
Foto von Richard Jacobs auf Unsplash
Im November 2020 haben wir eine umfassende Migration gestartet, um unseren PostgreSQL-Cluster von 9.6 auf 12.4 zu aktualisieren. In diesem Beitrag gebe ich Ihnen einen kurzen Überblick über unsere Architektur bei Coffee Meets Bagel, erkläre, wie die Ausfallzeit des Upgrades auf unter 30 Minuten reduziert wurde, und teile mit, was wir dabei gelernt haben.
Die Architektur
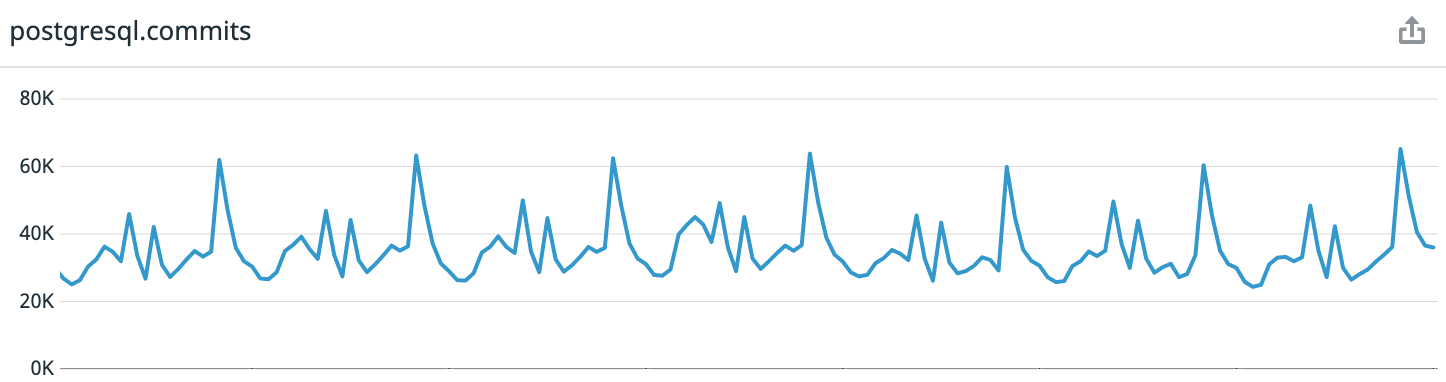
Als Referenz: Coffee Meets Bagel ist eine romantische Dating-App mit einem Kurationssystem. Jeden Tag erhalten unsere Benutzer mittags in ihrer Zeitzone eine begrenzte Anzahl hochwertiger Kandidaten. Dies führt zu sehr vorhersehbaren Lastmustern. Wenn Sie sich die Daten der letzten Woche ab dem Zeitpunkt des Schreibens des Artikels ansehen, erhalten wir durchschnittlich 30.000 Transaktionen pro Sekunde, in der Spitze - bis zu 65.000.
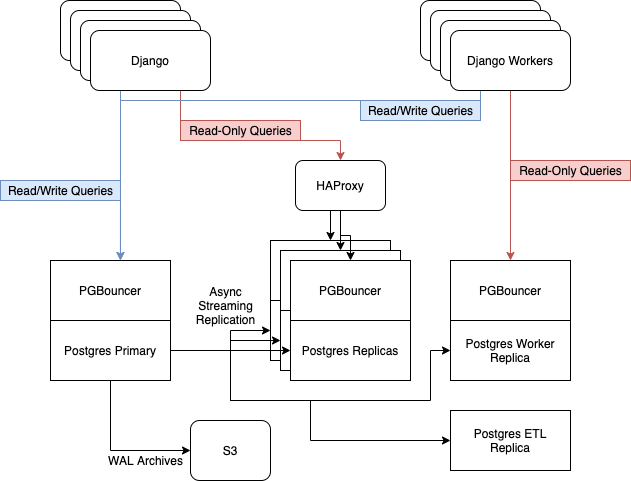
Vor dem Update wurden 6 Postgres-Server auf i3.8xlarge-Instanzen in AWS ausgeführt. Sie enthielten einen Masterknoten, drei Replikate für die Bereitstellung von schreibgeschütztem Webverkehr, ausgeglichen mit HAProxy, einen Server für asynchrone Mitarbeiter und einen Server für ETL [ Extrahieren, Transformieren, Laden ] und Business Intelligence....
