 und wird verwendet, um Bilder aus Textbeschreibungen zu synthetisieren.
Im Juni letzten Jahres zeigte das Unternehmen , wie ein Modell, das auf Pixelsequenzen mit einer genauen Beschreibung trainiert wurde, Lücken in Bildern ausfüllen kann, die in die Eingabe eingespeist werden. Die Ergebnisse waren damals schon beeindruckend, aber hier hat Open AI alle Erwartungen übertroffen. Genau wie GPT-3 kohärente vollständige Sätze synthetisiert, erzeugt DALL · E komplexe Bilder.

Die Modelle sind überraschend gut in anthropomorphen Objekten (Radieschen, die mit dem Hund spazieren gehen) und einer Kombination inkompatibler Objekte (eine Schnecke in Form einer Harfe), weshalb sie die Fusion zweier Namen für den Namen gewählt haben - des spanischen Surrealisten Salvador Dali und der Pixar-Roboter WALL-I.
Welche Ergebnisse erzielt das Modell?
Das Modell kann die Tiefe des Raums visualisieren und so eine dreidimensionale Szene manipulieren. Bei der Beschreibung des gewünschten Bildes reicht es aus, anzugeben, aus welchem Winkel das Objekt gesehen werden soll und unter welcher Beleuchtung. Auf diese Weise können in Zukunft echte 3D-Darstellungen erstellt werden.
Darüber hinaus kann das Modell optische Effekte auf die Szene anwenden, beispielsweise bei Aufnahmen mit einem Fischaugenobjektiv. Bisher kommt er aber mit Reflexionen nicht gut zurecht - der Würfel im Spiegel wurde nicht überzeugend synthetisiert. Mit unterschiedlichen Zuverlässigkeitsgraden bewältigt DALL · E durch natürliche Sprache die Aufgaben, für die 3D-Modellierungs-Engines in der Industrie verwendet werden. Dadurch kann es zum Rendern von Raumdesign-Renderings verwendet werden.
Das Modell ist sich der Geografie und der Wahrzeichen sowie der Besonderheiten einzelner Epochen bewusst. Sie kann ein Foto eines alten Telefons oder der Golden Gate Bridge in San Francisco synthetisieren.
Bei alledem benötigt das Modell keine ultrapräzise Beschreibung - es wird einige der Lücken selbst füllen. Wie von Open AI festgestellt, ist das Ergebnis umso schlechter, je genauer die Beschreibung ist.
Denken Sie daran, dass das GPT-3 ein Zero-Shot-Modell ist und nicht zusätzlich konfiguriert und geschult werden muss, um bestimmte Aufgaben auszuführen. Zusätzlich zur Beschreibung können Sie einen Hinweis geben, damit das Modell die gewünschte Antwort generiert. DALL · E macht dasselbe mit dem Rendern und kann verschiedene Bild-zu-Bild-Konvertierungsaufgaben basierend auf Eingabeaufforderungen ausführen. Sie können beispielsweise ein Bild als Eingabe angeben und darum bitten, es in Form einer Skizze zu erstellen.
Überraschenderweise haben sich die Macher kein solches Ziel gesetzt und dies beim Training des Modells in keiner Weise vorgesehen. Die Fähigkeit wurde nur während des Testens offenbart.
Anhand dieser Entdeckung untersuchten die Autoren die Fähigkeit von DALL · E, logische Probleme des visuellen IQ-Tests zu lösen, und stellten die Aufgabe, nicht die richtige Antwort aus den vorgestellten Optionen auszuwählen, sondern das fehlende Element vollständig vorherzusagen.
Im Allgemeinen gelang es dem Modell, die Sequenz in dem Teil der Aufgaben, in dem ein geometrisches Verständnis erforderlich war, korrekt fortzusetzen.
Das Modell wurde noch nicht veröffentlicht, und es gibt nicht einmal eine grobe Beschreibung seiner Architektur. In dieser Phase können Sie den Zugriff auf die API anfordern oder die inoffizielle Implementierung auf PyTorch überprüfen ( eine inoffizielle Version auf TensorFlow wird ebenfalls bearbeitet ).
CLIP (Contrastive Language - Image Pre-Training)
Zugänglichkeit: Projektseite / Quellcode
Deep Learning hat die Bildverarbeitung revolutioniert, aber die aktuellen Ansätze weisen immer noch zwei wesentliche Probleme auf, die die Verwendung von DNN in diesem Bereich in Frage stellen.
