Anmerkung
Die wahrgenommene Black-Box-Natur neuronaler Netze ist ein Hindernis für Anwendungen, bei denen Interpretierbarkeit wichtig ist. Hier präsentieren wir DeepLIFT (Deep Learning Important FeaTures), eine Methode zum Zerlegen der Ausgangsvorhersage eines neuronalen Netzwerks an einem bestimmten Eingang, indem die Antworten aller Neuronen (Knoten) des Netzwerks auf jedes Merkmal des Eingangssignals zurückpropagiert werden. DeepLIFT vergleicht die Aktivierung jedes Neurons mit seiner „Referenzaktivierung“ und weist Schätzungen seines individuellen Beitrags zu. Durch die getrennte Betrachtung der positiven und negativen Beiträge kann DeepLIFT auch Abhängigkeiten identifizieren, die andere Ansätze übersehen. Die Ergebnisse können effizient in einem Rücklauf berechnet werden. Wir wenden DeepLIFT auf MNIST-trainierte Modelle und simulierte Genomdaten an.zeigt signifikante Vorteile gegenüber Gradientenmethoden.
Video-Tutorial: http://goo.gl/qKb7pL
ICML-Folien: bit.ly/deeplifticmlslides
ICML-Vortrag: https://vimeo.com/238275076
Code: http://goo.gl/RM8jvH
1. Einleitung
, , « » , . DeepLIFT ( ), . . -, «» , «» . , , DeepLIFT , , , . -, , DeepLIFT , . DeepLIFT , , ,
2.
.
2.1.
. & ( & , 2013 [12]) . «In-silico mutagenesis» (Zhou & Troyanskaya, 2015 [13]) . Zintgraf . (Zintgraf et al., 2017 [14]) . , . , (. 1).

, . , i1 = 1 i2 = 1, i1 i2 0 . , , i1 + i2> 1.
2.2. ,
, , . DeepLIFT.
2.2.1. , (, )
. ( ., 2013 [9]) « » . , () (Zeiler & Fergus, 2013 [12]), (ReLU). , ReLU , , ReLU . , , ReLU , , , ReLU . . (Springenberg et al., 2014 [10]) , ReLU, ReLU , . , , , ReLU. - , , () , . , , . 1, y h ( ), h i1 i2 , i1 + i2> 1 ( ). (. 2).
2.2.2. ×
. (Bach et al., 2015 [1]) , (LRP). . Kindermans et al. (Shrikumar et al., 2016; Kindermans et al., 2016 [8]) , , , LRP ReLU Simonyan et al. ( , × ). DeepLIFT gradient × input, GPU, LRP GPU, .
× , , , . 1 . 2.
2.2.3.
, , (: ) (Sundararajan et al., 2016). , 1 2, ( , , ) . , (. 3.4.3).
2.3. Grad-CAM CAM
Grad-CAM (Selvaraju et al., 2016 [7]) , , , , . ( ) , , Grad-CAM , , Grad-CAM. , . .
3. DeepLIFT
3.1. DeepLIFT
DeepLIFT «» «». «» - «» , , ( . 3.3). , t , , x1, x2, ..., xn , t. t0 t. ∆t , ∆t = t − t0. DeepLIFT




DeepLIFT , , . 1, , . , DeepLIFT, .2, - () . , , , .

-10. , x = 10; x = 10 + e, × 10 + e x -10 ( - ). x < 10, x 0. , ( , ) .
3.2.
3.2.1.
x ∆x t ∆t, , m∆x∆t :

, m∆x∆t - ∆x ∆t, ∆x. : ∂t / ∂x - ∆t, ∆x, ∆x. , .
3.2.2.
, x1, ..., xn, y1, ..., yn t.

. 1 (. ):

. 3 . , - , .
3.3.
DeepLift, 3.5, , - . : y x1, x2, ... , y = f(x1, x2,...).

, ... , y0 :

, .
DeepLIFT. , , , DeepLIFT . « ?». MNIST , . ( {A,C,G, T}) , , ACGT (. 5), , ( J).
, × ( × ∆, ∆ ). , ( 2.2.3) , , DeepLIFT. Guided Backprop , , , , , .
3.4.
3.5.3 , - . , y ∆y + ∆y−, ∆y, :
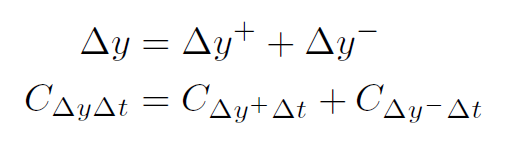
∆y+ ∆y− ∆y , ∆xi, . RevealCancel ( 3.5.3), t , m∆y + ∆t m∆y − ∆t . ( 3.5.1 3.5.2) : m∆y∆t = m∆y + ∆t = m∆y − ∆t.
3.5.
. ( 3.2) ( ) .
3.5.1.
( ). y - xi ,