Wir verlassen uns auf die integrierte Streaming-Replikation von Postgres, um unsere Replikatflotte auf dem neuesten Stand zu halten.
Gründe für das Upgrade
In den letzten Jahren haben wir unsere Datenschicht merklich ignoriert und sie ist daher leicht veraltet. Besonders viele "Krücken" wurden von unserem Hauptserver aufgenommen - er ist seit 3,5 Jahren online. Wir patchen verschiedene Systembibliotheken und Dienste, ohne den Server anzuhalten.

Mein Kandidat für das Subreddit r / uptimeporn
Infolgedessen haben sich viele Kuriositäten angesammelt, die Sie nervös machen. Beispielsweise werden neue Dienste
systemd
nicht gestartet. Ich musste den Start des Agenten
datadog
in der Sitzung konfigurieren
screen
. Manchmal reagierte SSH nicht mehr, wenn die Prozessorlast über 50% lag und der Server selbst regelmäßig Datenbankanforderungen sendete.
Und auch der freie Speicherplatz auf der Festplatte näherte sich gefährlichen Werten. Wie oben erwähnt, lief Postgres auf i3.8xlarge-Instanzen in EC2 mit 7,6 TB NVMe-Speicher. Im Gegensatz zu EBS kann die Größe der Festplatte hier nicht dynamisch geändert werden - wie ursprünglich festgelegt. Und wir haben ungefähr 75% der Festplatte gefüllt. Es wurde klar, dass die Instanzgröße geändert werden muss, um zukünftiges Wachstum zu unterstützen.
Unsere Anforderungen
- Minimale Ausfallzeit. Wir haben uns ein Ziel von 4 Stunden Gesamtausfallzeit gesetzt, einschließlich ungeplanter Ausfälle aufgrund von Upgrade-Fehlern.
- Erstellen Sie einen neuen Datenbankcluster auf neuen Instanzen, um die aktuelle Flotte alternder Server zu ersetzen.
- Gehen Sie zu i3.16xlarge, um Platz zum Wachsen zu erhalten.
Wir kennen drei Möglichkeiten, um Postgres zu aktualisieren: Sichern und Wiederherstellen von Postgres, pg_upgrade und pglogische logische Replikation.
Wir haben die erste Methode sofort abgebrochen und aus einem Backup wiederhergestellt: Für unser 5,7-TB-Dataset würde es zu lange dauern. Bei seiner Geschwindigkeit erfüllte pg_upgrade nicht die Anforderungen 2 und 3: Es ist ein Migrationstool auf demselben Computer. Daher haben wir uns für die logische Replikation entschieden.
Unser Prozess
Es wurde genug über die Hauptmerkmale von pglogical geschrieben. Anstatt gemeinsame Wahrheiten zu wiederholen, werde ich daher einfach Artikel geben, die sich für mich als nützlich erwiesen haben:
- Upgrade der Hauptversion mit minimalen Ausfallzeiten ;
- Upgrade von PostgreSQL von 9.4 auf 10.3 mit pglogical ;
- Pglogisch entmystifizieren - Tutorial .
Wir haben einen neuen primären Postgres 12-Server erstellt und pglogical verwendet, um alle unsere Daten zu synchronisieren. Als es synchronisiert und fortgesetzt wurde, um eingehende Änderungen zu replizieren, haben wir begonnen, Streaming-Replikate dafür hinzuzufügen. Nach dem Einrichten des neuen Streaming-Replikats haben wir es in HAProxy aufgenommen und eine der alten Versionen 9.6 entfernt.
Dieser Vorgang wurde fortgesetzt, bis die Postgres 9.6-Server mit Ausnahme des Masters vollständig heruntergefahren wurden. Die Konfiguration hatte die folgende Form.

Dann war die Clusterumschaltung (Failover) an der Reihe, für die wir das Wartungsfenster angefordert haben. Der Umstellungsprozess ist auch im Internet gut dokumentiert, daher werde ich nur auf die allgemeinen Schritte eingehen:
- Übergabe des Standortes in den technischen Arbeitsmodus;
- Ändern der DNS-Einträge des Masters auf einen neuen Server;
- Erzwungene Synchronisation aller Sequenzen von Primärschlüsseln;
- Manueller Start von Checkpoint (
CHECKPOINT
) am alten Master. - Auf dem neuen Assistenten - Durchführen einiger Datenvalidierungs- und Testverfahren;
- Site aktivieren.