Erstens bleibt das Erstellen von Datensätzen sehr teuer, ermöglicht jedoch gleichzeitig die Erkennung eines sehr begrenzten Satzes visueller Bilder und eignet sich für enge Aufgaben. Bei der Erstellung des ImageNet-Datasets waren beispielsweise 25.000 Personen erforderlich, um Beschreibungen von 14 Millionen Bildern für 22.000 Objektkategorien zu erstellen. Gleichzeitig kann das ImageNet-Modell nur die Kategorien vorhersagen, die im Dataset dargestellt sind. Wenn eine andere Aufgabe erforderlich ist, müssen Spezialisten neue Datasets erstellen und die Schulung des Modells abschließen.
Zweitens sind Modelle, die bei Benchmarks gut abschneiden, in ihrer natürlichen Umgebung nicht ausreichend. In der realen Welt eingesetzte Modelle funktionieren nicht so gut wie in Laborumgebungen. Mit anderen Worten, das Modell ist so optimiert, dass es einen bestimmten Test besteht, wenn ein Schüler vergangene Prüfungsfragen stopft.
Das offene neuronale Netzwerk CLIP von OpenAI zielt darauf ab, diese Probleme zu lösen. Das Modell wird auf einer Vielzahl von Bildern und Textbeschreibungen trainiert, die im Internet verfügbar sind, und übersetzt sie in Vektordarstellungen und Einbettungen. Diese Darstellungen werden so verglichen, dass die Nummern der Inschrift und das dafür geeignete Bild nahe beieinander liegen.
CLIP kann sofort an verschiedenen Benchmarks getestet werden, ohne deren Daten zu trainieren. Das Modell führt Klassifizierungstests ohne direkte Optimierung durch. Der ObjectNet-Test testet beispielsweise die Fähigkeit des Modells, Objekte an verschiedenen Orten und mit wechselndem Hintergrund zu erkennen, während ImageNet Rendition und ImageNet Sketch die Fähigkeit des Modells testen, abstraktere Bilder von Objekten (nicht nur eine Banane, sondern eine geschnittene Banane) zu erkennen oder Bananenskizze). CLIP ist bei allen gleich gut.
CLIP kann angepasst werden, um eine Vielzahl von visuellen Klassifizierungsaufgaben ohne zusätzliche Schulungsbeispiele auszuführen. Um CLIP auf ein neues Problem anzuwenden, müssen Sie dem Encoder nur die Namen der visuellen Darstellungen geben, und es wird ein linearer Klassifikator dieser Darstellungen erstellt, dessen Genauigkeit den mit dem Lehrer trainierten Modellen nicht unterlegen ist.
Github hat bereits eine Implementierung für Fotos mit Unsplash, die zeigt, wie gut das Modell Bilder gruppiert. Designer können damit bereits Moodboards entwerfen.
DeBERTa von Microsoft
Verfügbarkeit: Quell- / Projektseite
Wie üblich überschatteten Nachrichten von OpenAI andere Ankündigungen, obwohl es ein anderes Ereignis gab, das in der Community aktiv diskutiert wurde. Das DeBERTa-Modell von Microsoft übertraf beim SuperGLUE Natural Language Comprehension (NLU) -Test die menschliche Basislinie.
Ein auf 10 Parametern basierender Benchmark bestimmt, ob der Algorithmus das Gelesene „versteht“ und bewertet. Die durchschnittliche Punktzahl für Nicht-Experten beträgt 89,8 Punkte, und die Probleme, die die Modelle lösen müssen, sind mit einer Englischprüfung vergleichbar. DeBERTa zeigte 90,3, gefolgt von Googles T5 + Meena.
So gelang es dem Modell, einen Menschen zum zweiten Mal zu überholen, aber es ist bemerkenswert, dass DeBERTa 1,5 Milliarden Trainingsparameter hat, 8-mal weniger als T5.
Das Modell stellt einen neuen, geteilten Aufmerksamkeitsmechanismus dar, der sich vom ursprünglichen Transformator unterscheidet und bei dem jedes Token durch Inhaltsvektoren und Positionen codiert wird, die sich nicht zu einem Vektor addieren. Separate Matrizen arbeiten mit ihnen.