:

∆y :


:

, 3.2.1.
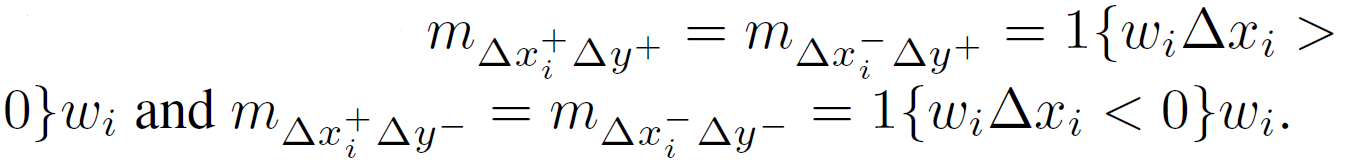
, ∆xi = 0? « » « », , ∆x + i ∆x - i ( ), « » . ,

∆xi 0 ( ∆x-).
. B, , .
3.5.2.
, , ReLU, tanh sigmoid. y - x , y = f(x). y , , ,

: ∆y+ ∆y− ∆+ ∆x− :

, :

,

, . .

, , x , , .
, , , . 1 . 2. . 1,


( , , ). . 2, 0 = 0 = 0, x = 10 + , ∆y =

, × 10+e x -10 (DeepLIFT ).
(Lundberg & Lee, 2016 [6]), DeepLIFT Shapely. , Shapely , . «» , DeepLIFT Shapely. Lundberg & Lee DeepLIFT, .
3.5.3. : REVEALCANCEL
, , . min (i1, i2), . 3, i1 = 0 i2 = 0. , i1, i2 ( , ). , min.
, , ,

,


, ,

i1


, ,

- , , i1 i2, - , i2 i1 h2. i1 < i2;

, , ×, i1, i2, i1 i2 ( . C).
. y = f (x). , ∆y + ∆y−

( ), :
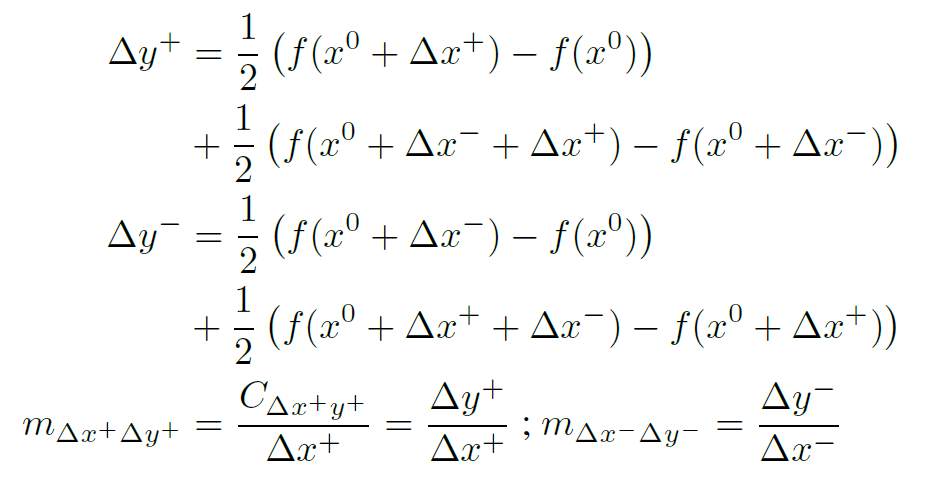
, ∆y+ ∆x+ , ∆x−, ∆y− ∆x− , ∆x+. Shapely ∆x+ ∆x−, y.
, , - , . . 3 RevealCancel 0,5min(i1, i2) ( . C).
RevealCancel , . 1 .2, , . , ReLU, ∆y > 0 iff ∆x ≥ b. ∆x < b , ∆x+, ∆x− ( ), («») . RevealCancel , ∆x+ ∆x- .
.")
,

, , 2.2, i1 i2. RevealCancel 0,5min(i1, i2) .
3.6.
softmax , , . , , , 3.1. , o = (y), y - .

o 1, x1 x2 0,5 0 . , x1 = 100 x2 = 100, o - 1, x1 x2 0,25 . , DeepLIFT. , y, o.
Softmax
, softmax, softmax, , softmax , softmax - . , , . , n - ,

ci ,

, :

, softmax softmax .
4.
4.1. (MNIST)
MNIST (Le-Cun et al., 1999) Keras (Chollet, 2015) 99,2%. , , softmax (. D ). > 1 , , (Springenberg et al., 2014 [10]). DeepLift ( ).
, , : , co, , , Co. ,

157 (20% ),

Co Ct .