Insgesamt verlief der Übergang gut. Trotz dieser großen Änderungen in unserer Infrastruktur gab es keine ungeplanten Ausfallzeiten.
Gewonnene Erkenntnisse
Mit dem Gesamterfolg der Operation traten auf dem Weg einige Probleme auf. Die schlimmsten von ihnen hätten fast unseren Postgres 9.6-Meister getötet ...
Lektion 1: Langsame Synchronisation kann gefährlich sein
Beginnen wir mit einem Kontext: Wie funktioniert pglogisch? Der Absenderprozess auf dem Provider (in diesem Fall unser alter Assistent 9.6) dekodiert das Write-Ahead-WAL-Protokoll, ruft die logischen Änderungen ab und sendet sie an den Abonnenten.
Wenn der Teilnehmer zurückbleibt, speichert der Anbieter WAL-Segmente, sodass beim Aufholen des Teilnehmers keine Daten verloren gehen.
Wenn zum ersten Mal eine Tabelle zum Replikationsdatenstrom hinzugefügt wird, muss pglogical zuerst die Tabellendaten synchronisieren. Dies erfolgt mit dem Befehl Postgres
COPY
. Danach sammeln sich WAL-Segmente auf dem Anbieter an, so dass sich Änderungen während des Betriebs ergeben
COPY
Es stellte sich heraus, dass es nach der ersten Synchronisation an den Teilnehmer übertragen wurde, um keinen Datenverlust zu gewährleisten.
In der Praxis bedeutet dies, dass Sie beim Synchronisieren einer großen Tabelle auf einem System mit einer hohen Schreib- / Änderungslast die Festplattennutzung sorgfältig überwachen müssen. Beim ersten Versuch, unsere größte Tabelle (4 TB) zu synchronisieren, arbeiteten das Team und der Bediener
COPY
mehr als einen Tag. Während dieser Zeit hat der Herstellerknoten mehr als ein Terabyte proaktiver WAL-Protokolle gesammelt.