NeuralMagicEye
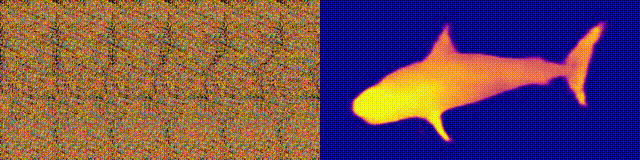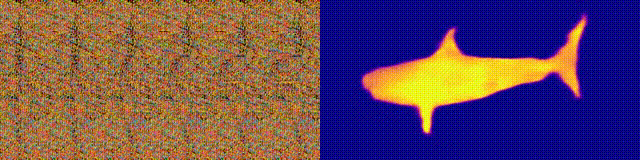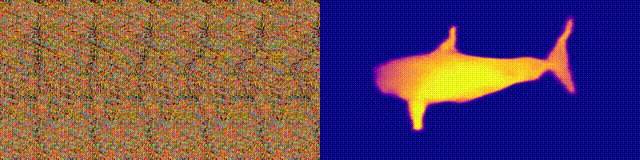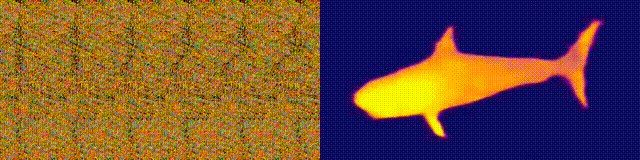
Zugänglichkeit: Projektseite / Code / Colab
Erinnern Sie sich an die Magic Eye-Alben mit Stereogrammen? Hier ist etwas Ähnliches, nur für Autostereogramme, bei denen beide Teile des Stereopaars im selben Bild sind und in einer Rasterstruktur codiert sind, so dass visuelle Illusionen von Dreidimensionalität erzeugt werden können.
Der Autor der Studie trainierte das CNN-Modell, um die Tiefe des Autostereogramms zu rekonstruieren und dessen Inhalt zu verstehen. Um den Stereoeffekt zu erzielen, musste das Modell trainiert werden, um die Nichtübereinstimmung von quasi-periodischen Texturen zu erkennen und zu bewerten. Das Modell wurde an einem Datensatz aus 3D-Modellen ohne Lehrer trainiert.
Mit dieser Methode können Sie die Tiefe des Autostereogramms genau wiederherstellen. Die Forscher hoffen, dass dies Menschen mit Sehbehinderungen hilft und Stereogramme als Wasserzeichen in Bildern verwendet werden können.
StyleFlow

Zugänglichkeit: Quellcode
Wie wir mehr als einmal gesehen haben, können bedingungslose GANs (wie StyleGANs) qualitativ hochwertige, fotorealistische Bilder erstellen. Es ist jedoch selten möglich, den Generierungsprozess mithilfe semantischer Attribute zu verwalten und gleichzeitig die Qualität der Ausgabe beizubehalten. Aufgrund der komplexen und verwirrenden GAN-Latenz führt das Bearbeiten eines Attributs häufig zu unerwünschten Änderungen an anderen. Dieses Modell hilft, dieses Problem zu lösen. Sie können beispielsweise den Betrachtungswinkel, die Beleuchtungsvariation, den Ausdruck, das Gesichtshaar, das Geschlecht und das Alter ändern.
Transformatoren zähmen
Zugänglichkeit: Projektseite / Quellcode
Transformatoren können in einer Vielzahl von Anwendungen hervorragende Ergebnisse liefern. In Bezug auf die Rechenleistung sind sie jedoch sehr anspruchsvoll und daher nicht für die Arbeit mit hochauflösenden Bildern geeignet. Die Autoren der Studie kombinierten einen Transformator mit einem induktiv verschobenen Faltungsnetzwerk und konnten Bilder mit hoher Auflösung abbilden.
POse EMbedding

Zugänglichkeit: Quellcode
Alltägliche Aktivitäten, sei es beim Laufen oder Lesen eines Buches, können als eine Abfolge von Körperhaltungen betrachtet werden, die aus der Position und Ausrichtung des Körpers einer Person im Raum bestehen. Die Posenerkennung eröffnet eine Reihe von Möglichkeiten für AR, Gestensteuerung usw. Die aus dem 2D-Bild erhaltenen Daten unterscheiden sich jedoch je nach Blickwinkel der Kamera. Dieser Algorithmus von Google AI erkennt die Ähnlichkeit von Posen aus verschiedenen Winkeln und stimmt die Schlüsselpunkte der 2D-Anzeige der Pose mit der ansichtsinvarianten Einbettung überein.
Lernen zu lernen
Zugänglichkeit: Quellcode
Um zu lernen, wie man eine Flasche aufhebt oder auf den Tisch stellt, muss nur eine andere Person dies tun. Um zu lernen, wie solche Objekte zu bedienen sind, benötigt eine Maschine manuell programmierte Belohnungen, um die Bausteine einer Aufgabe erfolgreich abzuschließen. Bevor ein Roboter lernen kann, eine Flasche auf einen Tisch zu stellen, muss er dafür belohnt werden, dass er gelernt hat, die Flasche vertikal zu bewegen. Erst nach einer Reihe solcher Iterationen lernt er, die Flasche zu platzieren. Facebook führte eine Methode ein, mit der eine Maschine in einigen menschlichen Beobachtungssitzungen trainiert wird.
So hell war der erste Monat dieses Jahres. Vielen Dank fürs Lesen und bleiben Sie dran für zukünftige Releases!