: , (8) (3 6). 8, 3 6. 8→6 * . : - 1K , . " -n" n .
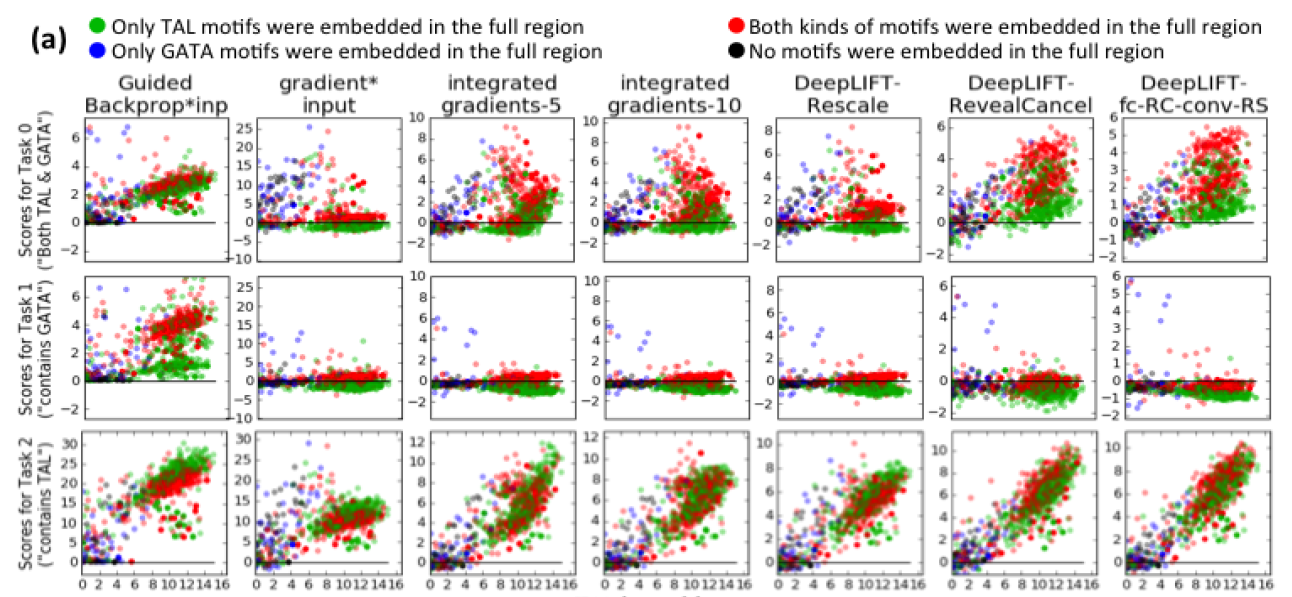

() TAL1 (. G GATA1). -5 . X: log- TAL1 . Y - : . , TAL1 GATA1; GATA1, TAL1, . “DeepLIFT-fc-RC-conv-RS” RevealCancel ( ) , , -, RevealCancel .
() (log-odds > 7) TAL1 , TAL1 GATA1, <= 0 0; * INP DeepLIFT RevealCancel , 1 ( ()).
4.2. ()
( {A,C,G, T}). ( 200-1000), , (RPs), . RP (, GATA1) (, ) (, GATAA GATTA). , (), . , DeepLIFT , , , .
200 ACGT 0,3, 0,2, 0,2 0,3 . (. F) RPs GATA1 TAL1(. 6) (Kheradpour &Kellis, 2014 [3]), 0-3 . , 3 . 1 « - GATA1 TAL1 ()», 2 «GATA1 ()» 3 «TAL1 ()». 1/4 GATA1, TAL1 ( 111), 1/4 GATA1 ( 010), 1/4 TAL1 ( 001) 1/4 ( 000). , F. , ACGT (. . ACGT 0.3, 0.2, 0.2, 0.3; . J). × × ( "", measured ). , , , × , , ; , .
, , ACGT. , 5 ( ) , , . . 5 ( TAL1) E ( GATA1). , : (1) TAL1 2 (2) TAL1 1, (3) ; GATA1 ( 1, 2); (4) TAL1 GATA1 0, (5) , , , ( ; , . 5).
× (2) TAL1 1 ( . H). (4), 0 ( ). Guided Backprop × input, gradient × input (3), , 7, logodds (, ). , Guided Backprop × input gradient × input (. 6). . 2. ( y) .
DeepLIFT: (DeepLIFT-Rescale), RevealCancel (DeepLIFT-RevealCancel) RevealCancel (DeepLIFT-fc-RC-conv-RS). MNIST, , DeepLIFT-fc-RC-convRS RevealCancel. , - , 3.5.3; , , , , (. 6 ).
Gradient × inp, DeepLIFT-Rescale TAL1 0 (. 5b), RevealCancel (. . 6). , RevealCancel . I, (: TAL1, , TAL1, ).