Wie Sie sich vielleicht erinnern, hatten unsere alten Datenbankserver nur noch zwei Terabyte freien Speicherplatz. Aus der Fülle der Serverfestplatte des Abonnenten haben wir geschätzt, dass nur ein Viertel der Tabelle kopiert wurde. Daher musste der Synchronisationsprozess sofort gestoppt werden - die Festplatte auf dem Master wäre früher beendet worden.
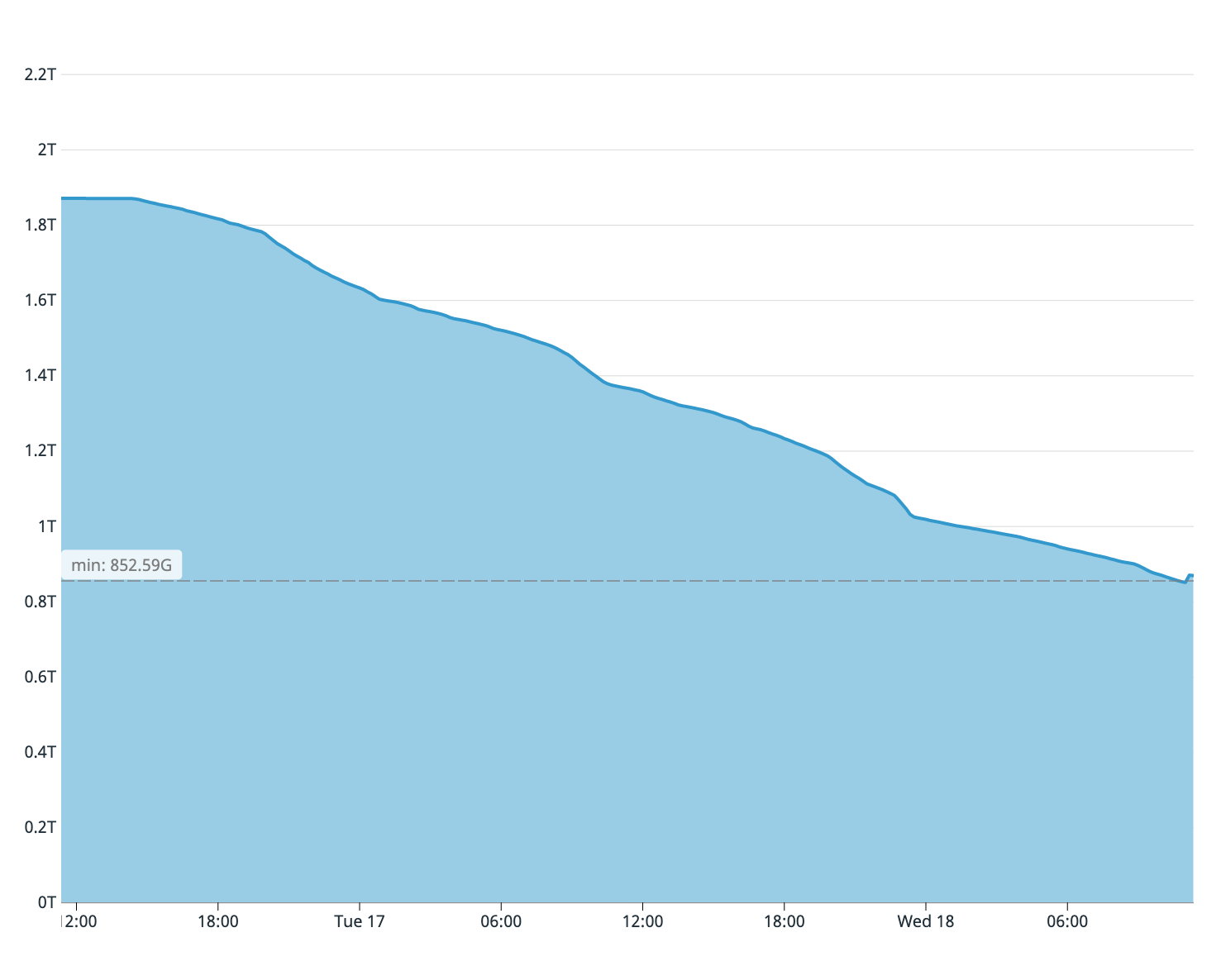
Verfügbarer Speicherplatz im alten Assistenten beim ersten Synchronisierungsversuch
Um den Synchronisierungsprozess zu beschleunigen, haben wir die folgenden Änderungen an der Abonnentendatenbank vorgenommen:
- Alle Indizes für die synchronisierte Tabelle wurden entfernt.
fsynch
umgeschaltet aufoff
;- Geändert
max_wal_size
zu50GB
; - Geändert
checkpoint_timeout
zu1h
.
Diese vier Schritte beschleunigen den Synchronisierungsprozess beim Abonnenten erheblich, und unser zweiter Versuch zur Tabellensynchronisierung wurde in 8 Stunden abgeschlossen.
Lektion 2: Jede Zeilenänderung wird als Konflikt protokolliert
Wenn pglogical einen Konflikt erkennt, hinterlässt die Anwendung einen "
CONFLICT: remote UPDATE on relation PUBLIC.foo. Resolution: apply_remote
" Eintrag in den Protokollen .
Es stellte sich jedoch heraus, dass jede vom Abonnenten verarbeitete Zeilenänderung als Konflikt protokolliert wurde. In wenigen Stunden der Replikation hinterließ die Datenbank des Abonnenten Gigabyte an widersprüchlichen Protokolldateien.
Dieses Problem wurde durch Festlegen eines Parameters
pglogical.conflict_log_level = DEBUG
in der Datei gelöst
postgresql.conf
.
Über den Autor
 Tommy Lee ist Senior Software Engineer bei Coffee Meets Bagel. Zuvor arbeitete er für Microsoft und Wave HQ, einen kanadischen Hersteller von Buchhaltungsautomatisierungssystemen.
Tommy Lee ist Senior Software Engineer bei Coffee Meets Bagel. Zuvor arbeitete er für Microsoft und Wave HQ, einen kanadischen Hersteller von Buchhaltungsautomatisierungssystemen.