(a) PWM- GATA1 TAL1, . (b) , , , TAL1, GATA1. . - GATA1, - TAL1. - TAL1 (CAGTTG CAGATG). TAL1 GATA1 0. RevealCancel RevealCancel .
5.
DeepLIFT, , «» «» . (. 1), , , tanh. DeepLIFT ( * - . . 2). , DeepLIFT-RevealCancel , (. 3). : () DeepLIFT RNN,(b) (c) «» ( Maxout Maxpooling ) .
[1] Bach, Sebastian, Binder, Alexander, Montavon, Gregoire, Klauschen, Frederick, Muller, Klaus-Robert, and Samek, Wojciech. On Pixel-Wise explanations for Non-Linear classifier decisions by Layer-Wise relevance propagation. PLoS One, 10(7):e0130140, 10 July 2015.
[2] Chollet, Franois. keras. https://github.com/fchollet/keras, 2015.
[3] Kheradpour, Pouya and Kellis, Manolis. Systematic discovery and characterization of regulatory motifs in encode tf binding experiments. Nucleic acids research, 42 (5):2976–2987, 2014.
[4] Kindermans, Pieter-Jan, Schtt, Kristof, Mller, KlausRobert, and Dhne, Sven. Investigating the influence of noise and distractors on the interpretation of neural networks. CoRR, abs/1611.07270, 2016. URL https://arxiv.org/abs/1611.07270.
[5] LeCun, Yann, Cortes, Corinna, and Burges, Christopher J.C. The mnist database of handwritten digits. http://yann.lecun.com/exdb/mnist/,1999.
[6] Lundberg, Scott and Lee, Su-In. An unexpected unity among methods for interpreting model predictions. CoRR, abs/1611.07478, 2016. URL http://arxiv.org/abs/1611.07478.
[7] Selvaraju, Ramprasaath R., Das, Abhishek, Vedantam, Ramakrishna, Cogswell, Michael, Parikh, Devi, and Batra, Dhruv. Grad-cam: Why did you say that? visual explanations from deep networks via gradient-based localization. CoRR, abs/1610.02391, 2016. URL http://arxiv.org/abs/1610.02391.
[8] Shrikumar, Avanti, Greenside, Peyton, Shcherbina, Anna,and Kundaje, Anshul. Not just a black box: Learning important features through propagating activation differences. arXiv preprint arXiv:1605.01713, 2016.
[9] Simonyan, Karen, Vedaldi, Andrea, and Zisserman, Andrew. Deep inside convolutional networks: Visualising image classification models and saliency maps. arXiv preprint arXiv:1312.6034, 2013.
[10] Springenberg, Jost Tobias, Dosovitskiy, Alexey, Brox, Thomas, and Riedmiller, Martin A. Striving for simplicity: The all convolutional net. CoRR, abs/1412.6806, 2014. URL http://arxiv.org/abs/1412.6806.
[11] Sundararajan, Mukund, Taly, Ankur, and Yan, Qiqi. Gradients of counterfactuals. CoRR, abs/1611.02639, 2016. URL http://arxiv.org/abs/1611.02639.
[12] Zeiler, Matthew D. und Fergus, Rob. Faltungsnetzwerke visualisieren und verstehen. AdRR, abs / 1311.2901, 2013. URL http://arxiv.org/abs/1311.2901 .
[13] Zhou, Jian und Troyanskaya, Olga G. Vorhersage der Auswirkungen nichtkodierender Varianten mit einem auf Deep Learning basierenden Sequenzmodell. Nat Methods, 12: 931–4, 2015, Okt. 2015. ISSN 1548–7105. doi: 10.1038 / nmeth.3547.
[14] Zintgraf, Luisa M., Cohen, Taco S., Adel, Tameem und Welling, Max. Visualisierung tiefer neuronaler Netzwerkentscheidungen: Vorhersage der Differenzdifferenz. ICLR, 2017. URL https://openreview.net/pdf?id=BJ5UeU9xx